Python
Descriptors in Python
An underrated gem of Python OOP.

Avi Chawla
An underrated gem of Python OOP.

TODAY'S ISSUE
Say we want to define a class where all instance-level attributes must be positive.
Getters and setters are commonly used to do this.
But the problem is that these getters and setters scale with the number of attributes in your class:
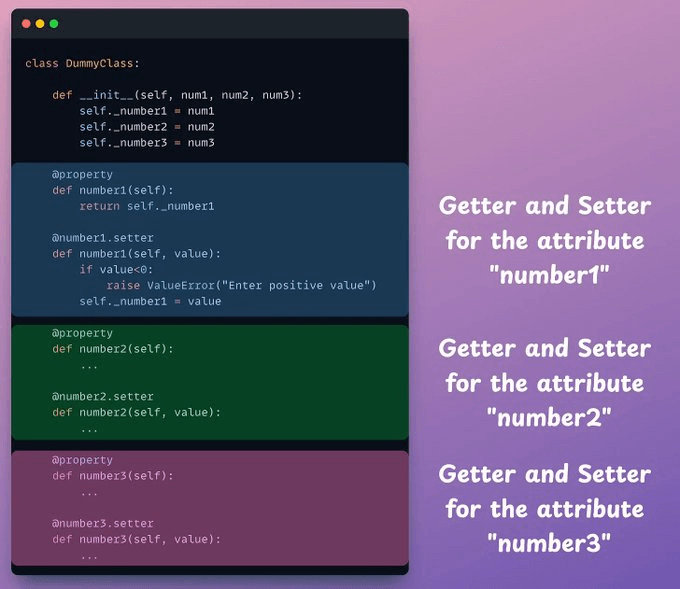
Also, there's so much redundancy in this code:
And to make things worse, the setters are not invoked while creating an object.

So you must add additional checks to ensure an object is created with valid inputs.
Descriptors solve all these problems.
Simply put, Descriptors are objects with methods (like __get__, __set__, etc.) that are used to manage access to the attributes of the class of interest.
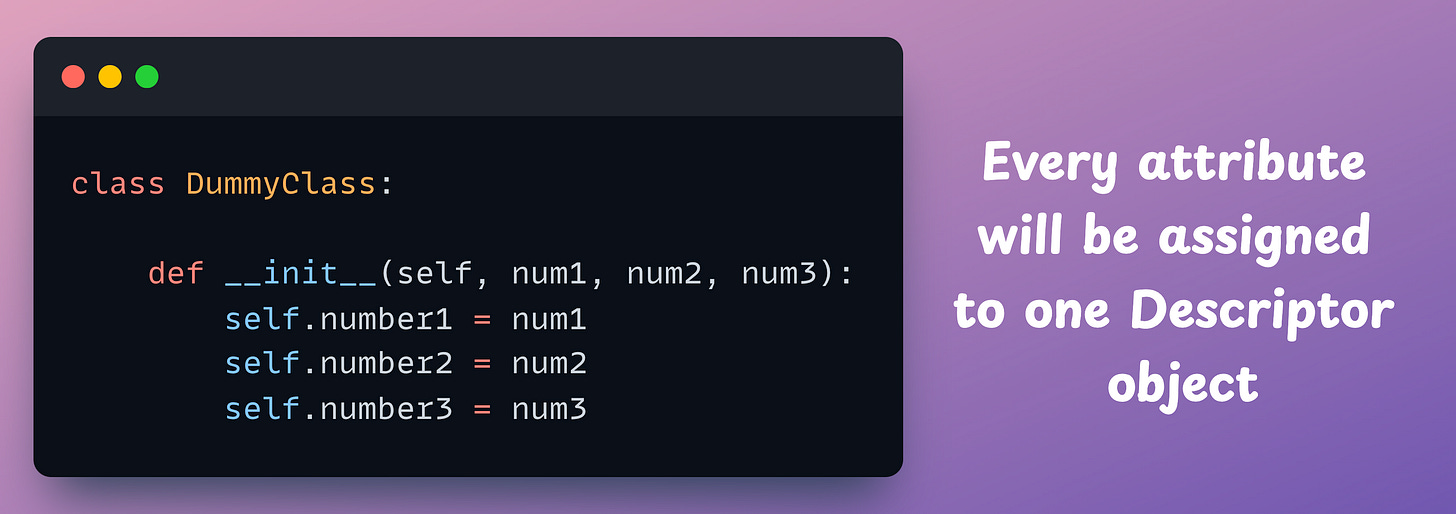
Thus:
number1 → gets its own descriptor.number2 → gets its own descriptor.number3 → gets its own descriptor.A Descriptor class is implemented with three methods:

__set__ method is called when the attribute is assigned a new value. We can define all custom checks here.__set_name__ method is called when the descriptor object is assigned to a class attribute. It allows the descriptor to keep track of the name of the attribute it’s assigned to within the class.__get__ method is called when the attribute is accessed.If it’s unclear, let me give you a demonstration.
