LLMs
Building a Real-time Voice RAG Agent
..explained with step-by-step code.

Avi Chawla
..explained with step-by-step code.

TODAY'S ISSUE
Typing to interact with AI applications can be a bit tedious and boring.
That is why real-time voice interactions will become more and more popular going ahead.
Today, let us show you how we built a real-time Voice RAG Agent, step-by-step.
Here’s an overview of what the app does:
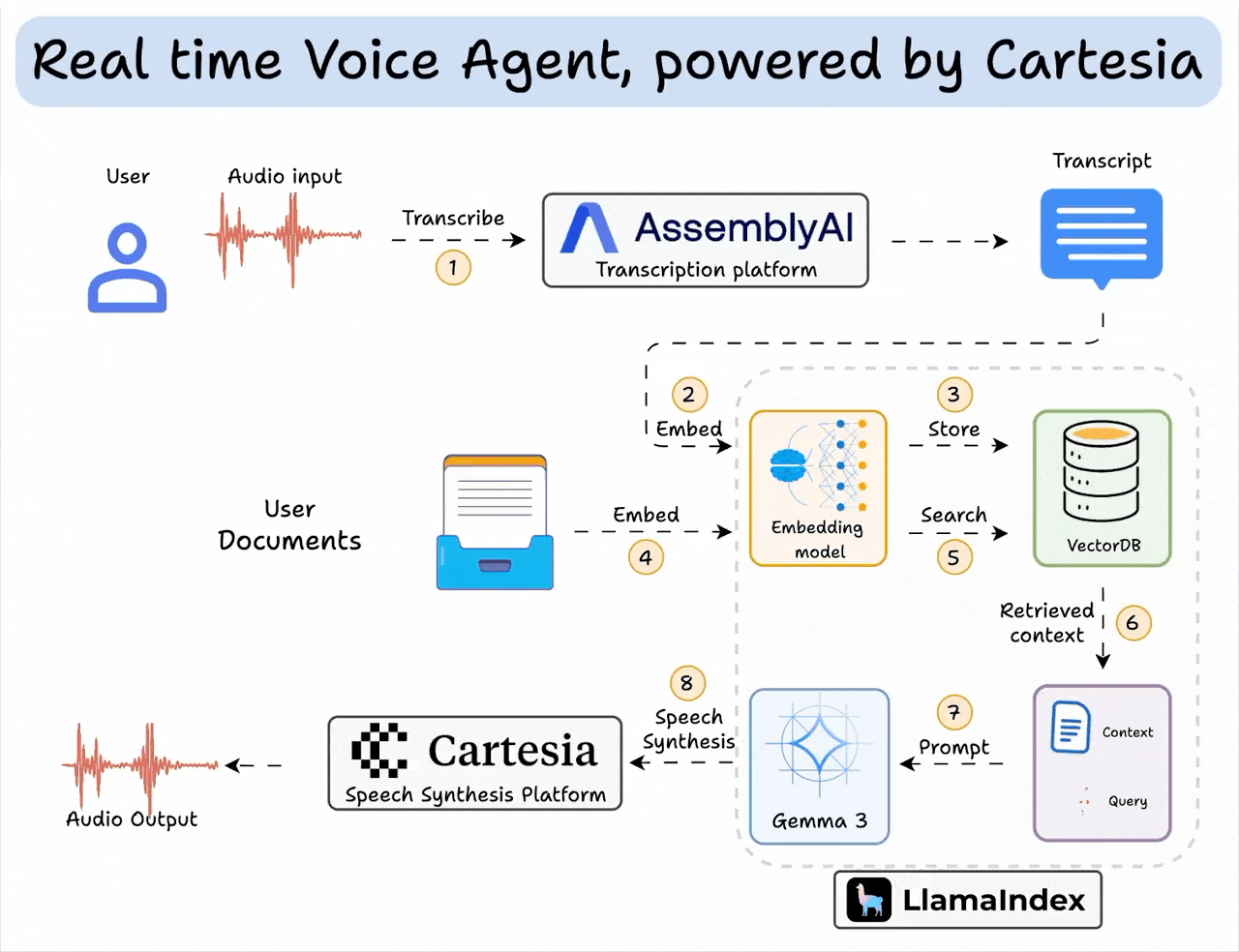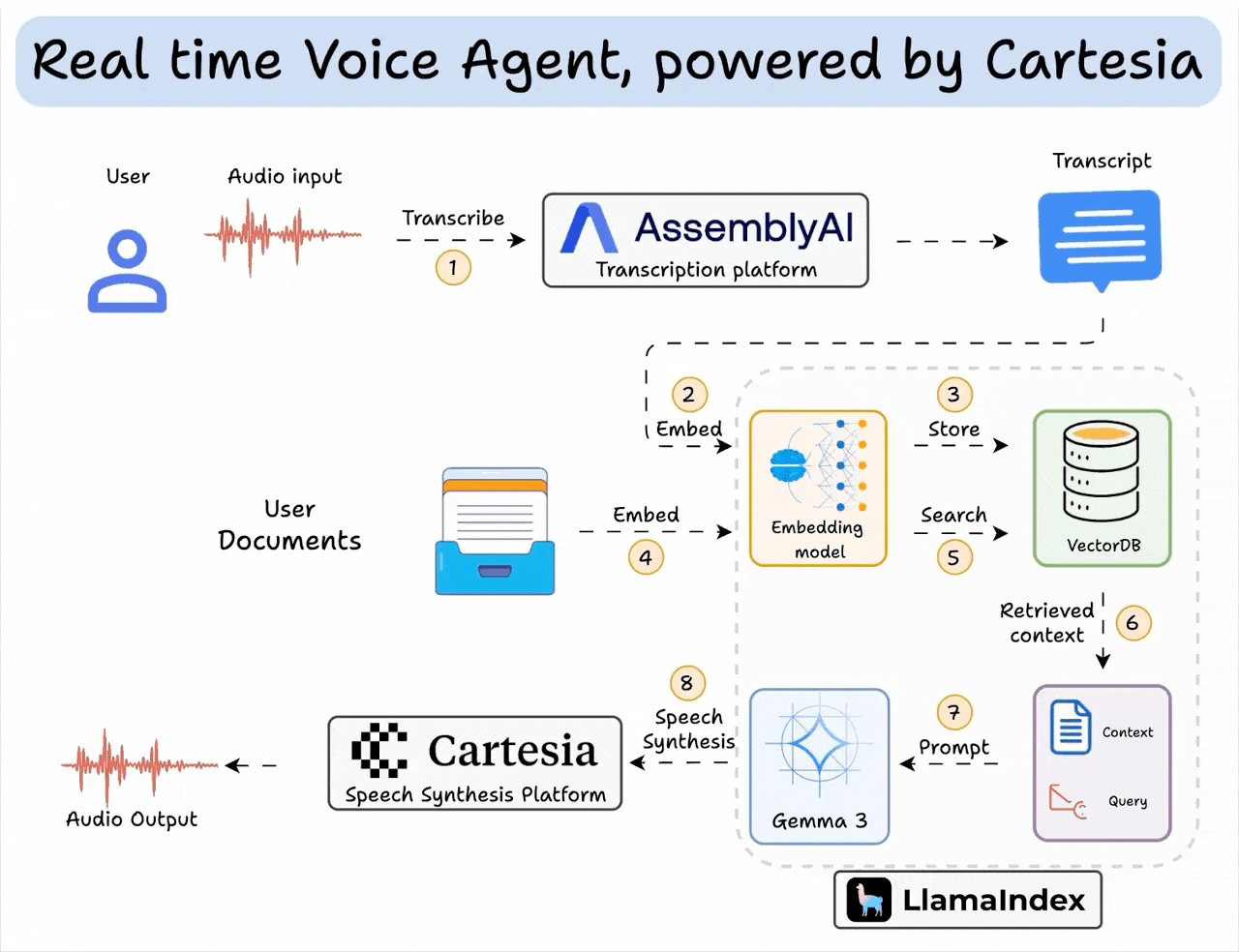