Machine Learning
Contrastive Learning Using Siamese Networks
Building a face unlock system.

Avi Chawla
Building a face unlock system.

TODAY'S ISSUE
As an ML engineer, you are responsible for building a face unlock system.
Let’s look through some possible options:
Today, we shall cover the overall idea and do the implementation tomorrow.
Output 1 if the true user is opening the mobile; 0 otherwise.
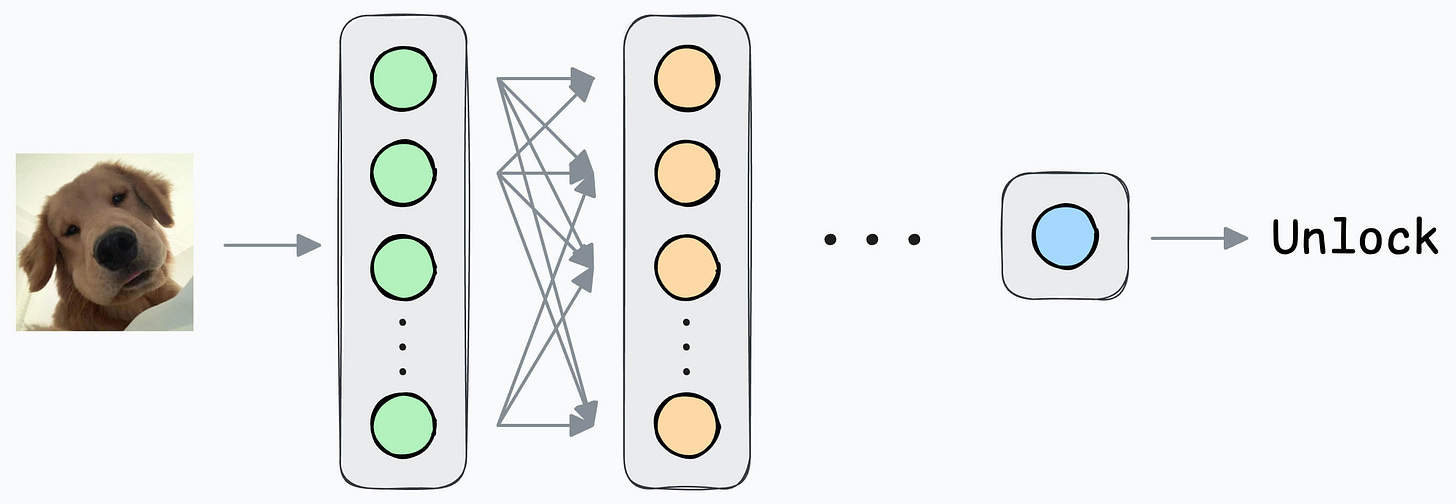
Initially, you can ask the user to input facial data to train the model.
But that’s where you identify the problem.
All samples will belong to “Class 1.”

Now, you can’t ask the user to find someone to volunteer for “Class 0” samples since it’s too much hassle for them.
Not only that, you also need diverse “Class 0” samples. Samples from just one or two faces might not be sufficient.
The next possible solution you think of is…
Maybe ship some negative samples (Class 0) to the device to train the model.

Might work.
But then you realize another problem:
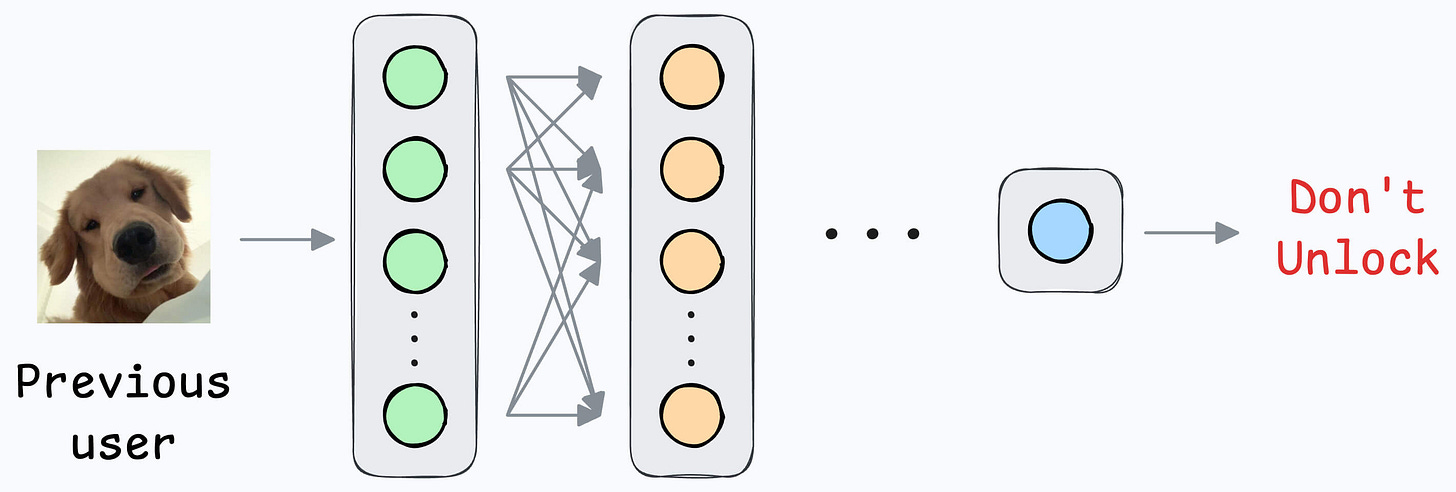
What if another person wants to use the same device?