Consider this Descriptor class:

I’ll explain this implementation shortly, but before that, consider this usage:
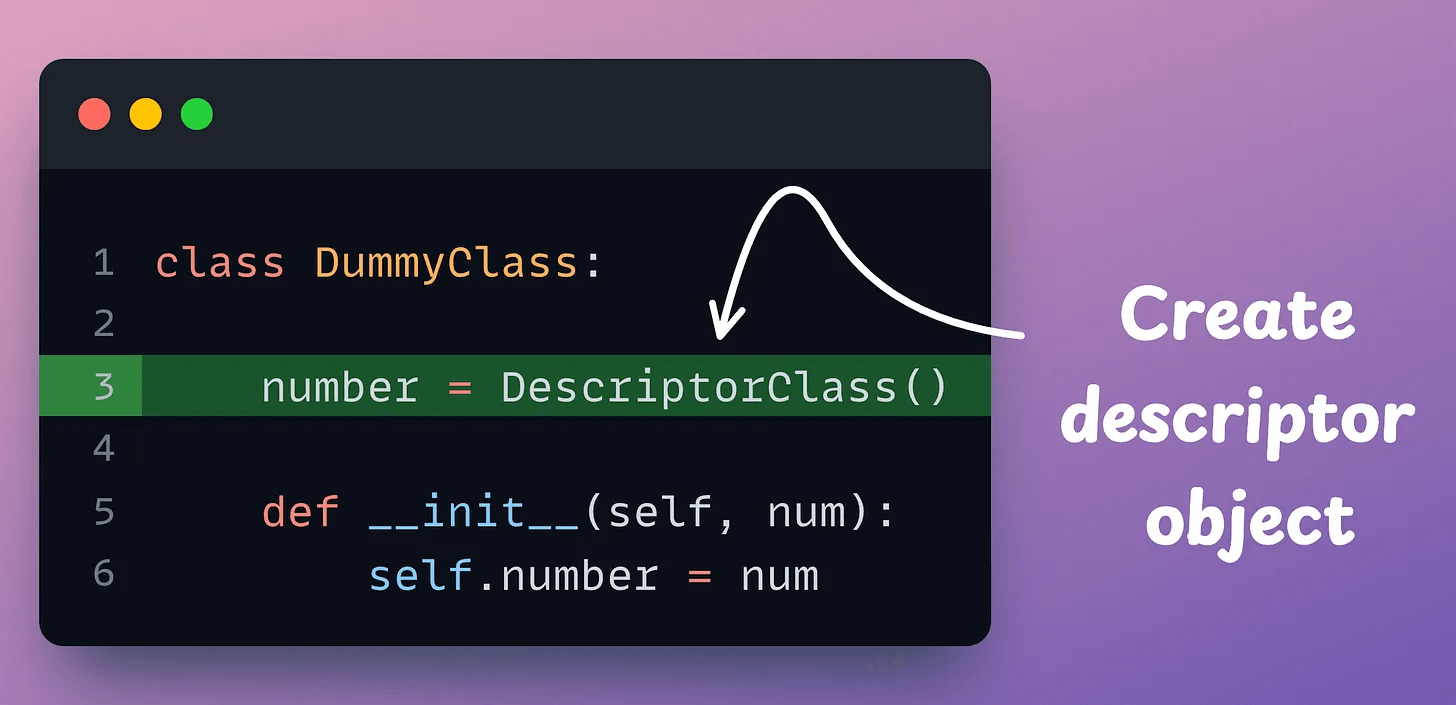
Now, let’s go back to the DescriptorClass implementation:
__set_name__(self, owner, name): This method is called when the descriptor is assigned to a class attribute (line 3). It saves the name of the attribute in the descriptor for later use.__set__(self, instance, value): When a value is assigned to the attribute (line 6), this method is called. It raises an error if the value is negative. Otherwise, it stores the value in the instance’s dictionary under the attribute name we defined earlier.__get__(self, instance, owner): When the attribute is accessed, this method is called. It returns the value from the instance’s dictionary.Done!
