MLOps and LLMOps: Case Studies
An exploration of real-world MLOps and LLMOps case studies, examining the importance of reliable ML and AI engineering and their significance for business outcomes.
Introduction
Several AI/ML systems do not just fail because the model is not good enough. They fail because everything around the model was not built to last.
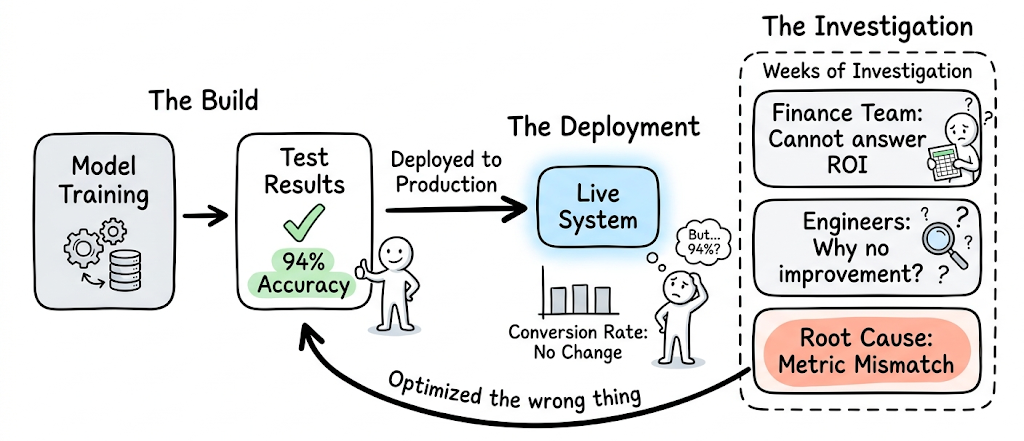
Consider a scenario: A team trains a model, it performs well in tests, and it is deployed to production. Yet conversion rates remain flat. A question from the finance team cannot be answered. Engineers spend weeks investigating why a recommendation system with 94% accuracy is making the product no better. This is not an edge case, rather a reflection of how real-world systems behave.
The companies that eventually get this right, do so by learning lessons that do not always have much to do with algorithms. Their progress comes from how they design systems, handle constraints, and adapt to failure.
This article is the final piece in our MLOps/LLMOps course. Here, we take a look at concrete, real-world examples. We examine a set of carefully chosen case studies drawn from real systems. Each case study focuses on the decisions that shaped the system, why specific approaches were chosen and the constraints teams operated under.
The examples span big tech, fintech, banking, e-commerce, etc. offering a grounded view of how modern AI/ML systems are actually built and sustained.
#1) The fundamental misunderstanding
Booking.com: Model performance ≠ Business performance
In 2019, Booking.com published a paper at KDD that has changed how most companies today think about ML.
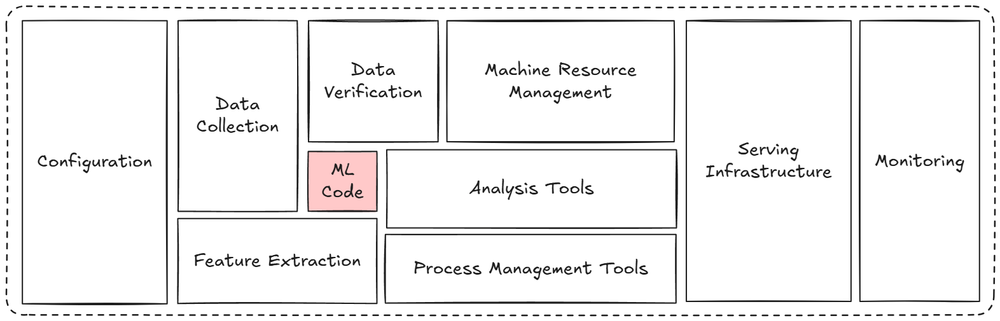
It described 150 deployed production models and one uncomfortable lesson: improving a model's accuracy often did not improve the business metric it was supposed to affect.
There were several reasons for this:
- Value saturation: the model had already captured most of the available gain, and further accuracy improvements had nothing much left to unlock.
- Segment saturation: when testing a new model against the current one, the two models increasingly agree on what to show users, shrinking the population actually exposed to any difference. The testable segment becomes too small to move aggregate metrics.
- Proxy metric over-optimization: the model had learned to maximize something measurable that was only loosely correlated with what the business actually cared about.
- Uncanny valley effect: as a model becomes too accurate (predicting user behavior so precisely that it feels like the system knows too much), it can unsettle users, producing a negative effect on business value.
Their solution was to treat randomized controlled trials (RCTs) as mandatory infrastructure, not optional validation.
This means every single model gets validated through an RCT before it stays in production. This was not a qualitative review or a conversation about the AUC, but rather an actual experiment measuring whether users behaved differently in a way that matters to the business.
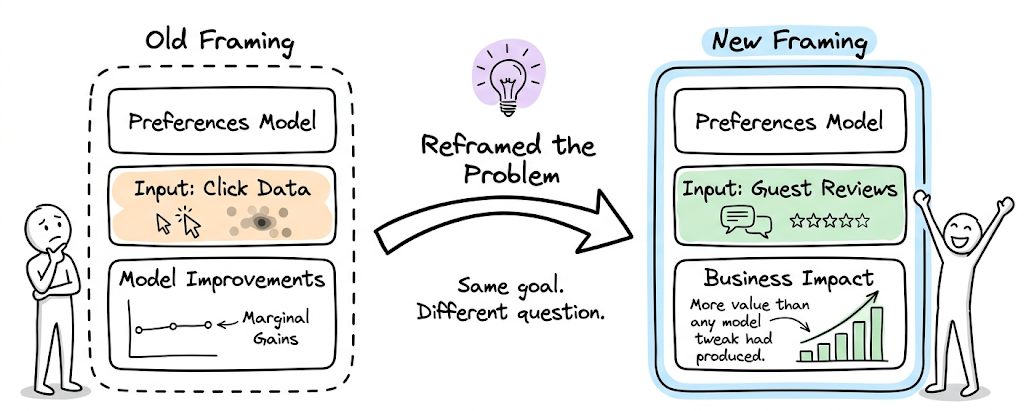
The deeper insight was about how teams construct problems. Switching a preferences model from click data to natural language processing on guest reviews produced more business value than any model-level improvement had. The framing of the problem and project scoping mattered more than the sophistication of the solution.