LLMs
Build a Multi-agent Content Creation System
...explained step-by-step with code.

Avi Chawla
...explained step-by-step with code.

TODAY'S ISSUE
Lately, we have been experimenting heavily with Motia, an open-source modern backend framework that brings together:
The video below shows a demo where we have built a multi-agent content creation system that is also exposed via APIs.
Tech stack:
Here’s the workflow:
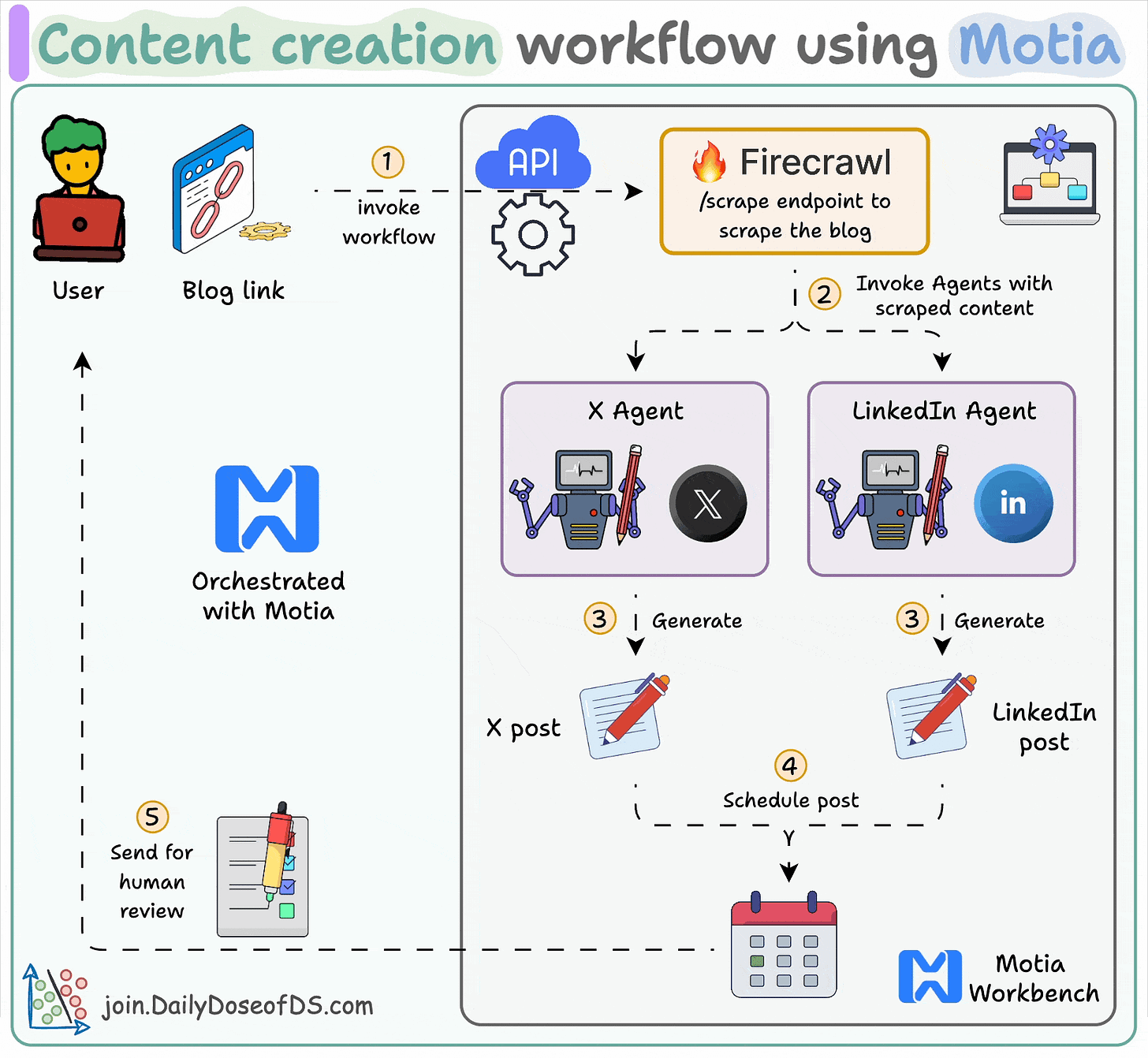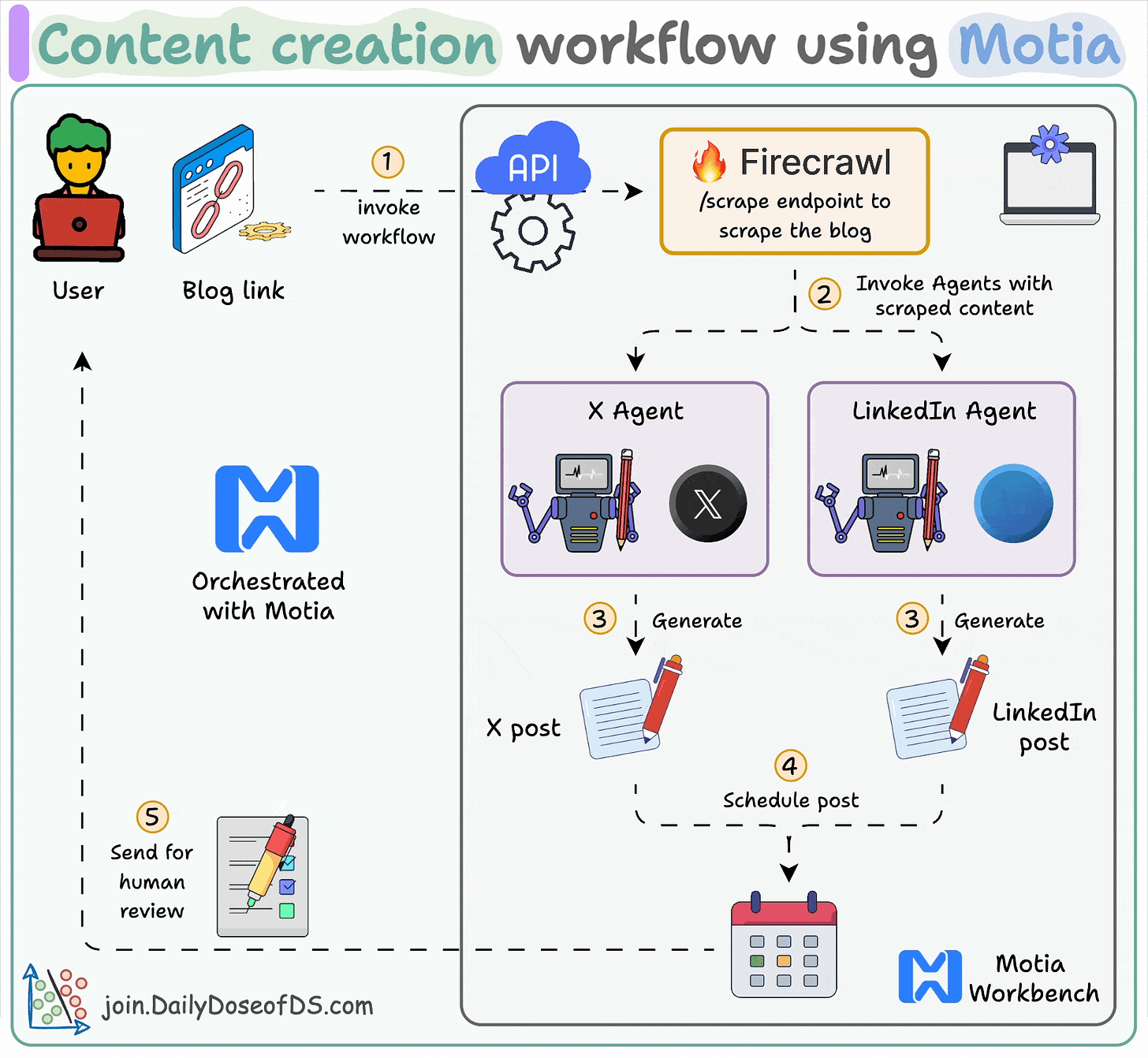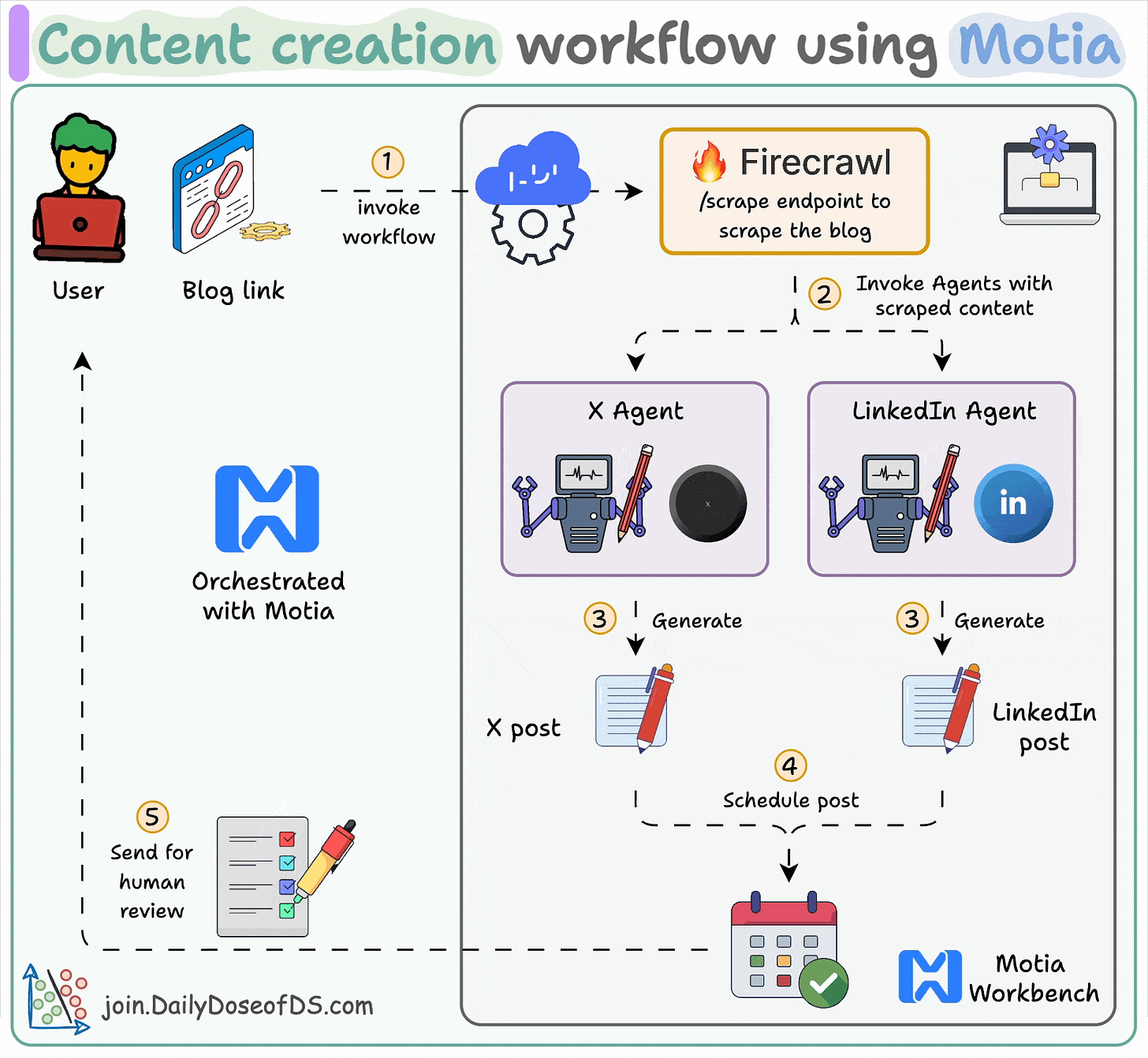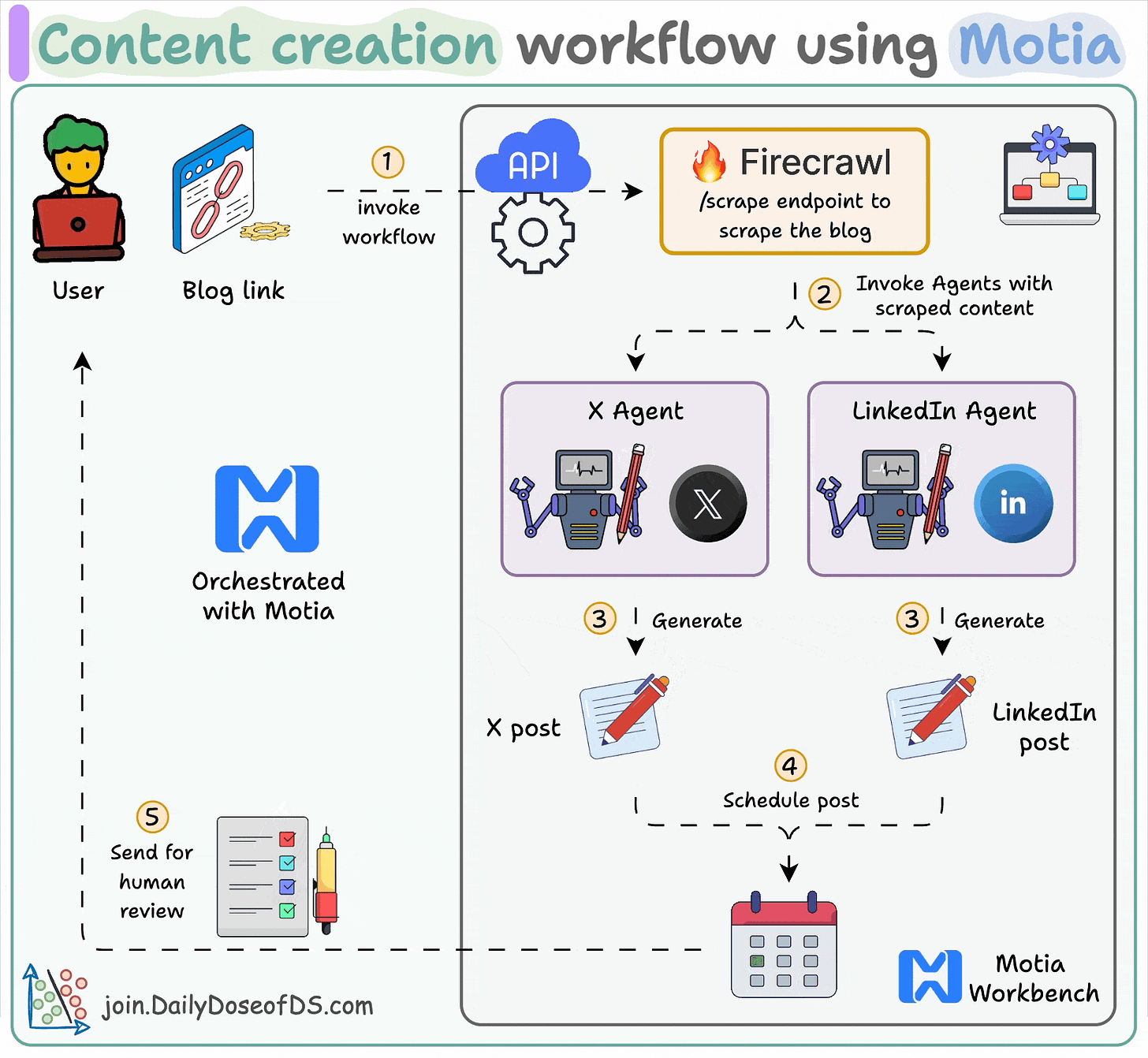
