Master Full-Stack AI Engineering, All in One Place
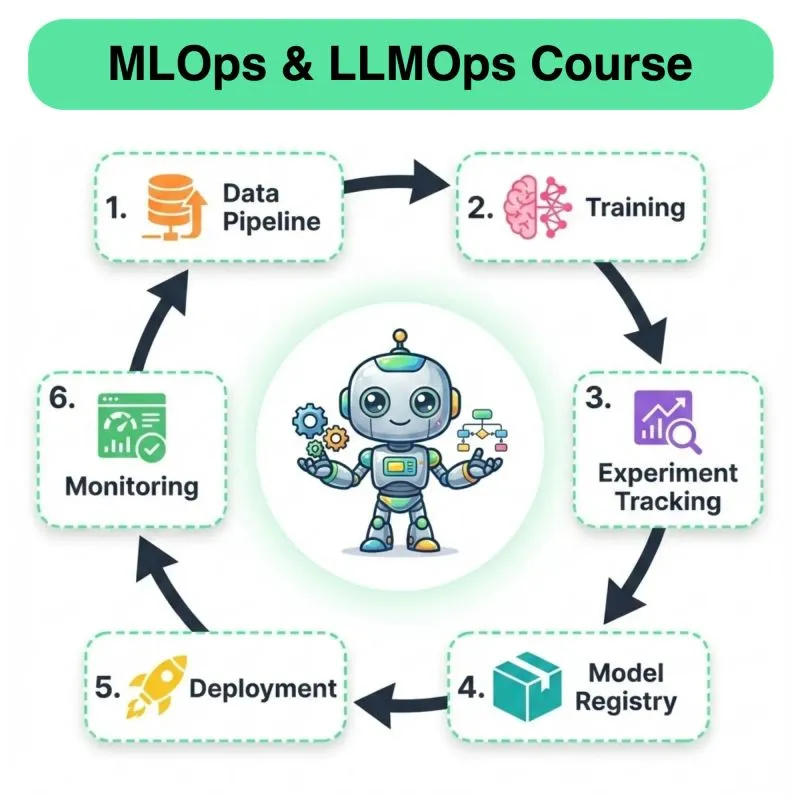
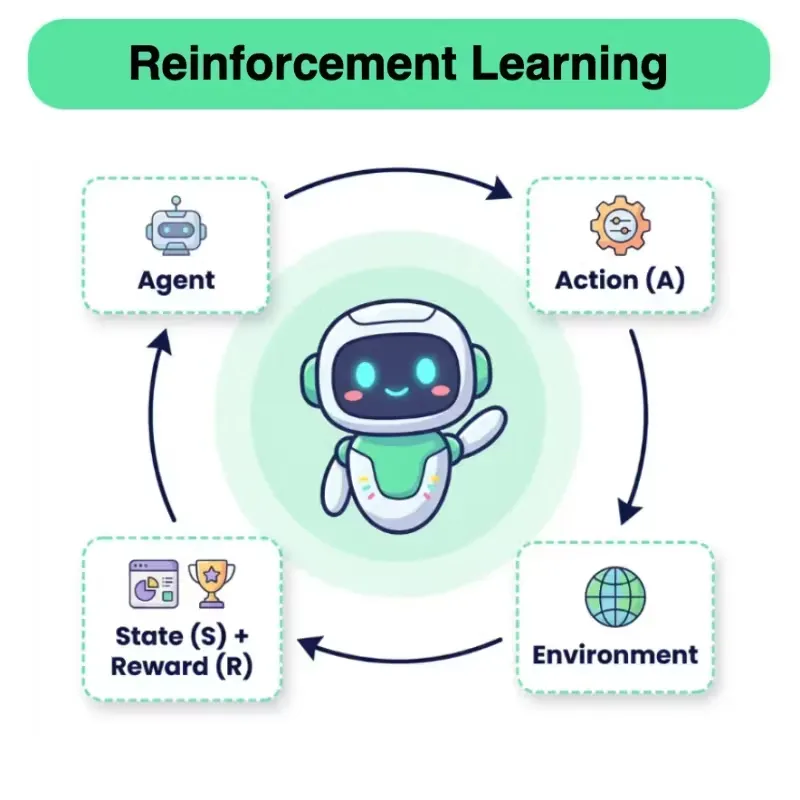