Since all new samples will belong to the “new face” during adaptation, what if the model forgets the first face?
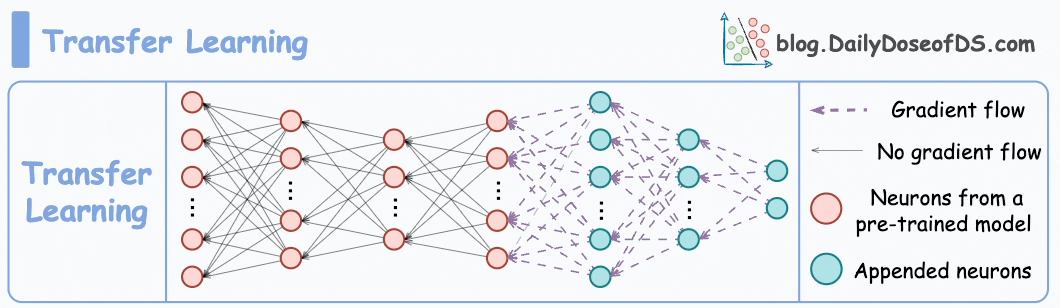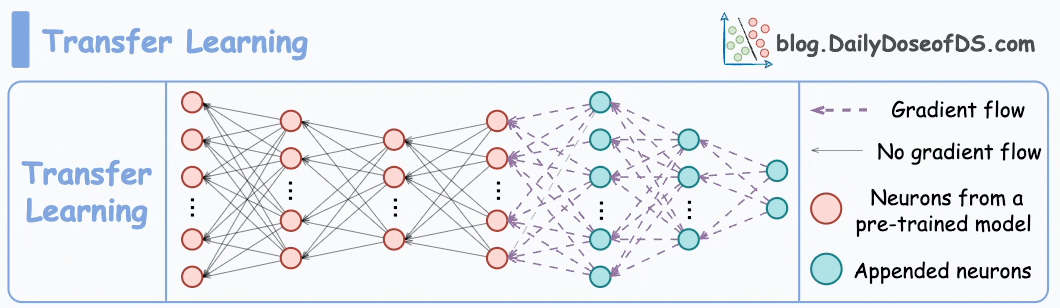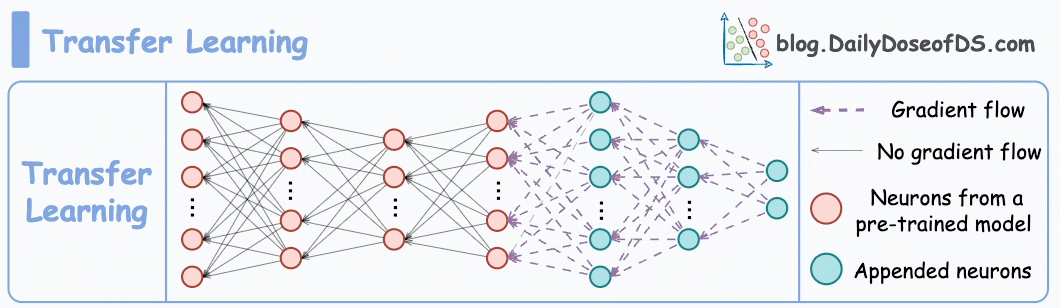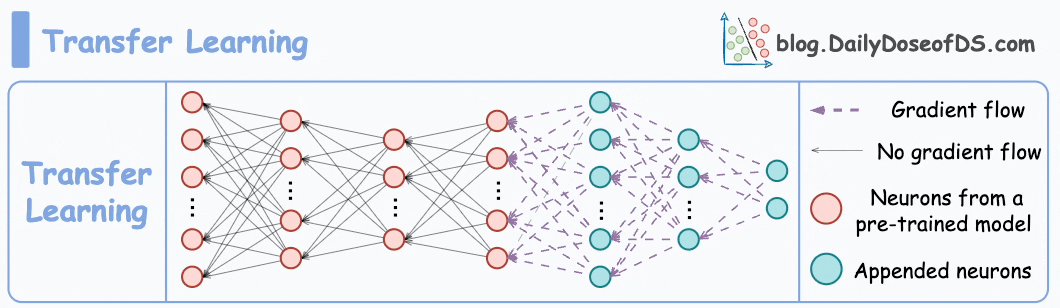
This is extremely useful when:
This is how you think it could work in this case:
It is expected that the first few layers would have learned to identify the key facial features.
