CI/CD Workflows
MLOps Part 18: A hands-on guide to CI/CD in MLOps with DVC, Docker, GitHub Actions, and GitOps-based Kubernetes delivery on Amazon EKS.
Recap
In Part 17 of this MLOps and LLMOps crash course, we explored monitoring and observability in ML systems, along with the key tools that make up the ML observability stack.
We began by understanding the two types of monitoring: functional and operational monitoring.
After that, we explored Evidently AI, the functional monitoring tool, and walked through data-drift detection, data-quality analysis, and HTML dashboard generation, complete with code examples.

Next, we did a brief discussion on Prometheus and Grafana for operational monitoring and understood their significance for ML systems and teams.

Finally, we went hands-on covering functional and operational monitoring setup in FastAPI-based applications.
If you haven’t explored Part 17 yet, we recommend going through it first, since it sets the flow for what's about to come.
Read it here:

In this chapter, we’ll understand and learn about CI/CD workflows in ML systems with necessary theoretical details and hands-on examples.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Introduction
CI/CD stands for continuous integration and continuous delivery/deployment, which are standard DevOps practices that automate the software development lifecycle to deliver software changes faster and more reliably.
CI focuses on automatically integrating code changes and running tests, while CD automates the release of those validated changes to a testing or production environment. This automation ensures code quality, speeds up releases, and helps developers respond quickly to user feedback.
Traditional CI/CD focuses on delivering code changes quickly and safely. With ML, we need to extend this idea to data and models too.
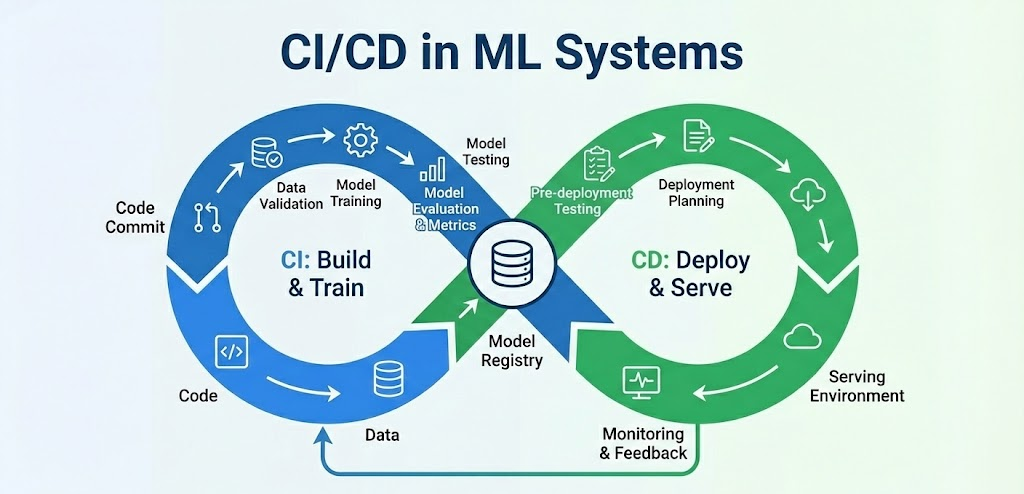
This means our pipelines must not only run code tests, but also validate input data, retrain models, track model metrics, and then deploy or push those models.
So let's go ahead and dive deeper into the various aspects, starting with CI for ML systems.
CI for ML
Continuous Integration for ML means automating the validation of everything upstream of deployment: data, code, and model.
The goal is to catch problems early (at commit time) before a model is deployed. This section breaks CI into three parts unique to ML: Data CI, Code CI, and Model CI.
Data CI: validating data
In ML, data is essentially "code", it defines model behavior. Therefore, integrating new data (or data pipelines) requires rigorous checks just like new code does.
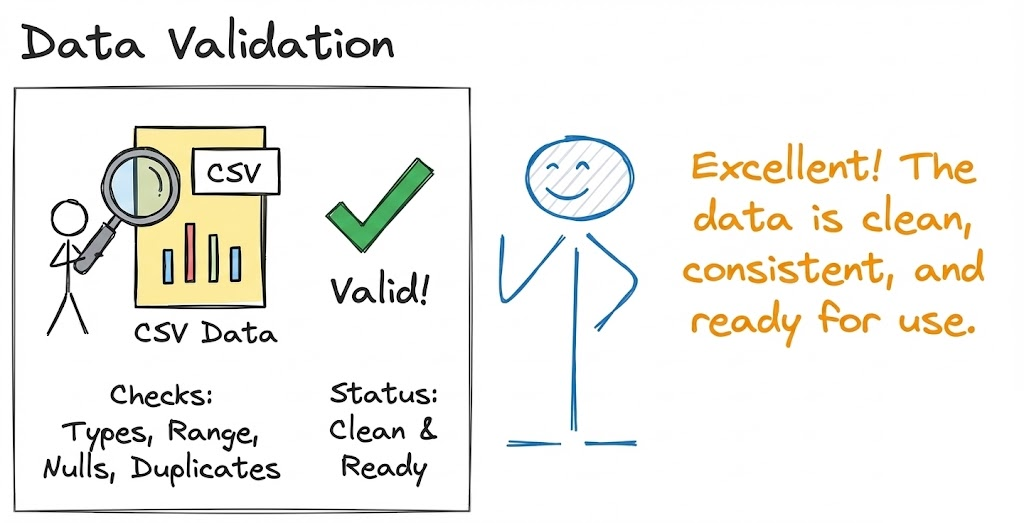
Data CI focuses on automatically testing data quality and detecting data drift as part of the integration process.
Schema and quality checks
Whenever new data is ingested or a new dataset version is used for training, the pipeline should validate that the data meets the expected schema and values.
Tools like Pandera allow you to define explicit expectations or schemas for data. For example, you can assert that certain columns exist, data types are correct, no critical nulls or out-of-range values, etc.