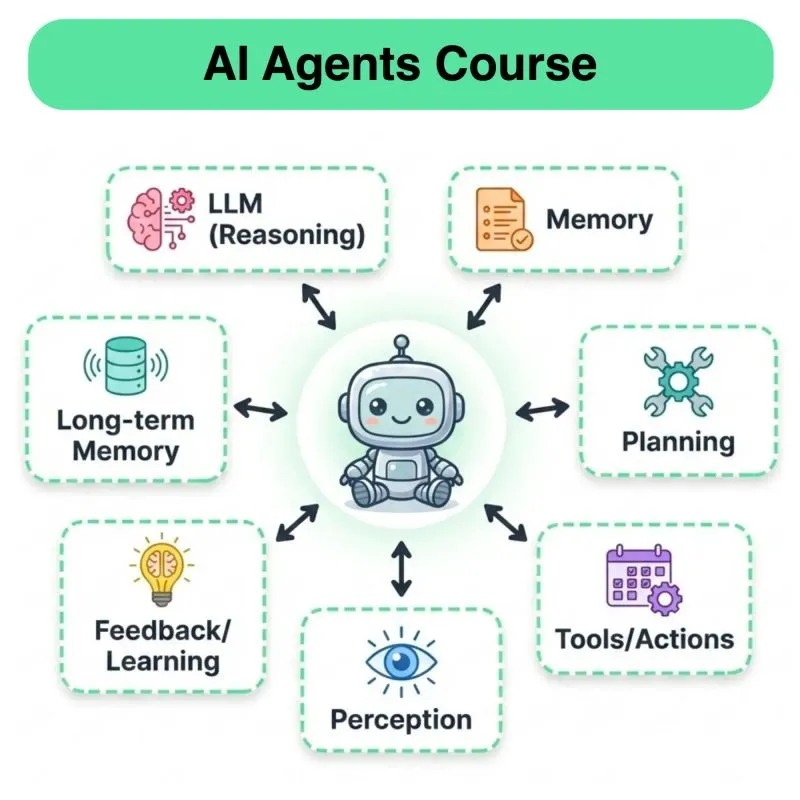
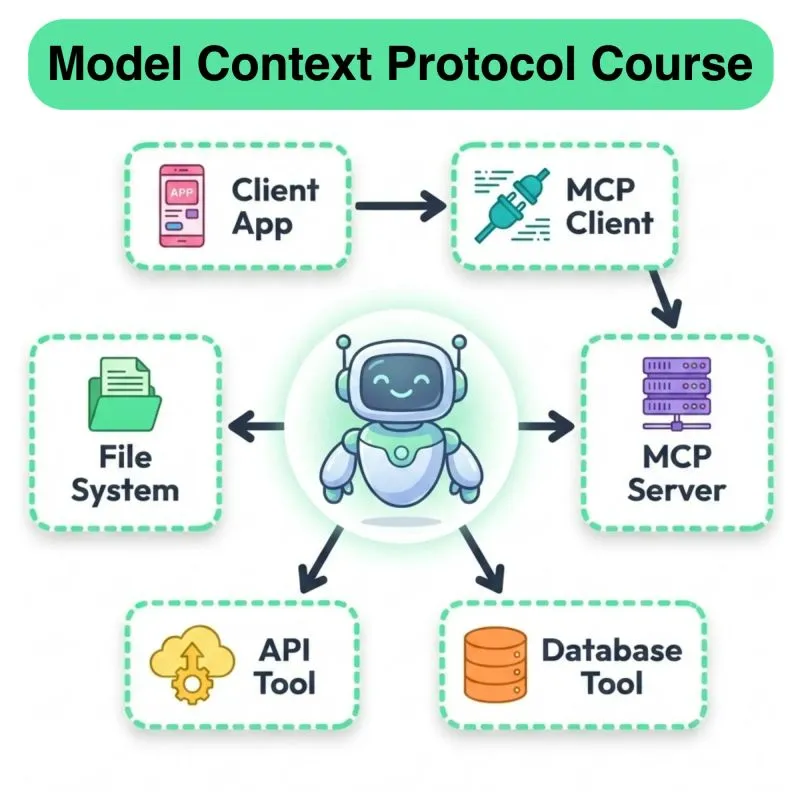
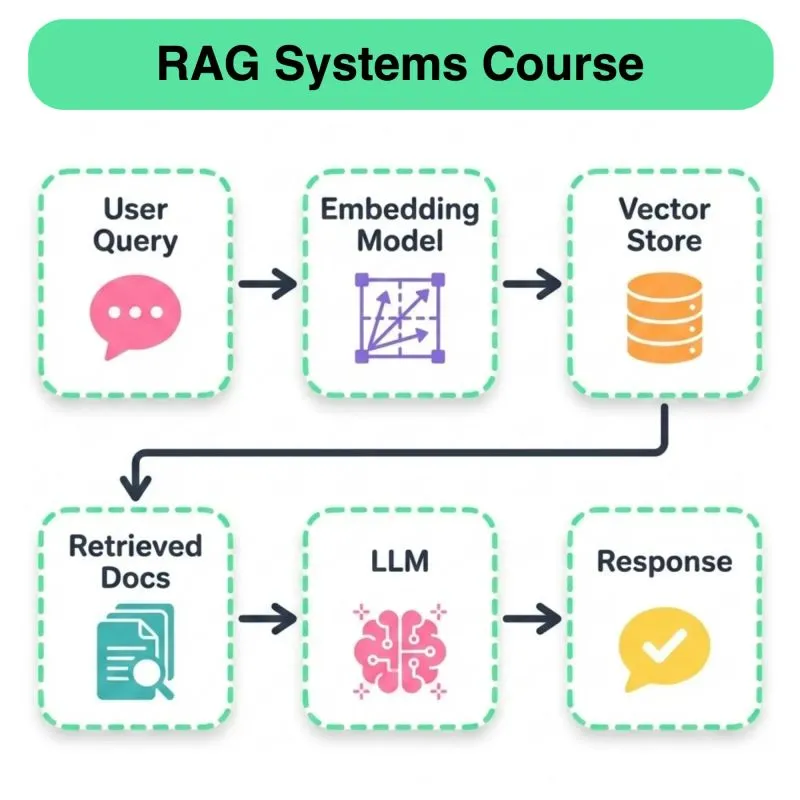
