Pandas
Pandas vs. FireDucks Performance Comparison
20x faster Pandas by changing one line of code.

Avi Chawla
20x faster Pandas by changing one line of code.

TODAY'S ISSUE
I have been using FireDucks quite extensively lately.
For starters, FireDucks is a heavily optimized alternative to Pandas with exactly the same API as Pandas.
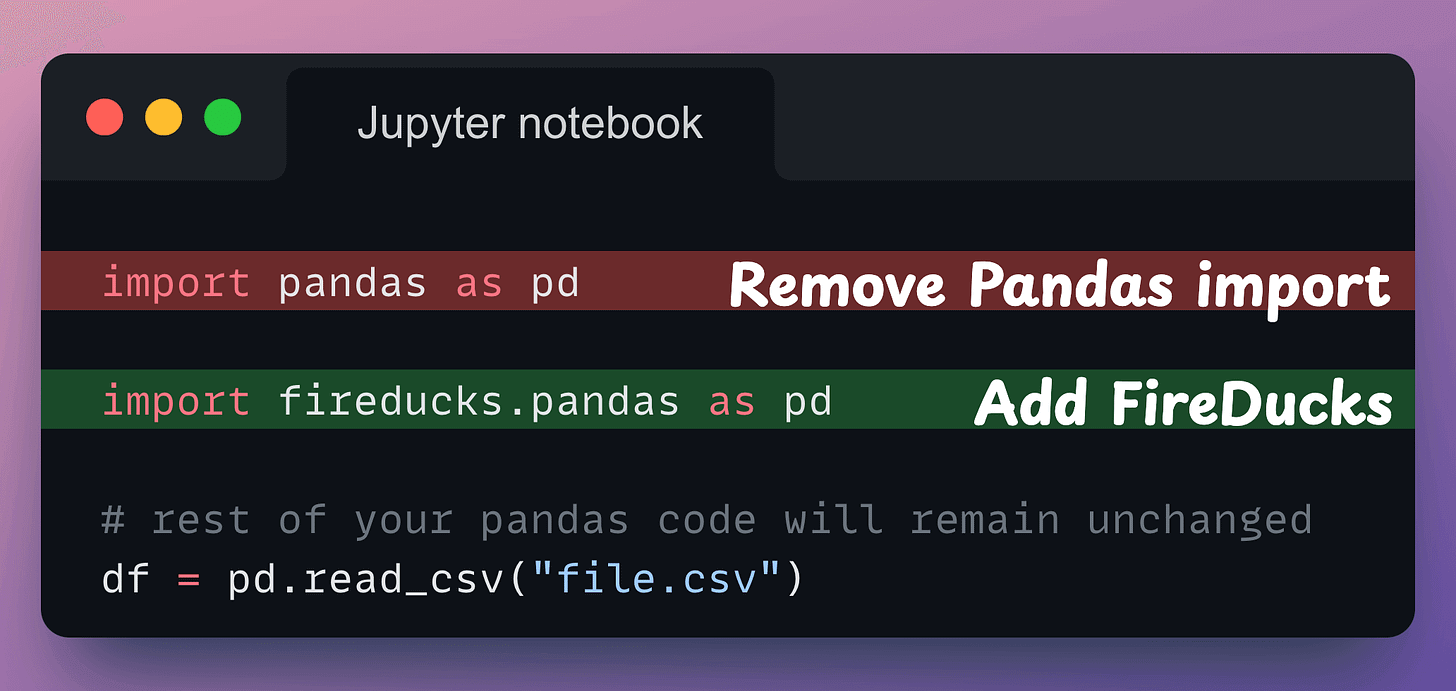
All you need to do is replace the Pandas import with the FireDucks import. That’s it.
As per FireDucks’ official benchmarks across 22 queries:

A demo of this speed-up in comparison to DuckDB, Pandas and Polars is also shown in the video below:
At its core, FireDucks is heavily driven by lazy execution, unlike Pandas, which executes right away.
This allows FireDucks to build a logical execution plan and apply possible optimizations.