These checks can run in CI to prevent training on corrupt or invalid data. Using data validation frameworks (e.g., Pandera) enables schema checks and automated anomaly detection on your data pipeline.
For instance, using Pandera (version 0.27.0) we can define a schema and validate a Pandas DataFrame in a test:
This little script loads a CSV file into a pandas DataFrame and then uses a Pandera model called TrainingDataSchema to make sure every column in that DataFrame satisfies the rules declared for it.
The schema specifies that feature1 must be a non-null floating-point value greater than zero, feature2 must be an integer between zero and one hundred (inclusive), and label must be an integer equal to either zero or one.
When the DataFrame is validated using validate with lazy=True, Pandera checks every row and collects all violations instead of stopping at the first error.
The code wraps this validation in a try/except block so that if the data fails the schema checks, the exception provides a compact table (failure_cases) showing exactly which rows and values broke which constraint, along with a count of total errors.
If the data passes all checks, the script simply prints that validation succeeded.
In a CI context, this could be part of a test that fails if the data doesn't conform.
Data tests like this ensure that upstream data issues (like a schema change or unexpected distribution shift) are caught early, rather than silently corrupting the model training.
Data drift checks
Data drift refers to changes in the statistical distribution of data over time. While data drift is often monitored in production, you may also integrate drift detection in CI when new data is used for retraining.
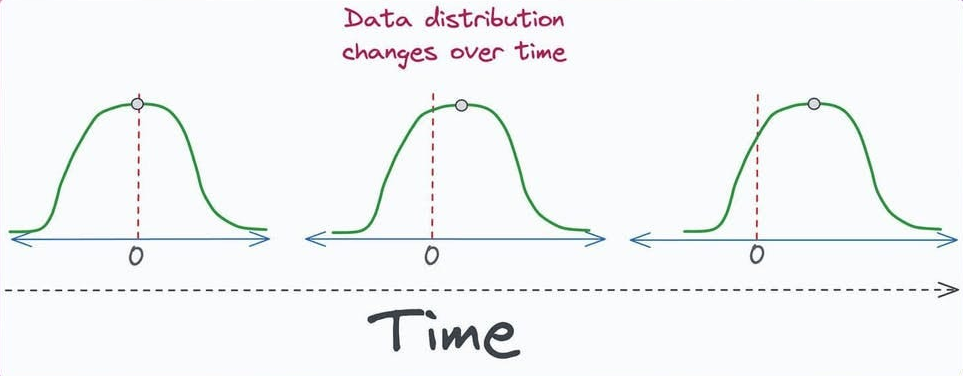
For example, if a new training dataset is significantly different from the previous training data, you might want the pipeline to flag it before retraining (especially if such drift is unintended).
Tools like Evidently AI can help with that. You can programmatically compare a new dataset against a reference dataset and get a drift score.
We covered Evidently AI in Part 17 of this course, you can check it out below:

In CI, this could prevent retraining a model on data that is too different without additional review. Often, significant drift might require updating data processing or a model retraining strategy.
Data versioning
To enable reproducibility and continuous integration of data, teams use data version control tools like DVC. These tools let you track dataset versions similar to how Git tracks code versions.

