Machine Learning
Discriminative vs. Generative Models
a popular interview question.

Avi Chawla
a popular interview question.

TODAY'S ISSUE
Here’s a visual that depicts how generative and discriminative models differ:
We have seen this topic come up in several interviews, so today, let’s understand the details.
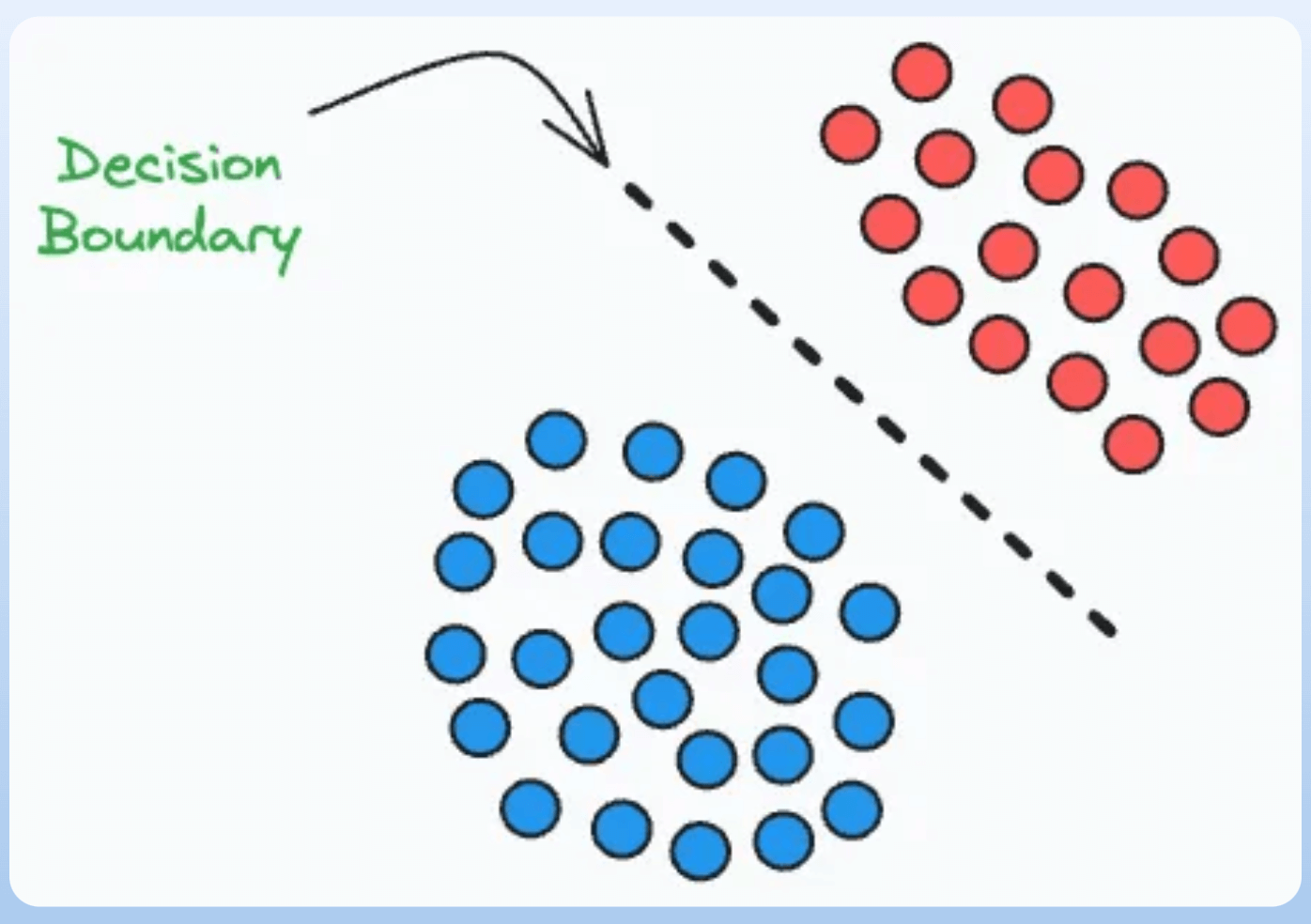
Discriminative models are primarily centered around discriminating between values of the outcome.
While their general notion appeals towards classification, regression models are also discriminative models.
For instance, even though linear regression does not involve a decision boundary between two classes, it is still discriminating between an outcome of “0.5” vs an outcome of “1.5” vs an outcome of “-0.6”.
Mathematically speaking, they maximize the conditional probability P(Y|X), which is read as follows: “Given an input X, maximize the probability of label Y.”