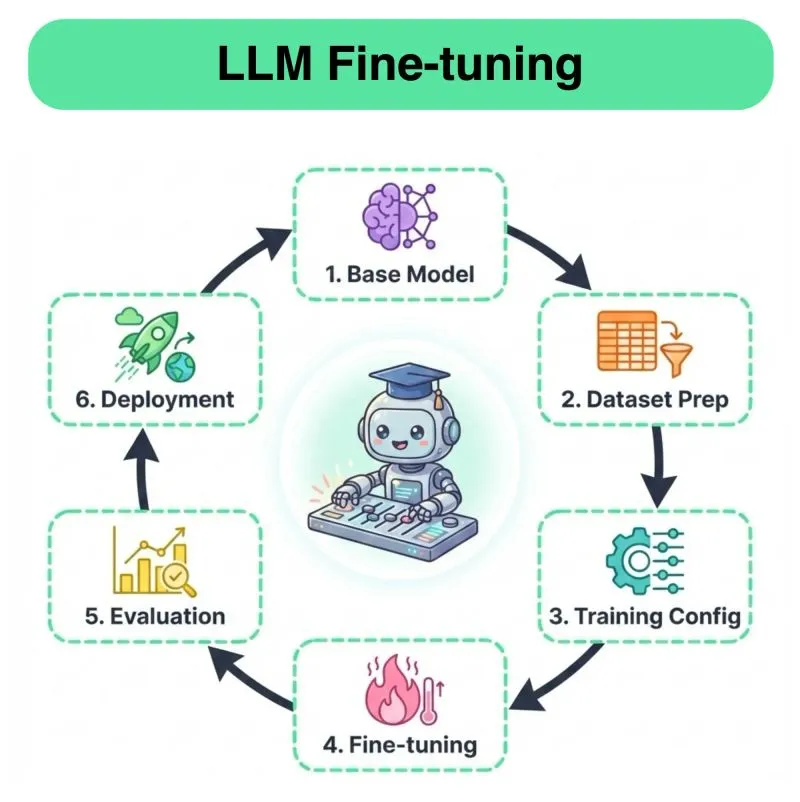
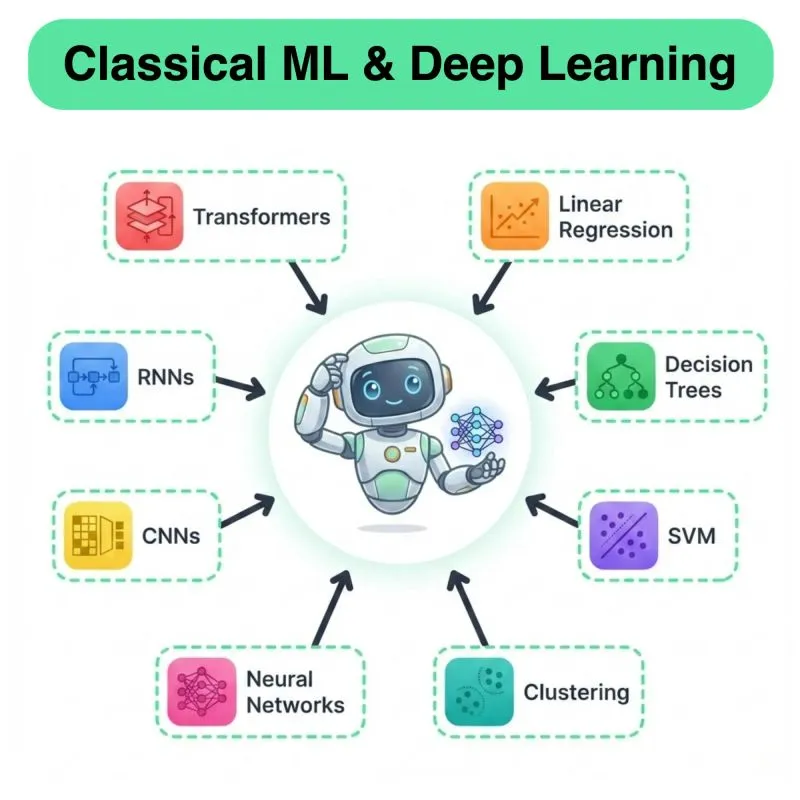
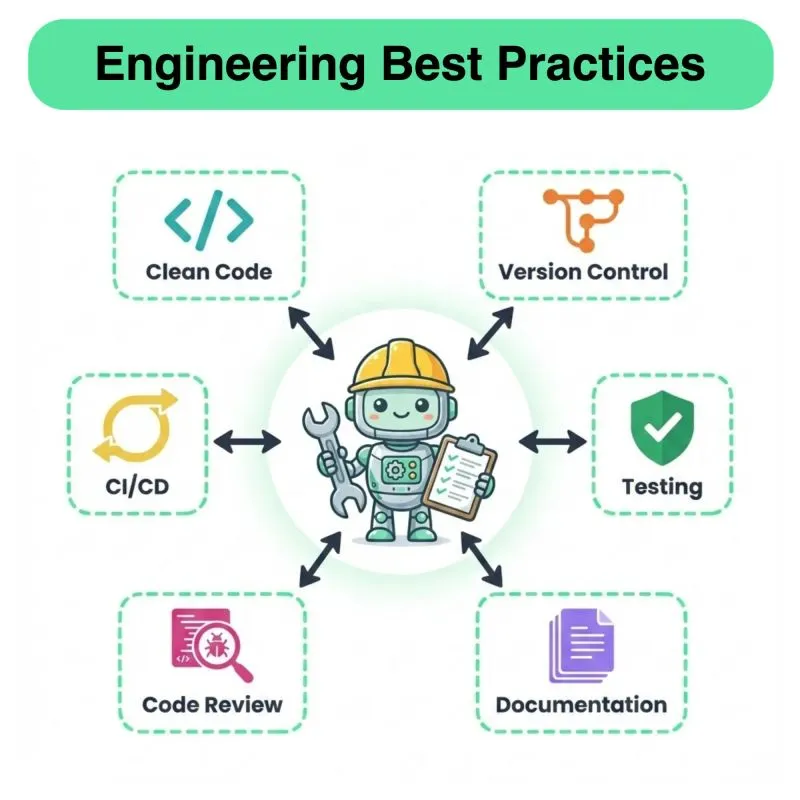
Daily New Content Release
10-day Refund (Lifetime & Yearly)
Personal chat support
Hands-on code-based learning
Intuitive & Visual Explanation
Success Cases

