LLMs
Run LLMs Locally with Ollama
A step-by-step hands-on guide.

Avi Chawla
A step-by-step hands-on guide.

TODAY'S ISSUE
It's easier to run an open-source LLM locally than most people think.
Today, let's cover a step-by-step, hands-on demo of this.
Here's what the final outcome looks like:
We'll run Microsoft's phi-2 using Ollama, a framework to run open-source LLMs (Llama2, Llama3, and many more) directly from a local machine.
On a side note, we started a beginner-friendly crash course on RAGs recently with implementations. Read the first two parts here:
Let's begin!
Go to Ollama.com, download Ollama, and install it.

Ollama supports several open-source models (listed here). Here are some of them, along with the command to download them:
Next, download phi-2 by running the following command:
Expect the following in your terminal:
Done!
An open-source LLM is now running on your local machine, and you can prompt it as follows:
Models running from Ollama can be customized with a prompt. Let's say you want to customize phi-2 to talk like Mario.
Make a copy of the existing modelfile:
Next, open the new file and edit the PROMPT setting:
Next, create your custom model as follows:
Done!
Now run the mario model:
Using an LLM locally was simple, wasn't it?
That said, Ollama elegantly integrates with almost all LLM orchestration frameworks like LlamaIndex, Langchain, etc., which makes it easier to build LLM apps on open-source LLMs.
We have been using them in our beginner-friendly crash course on building RAG systems. Read the first two parts here:
👉 Over to you: What are some ways to run LLMs locally?
Modern neural networks being trained today are highly misleading.
They appear to be heavily overconfident in their predictions.
For instance, if a model predicts an event with a 70% probability, then ideally, out of 100 such predictions, approximately 70 should result in the event occurring.
However, many experiments have revealed that modern neural networks appear to be losing this ability, as depicted below:
Calibration solves this.
A model is calibrated if the predicted probabilities align with the actual outcomes.
Handling this is important because the model will be used in decision-making and an overly confident can be fatal.
To exemplify, say a government hospital wants to conduct an expensive medical test on patients.
To ensure that the govt. funding is used optimally, a reliable probability estimate can help the doctors make this decision.
If the model isn't calibrated, it will produce overly confident predictions.
There has been a rising concern in the industry about ensuring that our machine learning models communicate their confidence effectively.
Thus, being able to detect miscalibration and fix is a super skill one can possess.
Learn how to build well-calibrated models in this crash course →
Lately, I have been experimenting with Lightning Fabric, which brings together:
In a recent issue, I covered the four small changes you can make to your existing PyTorch code to easily scale it to the largest billion-parameter models/LLMs.
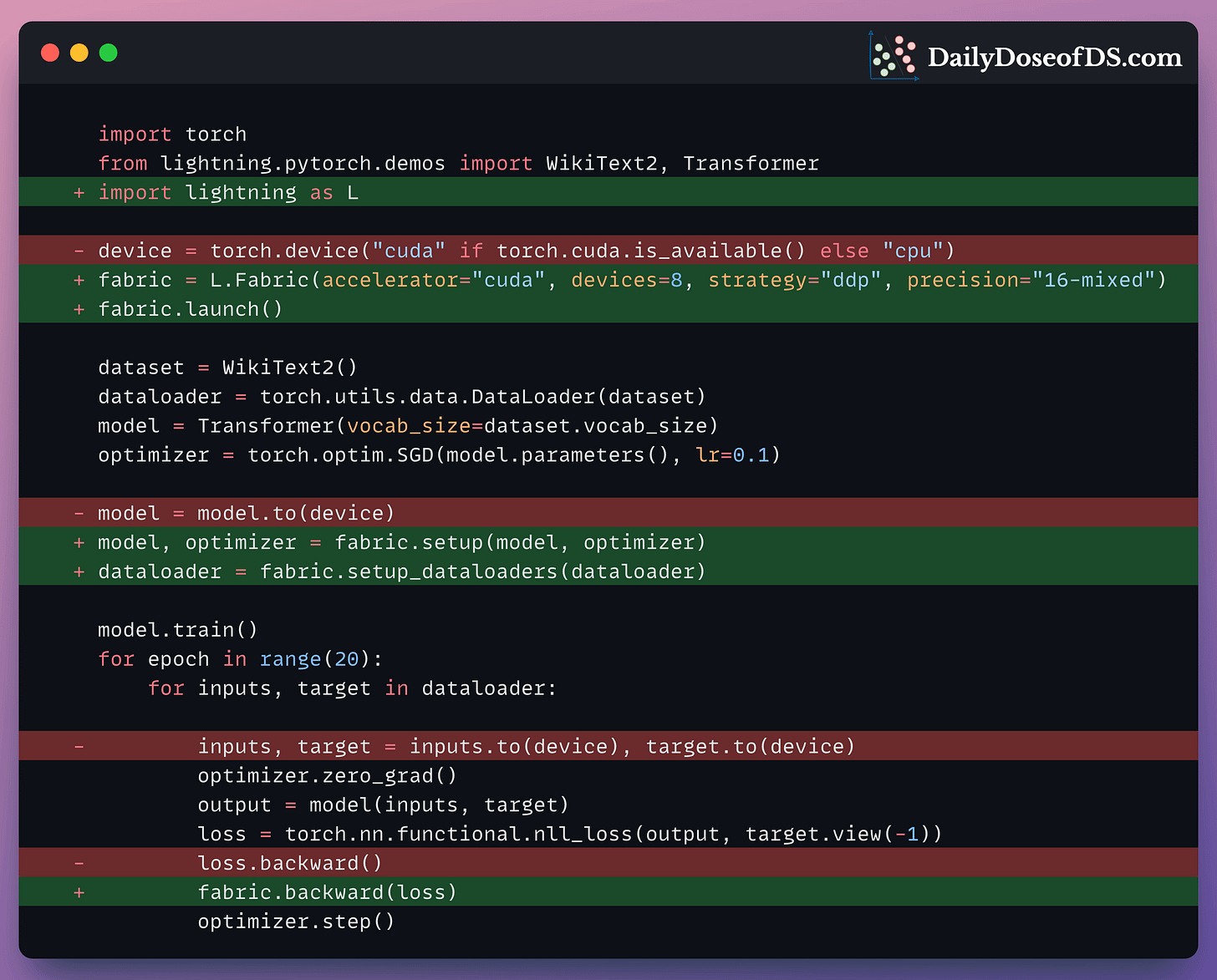
Learn how to integrate PyTorch Fabric in PyTorch code here →