Now, see how this solution solves all the problems we discussed earlier.
Creating an object of DummyClass with an invalid value raises an error:

Passing an invalid value during the initialization raises an error as well:

Moving on, let’s define multiple attributes in the DummyClass now:

Creating an object and setting an invalid value for any of the attributes raises an error:

Recall that we never defined multiple getters and setters for each attribute individually, like we did with the @property decorator earlier.
I find descriptors to be massively helpful in reducing work and code redundancy while also making the entire implementation much more elegant.
Here’s a full deep dive into Python OOP if you want to learn more about advanced OOP in Python: Object-Oriented Programming with Python for Data Scientists.
👉 Over to you: What are some cool things you know about Python OOP?
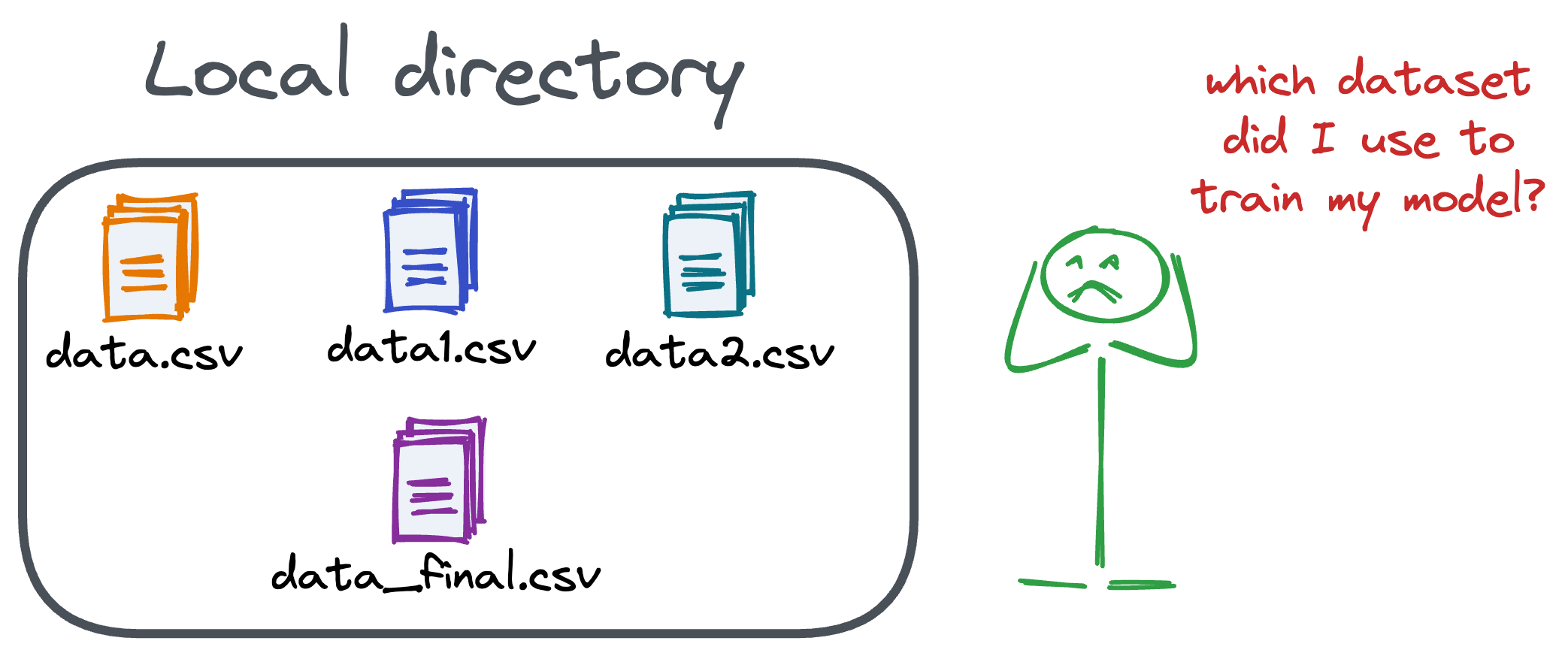
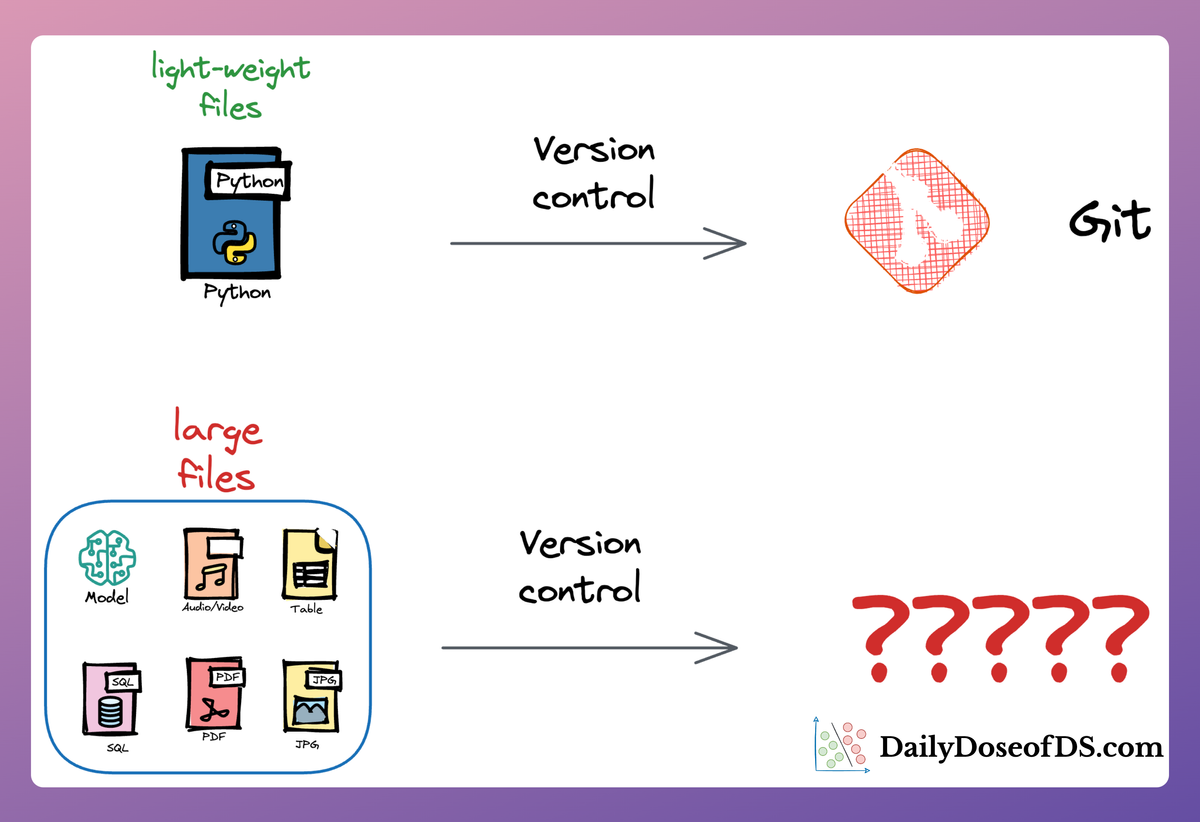
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
That is why Git is best suited for versioning codebase, which is primarily composed of lightweight files.
However, ML projects are not solely driven by code.