Popular examples include:
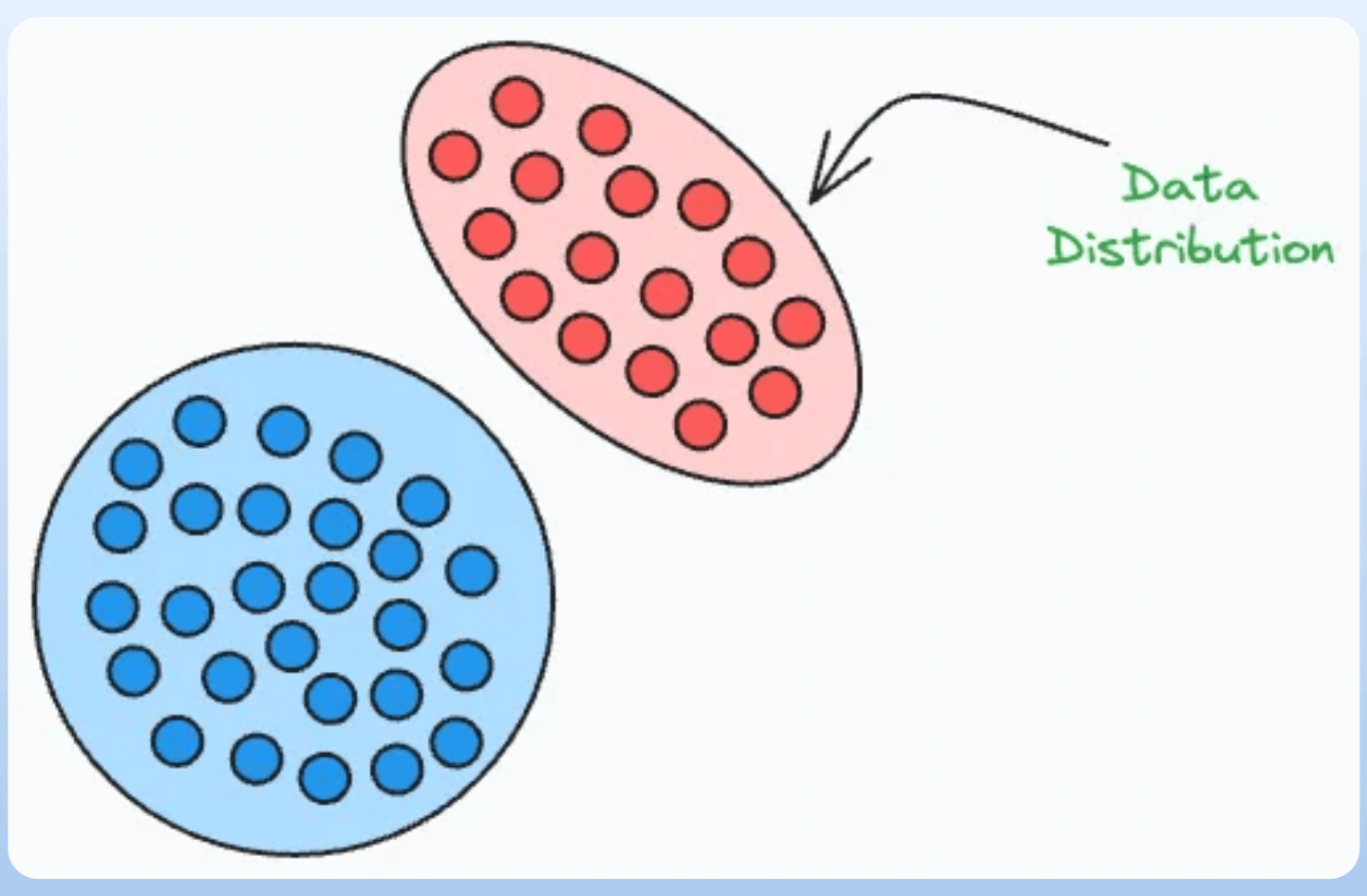
Generative models primarily focus on learning the class-conditional distribution.
Thus, they maximize the joint probability P(X, Y) by learning the class-conditional distribution P(X|Y):
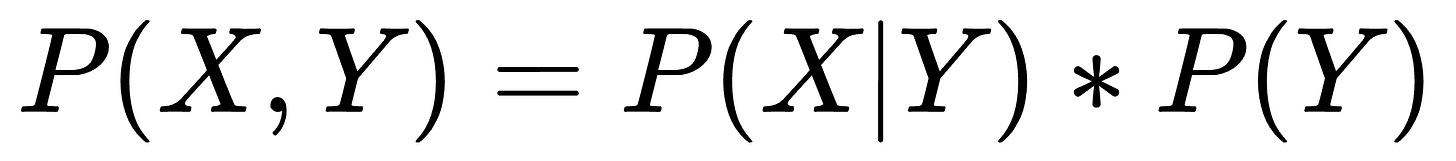
Popular examples include:
We formulated Gaussian Mixture Models and implemented them from scratch here: Gaussian Mixture Models (GMMs).