From there on, training on the user’s face won’t require much data.
But yet again, you realize that you shall run into the same problems you observed with the binary classification model since the new layers will still be designed around predicting 1 or 0.
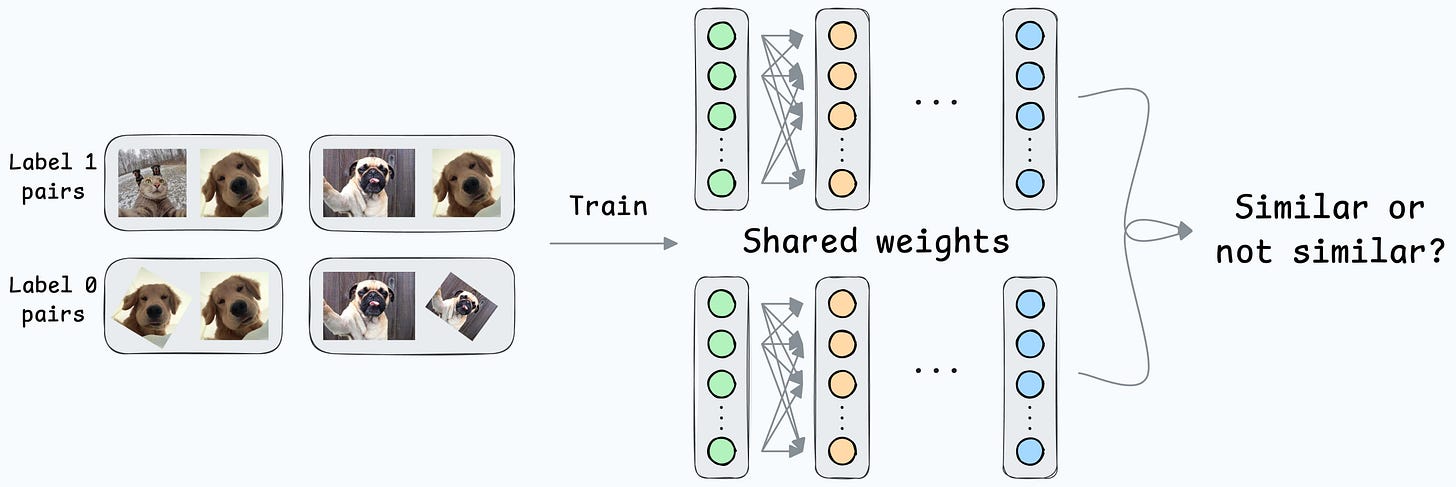
At its core, a Siamese network determines whether two inputs are similar.
