Graph Neural Networks Part 3 (Implementation Included)
A practical and beginner-friendly guide to building neural networks on graph data.
Introduction
We covered several details about graph learning with graph neural networks in the first part of this crash course.
In the second part, we went into more detail about graph neural networks, understood the limitations of the methods covered in part 1, and finally, we discussed many of the advancements that helped us build more robust graph neural network models, like graph attention networks and some of its variants.
But towards the end, we also observed the challenges associated with training attention-driven models.
More specifically, given the scale of typical graph datasets, which can contain millions of nodes and edges, the slow and inefficient training processes of graph attention networks make these models impractical for large-scale applications.
This became evident from the time it took to train the attention-drive model, shown again below:
From the above training logs, it is clear that while attention-based graph networks take much longer to train, they are typically significantly more powerful than the standard and naive GCN model we discussed in Part 1.
This enhanced performance is primarily attributed to the attention mechanism, which enables the model to dynamically gather and integrate information from neighboring nodes, thereby forming more robust node representations.
Assuming you have already read Part 1 and Part 2, let's proceed with Part 3.
GraphSAGE
GraphSAGE (short for Graph Sample and AggregatE) is an approach designed to address the scalability issues faced by traditional graph neural networks, such as the ones discussed earlier.
Unlike previous methods that operate on the entire graph structure at once, GraphSAGE introduces an inductive learning framework that allows the model to generate node embeddings for unseen nodes during inference, making it particularly useful for dynamic and large-scale graphs.
More specifically, one of the key challenges with the GNN models we discussed earlier, such as GCNs and attention-driven models, is their reliance on the entire graph during training.
Recall that:
- In the case of GCNs, we aggregate information from our neighboring nodes to form the central node representation:
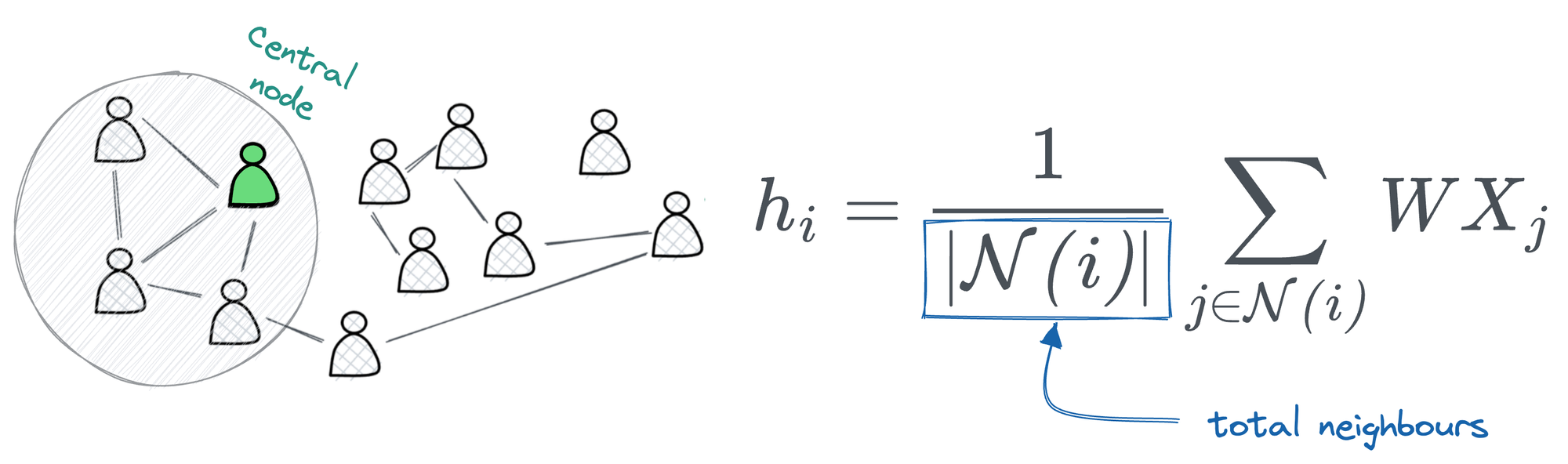
- And in the case of attention-based graph networks, we do the same thing as above, but an additional weighing factor is also added during aggregation, as depicted below:
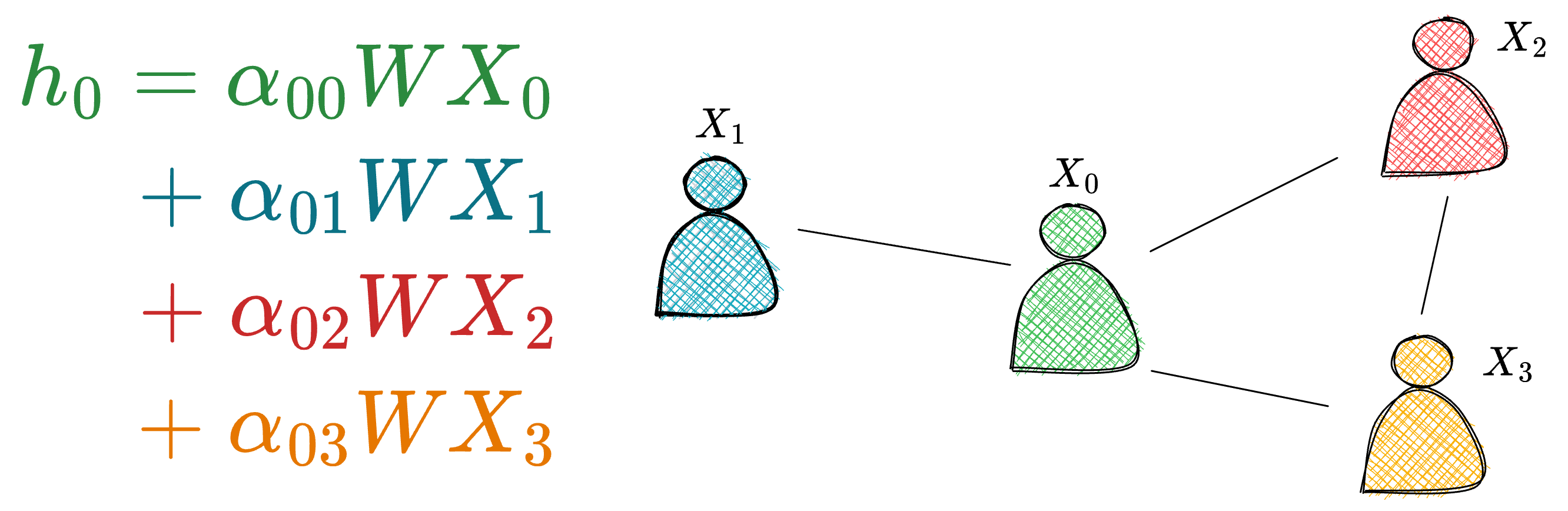
Computing attention scores is an expensive operation, as we just saw above and in Part 2 as well. Thus, it not only increases memory consumption but also limits their applicability to massive graphs where training on the full graph becomes computationally infeasible.
GraphSAGE addresses this problem.
In a gist (and as suggested by the name—Graph Sample and AggregatE), the idea is to sample a fixed-sized neighborhood of nodes during training, significantly reducing the computational load and making it possible to train on much larger graphs.
Let's dive in and also get into the implementation-related details.