Since generative models learn the underlying distribution, they can generate new samples.

For instance, consider a GAN:
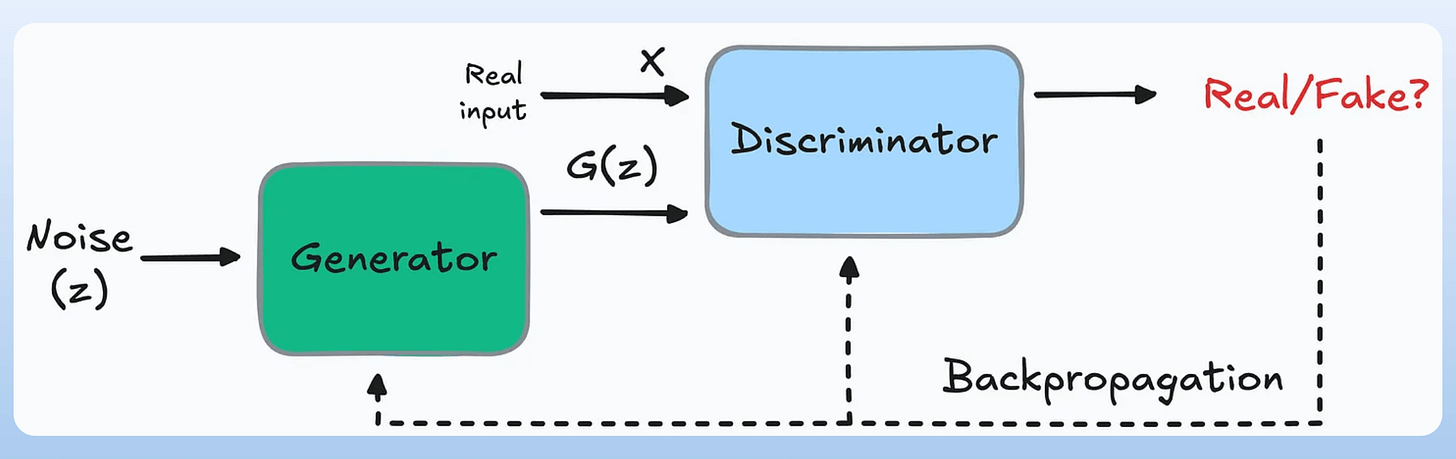
Once the model has been trained, you can remove the discriminator and just use the generator to generate real-looking images:
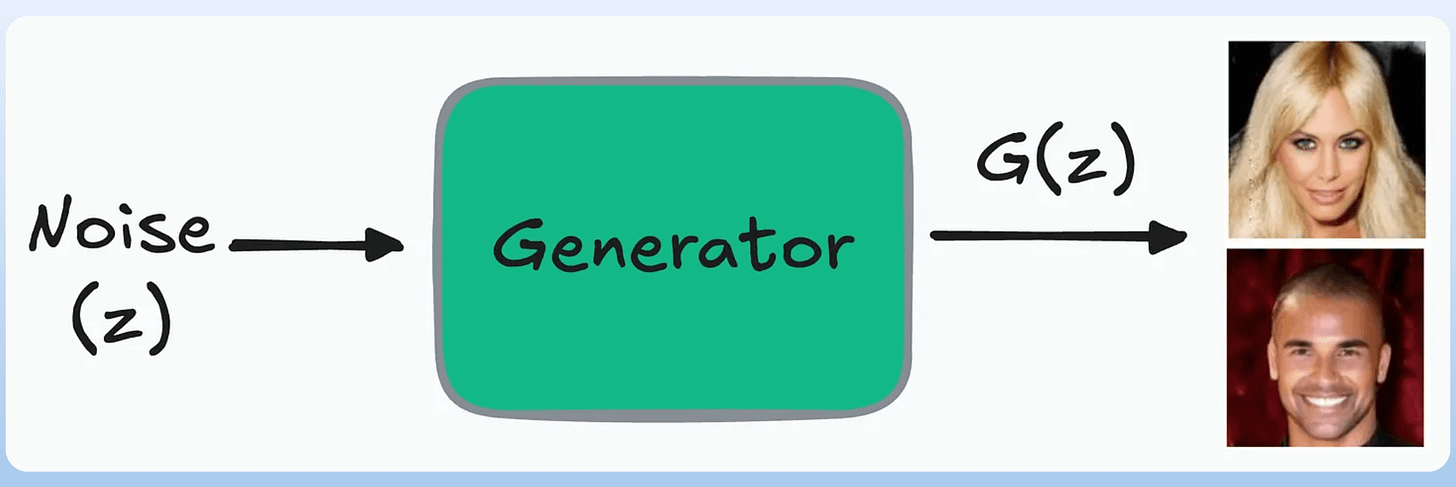
However, this is not possible with discriminative models.