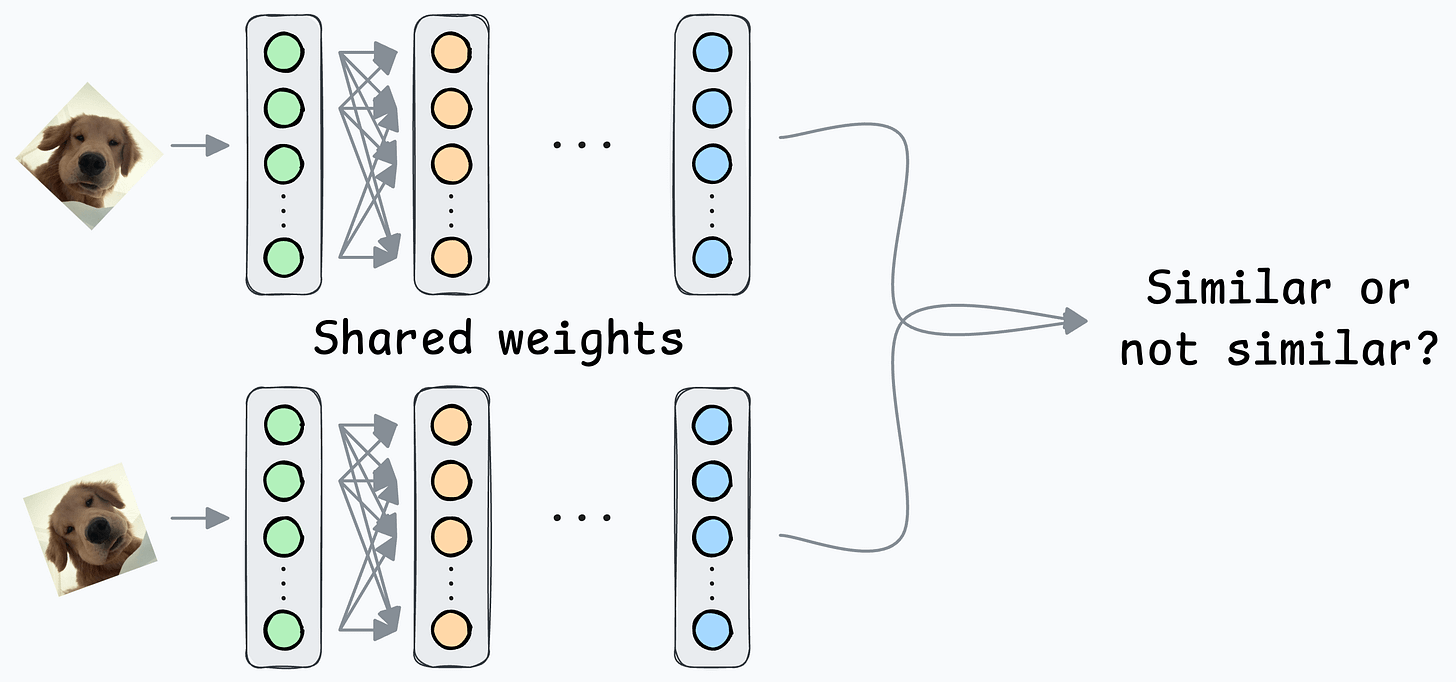
It does this by learning to map both inputs to a shared embedding space (the blue layer above):
They are beneficial for tasks where the goal is to compare two data points rather than to classify them into predefined categories/classes.
This is how it will work in our case:
Create a dataset of face pairs:


After creating this data, define a network like this:
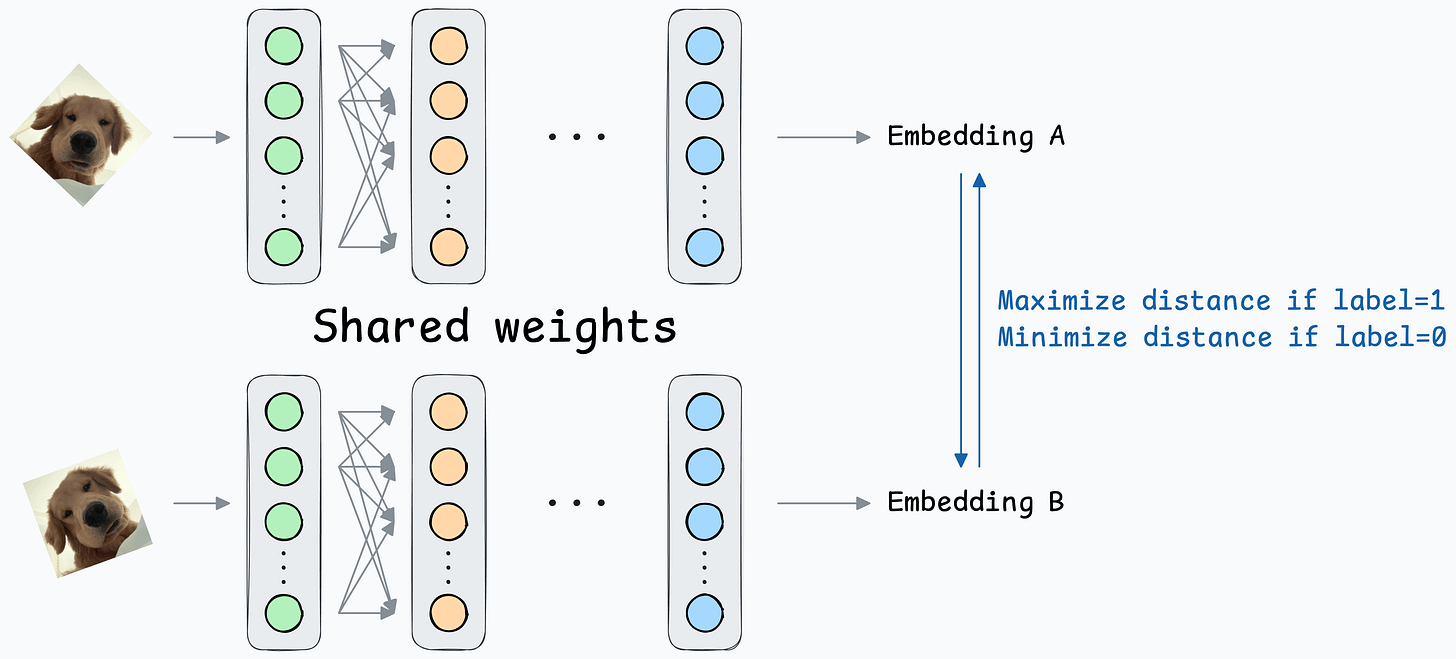
Contrastive loss (defined below) helps us train such a model:
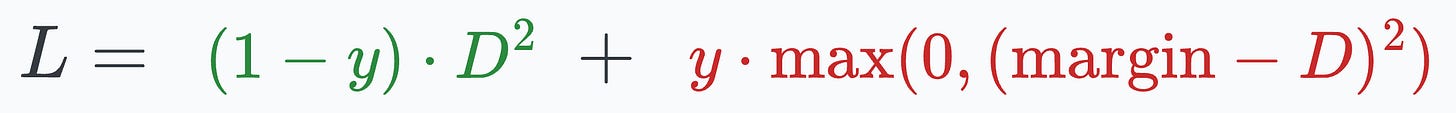
where:
y is the true label.D is the distance between two embeddings.margin is a hyperparameter, typically greater than 1.Here’s how this particular loss function helps:
margin value, leading to more distance between the embeddings.0, leading to a low distance between the embeddings.When y=0 (same person), the loss will be:
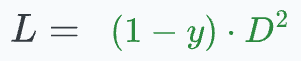
When y=1 (different people), the loss will be:
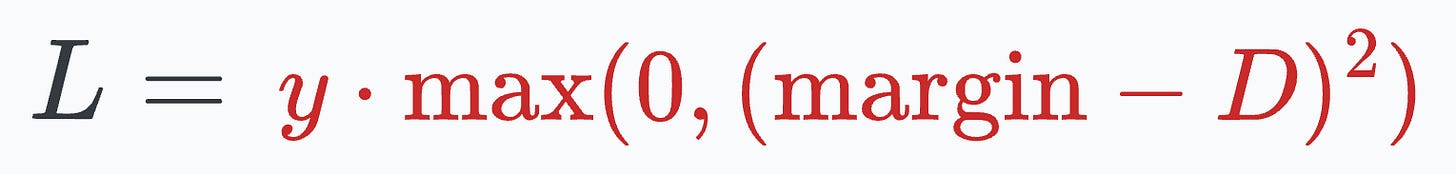
This way, we can ensure that:
Here’s how it will help in the face unlock application.
First, you will train the model on several image pairs using contrastive loss.
This model (likely after model compression) will be shipped to the user’s device.
During the setup phase, the user will provide facial data, which will create a user embedding:
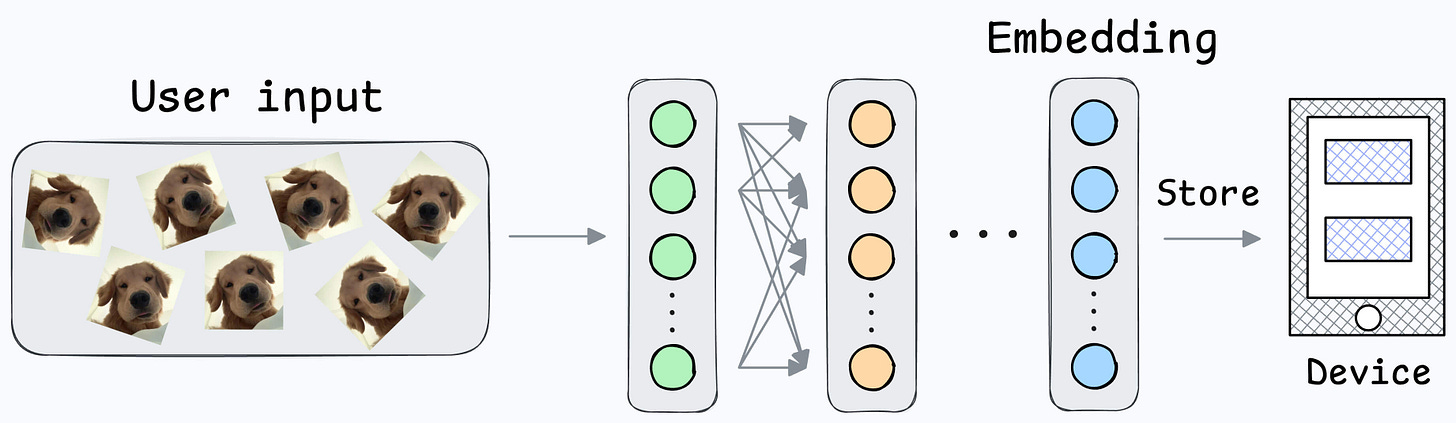
This embedding will be stored in the device’s memory.
Next, when the user wants to unlock the mobile, a new embedding can be generated and compared against the available embedding:
Done!
Note that no further training was required here, like in the earlier case of binary classification.
Also, what if multiple people want to add their face IDs?
No problem.
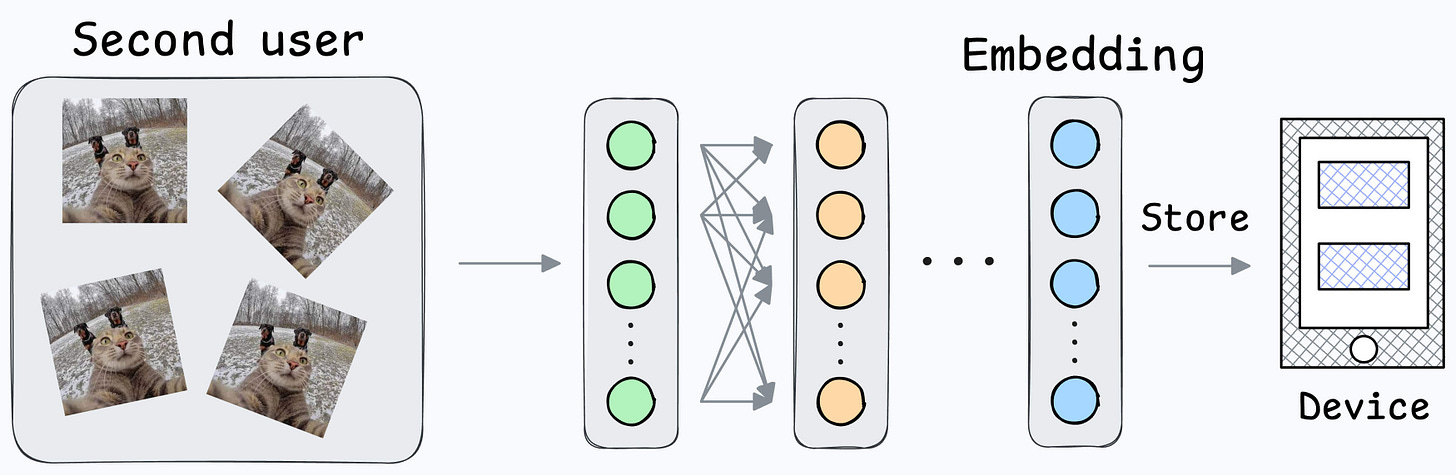
Create another embedding for the new user.
During unlock, compare the incoming user against all stored embeddings.
That was simple, wasn’t it?
I am ending today’s issue here, but tomorrow, we shall discuss a simple implementation of Siamese Networks using PyTorch.
Until then, here’s some further hands-on reading to learn how to build on-device ML applications:
👉 Over to you: Siamese Networks are not the only way to solve this problem. What other architectures can work?
After using OpenAI’s Swarm, we realized several limitations.
One major shortcoming is that it isn’t suited for production use cases since the project is only meant for experimental purposes.
SwarmZero solves this.
We recently shared a practical and hands-on demo of this.
We’ll build a PerplexityAI-like research assistant app that:
Learn how to build multi-agent applications with SwarmZero →