Success Cases


95% of our Subscribers either landed a new job, built their own company or got promoted!

Daily Dose of Data Science has been instrumental in my growth as a Machine Learning Engineer. The solid conceptual foundation I developed through its resources was invaluable during my ML interviews at numerous companies, including Google.
As my go-to resource for continuous learning, it has been key to staying at the forefront of ML research and trends. The resources consistently offer deep insights that sharpen both my understanding and problem-solving mindset.
That's what makes DailyDoseofDS so impactful. It doesn't just teach concepts; it helps you develop an engineer's mindset by bridging the gap between theory and practical creativity. It continues to challenge and inspire me, broadening my perspective on ML algorithms and engineering.


DailyDoseofDS was a game-changer for me. The clarity in the explanations, the practical projects, and the consistency of the content helped me go from just consuming theory to applying data science in real-world scenarios.
Thanks to the resources, I built a strong portfolio, which was instrumental in securing my role as a Senior Data Scientist at RedHat. The value I got from this platform far exceeded any course I've taken.


DailyDoseofDS took me from zero to a hired Senior Principal AI/ML Engineer (GenAI).
The clear path from LLM basics to advanced Agent frameworks was exactly what I needed.
I built a Retrieval-Augmented Generation (RAG) agent based on a project from the course, allowing me to go from theory to implementation in under three months.
The resources are practical, relevant, and directly tied to the skills employers are looking for right now.


DailyDoseofDS played a pivotal role in my preparation journey.
The clear explanations, structured practice problems, and case-study guidance directly helped me succeed in my PayPal interviews and secure a job as a Senior Data Scientist.
Beyond technical upskilling, the resources gave me clarity on how to approach product data science problems and communicate my solutions effectively, skills that proved invaluable in securing the role.


Before I found the Daily Dose of Data Science, the leap to Senior Agentic AI Architect felt daunting.
My challenge wasn't understanding LLMs but architecting production-grade, multi-agent systems at scale. The in-depth articles on MLOps for LLMs and the breakdown of Vector Database strategies and RAG series were invaluable.
They provided the exact, tangible blueprints I used to answer complex interview questions and confidently design the initial system for my new role at Accenture.


Daily Dose of Data Science has been instrumental in helping me transition from a GIS Analyst to a Lead Data Scientist at S&P Global.
Since early 2023, it's been part of my daily learning routine since the resources are practical, and easy to follow, making even complex ML and AI topics approachable.
This consistent exposure not only strengthened my technical foundation but also gave me the confidence to lead projects and mentor others.
The tutorials and deep dives often act as a springboard for me to explore new ideas at work, and many concepts I first discovered through Daily Dose have directly influenced my team's delivery. It's one of the few resources I trust to keep me sharp and relevant in this fast-evolving field.


Over the past two years, DailyDoseofDS has been one of the most valuable parts of my learning journey.
Those lessons directly contributed to my growth and helped me step into my current role as VP Engineering at Walmart, where I lead teams building and deploying data-driven solutions. The deep dives into AI/ML didn't just sharpen my technical foundation but also expanded the way I think about AI strategically.
What I love most is that everything goes beyond theory by bridging complex AI/ML concepts with real-world applications I can bring into discussions and decision-making.
As an executive, that connection between depth and practicality has been a game-changer, helping me guide technical teams with more clarity and confidence. The recent pieces on Agentic AI have been especially powerful. They've helped me stay ahead of the curve and think more intentionally about how we adapt as this AI landscape evolves so rapidly.


Daily Dose of Data Science played a pivotal role in helping me lead my company's transition to becoming AI-native. As a Senior Director of Engineering, I was tasked with driving our AI initiatives from the ground up.
The deep dives on MCP, AI Agents, and modern deployment architectures gave me the technical clarity and strategic perspective I needed to make that shift.
What stood out to me was how practical the content was; every post connected emerging AI technologies with real-world engineering use cases. It helped me not just understand these systems conceptually, but also communicate their business value effectively to leadership and engineering teams.
The insights I gained directly shaped how we built our internal AI roadmap, selected our stack, and trained our teams for this transformation.