Furthermore, generative models possess discriminative properties, i.e., they can be used for classification tasks (if needed).
However, discriminative models do not possess generative properties.
Let’s consider an example to better understand them.
Imagine you are a language classification system.
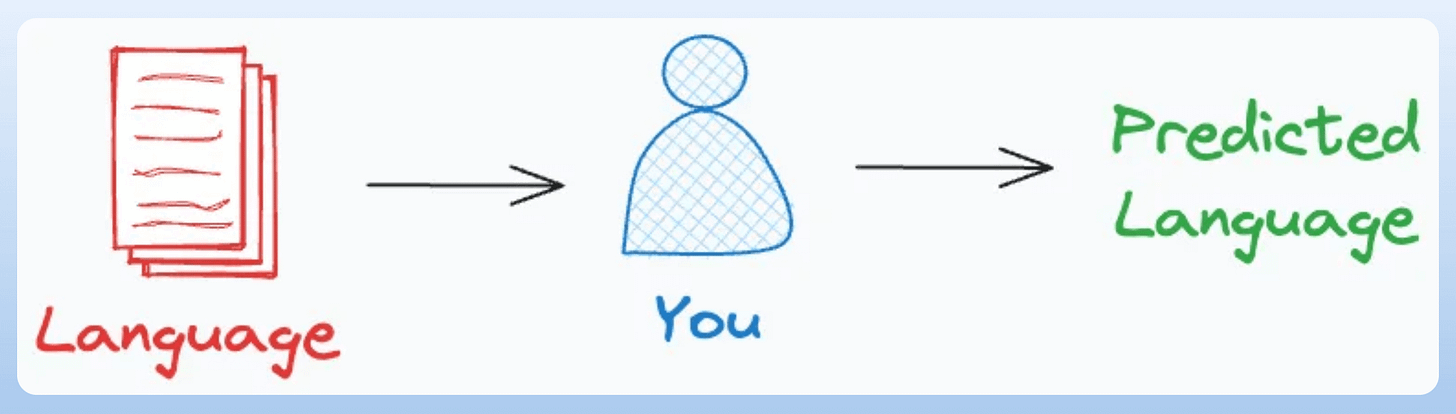
There are two ways to classify languages:
The first approach is generative. This is because you learned the underlying distribution of each language.
In other words, you learned the joint distribution P(Words, Language).
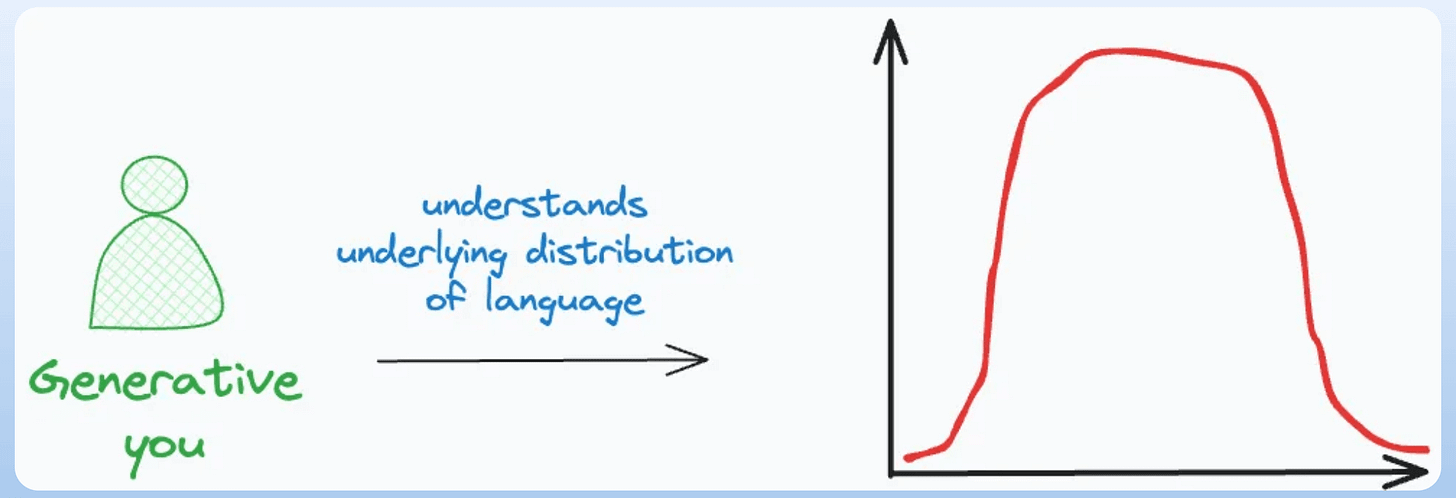
Moreover, since you understand the underlying distribution, you can also generate new sentences.