That said, FireDucks supports an eager execution mode as well, like Pandas, which you can use as follows:

So I tested Pandas and FireDucks head-to-head on several common tabular operations under eager evaluation.
The results have been summarized below:
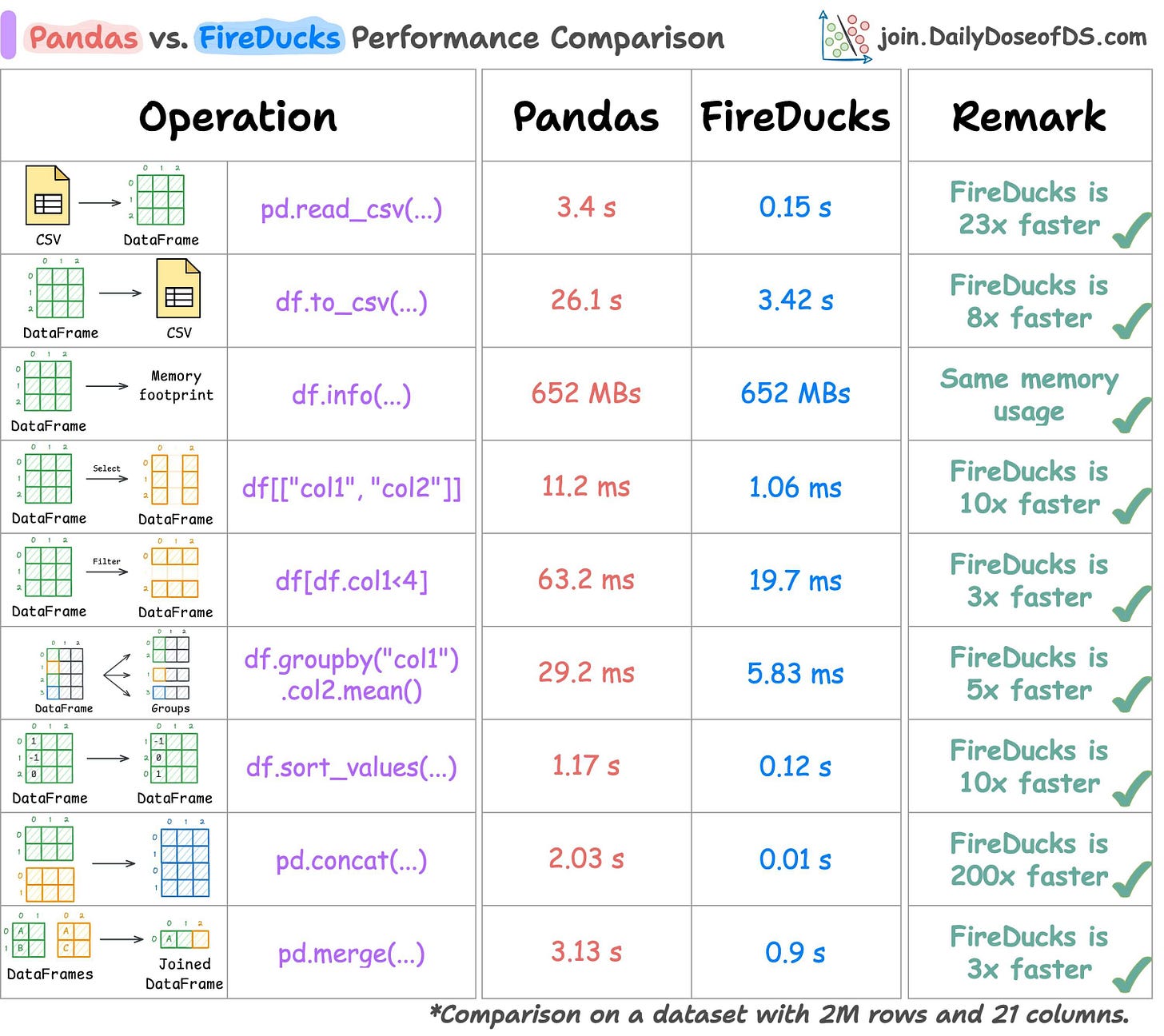
As depicted above, FireDucks performs better than Pandas in all operations.
Isn’t that amazing?
First, install the library:

Next, there are three ways to use it:

fireducks.pandas), which can be imported instead of using Pandas. Thus, to use FireDucks in an existing Pandas pipeline, replace the standard import statement with the one from FireDucks: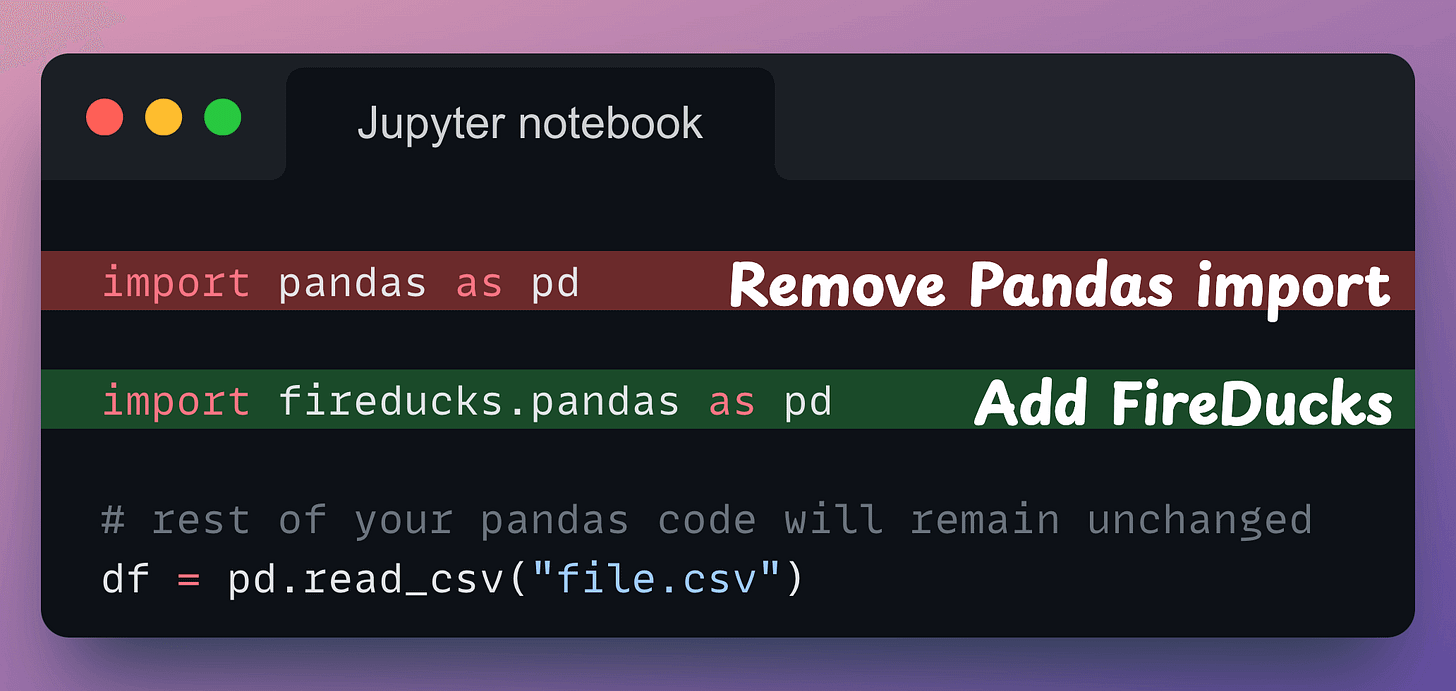

Done!
It’s that simple to use FireDucks.
The code for the above benchmarks is available in this colab notebook.
👉 Over to you: What are some other ways to accelerate Pandas operations in general?
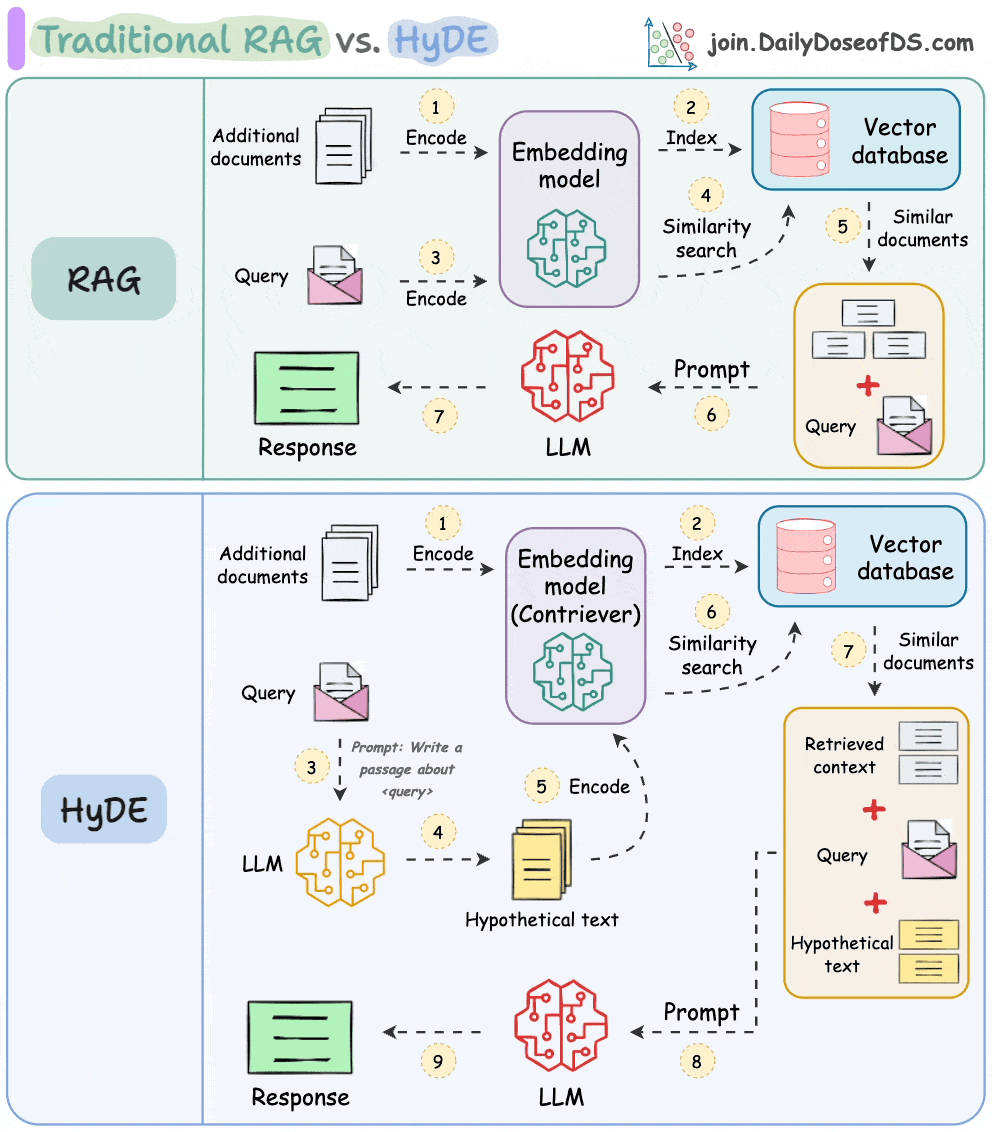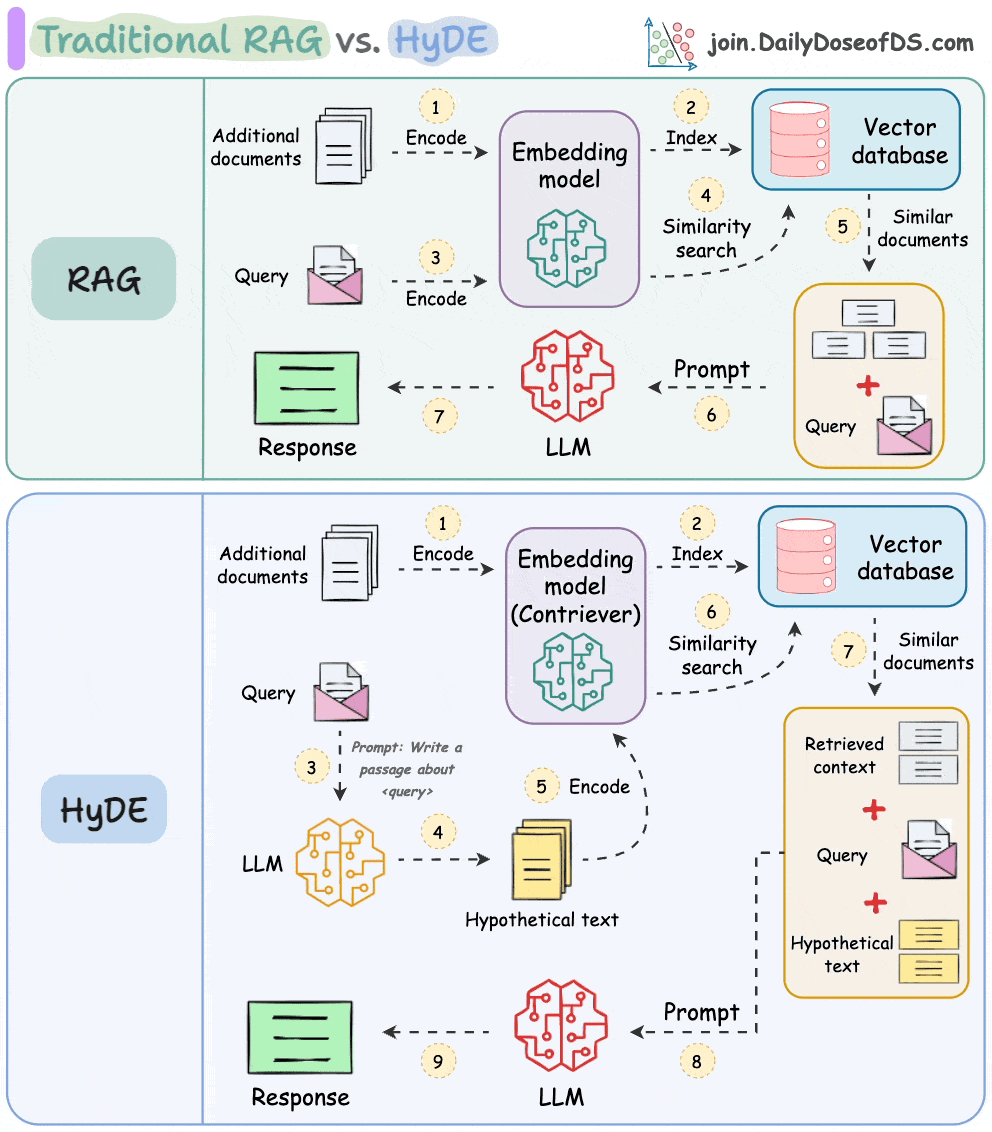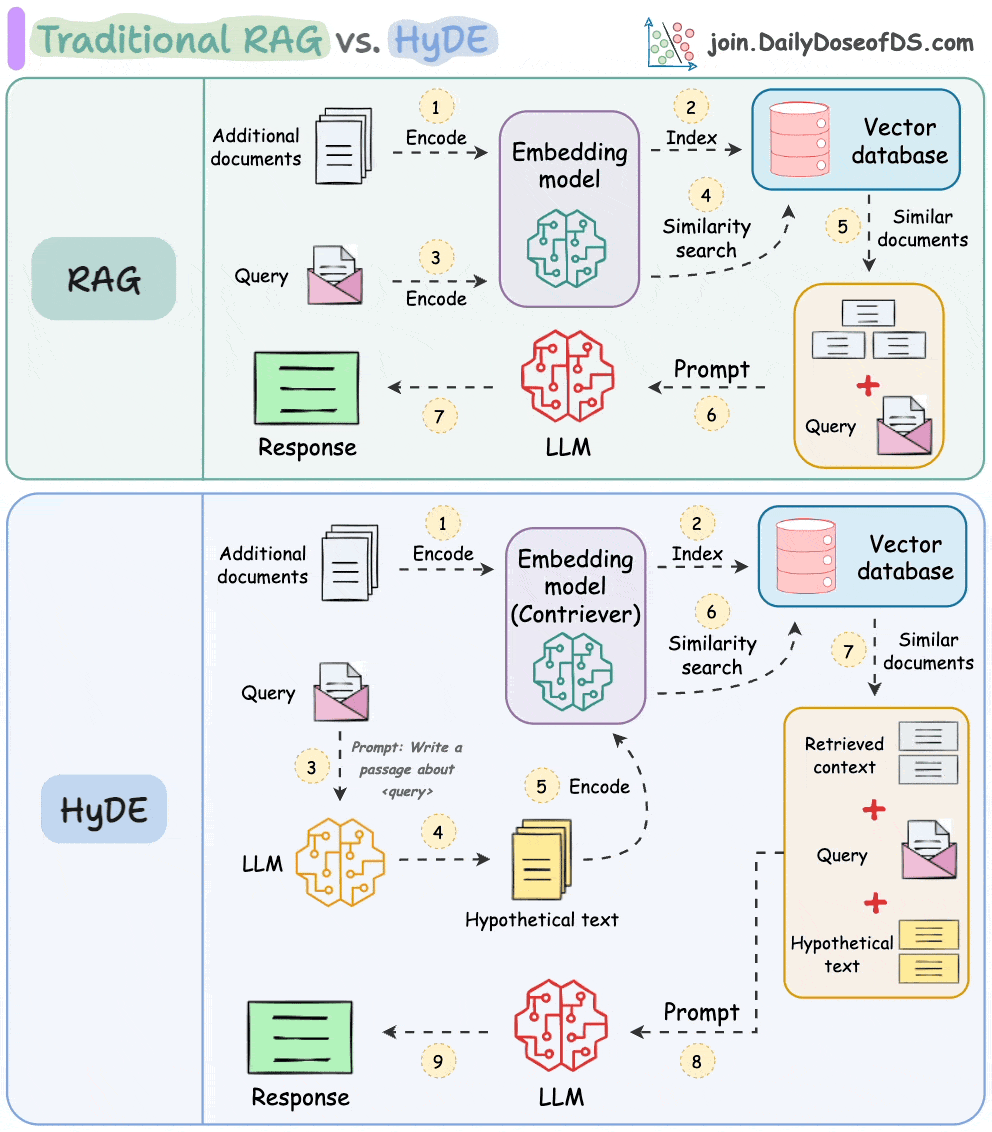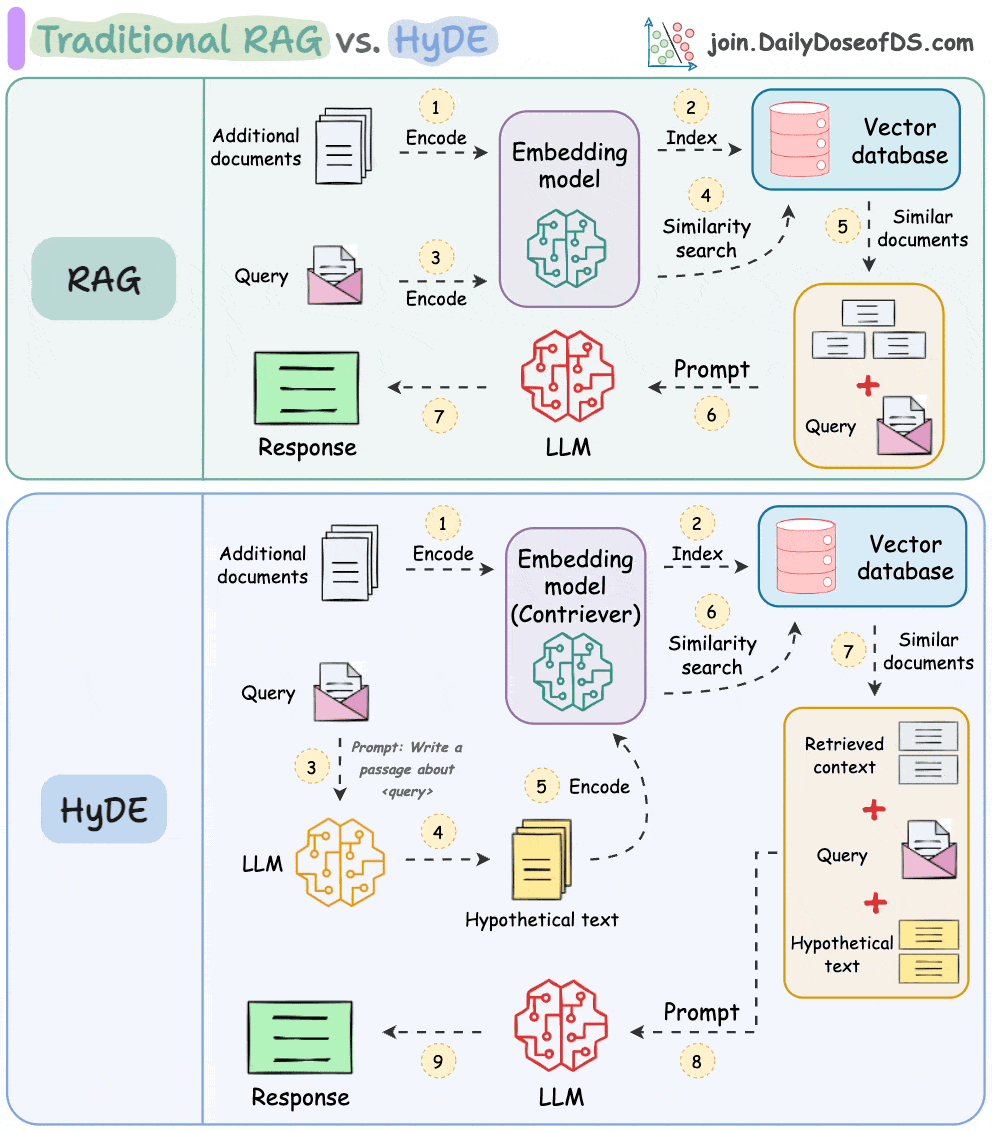
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
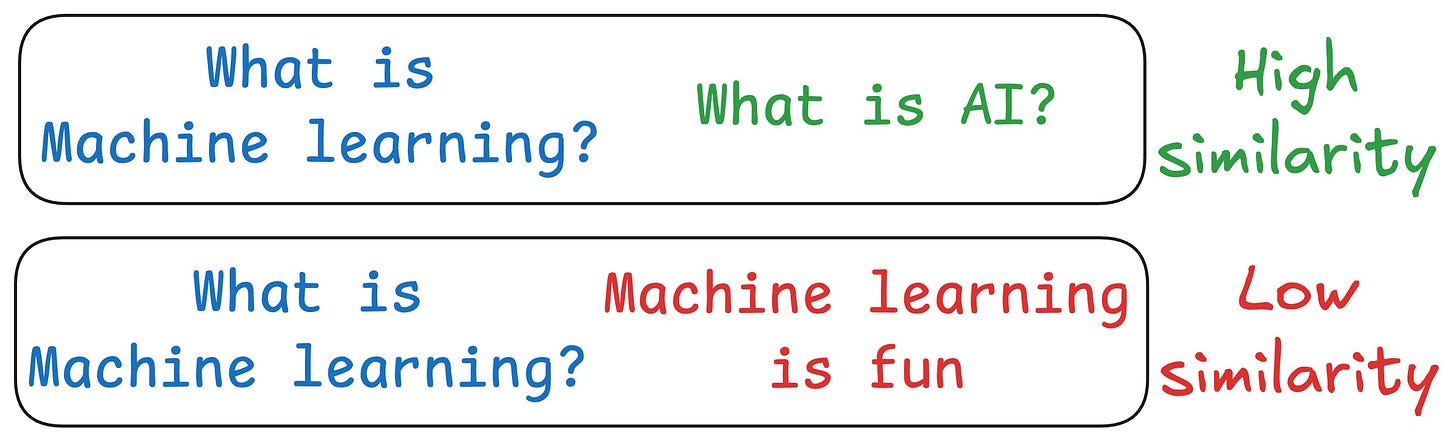
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
We covered this in detail in a newsletter issue published last week →
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
That is why Git is best suited for versioning codebase, which is primarily composed of lightweight files.
However, ML projects are not solely driven by code.
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.
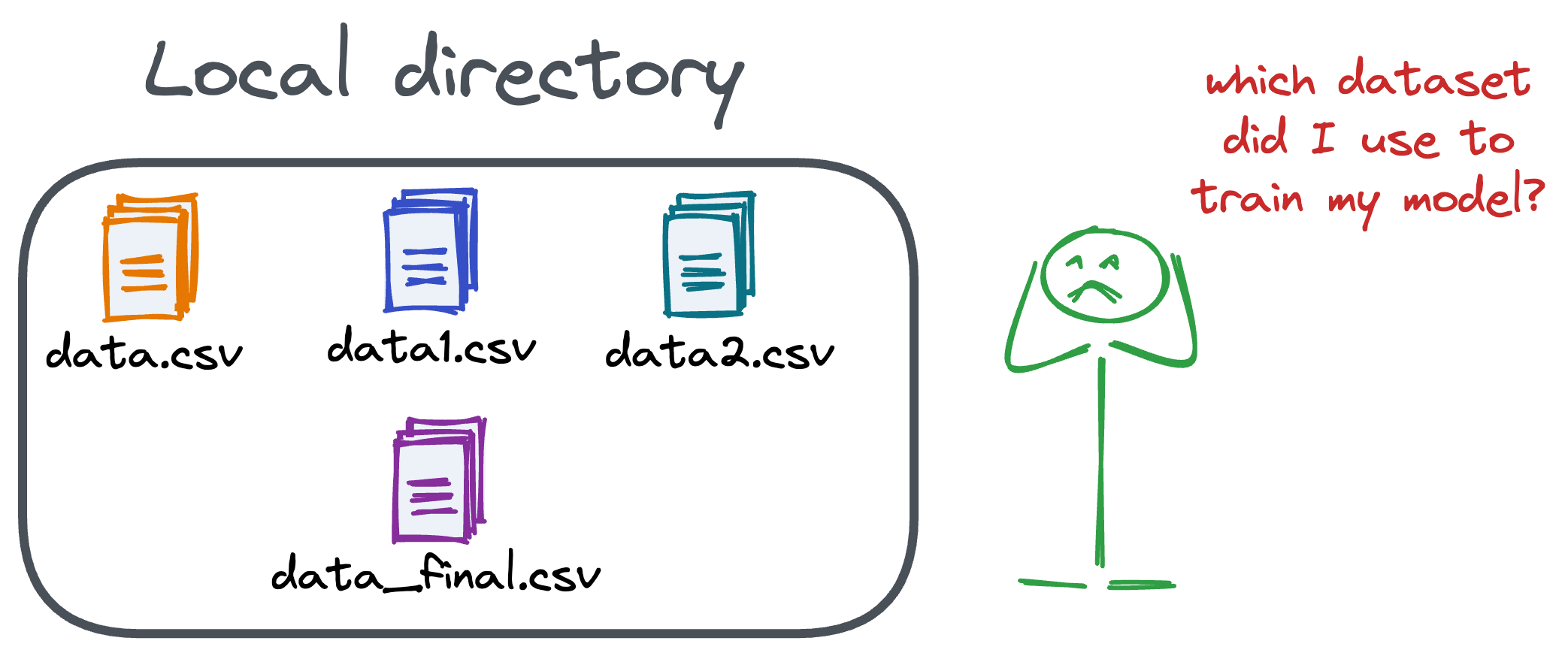
Data version control (DVC) solves this problem.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
Here's everything you need to know (with implementation) about building 100% reproducible ML projects →