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.
Data version control (DVC) solves this problem.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
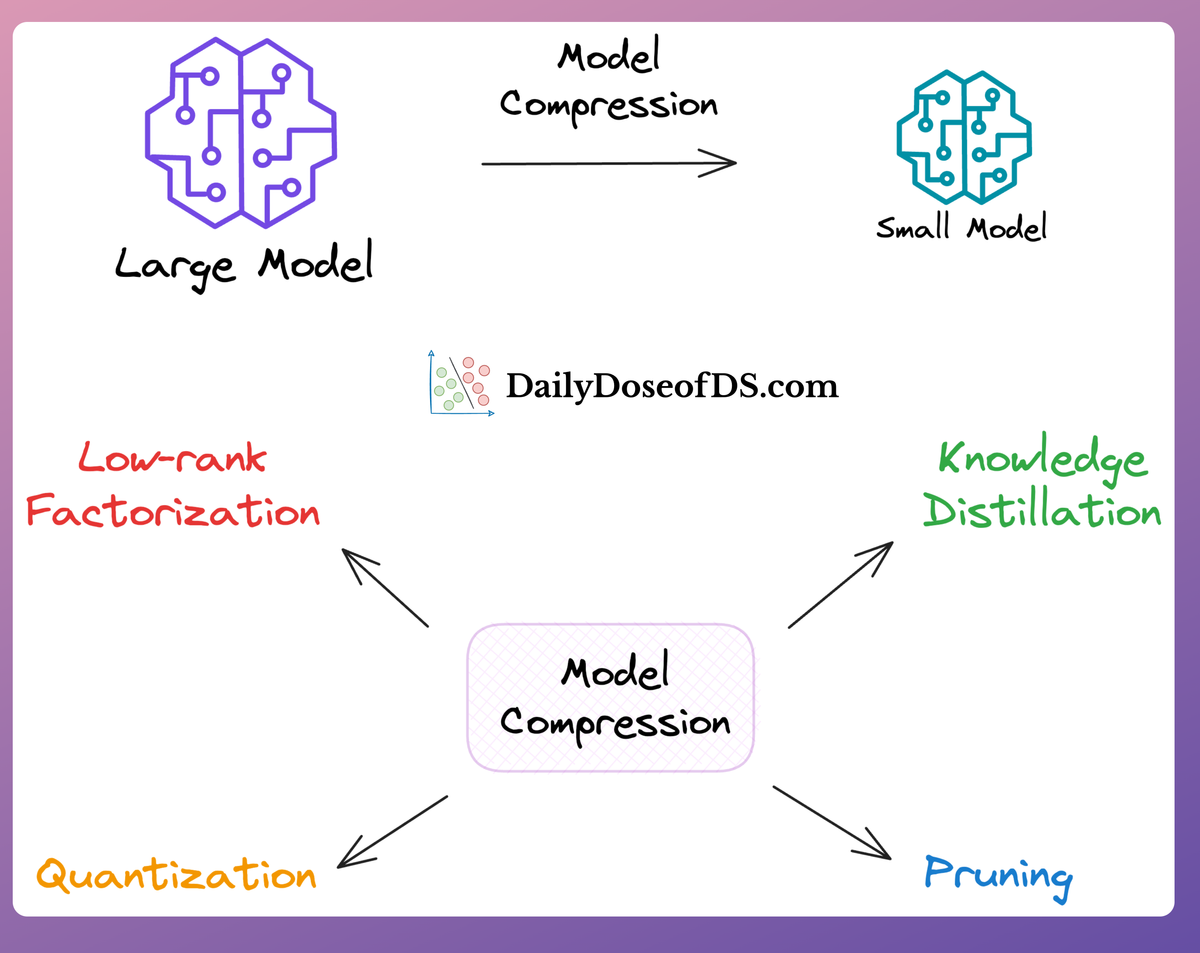
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