The second approach is discriminative. This is because you only learned some distinctive patterns for each language:
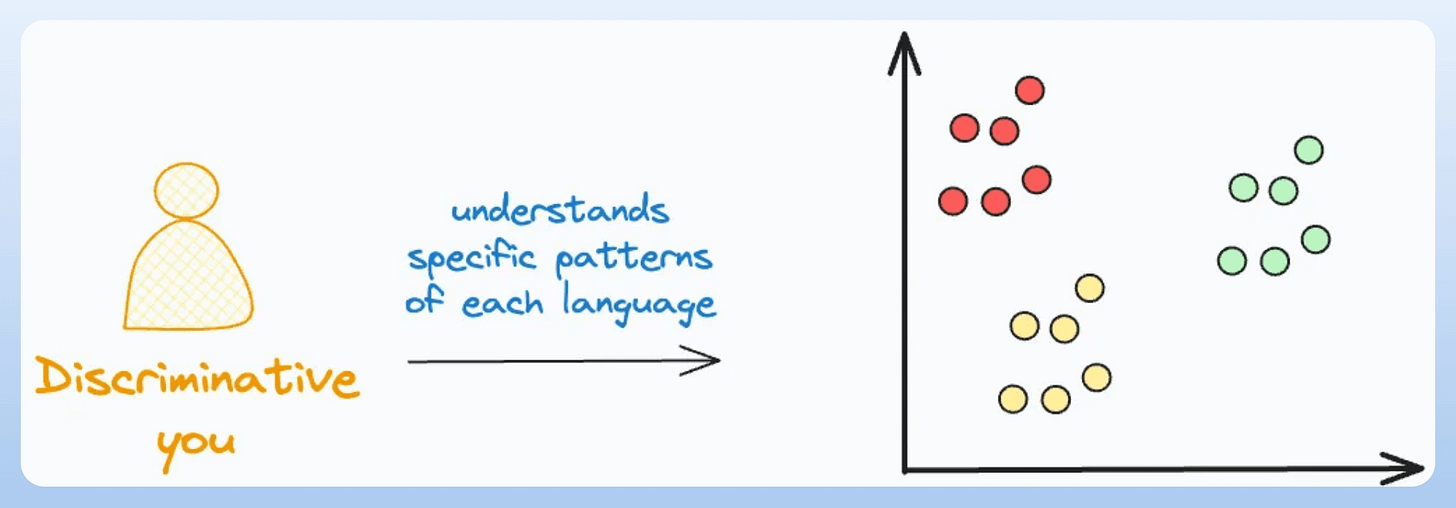
In this case, since you learned the conditional distribution P(Language|Words), you cannot generate new sentences.
This is the difference between generative and discriminative models.
Also, the above description might persuade you that generative models are more generally useful, but it is not true.
Generative models have their own modeling complications—like requiring much more data than discriminative models.
Relate it to the language classification example again.
Imagine the amount of data you would need to learn all languages (generative approach) vs. the amount of data you would need to understand some distinctive patterns (discriminative approach).
👉 Over to you: What are some other problems while training generative models?
Before MCPs became mainstream (or popular like they are right now), most AI workflows relied on traditional Function Calling.
Now, MCP (Model Context Protocol) is introducing a shift in how developers structure tool access and orchestration for Agents.