It’s easier to explain everything via video, so we have added one at the top.
It demonstrates building a multi-agent content creation system that is also exposed via APIs.
Just like React streamlines frontend development, Motia simplifies the AI backend, where you only need one solution instead of a dozen tools.
Key features:
GitHub repo → (don’t forget to star it)

Printing the response, we get:
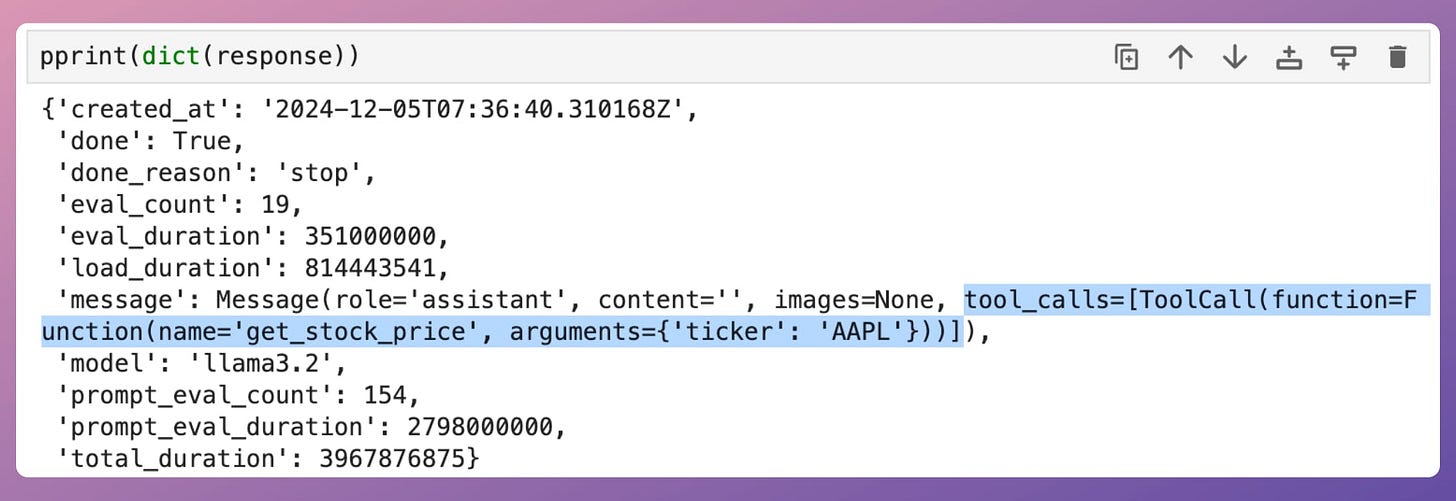
Notice that the message key in the above response object has tool_calls, which includes relevant details, such as:
tool.function.name: The name of the tool to be called.tool.function.arguments: The arguments required by the tool.Thus, we can utilize this info to produce a response as follows:
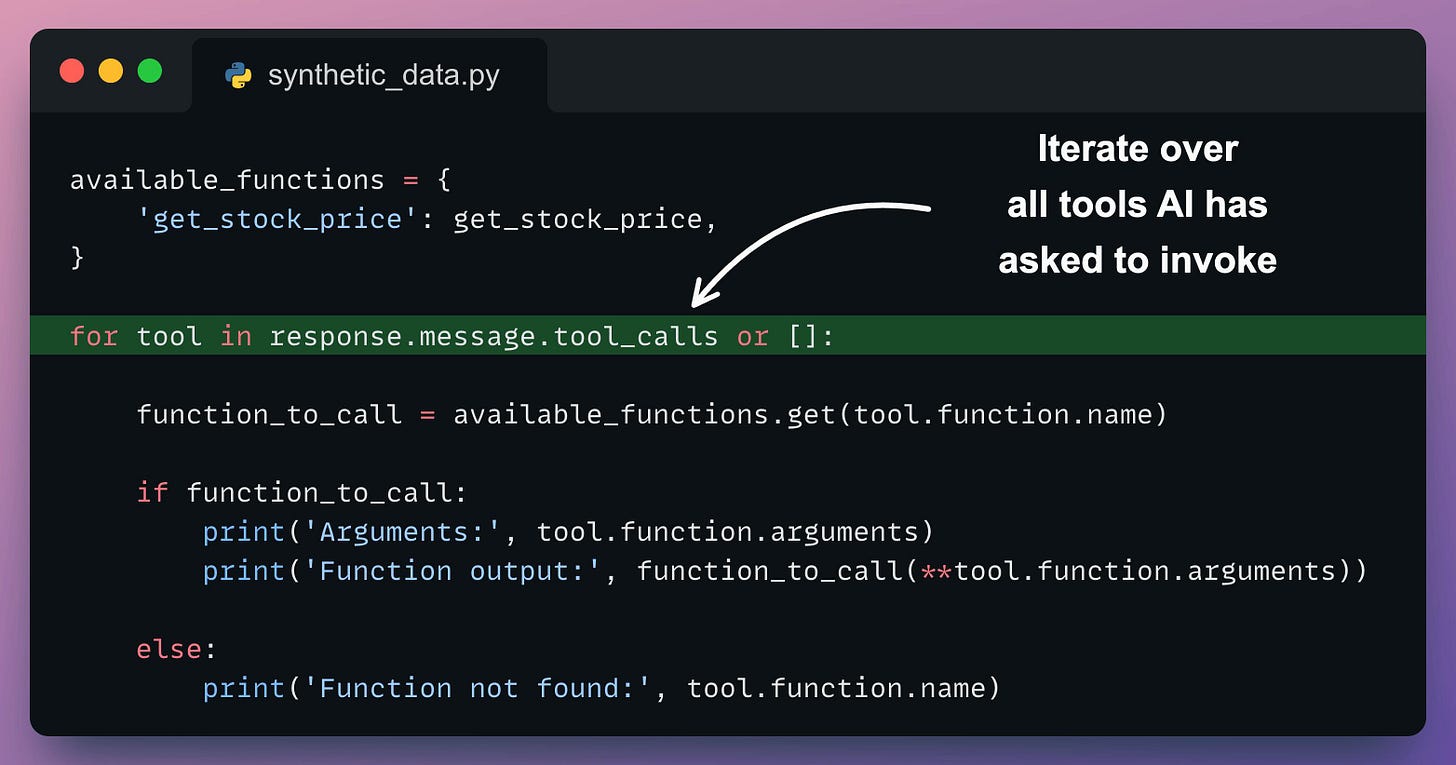
This produces the following output.
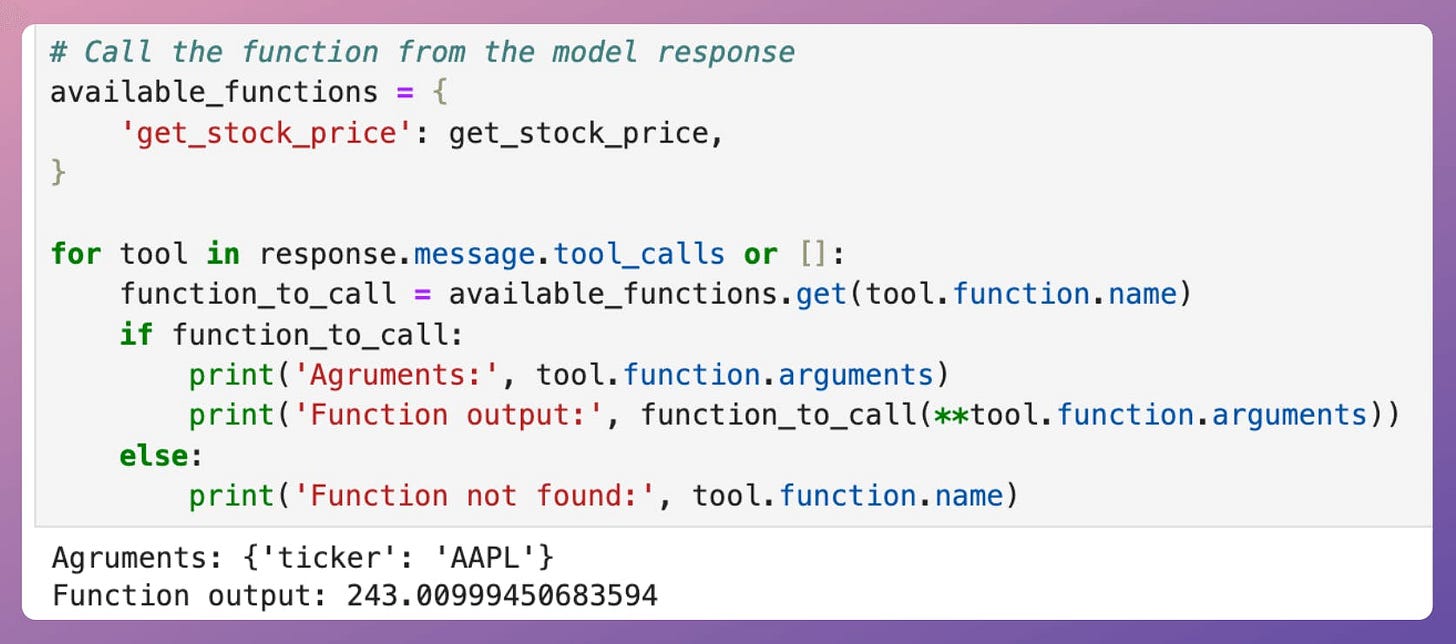
This produces the expected output.
Of course, the above output can also be passed back to the AI to generate a more vivid response, which we haven't shown here.
But this simple demo shows that with tool calling, the assistant can be made more flexible and powerful to handle diverse user needs.
👉 Over to you: What else would you like to learn about in LLMs?
We have covered several LLM fine-tuning approaches before.
DoRA is another promising and SOTA technique that improves LoRA and other similar fine-tuning techniques.
These results show that even with a reduced rank (e.g., halving the LoRA rank), DoRA significantly outperforms LoRA:
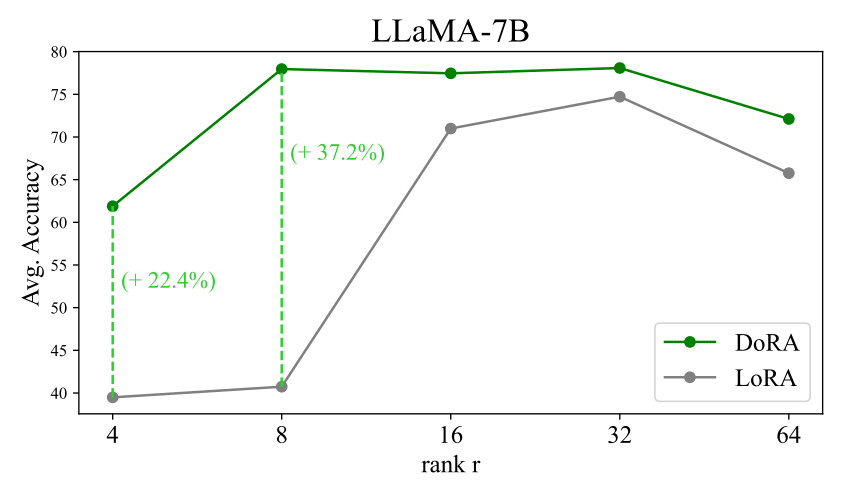
But why care about efficient LLM fine-tuning techniques?
Traditional fine-tuning is practically infeasible with LLMs.
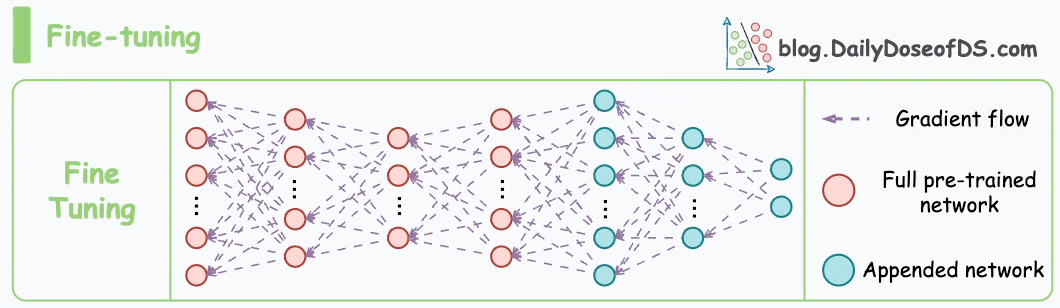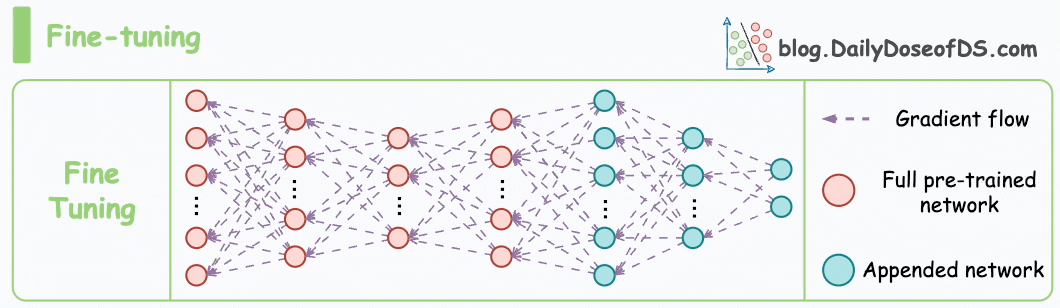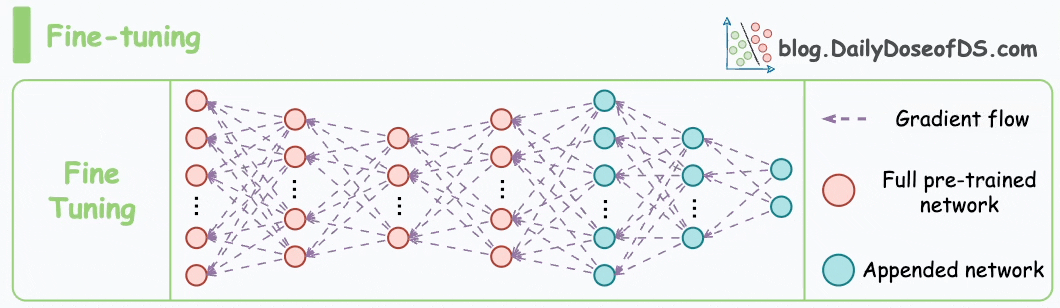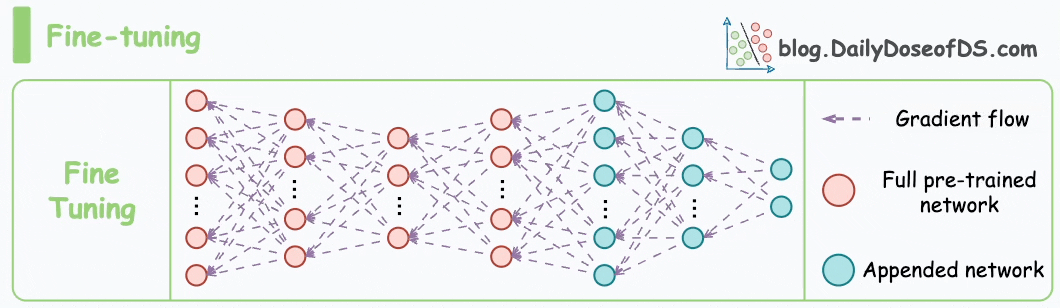
To understand, consider this:
GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
Techniques like LoRA (and other variants) solved this key business problem.
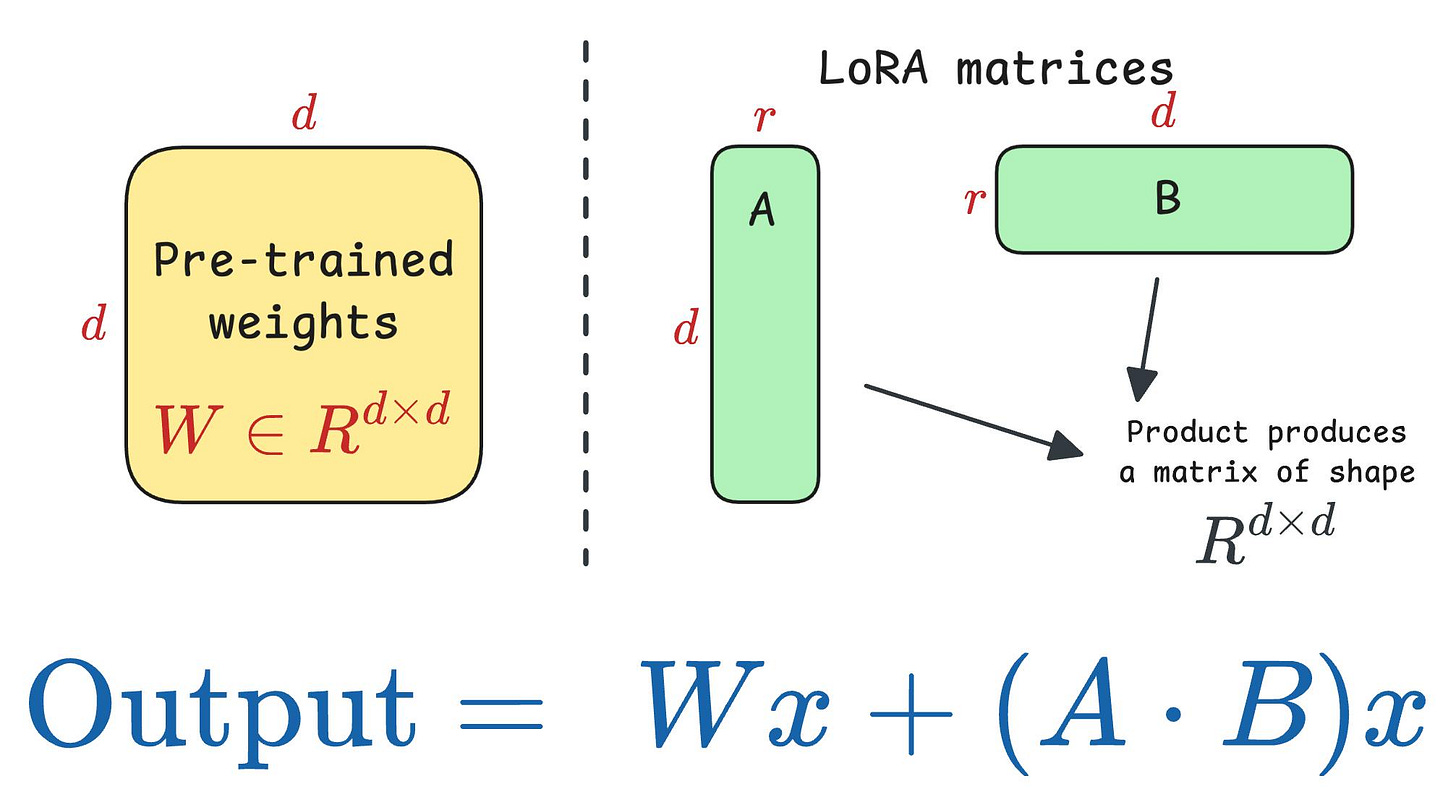
DoRA further optimized this.
We did an algorithmic breakdown of how DoRA works and observations from LoRA that led to its development.
We also implemented it from scratch in PyTorch to help you build an intuitive understanding.
RAG is powerful, but not always ideal if you want to augment LLMs with more information.
Several industry use cases heavily rely on efficient LLM fine-tuning, which you must be aware of in addition to building robust RAG solutions.