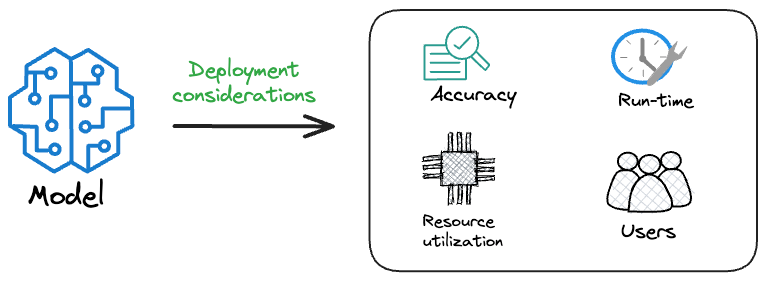
Instead, we also consider several operational and feasibility metrics, such as:
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
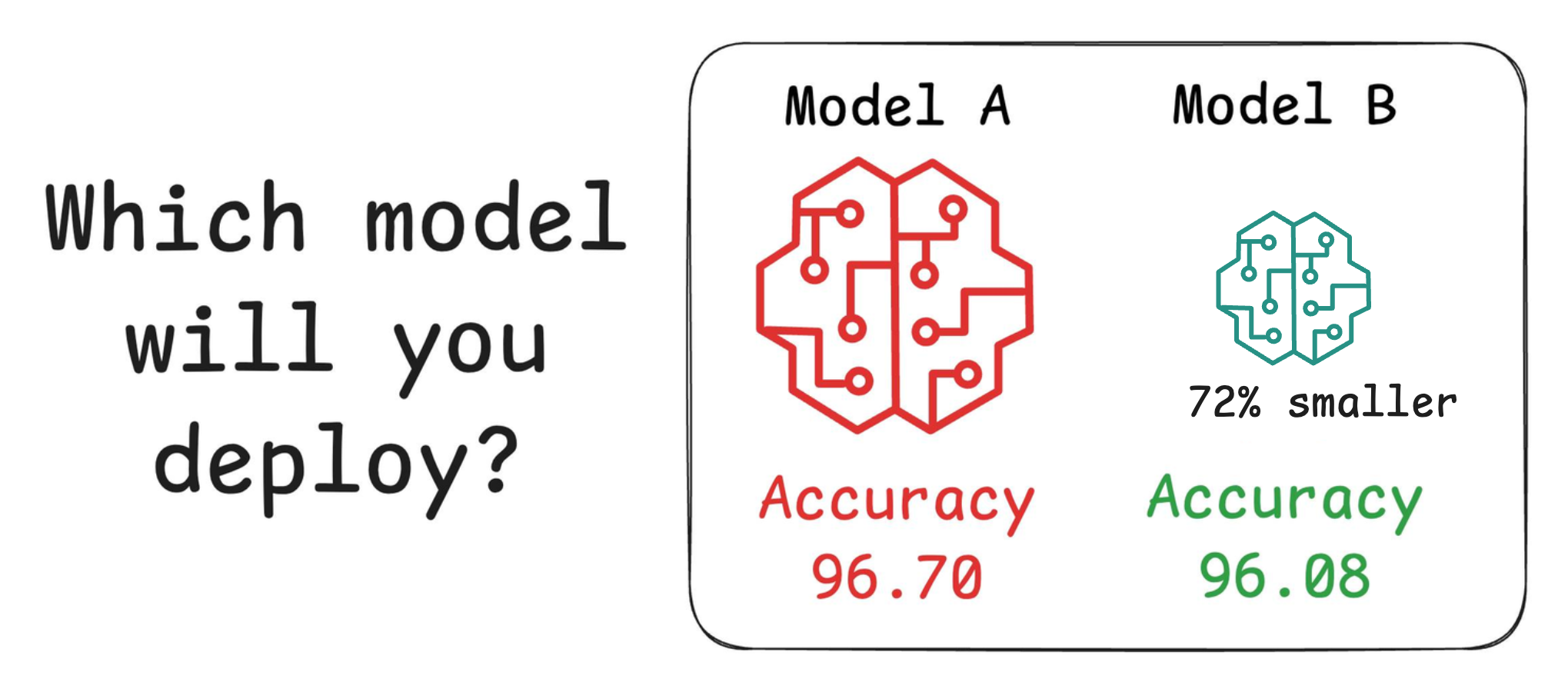
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.