Here’s a visual that explains Function calling & MCP:
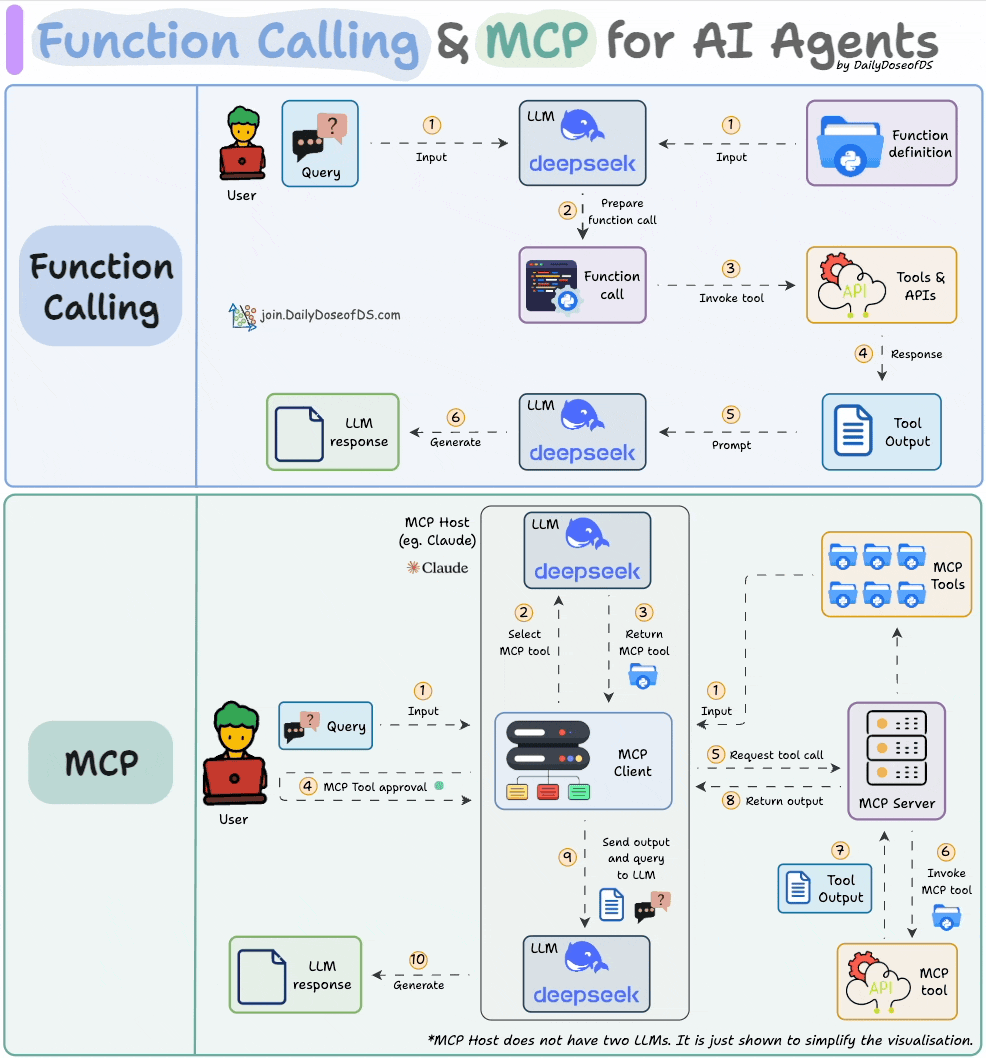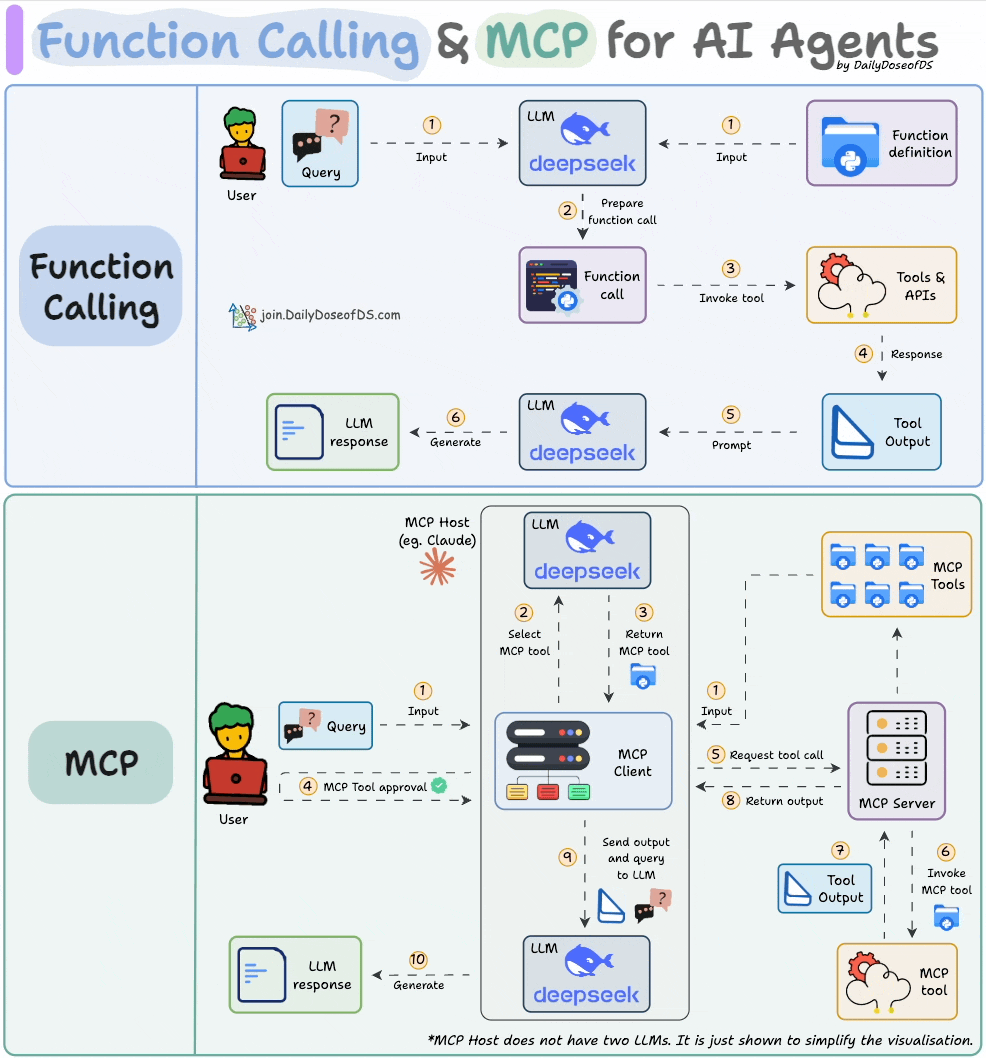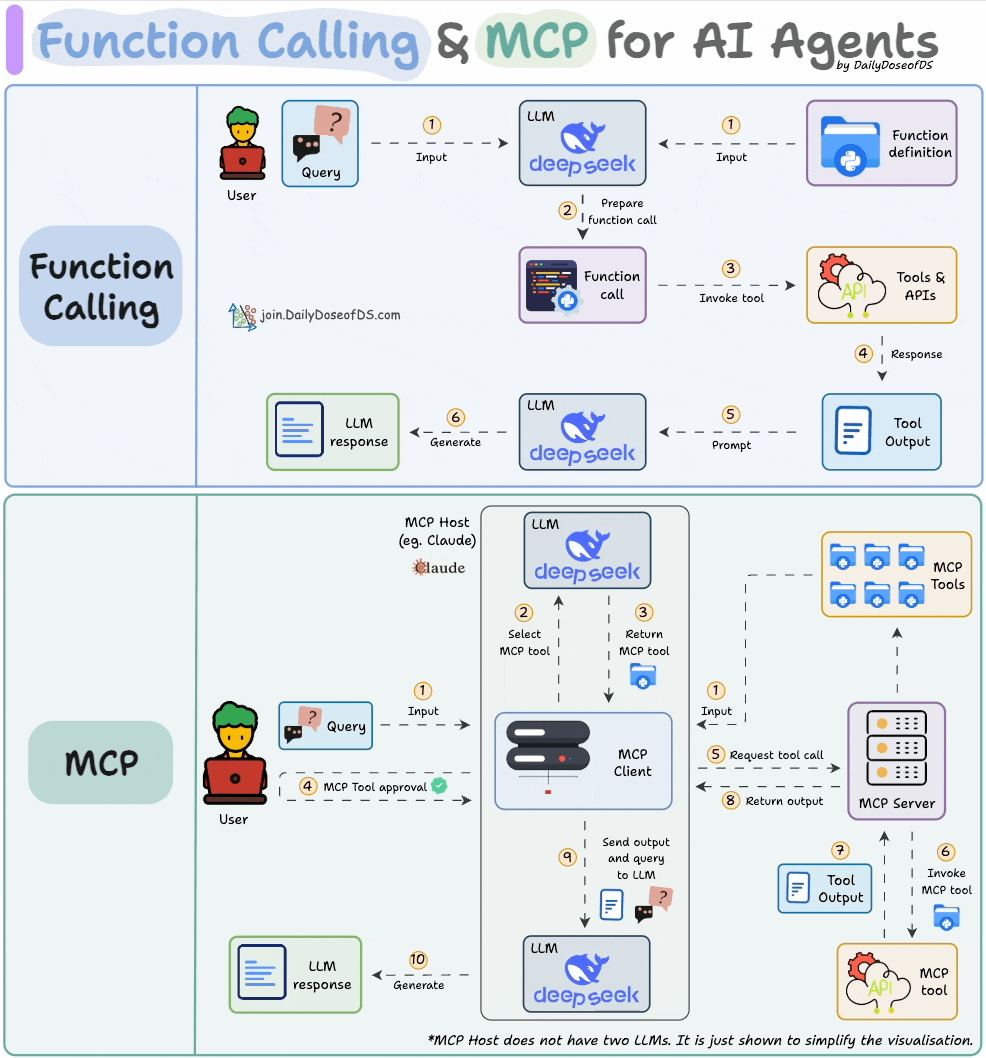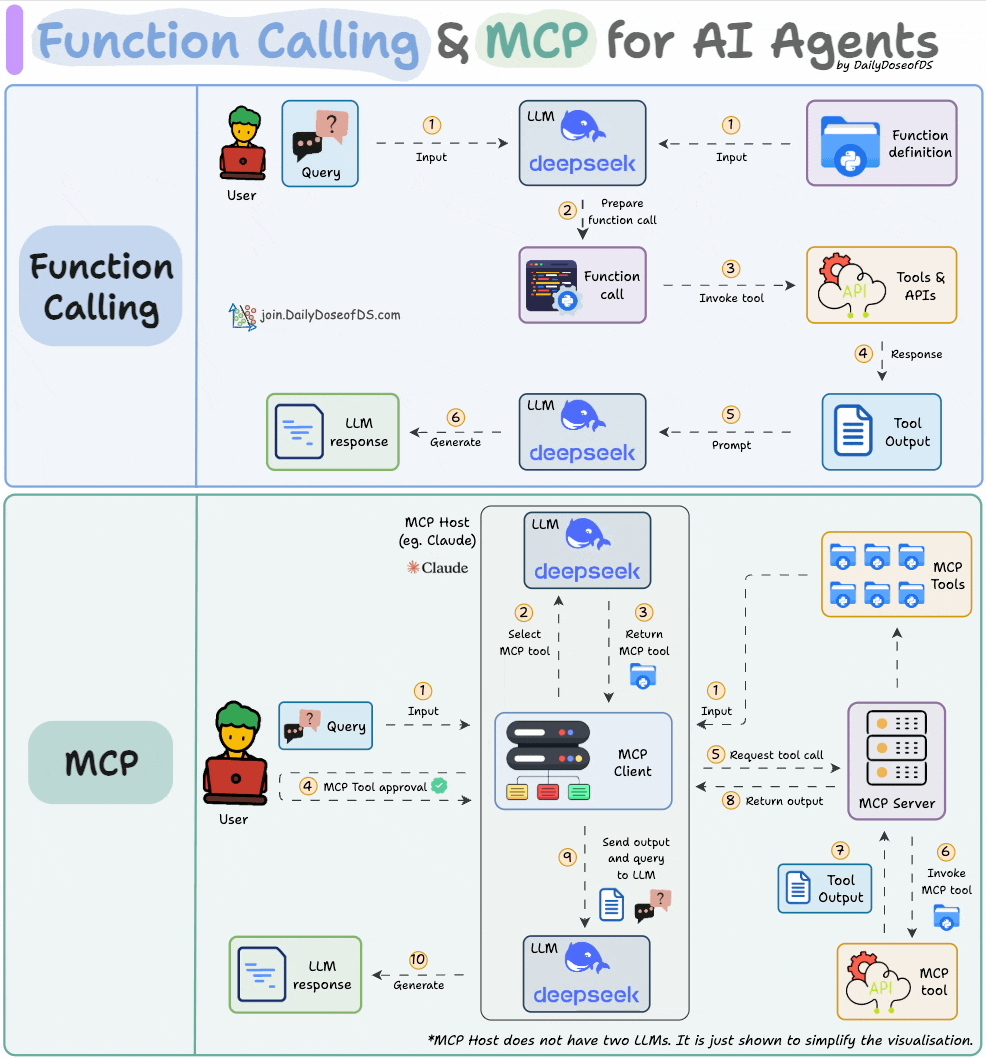
Learn more about it with visual and code in our recent issue here →
There’s so much data on your mobile phone right now — images, text messages, etc.
And this is just about one user—you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
The problem?
This data is private.
So consolidating this data into a single place to train a model.
The solution?
Federated learning is a smart way to address this challenge.
The core idea is to ship models to devices, train the model on the device, and retrieve the updates:
But this isn't as simple as it sounds.
1) Since the model is trained on the client side, how to reduce its size?
2) How do we aggregate different models received from the client side?
3) [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Learn how to implement federated learning systems (beginner-friendly) →