Correlation Analysis
How to Assess Correlation on Ordinal Data?
The limitations of Pearson correlation.

Avi Chawla
The limitations of Pearson correlation.

TODAY'S ISSUE
If your correlation analysis includes ordinal features (those with a natural encoding, like t-shirt size, grade, etc.)...
...the choice of encoding can largely affect the correlation results.
For instance, consider this dataset.
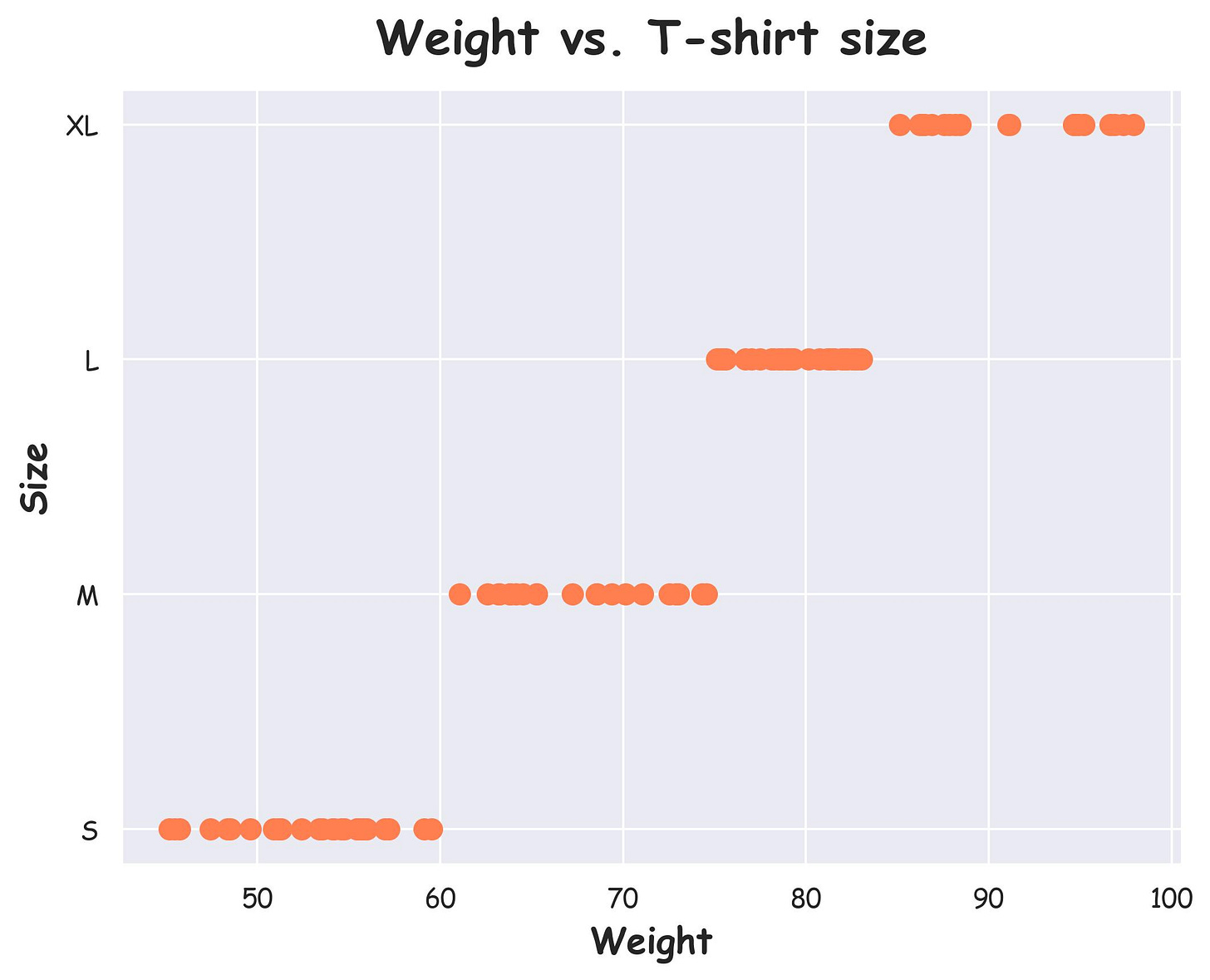
Here, we have:
The graph above shows a monotonic relationship between the two features.
If we use Pearson correlation (as shown below), the choice of encoding determines the actual correlation value:
However, using Spearman correlation solves this issue:
This time, the correlation value is the same.
This happens because the Spearman correlation is rank-based.
In other words, since it operates on the “ranks” of the data, it is more suitable for such cases of correlation analysis.
Using Spearman correlation is pretty simple. If you are using Pandas, specify the desired correlation measure as follows:
That said, there’s one more thing to take care of when you are training ML models to predict ordinal categorical data.
Ordinal datasets are quite prevalent in the industry, and typical classification models almost always produce suboptimal results in such cases.
With special attention and techniques, however, one can not only add more interpretability to ML models but also produce more accurate machine learning models.
We covered them in detail here: You Are Probably Building Inconsistent Classification Models Without Even Realizing.
👉 Over to you: What are some other measures to determine the correlation between categorical data and continuous data?
Conformal prediction has gained quite traction in recent years, which is evident from the Google trends results:
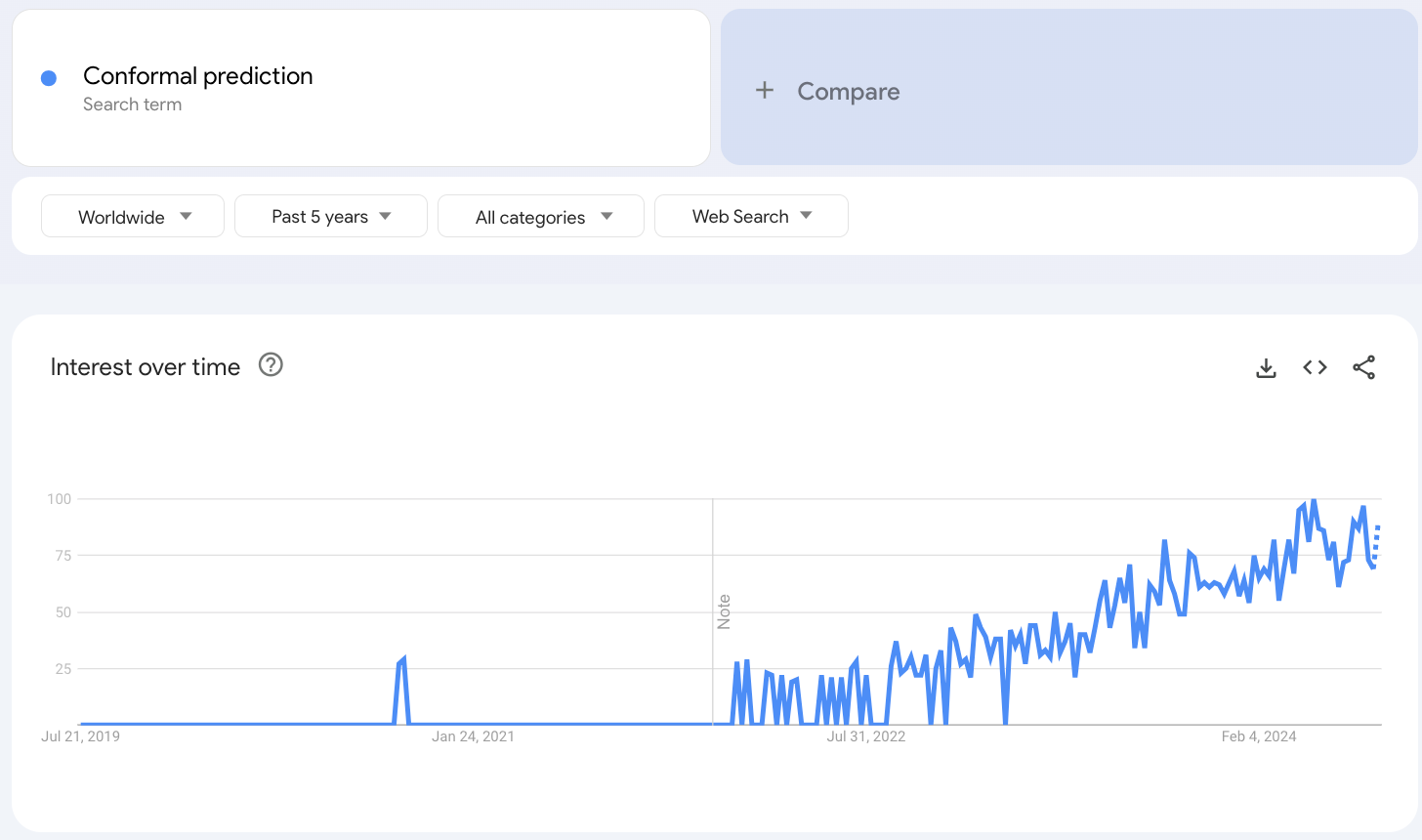
The reason is quite obvious.
ML models are becoming increasingly democratized lately. However, not everyone can inspect its predictions, like doctors or financial professionals.
Thus, it is the responsibility of the ML team to provide a handy (and layman-oriented) way to communicate the risk with the prediction.
For instance, if you are a doctor and you get this MRI, an output from the model that suggests that the person is normal and doesn’t need any treatment is likely pretty unuseful to you.
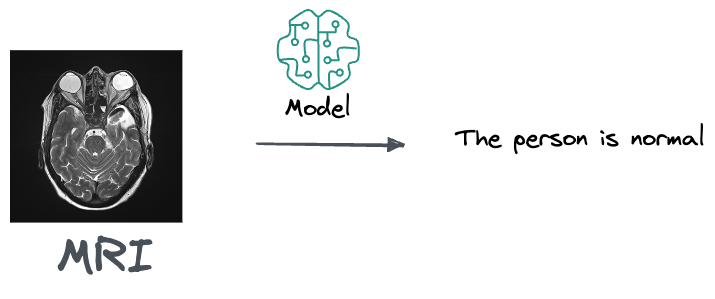
This is because a doctor's job is to do a differential diagnosis. Thus, what they really care about is knowing if there's a 10% percent chance that that person has cancer or 80%, based on that MRI.
Conformal predictions solve this problem.
A somewhat tricky thing about conformal prediction is that it requires a slight shift in making decisions based on model outputs.
Nonetheless, this field is definitely something I would recommend keeping an eye on, no matter where you are in your ML career.
Learn how to practically leverage conformal predictions in your model →
It's easier to run an open-source LLM locally than most people think.
Recently, we covered a step-by-step, hands-on demo of this using Ollama.
Here's what the final outcome looks like:
We ran Microsoft's phi-2 using Ollama, a framework to run open-source LLMs (Llama2, Llama3, and many more) directly from a local machine.