LLMs
Building a 100% local mini-ChatGPT
...using Llama-3.2 Vision and Chainlit.

Avi Chawla
...using Llama-3.2 Vision and Chainlit.

TODAY'S ISSUE
We built a mini-ChatGPT that runs locally on your computer and is powered by the open-source Llama3.2-vision model.
Here's a demo before we show you how we built it:
You can chat with it just like you would chat with ChatGPT, and provide multimodal prompts.
Here’s what we used:
The code is available on GitHub here: Local ChatGPT.
Let's build it.
We'll assume you are familiar with multimodal prompting. If you are not, we covered in Part 5 of our RAG crash course (open-access).
We begin with the import statements and define the start_chat method, which is invoked as soon as a new chat session starts:
We use the @cl.on_chat_start decorator in the above method.
Next, we define another method which will be invoked to generate a response from the LLM:
Finally, we define the main method:
Done!
Run the app as follows:
This launches the app shown below:
The code is available on GitHub here: Local ChatGPT.
We launched this repo recently, wherein we’ll publish the code for such hands-on AI engineering newsletter issues.
This repository will be dedicated to:
Find it here: AI Engineering Hub (and do star it).
👉 Over to you: What more functionalities would you like to see in the above app?
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
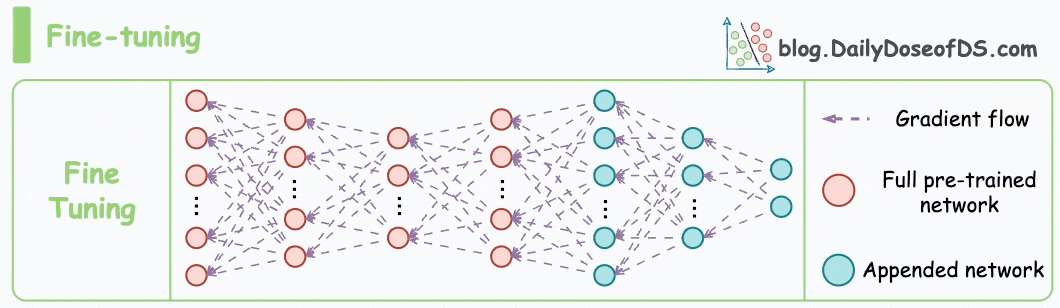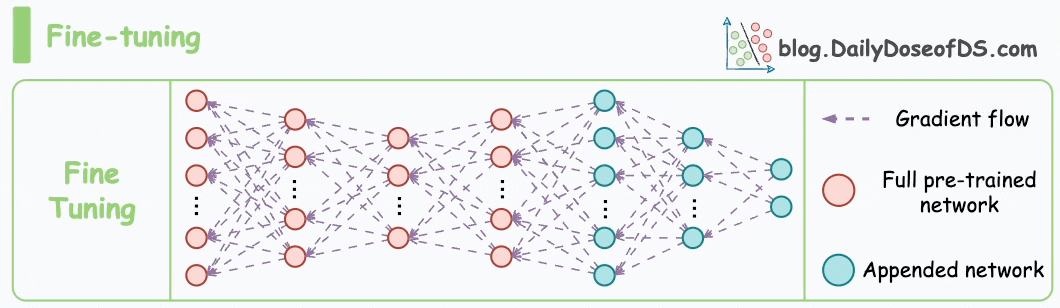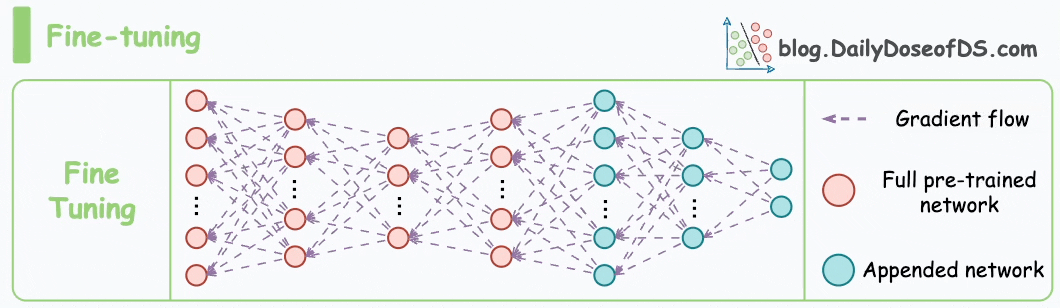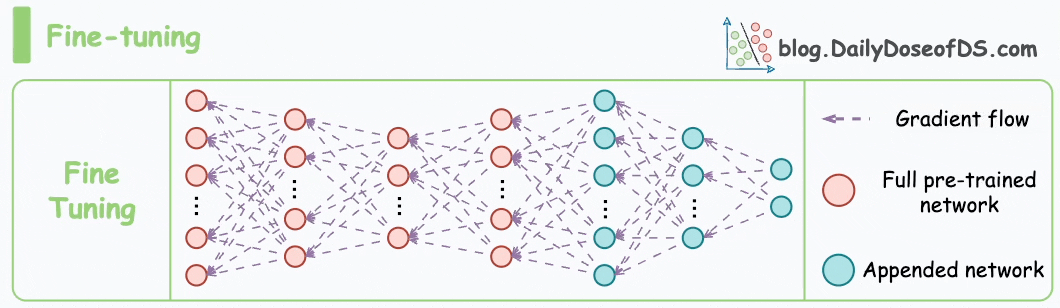
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.