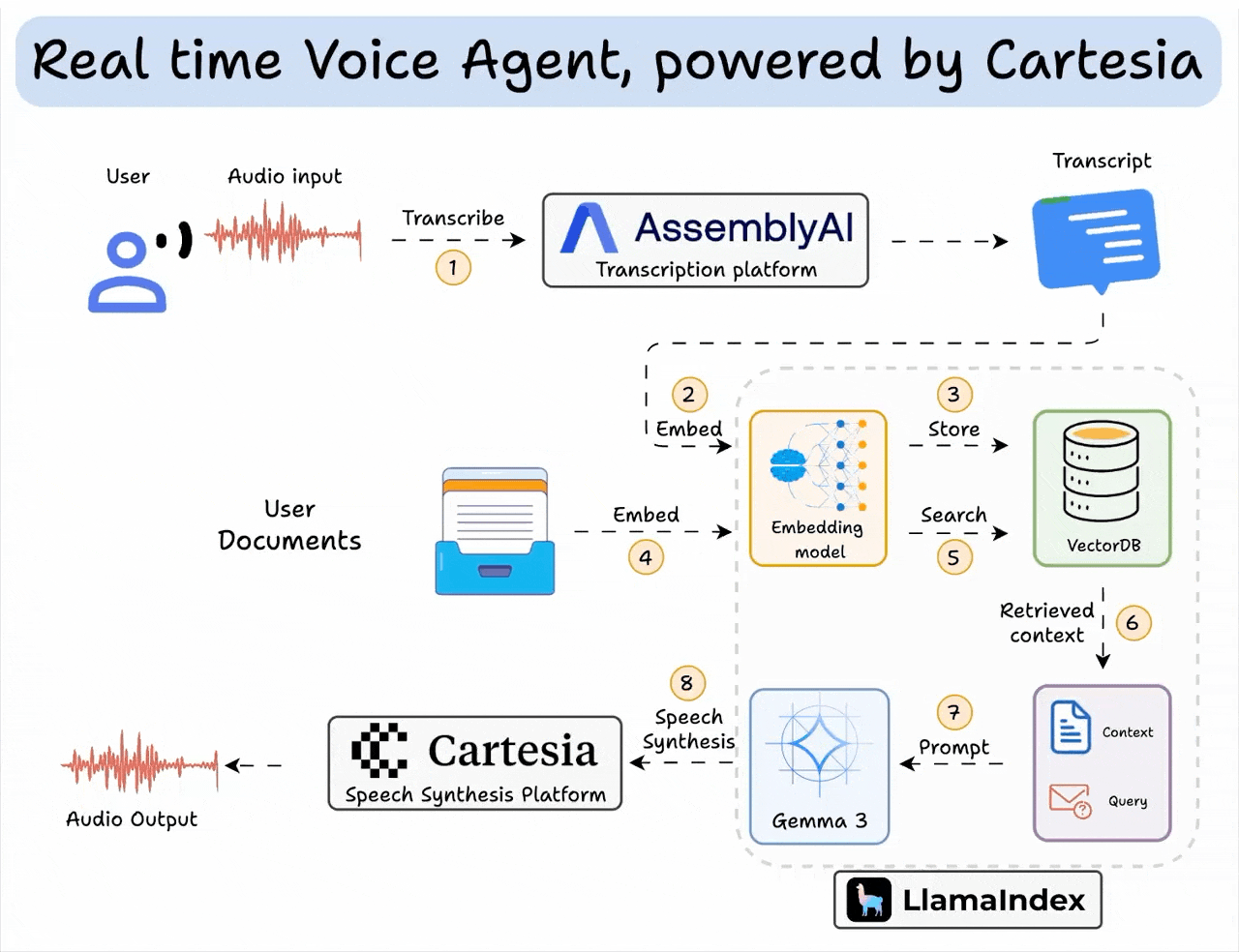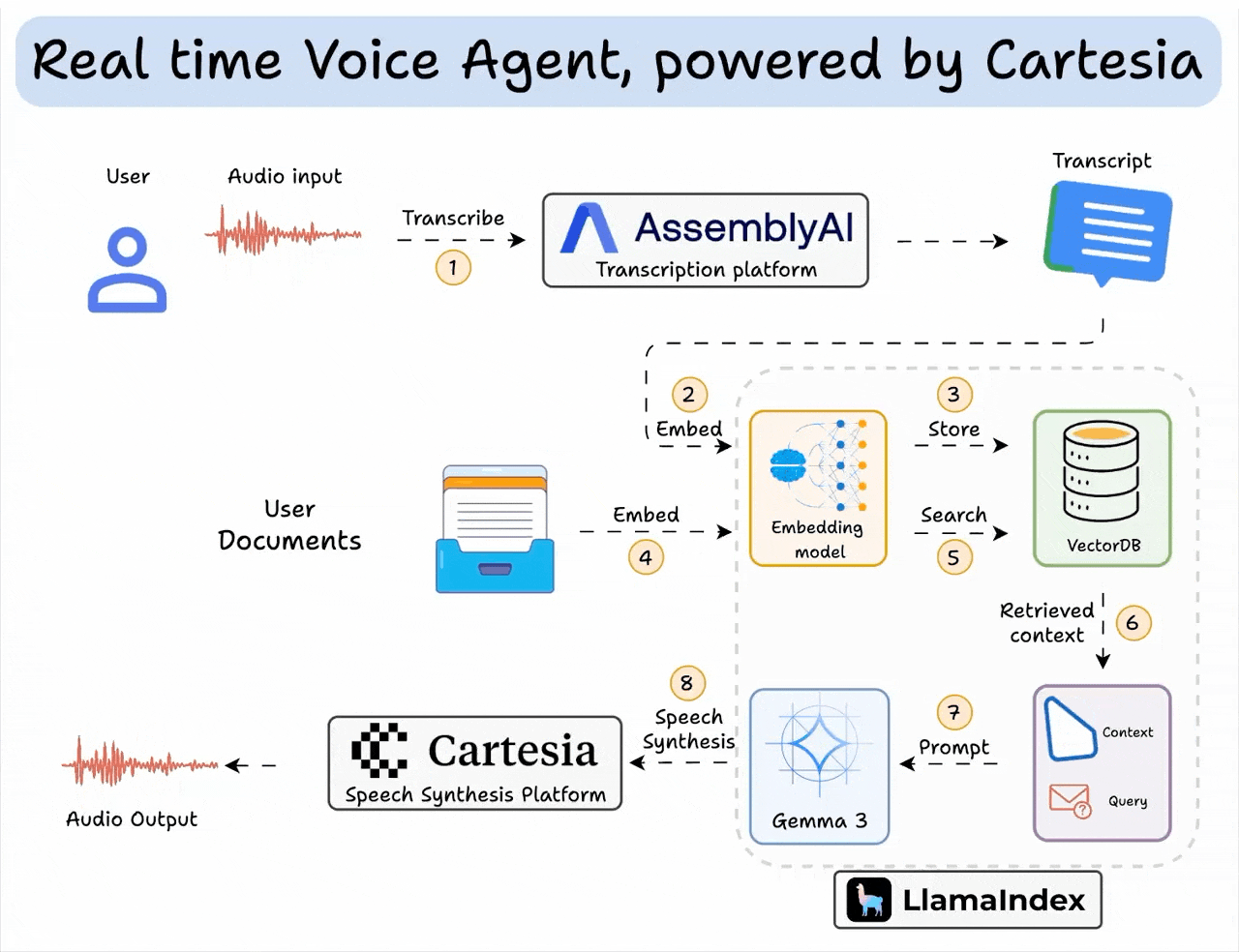
The code is provided later in the article. Also, if you’d like, we have added a video below if you want to see this in action:
Now let's jump into code!
Now let's jump into code!
This ensures we can load configurations from .env and keep track of everything in real-time.
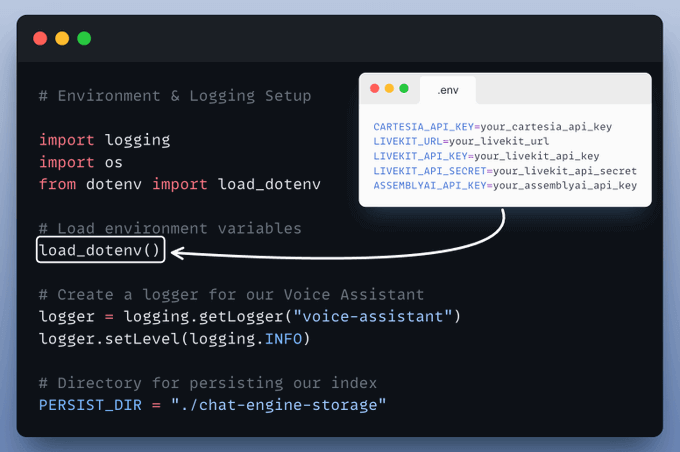
This is where your documents get indexed for search and retrieval, powered by LlamaIndex.
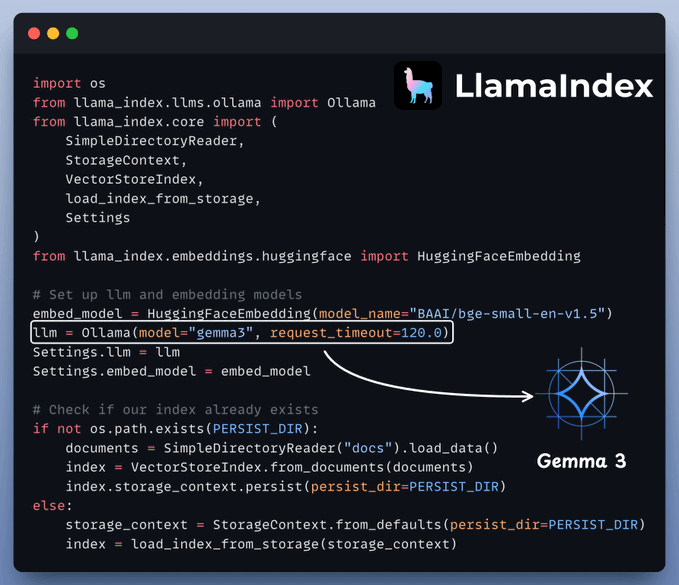
The Agent’s answer would be grounded to this knowledge base.
We also want Voice Activity Detection (VAD) for a smooth real-time experience—so we’ll “prewarm” the Silero VAD model.
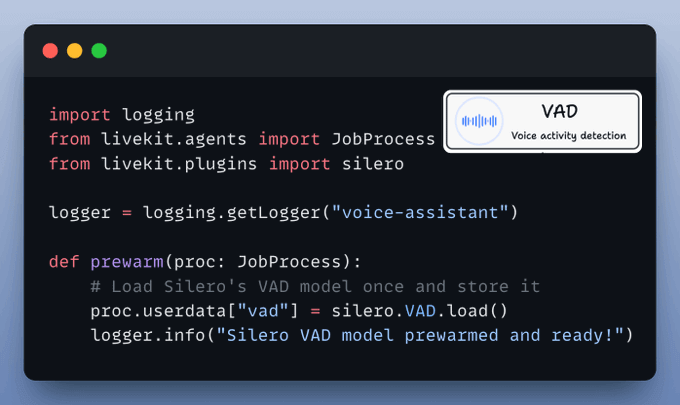
This helps us detect when someone is actually speaking.
This is where we bring it all together. The agent:
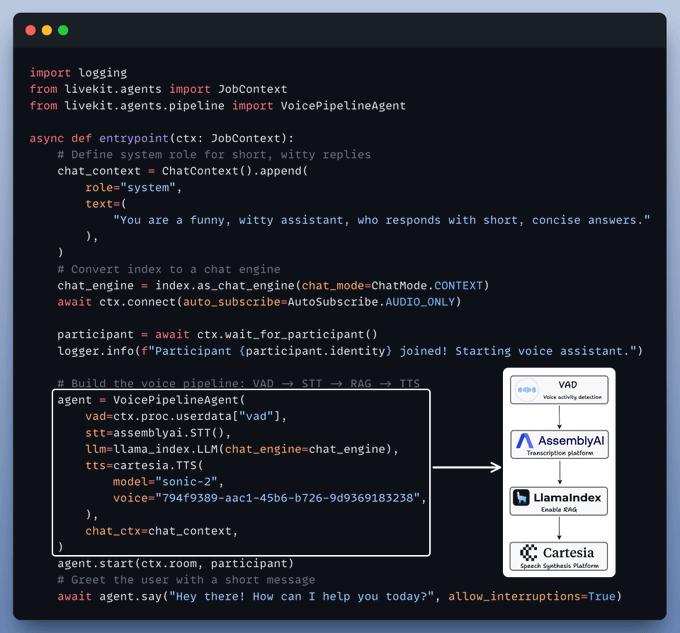
Finally, we tie it all together. We run our agent with specifying the prewarm function and main entry point.

That’s it—your Real-Time Voice RAG Agent is ready to roll!
We added a video at the top if you want to see this in action!
The entire code is 100% open-source and available in this GitHub repo →
There’s so much data on your mobile phone right now — images, text messages, etc.
And this is just about one user—you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
The problem?
This data is private.
So consolidating this data into a single place to train a model.
The solution?
Federated learning is a smart way to address this challenge.
The core idea is to ship models to devices, train the model on the device, and retrieve the updates:
But this isn't as simple as it sounds.
1) Since the model is trained on the client side, how to reduce its size?
2) How do we aggregate different models received from the client side?
3) [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Learn how to implement federated learning systems (beginner-friendly) →