In CI, you can then pull specific data snapshots for training or testing. For example, DVC can store data files in remote storage and link them to Git commits.
A CI pipeline might want to fetch the exact version of a dataset corresponding to the current code version before running tests or training. This ensures that experiments are reproducible and that model training in CI is using the correct data.
Tools such as DVC integrate with Git to track large data files and even pipeline dependencies, allowing reproducible training when data changes.
We covered versioning of data with DVC in Part 3 of this course, you can check it out below:

In summary, Data CI treats data as a first-class citizen in integration tests. It guarantees that any new data entering the pipeline is valid, and it keeps an eye on distribution changes. This prevents “data bugs”, which can be just as harmful as code bugs, from propagating to model training.
Next, let's go ahead and take a look at CI for code.
Code CI: testing code
Code continuous integration for ML looks much like traditional CI on the surface: you run unit tests, enforce code style, and perform integration tests. However, the content of these tests is tailored to ML pipeline code.
Unit tests
Our feature engineering functions, data loaders, and utility functions can have unit tests. For example, if we have a function preprocess_data(df) that fills missing values or scales features, write tests for it using small sample inputs.
If you have a custom loss function or metric, test it on known inputs. These tests catch logical bugs early.
Example: If one_hot_encode() is supposed to produce a fixed set of dummy columns, a unit test could feed a sample input and verify the output columns match expectations.
Pipeline integration test (small training run)
A unique kind of test in ML CI is a small-scale training run to catch pipeline integration issues.
This isn't about achieving good accuracy, but rather about making sure the training loop runs end-to-end with the current code and data schema.
For example, you might take a tiny subset of the data (or synthetic data) and run one epoch of training in CI, just to ensure that the model can train without runtime errors (and perhaps that the loss decreases on that small sample).
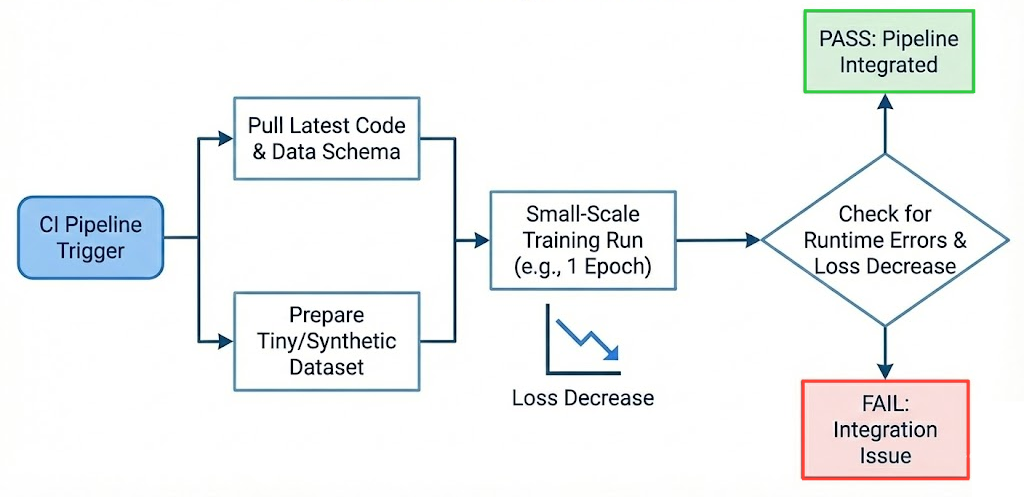
This can catch issues like misaligned tensor dimensions, incompatible data types, or broken training scripts that unit tests might miss.
Configuration and dependency checks
ML projects often have configuration for hyperparameters, data paths, etc. A CI process can validate these too. For example, if you use a config YAML or JSON, you might have a test to load it and ensure required fields exist.
Additionally, because ML code depends on many libraries (numpy, pandas, torch, etc.), it's a good practice to pin versions and record dependencies. This avoids the classic “it works on my machine” issue when deploying code.
Property-based tests
We must understand that tests in ML can be brittle if they rely on exact outputs, since adding new data or changing logic can make a comparison fail. Instead, focus on properties.
For example, if adding more data should not reduce the length of the output, test for that. If a function is supposed to normalize data, test that the mean of output is ~0. If the sum of the model’s prediction probabilities should sum to 1, test that property. These are more robust than testing for an exact prediction value.

