Machine Learning
Shuffle Feature Importance
An intuitive and reliable technique to measure feature importance.

Avi Chawla
An intuitive and reliable technique to measure feature importance.

TODAY'S ISSUE
There are so many techniques to measure feature importance.
I often find “Shuffle Feature Importance” to be a handy and intuitive technique to measure feature importance.
Let’s understand this today!
As the name suggests, it observes how shuffling a feature influences the model performance.
The visual below illustrates this technique in four simple steps:
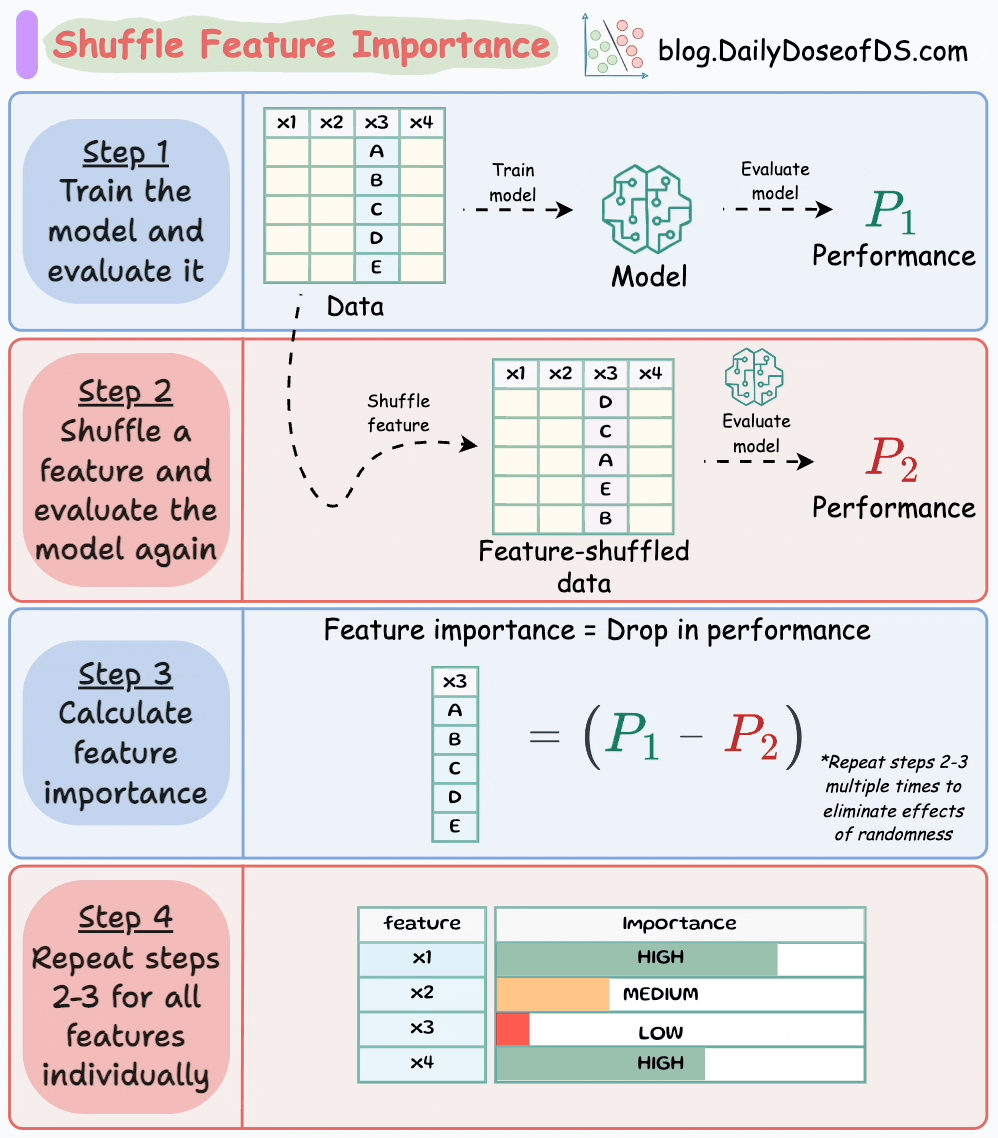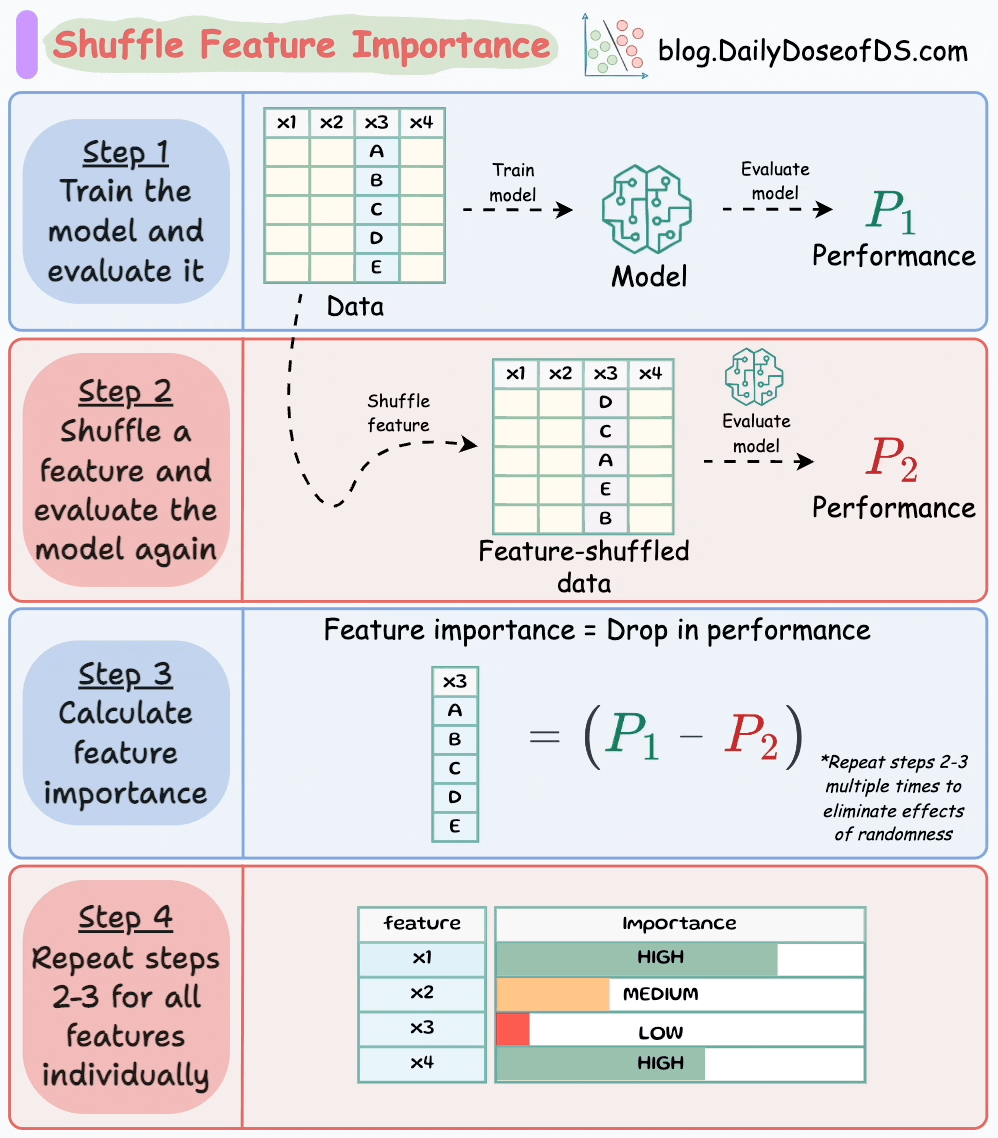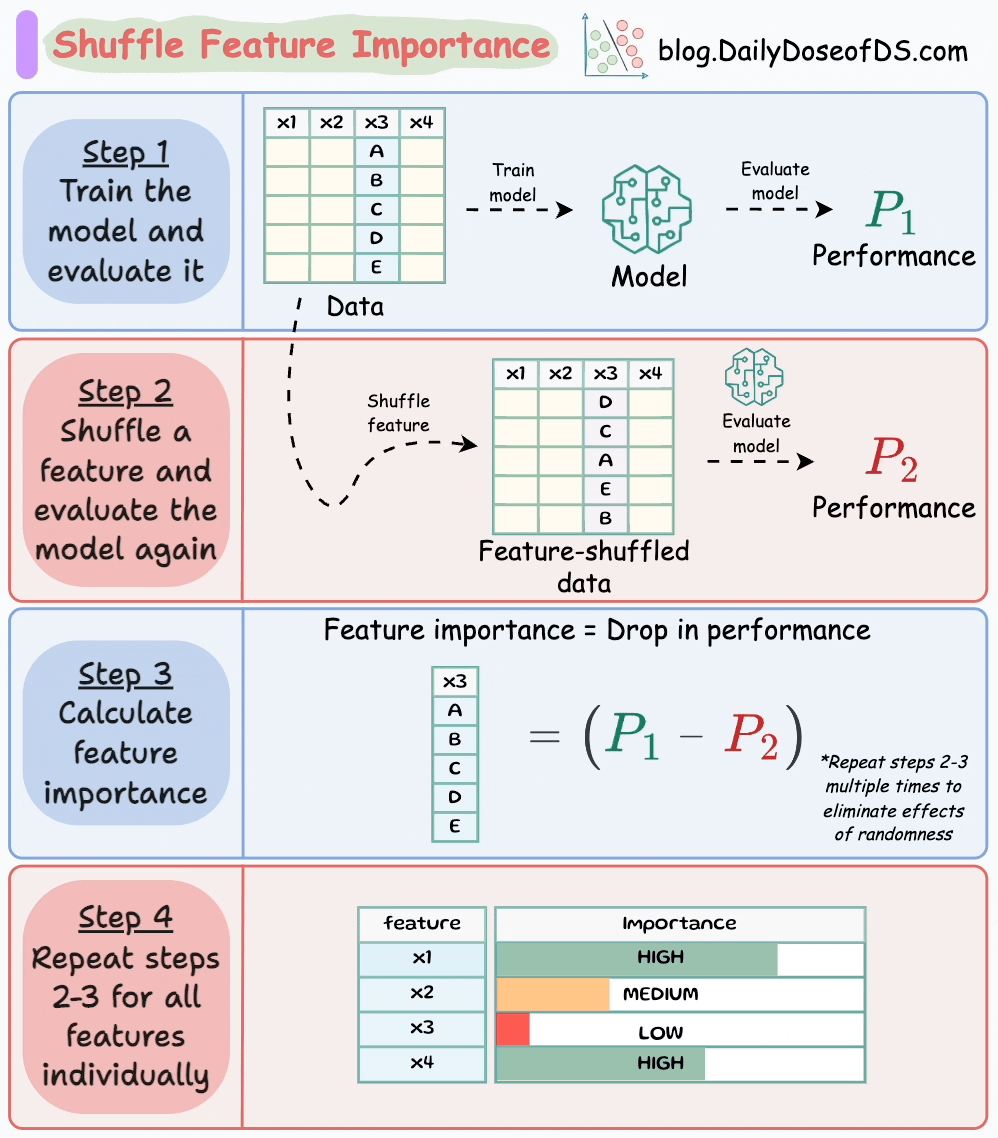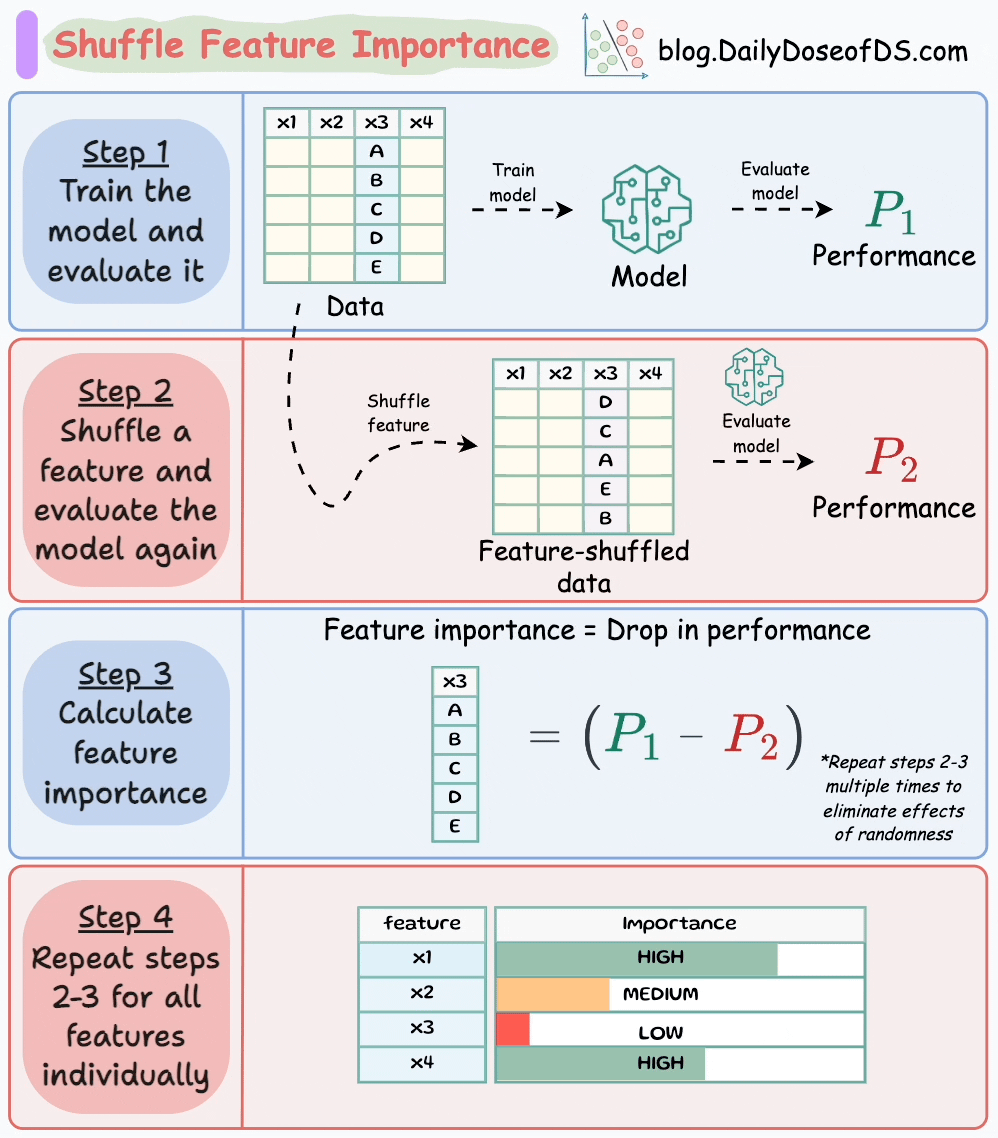
Here’s how it works:
P1.P2 (model is NOT trained again).P1-P2).This makes intuitive sense as well, doesn’t it?
Simply put, if we randomly shuffle just one feature and everything else stays the same, then the performance drop will indicate how important that feature is.
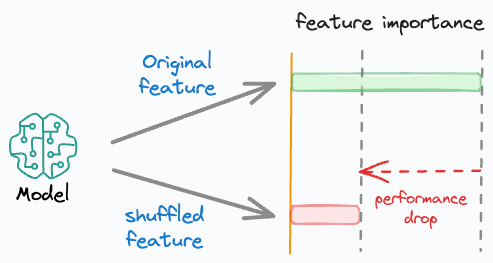
Do note that to eliminate any potential effects of randomness during feature shuffling, it is recommended to:
A few things that I love about this technique are:
Of course, there is one caveat as well.
Say two features are highly correlated, and one of them is permuted/shuffled.
In this case, the model will still have access to the feature through its correlated feature.
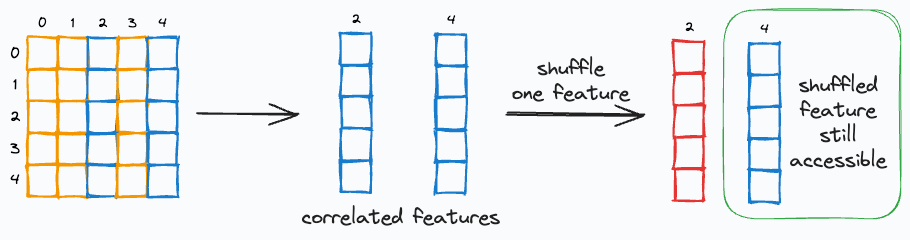
This will result in a lower importance value for both features.
One way to handle this is to cluster highly correlated features and only keep one feature from each cluster.
👉 Over to you: What other reliable feature importance techniques do you use frequently?
If you consider the last decade (or 12-13 years) in ML, neural networks have dominated the narrative in most discussions.
In contrast, tree-based methods tend to be perceived as more straightforward, and as a result, they don't always receive the same level of admiration.
However, in practice, tree-based methods frequently outperform neural networks, particularly in structured data tasks.
This is a well-known fact among Kaggle competitors, where XGBoost has become the tool of choice for top-performing submissions.
One would spend a fraction of the time they would otherwise spend on models like linear/logistic regression, SVMs, etc., to achieve the same performance as XGBoost.
Learn about its internal details by formulating and implementing it from scratch here →
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
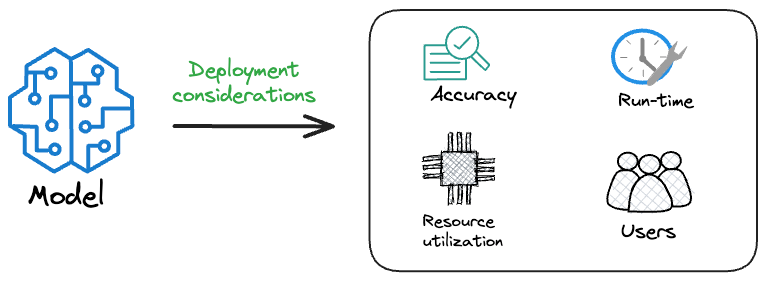
Instead, we also consider several operational and feasibility metrics, such as:
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.
Learn how to compress models before deployment with implementation →