LLMs
Supervised & Reinforcement Fine-tuning in LLMs
...covered with implementation

Avi Chawla
...covered with implementation

TODAY'S ISSUE
Today, we are discussing the difference between supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT).
In a gist, RFT allows you to transform any open-source LLM into a reasoning powerhouse without any labeled data. Check this visual👇
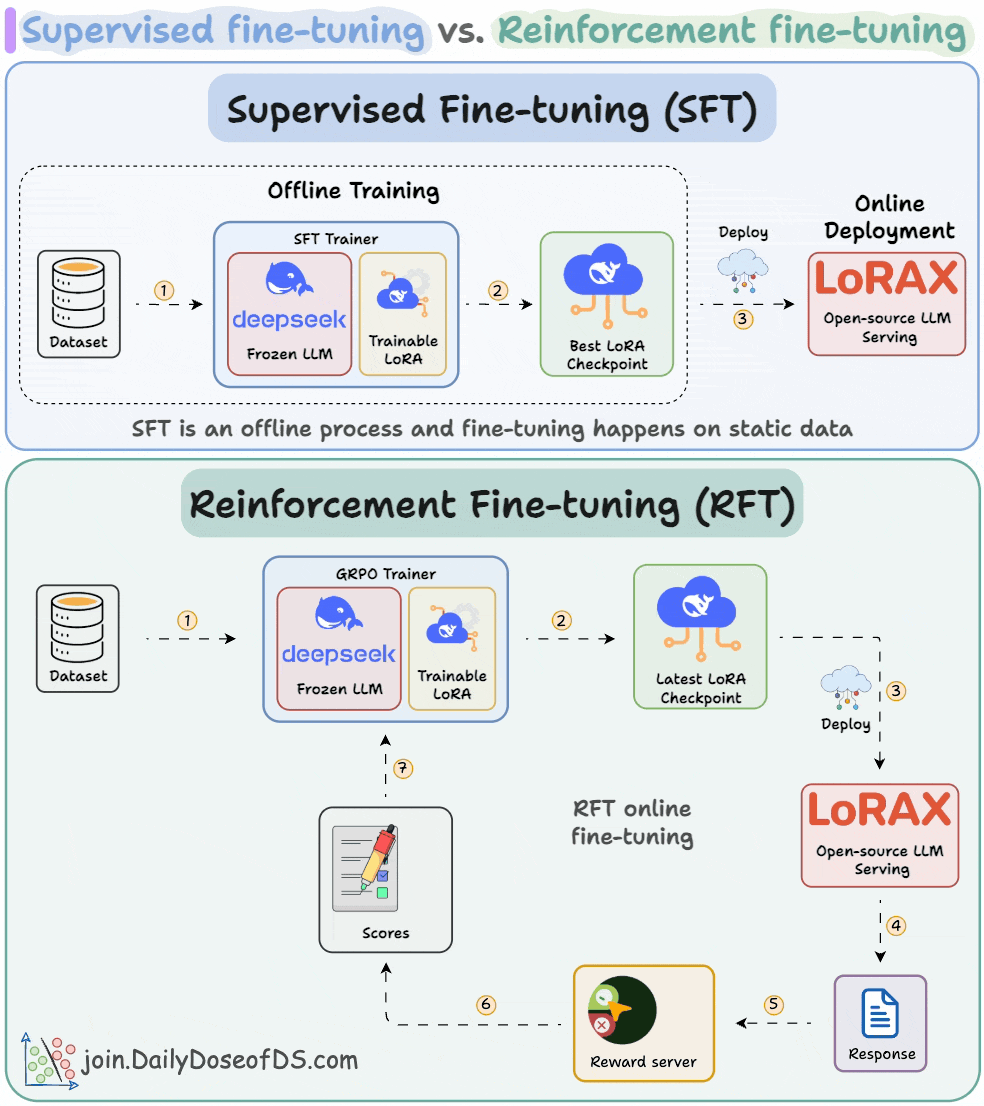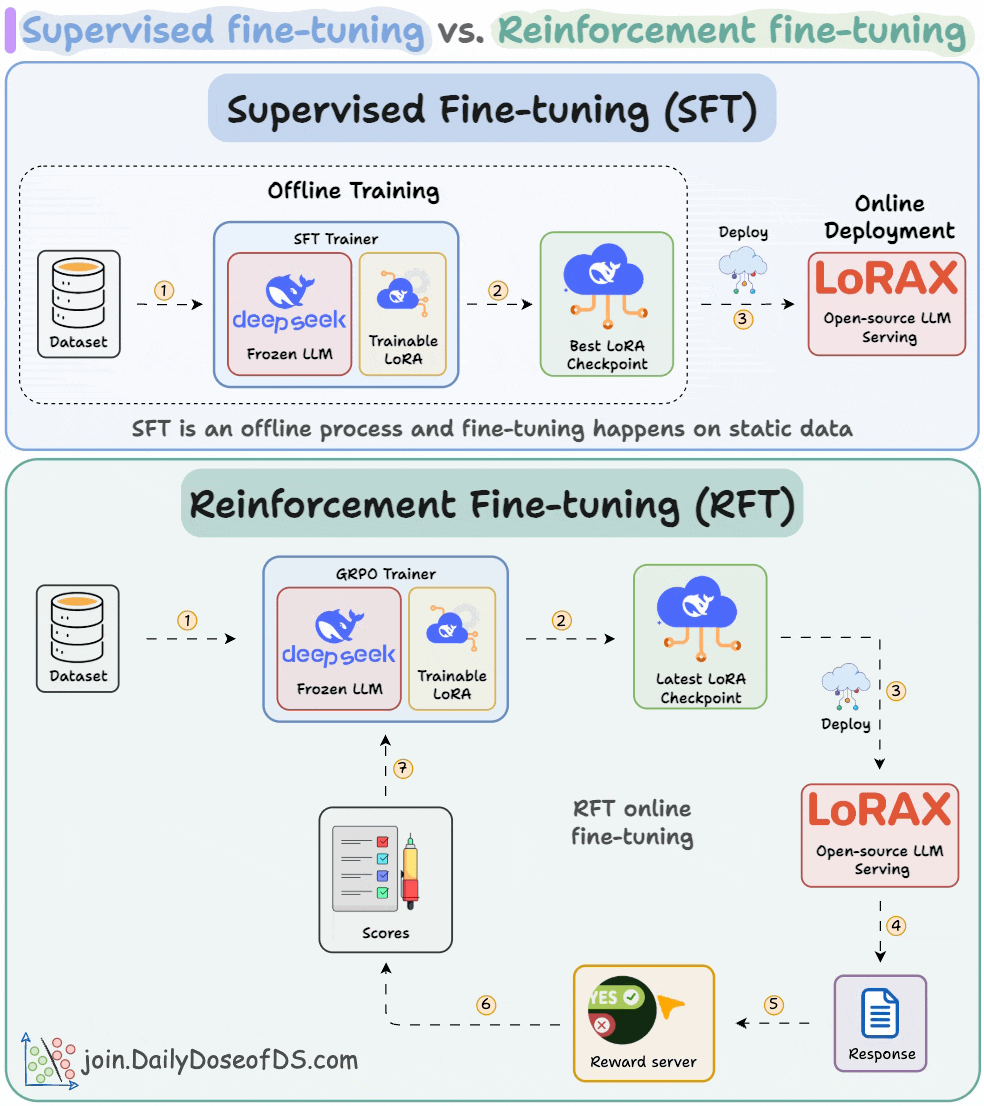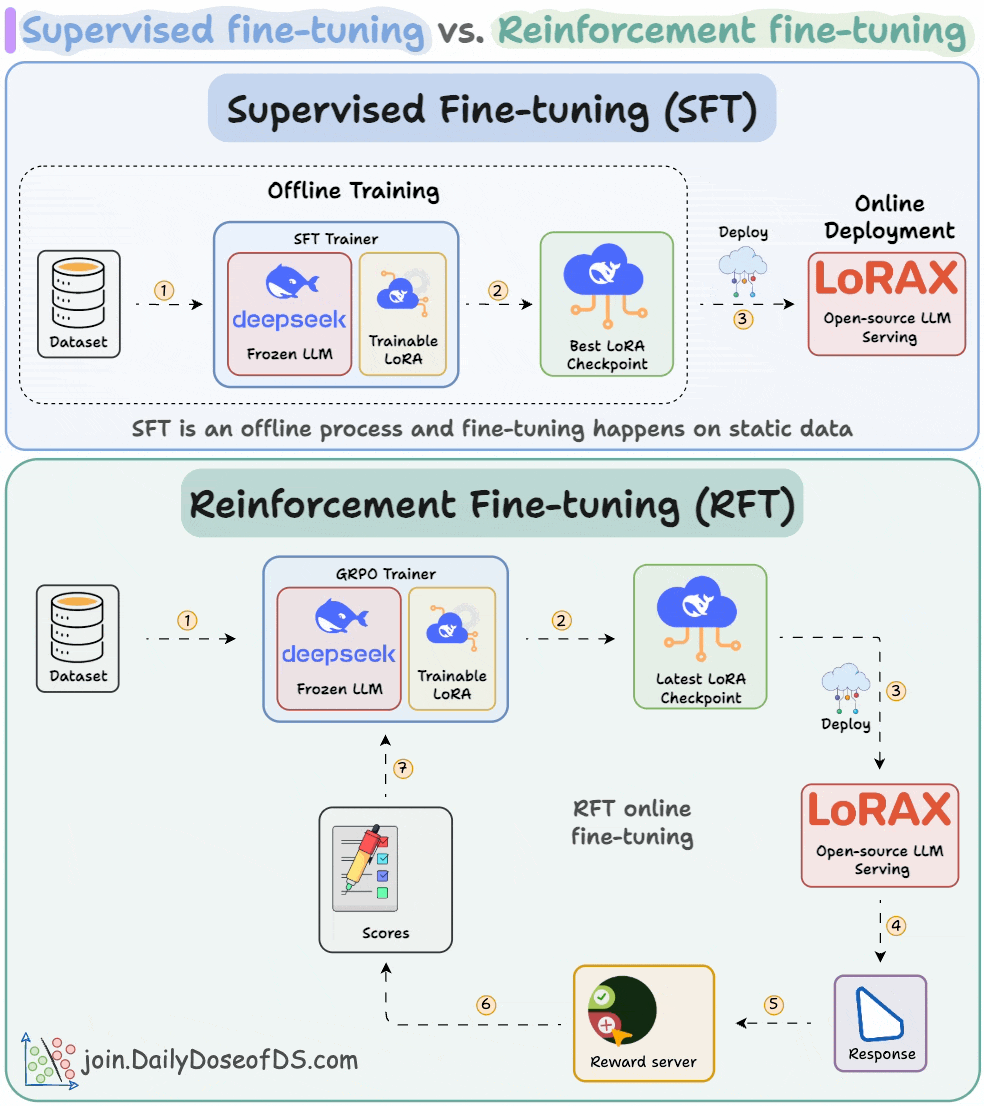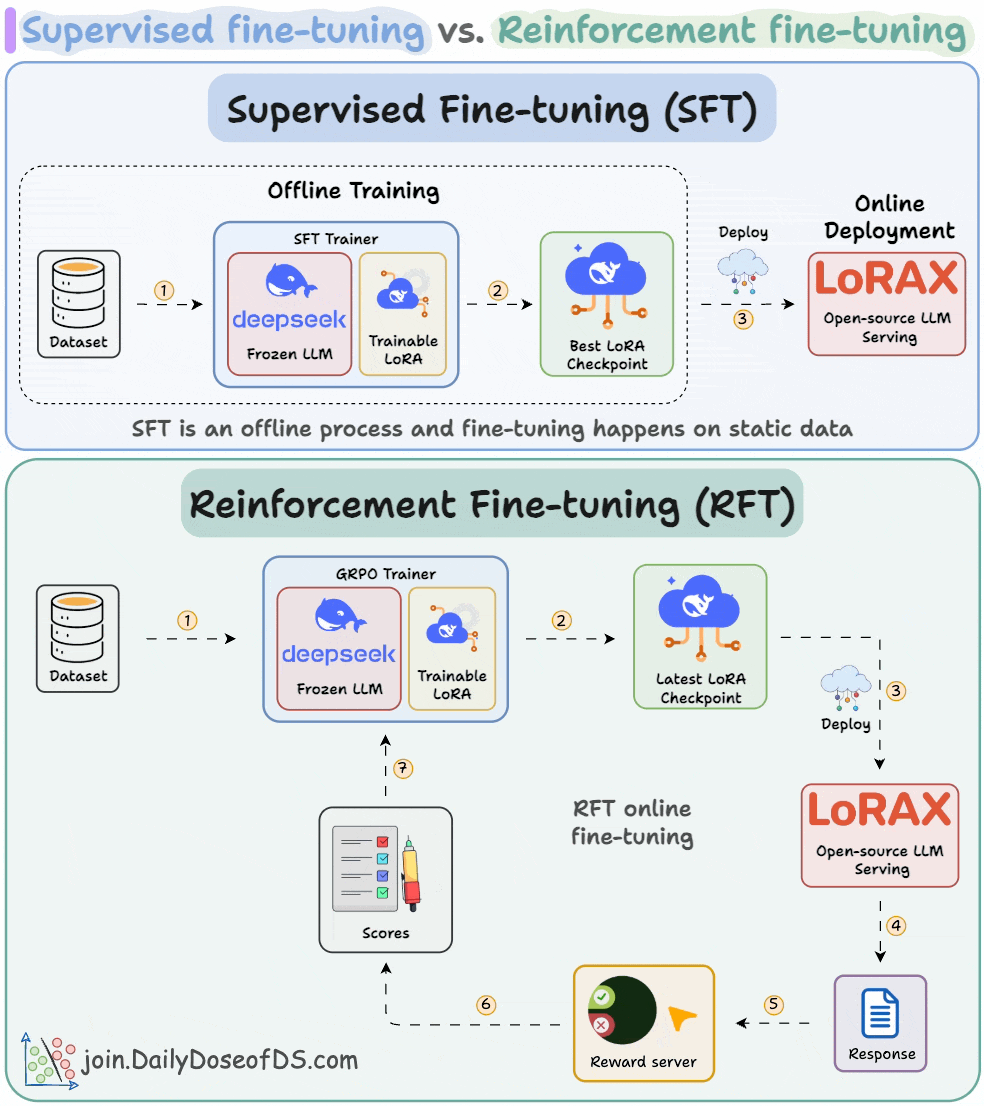
Supervised fine-tuning (SFT):
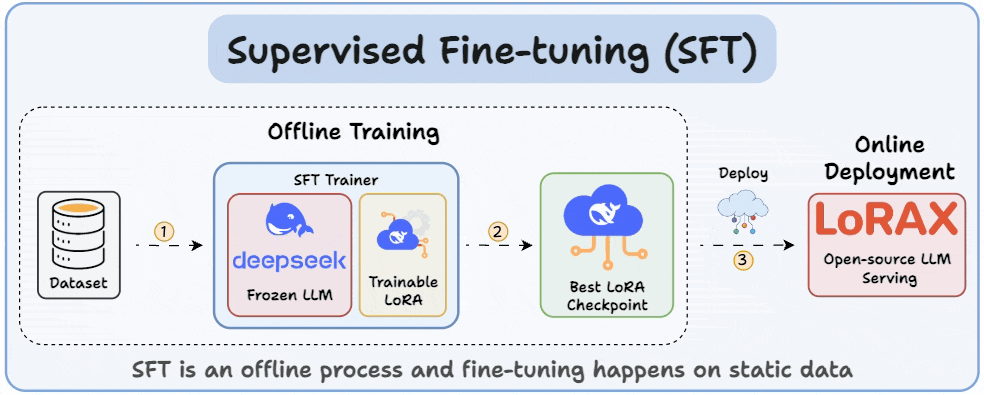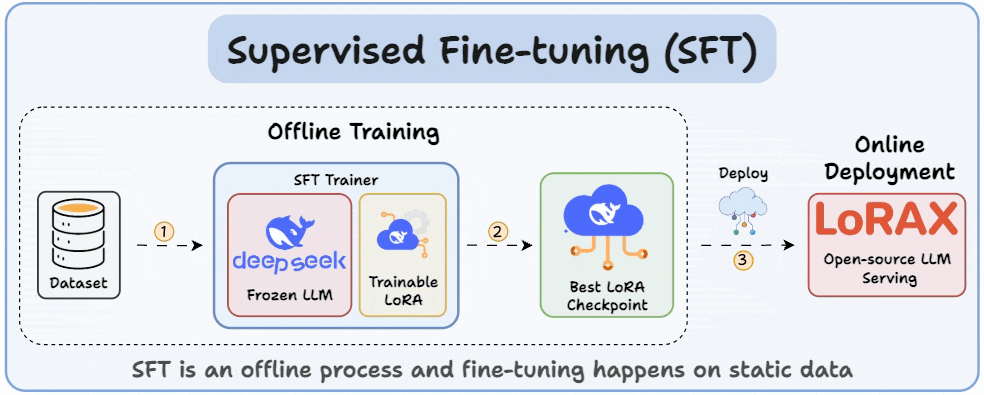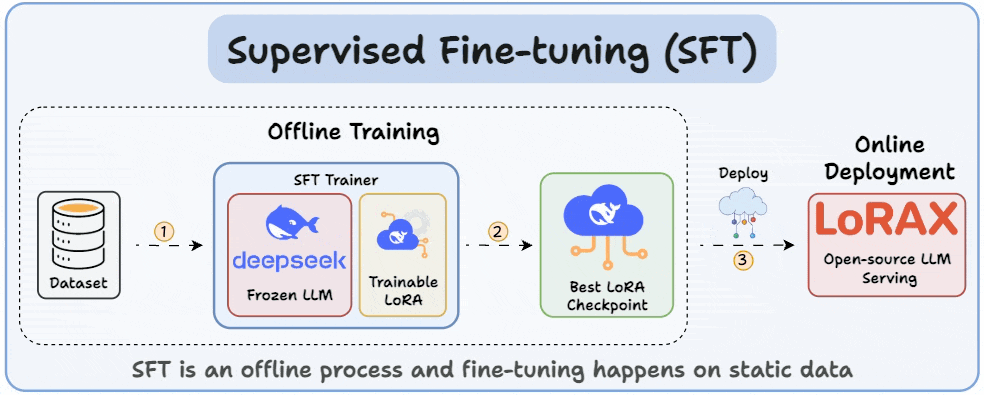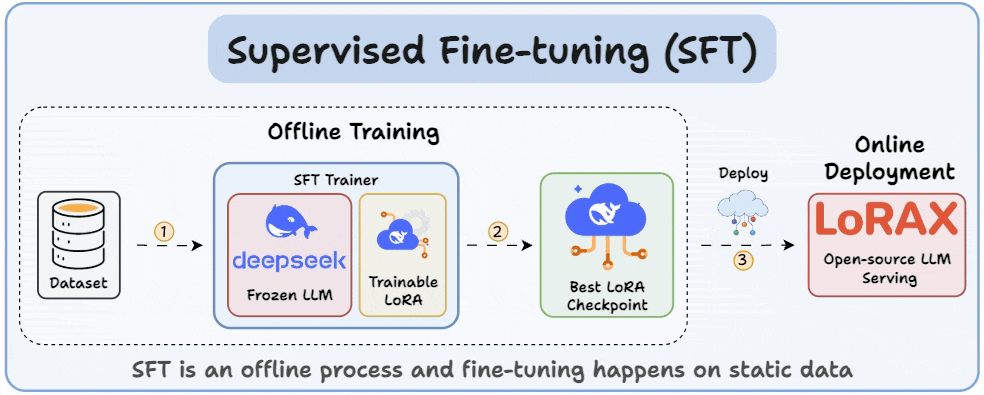
Due to a static dataset, the LLM often memorizes answers.
Reinforcement fine-tuning (RFT):
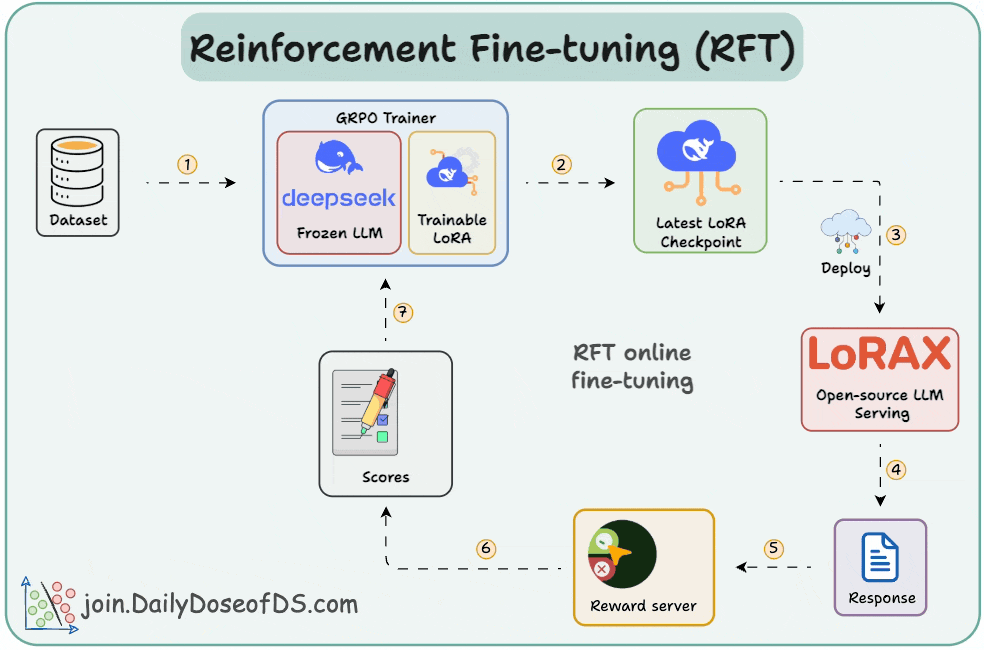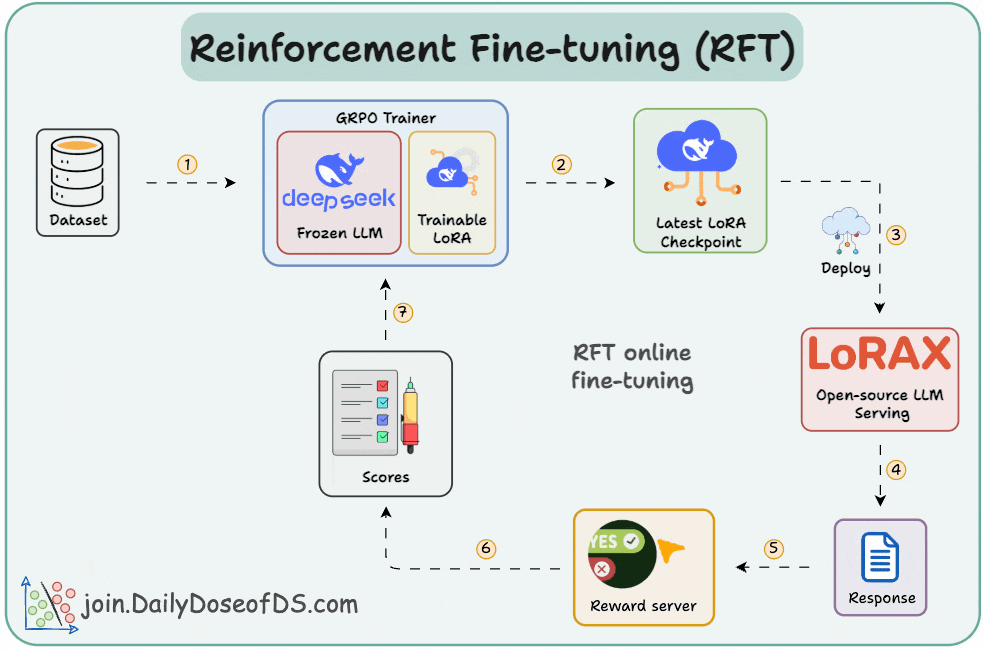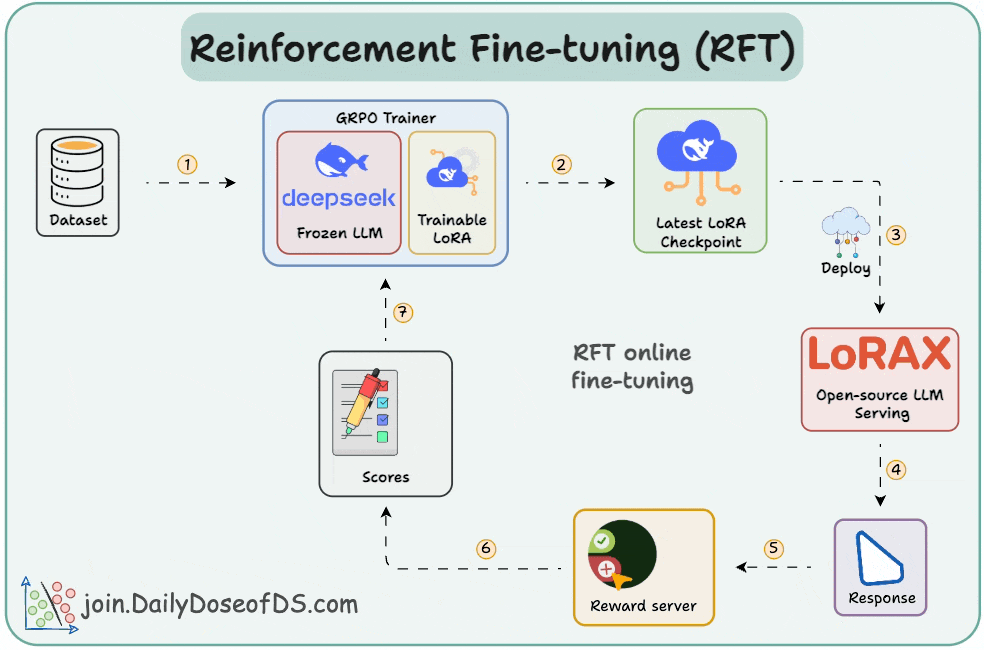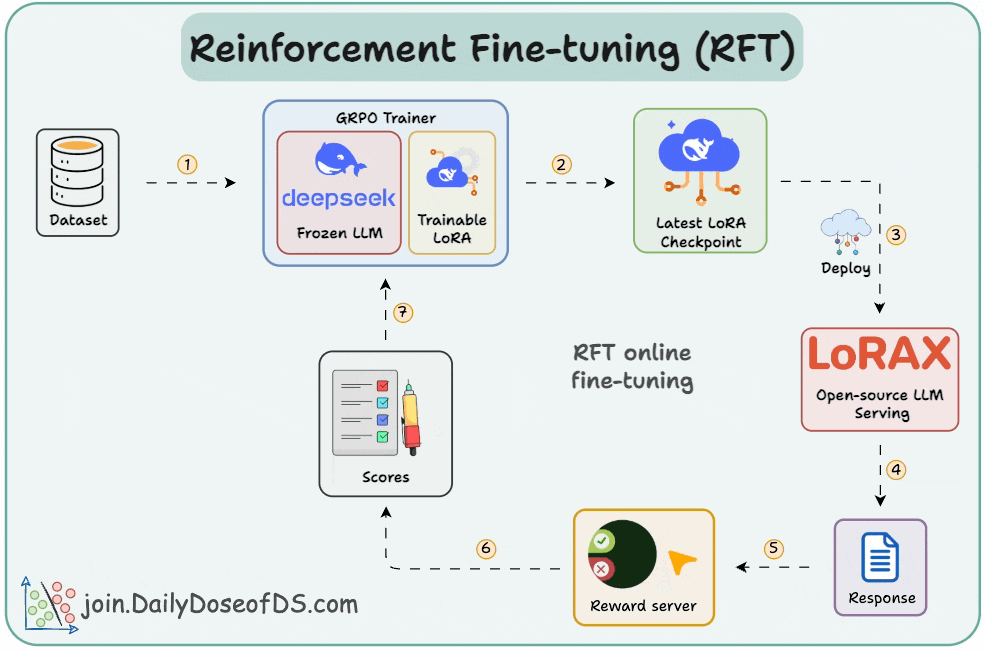
With time, the model starts generating high-reward answers.
Once the model has been trained, you can deploy it on open-source inference servers like LoRAX that can scale to 1000s of fine-tuned LLMs on a single GPU.
We have attached a video below that uses Predibase for RFT to transform Qwen-2.5:7b into a reasoning model.
Unlike previous generations, LLaMA 4 doesn’t rely solely on the classic Transformer architecture.
Instead, it uses a Mixture-of-Experts (MoE) approach, activating only a small subset of expert subnetworks per token.
Here’s how Mixture-of-Experts (MoE) differs from a regular Transformer model:
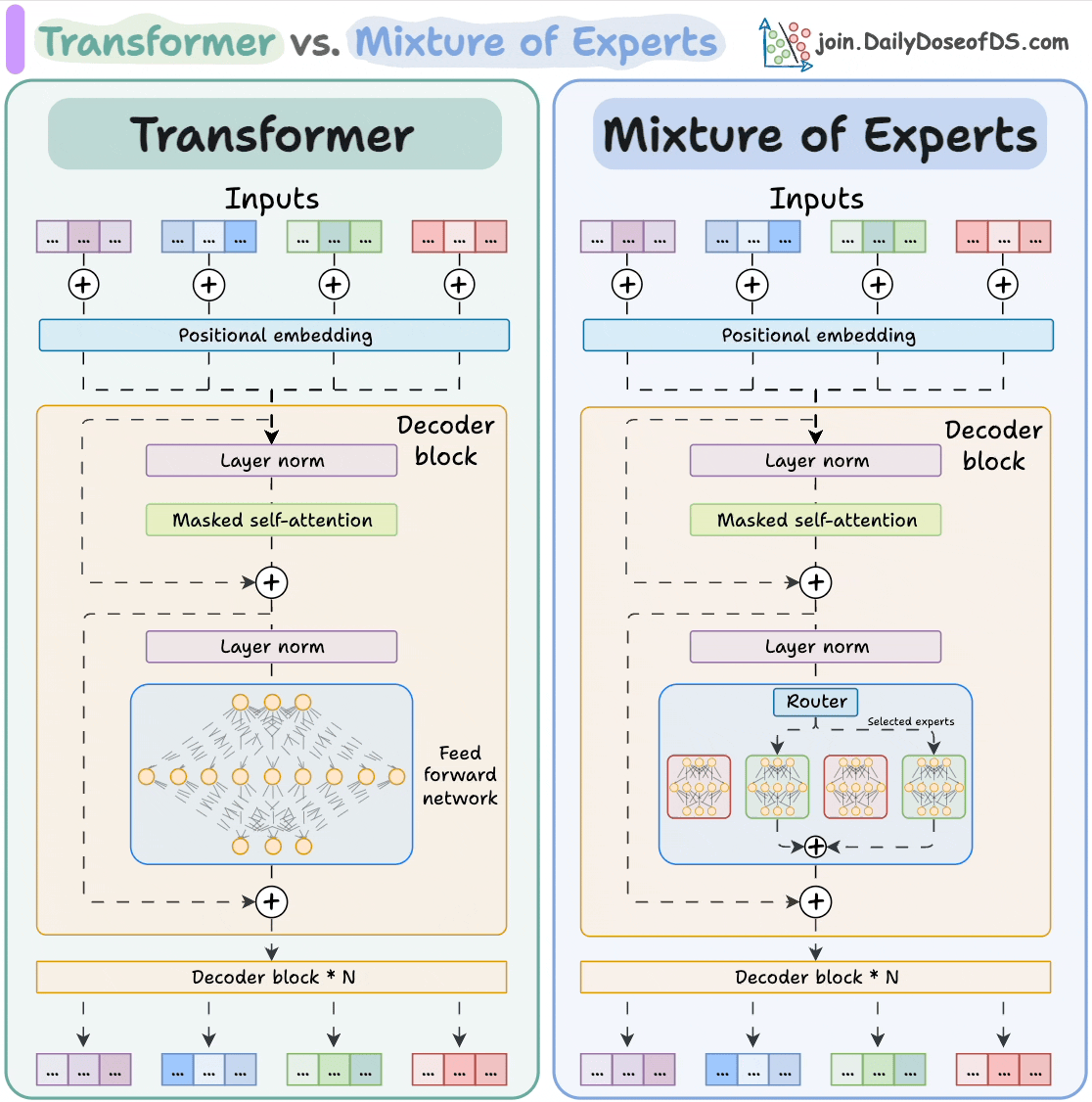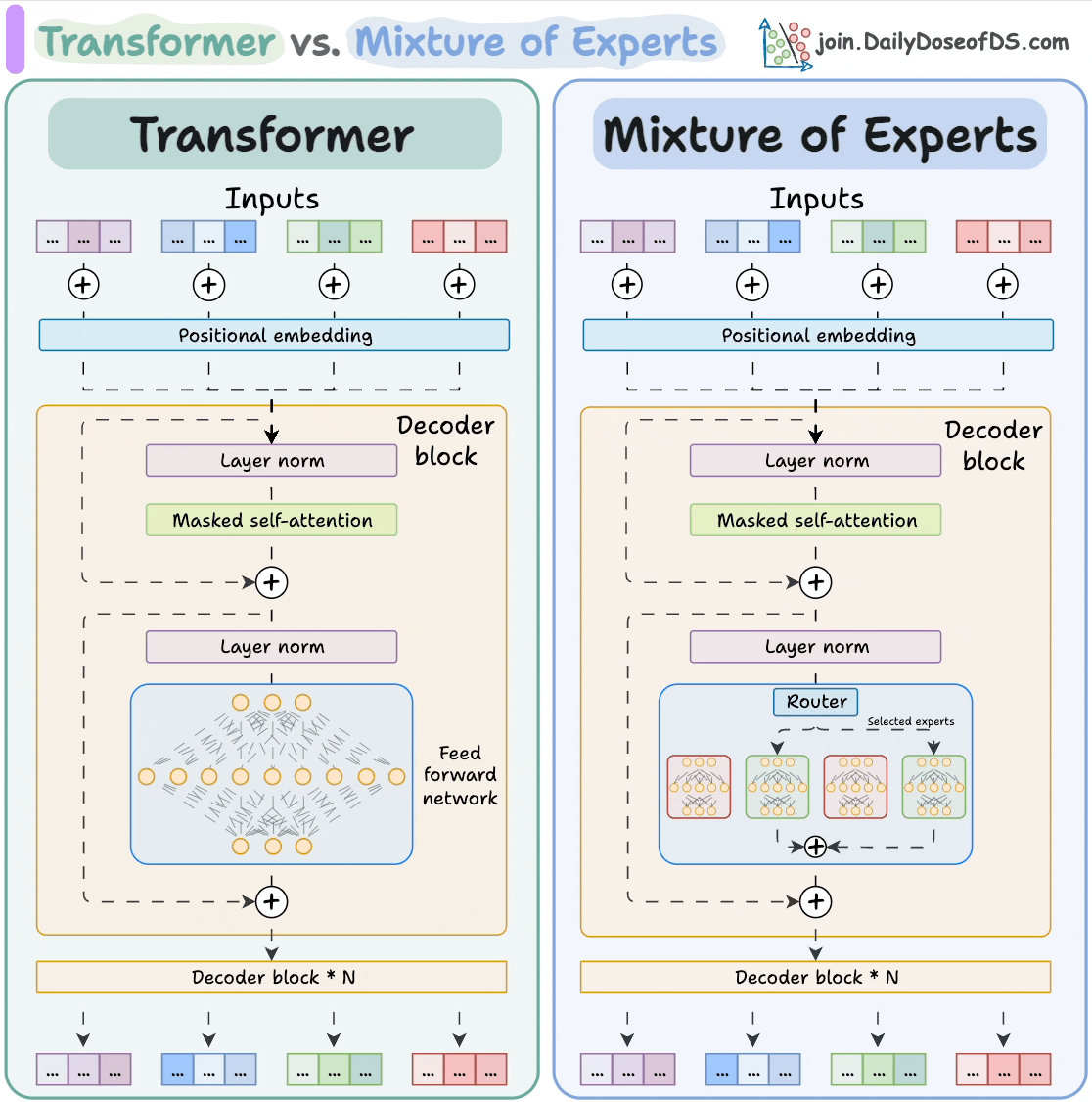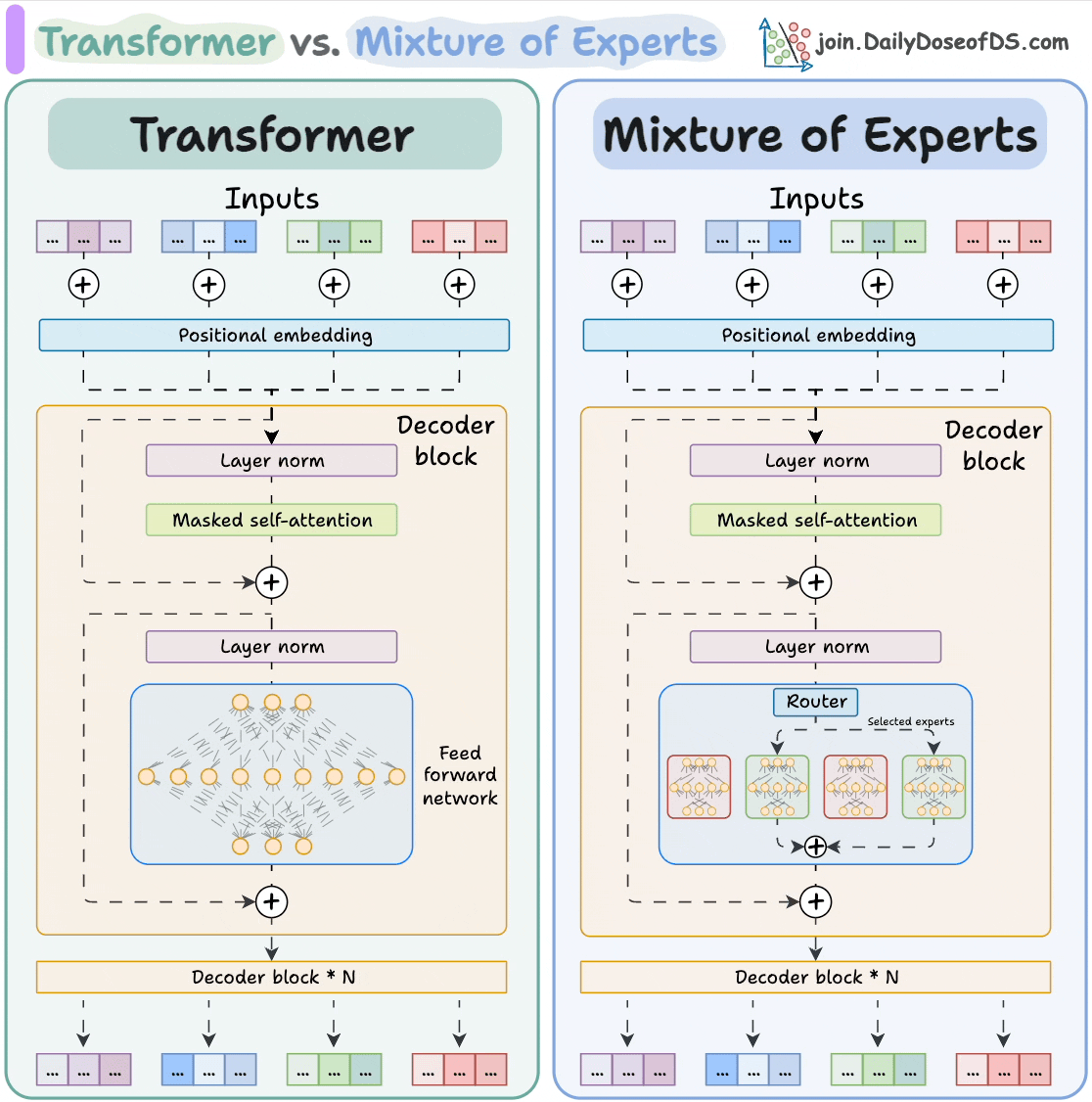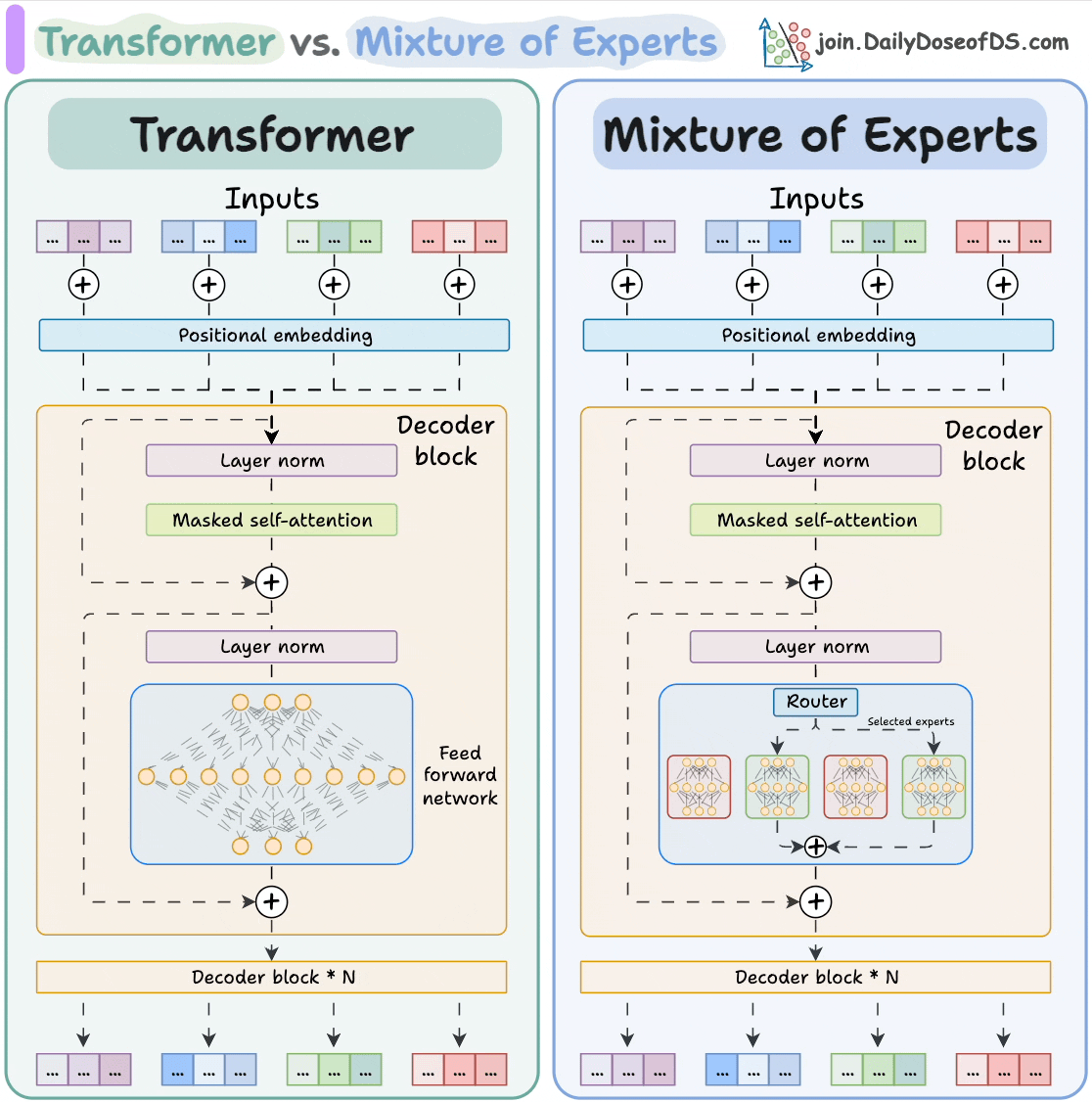
The subnetworks allow the model to scale to hundreds of billions of parameters while keeping inference efficient and cost-effective.
But how does that actually work under the hood?
We answer that by building an MoE-based Transformer from scratch.
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
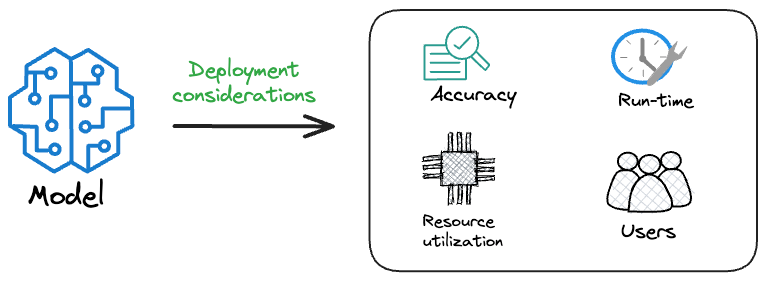
Instead, we also consider several operational and feasibility metrics, such as:
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.
Learn how to compress models before deployment with implementation →