The main point for Code CI is: treat your ML pipeline code like normal software. Write tests for data transformations, model training routines, and even the inference logic (e.g., a test could call the model’s predict on a known input to see if it returns output of expected shape and type).
By continuously integrating code changes with tests, you ensure that refactoring or new features (like trying a new preprocessing step) don’t break existing functionality.
Next, let's go ahead and take a look at CI for models.
Model CI: testing models and quality
Beyond code and data, we also need to continuously test the model artifact and its performance. This is where ML CI adds new types of tests not seen in standard software:
Performance metric thresholds
After training a model (even in CI on a smaller scale or with a previous training run), you should automatically evaluate it on a validation set and verify key metrics.
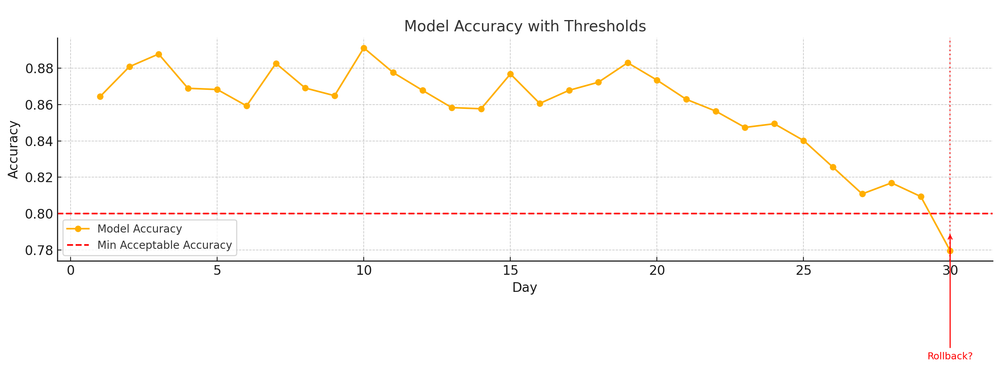
For example, if you expect at least 85% accuracy on the validation data, your CI can assert that. If the model underperforms (maybe due to a bug or bad data), the pipeline should fail rather than deploy.
In practice, teams define "failure thresholds", e.g., if the new model’s AUC drops 5 points below the current production model, do not promote it.
Reproducibility tests
A tricky aspect of ML is randomness. You should aim for reproducible training (set random seeds, control sources of nondeterminism). As part of CI, you might run a reproducibility test: train the model twice with the same data and seed, and confirm that you get the same result within certain tolerance, in cases.
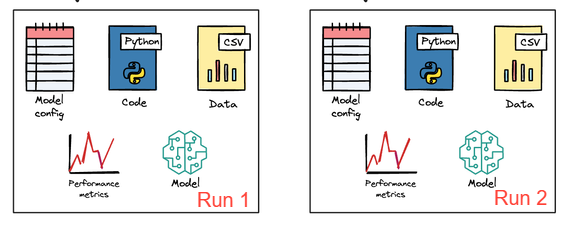
If a model is truly deterministic given a seed, then any drift might indicate non-deterministic behavior or external issues. This test might be expensive so perhaps not run on every commit, but it’s valuable when establishing a pipeline.
Another approach is comparing model outputs to a stored “baseline” output for a few sample inputs, plus, instead of storing entire output datasets, you can store expectations about them (like distribution, ranges) so that tests are less brittle.
Bias and fairness checks
ML integration tests can also include checks for ethical or regulatory concerns. For instance, after training, you might compute metrics across protected subgroups (male vs female, etc.) to detect large disparities. Tools like IBM’s AI Fairness 360 can automate parts of this.
Model artifact checks
Once a model is trained, there are some practical things to test about the artifact:
- Size check: If the model file is too large (maybe someone accidentally saved a model with debug info or a very high number of parameters), it could be impractical to deploy. A CI step can ensure the model file (e.g.,
model.pklormodel.onnx) is under a certain size. - Dependency check: Ensure that all libraries needed to load and run the model are accounted for. For example, if you use
pickleorjoblibfor a scikit-learn model, loading it requires the same Python environment with those library versions. If you export to ONNX, ensure your serving environment has an ONNX runtime.

- Serialization format validation: If you use a specific format, you might run a quick test that tries a round-trip: save the model, then load it back and see if it still predicts the same on a sample input. This catches issues where the model might not be properly serializable.
To summarize: Model CI introduces automated “gates” based on model evaluation. Instead of relying purely on a human to review a training run, the CI will fail fast if the model isn’t up to par (performance-wise or other checks).
These tests give confidence that models which pass CI are at least likely to be good candidates for deployment, or at least they aren't obviously bad.
With this, we now understand what continuous integration is, let's go ahead and explore continuous delivery (CD) for ML.
CD for ML
Continuous Delivery (CD) for ML takes the artifacts and results from CI (code, data, model that passed tests) and automates the process of packaging, releasing, and/or deploying them.
ML CD has to handle releasing not just application code, but also new model versions. It often integrates with specialized infrastructure like model serving platforms or orchestration on Kubernetes.
Let’s break down key aspects of CD for ML: