Context Engineering: Foundations, Categories, and Techniques of Prompt Engineering
LLMOps Part 5: An introduction to prompt engineering (a subset of context engineering), covering prompt types, the prompt development workflow, and key techniques in the field.
Recap
In Part 4, we explored key decoding strategies, sampling parameters, and the general lifecycle of LLM-based applications.
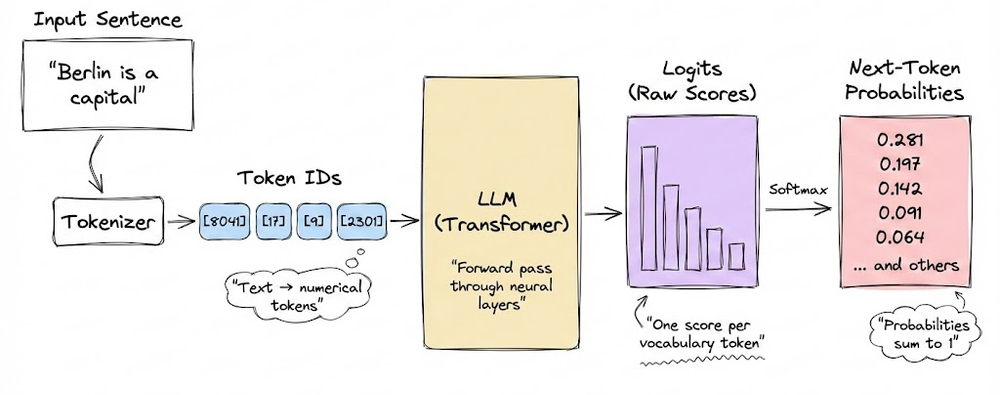
We began by introducing the concept of decoding, and how it functions. We explored the key decoding strategies in detail: greedy decoding, beam search, top-K, top-P, and min-P strategies.
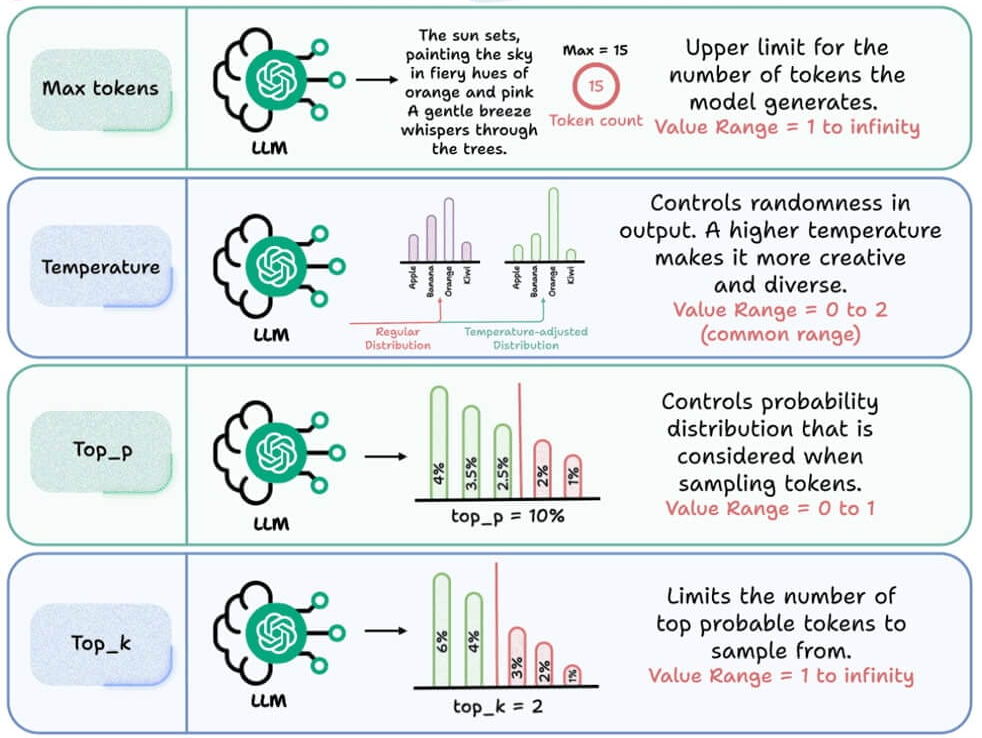
We then went ahead and understood the some of the major generation parameters, like temperature, top-P, top-K, max tokens, etc. in detail.
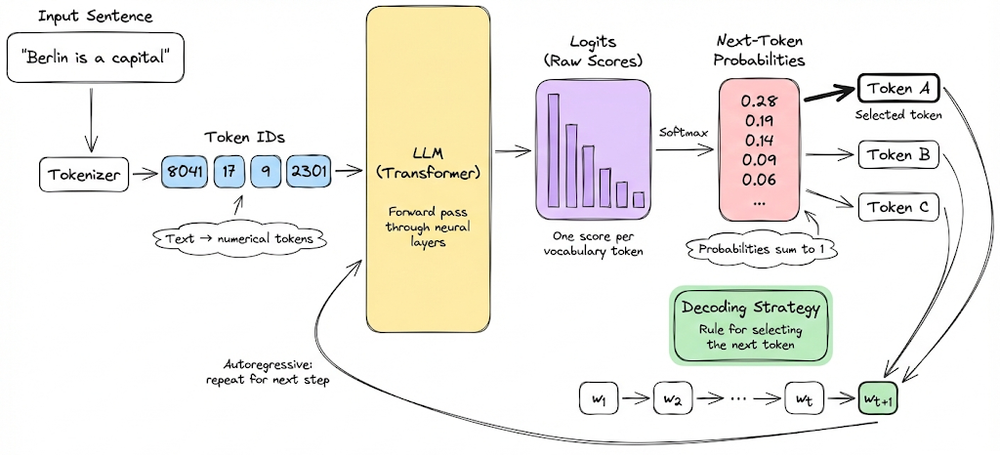
We also examined the complete text generation workflow and sketched a mental map of how LLMs function.
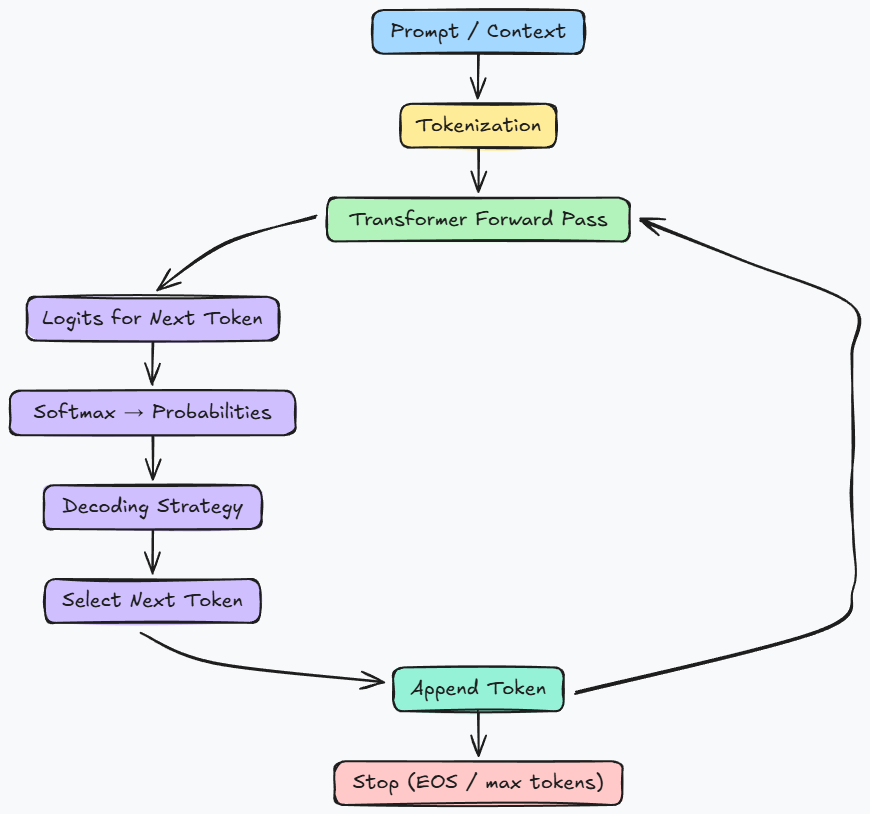
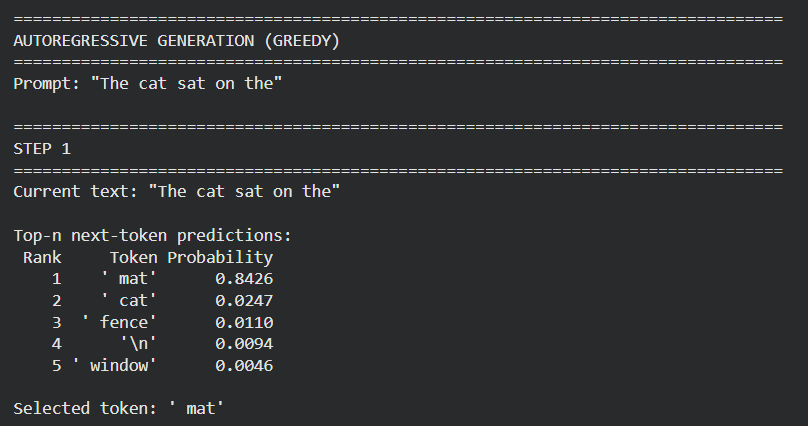
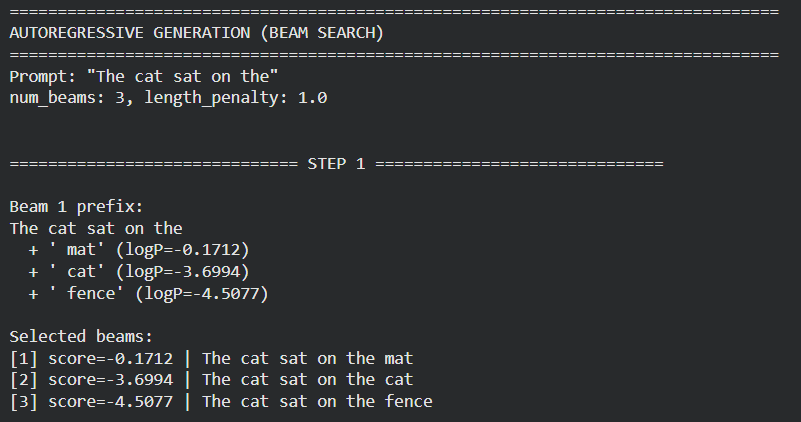
Moving ahead, we grounded the learned concepts about decoding and generation parameters with hands-on experiments. We compared the greedy and beam search decoding strategies, and showed how they operate at the token level.
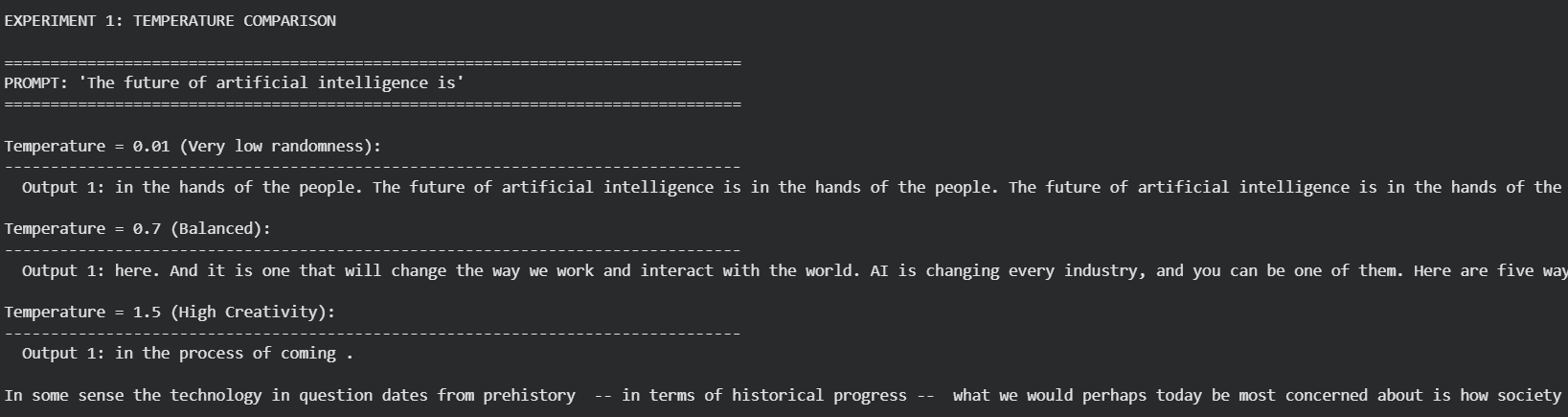
We also compared different values for generation parameters (temperature, top-P, top-K), clearly demonstrating the influence the model’s responses.

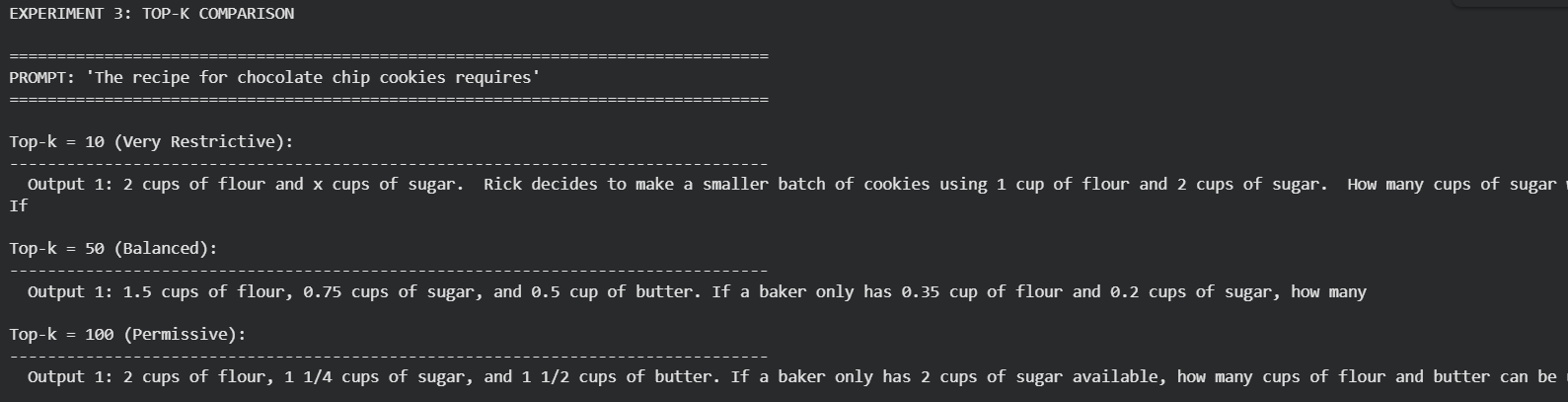
Finally, we transitioned towards more of LLMOps by exploring the general lifecycle of LLM-based applications and its different stages.
By the end of Part 4, we had developed a clear understanding of the core concepts and components underlying LLMs, along with a strong LLMOps mindset gained through understanding the application lifecycle.
Although this chapter is not strongly related to the previous part, we strongly recommend reviewing Part 4 first, as it helps maintain the natural learning flow of the series.
Read it here:

In this and the next few chapters, we will be exploring context (and prompt) engineering. This chapter, in particular, focuses on the fundamentals of prompt engineering.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Introduction
Large Language Models (LLMs) have unlocked powerful new capabilities in software, but harnessing them in production systems (LLMOps) requires more than just plugging in an API.
Two critical disciplines have emerged in recent years:
- Prompt engineering
- Context engineering
Prompt engineering focuses on how we design the textual inputs (prompts) to guide an LLM’s behavior, while context engineering is about managing the entire information flow, structuring the surrounding data, tools, and environment that feed into the model. Together, these techniques enable us to build reliable and efficient LLM-powered applications.
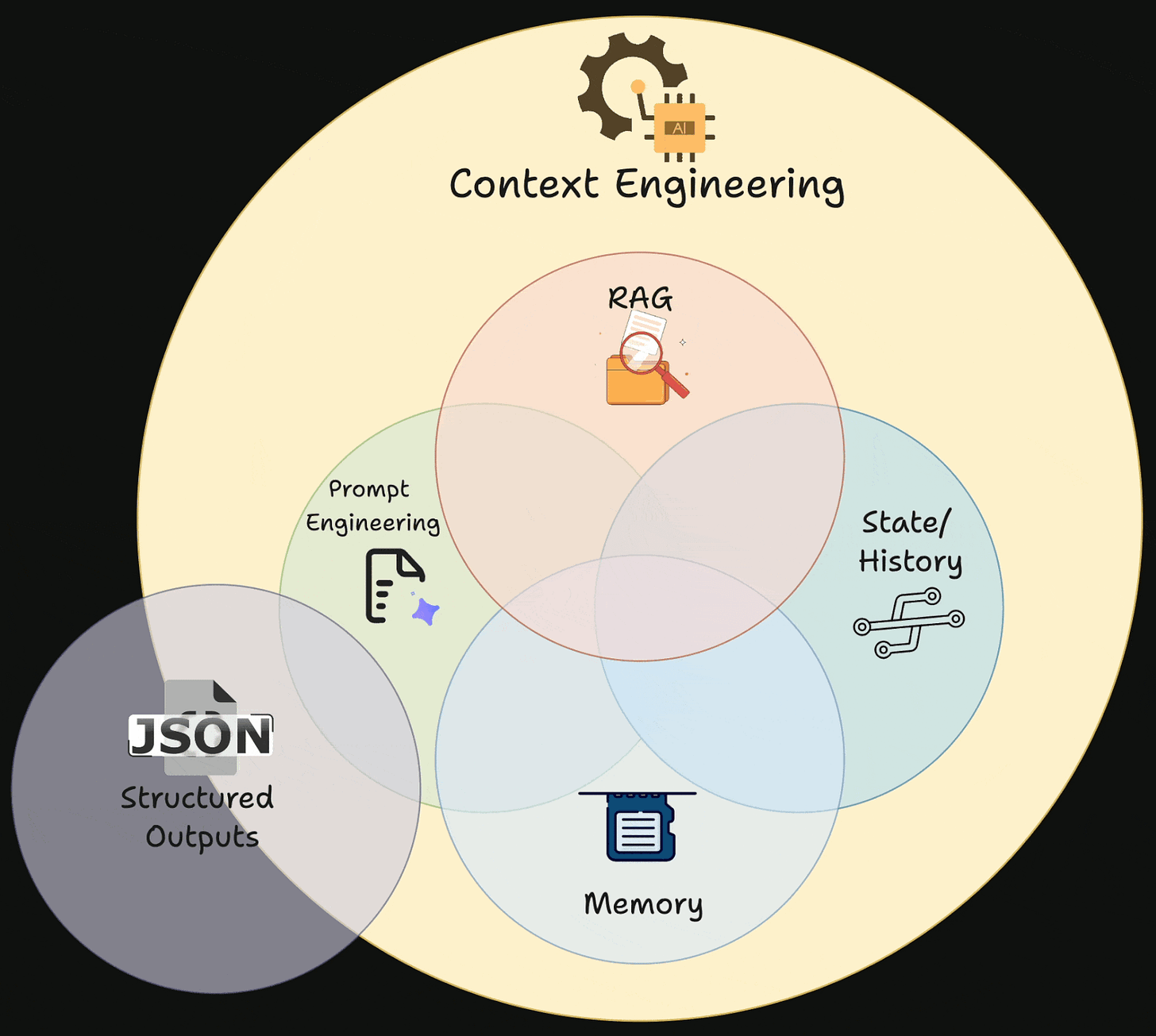
Now let’s go ahead and explore the core concepts of prompt engineering, a key subdomain of context engineering. We will begin with the fundamental principles, followed by a practical workflow for developing effective prompts. Finally, we will examine various prompt types and advanced prompting techniques.
Fundamentals of prompting
A prompt is the input given to an LLM to draw out a response, it can be a question, instruction, or any text the model completes or responds to.
From an engineering perspective, a prompt is not just casual text; it is a piece of logic we design to program the model’s behavior (often called “soft programming”).
In essence, prompt engineering means writing instructions that effectively leverage the knowledge already present in the model. Unlike traditional software where we write deterministic code, prompting is more of an interactive, probabilistic programming: we guide a black-box model with instructions, then observe how it behaves, and refine our approach.
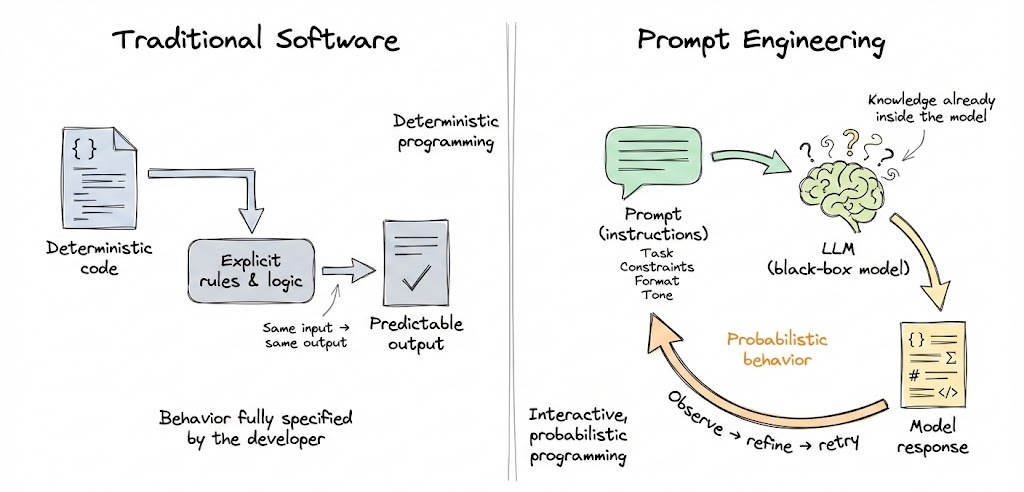
Why is prompt engineering needed?
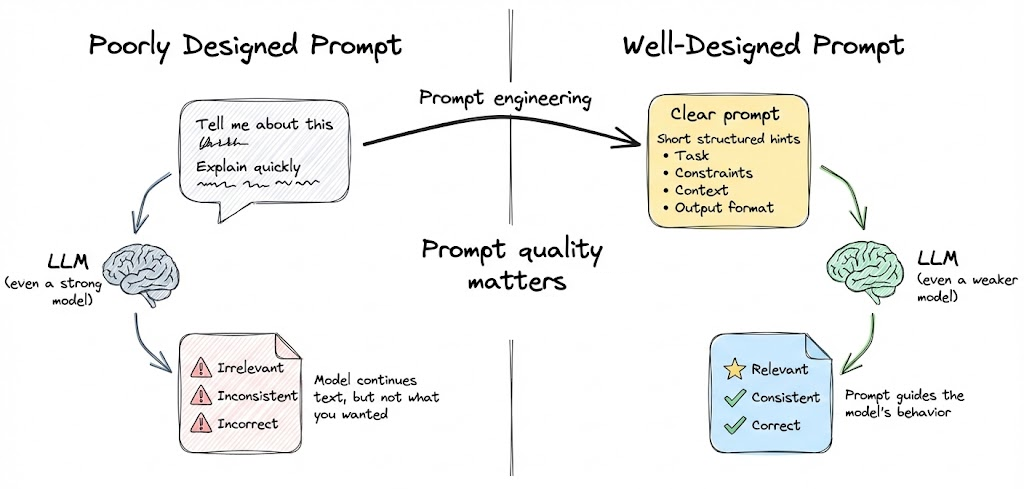
LLMs are trained to continue text in a plausible way, but to get the specific output we want, we must craft the input skillfully. A poorly designed prompt can lead to irrelevant, inconsistent or incorrect outputs, even from a very capable model.
On the other hand, a well-designed prompt can make even a weaker model perform surprisingly well on a given task. Prompt engineering has therefore become “the skill of designing prompts that guide a generative AI model toward the kind of response you actually want”.
The system perspective
From a system standpoint, prompting is a first-class component of the application. We treat prompts like code: we design them methodically, test them, version-control them, and continuously improve them.
Importantly, prompt engineering is often the most accessible way to adapt an LLM to your needs without model retraining. It requires no updates to the model’s weights, instead, you leverage the model’s already present knowledge by providing instructions and context.
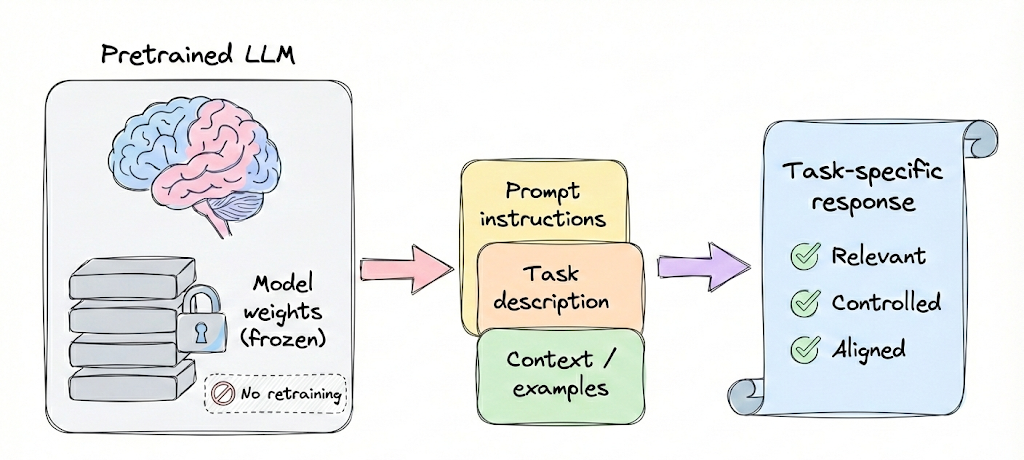
This makes prompt engineering fast to iterate on and deploy, which is why many early LLM applications relied solely on prompting. However, it’s not a silver bullet, more complex tasks often require going beyond skillful prompting to exploring a broader context pipeline, fine-tuning, or additional data.
In-context learning
Prompting is closely tied to the concept of in-context learning. Researchers discovered with GPT-3 that large models can learn tasks from examples given in the prompt itself, without any parameter updates.
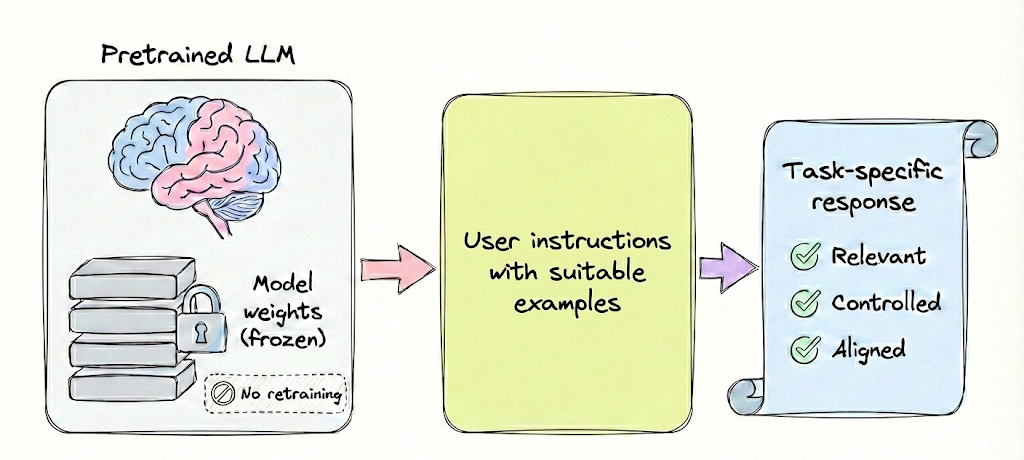
For instance, if you prompt the model with a few example question-answer pairs (few-shot prompting), the model can infer the pattern and apply it to a new question. If you provide no examples, expecting the model to solve the task from just instructions, that’s zero-shot prompting.
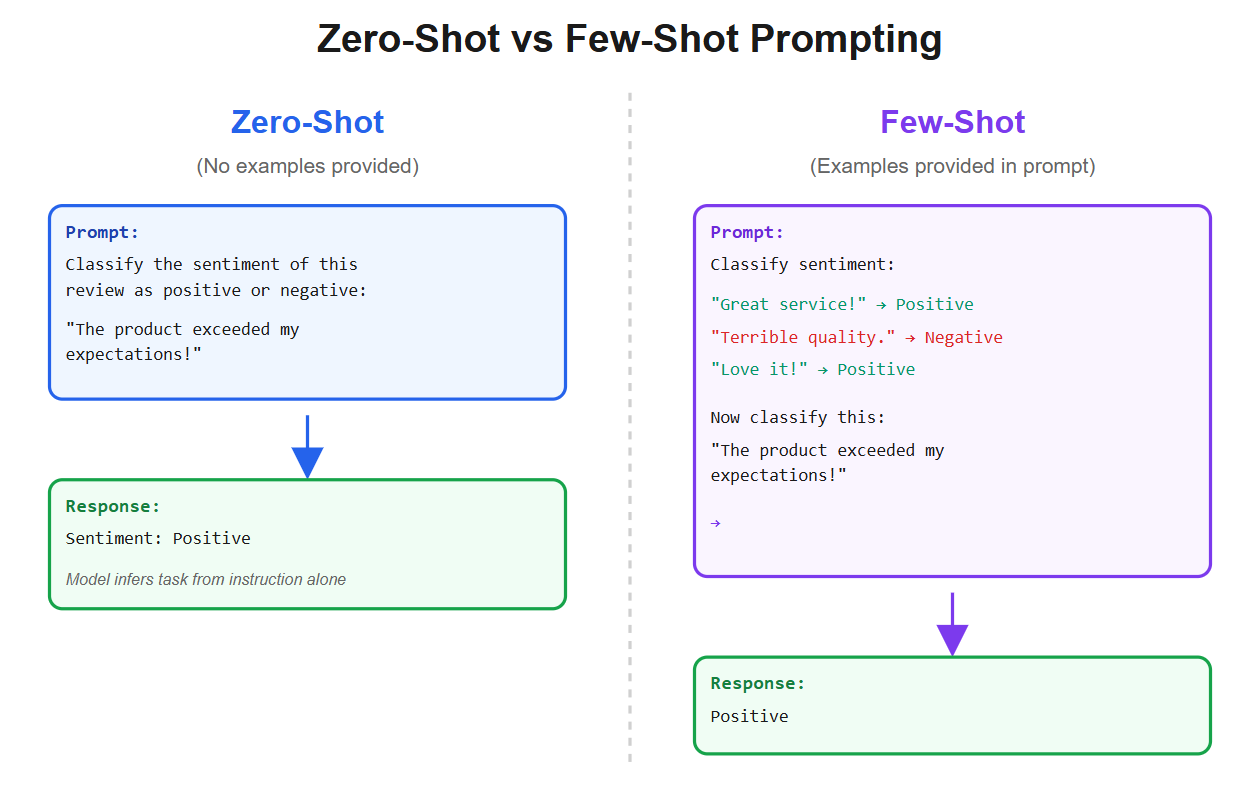
Few-shot prompting (sometimes called few-shot in-context learning) often improves accuracy by showing the model what format or style of answer is expected. For example, adding 5 examples makes it a “5-shot” prompt. GPT-3’s paper “Language Models are Few-Shot Learners” highlighted this ability.
However, there are diminishing returns with newer advanced models: experiments have shown GPT-4 sometimes doesn’t gain much from few-shot examples on certain tasks compared to zero-shot. This is likely because newer models are better at following instructions out-of-the-box, so a clear zero-shot instruction often suffices for them.
But in niche domains, a few examples can still boost performance significantly if the model’s training data lacked those patterns. In practice, you should experiment to find the optimal number of examples for your task: balancing performance versus the added prompt length (which increases cost and latency).
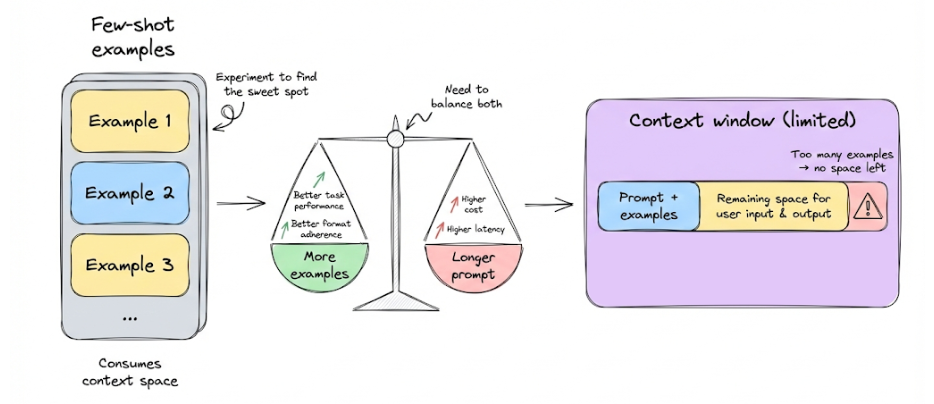
Note that few-shot prompts use up context space, so you can’t include too many examples given the context window is limited.
In summary, the fundamental idea is that prompts provide both instructions and context to the model. They can include a description of the task, relevant information or data, and examples of the task being performed.
Overall, prompt engineering is fundamentally about constructing these elements in a way that the model reliably produces the desired behavior. We now turn to a systematic approach to developing prompts.
Systematic prompt development workflow
Developing an effective prompt is an iterative engineering process. Rather than guess-and-check ad hoc, it helps to follow a structured workflow:
Define the task and success criteria
Start by clearly defining what you want the model to do (e.g., “extract the total price from an invoice email and output a JSON”). Identify what a correct output looks like and any constraints (formatting, tone, length, etc.).
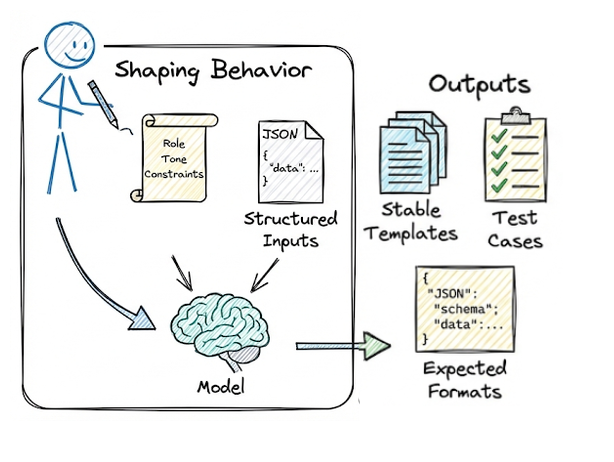
This is analogous to writing a spec; it will guide your prompt design and evaluation criteria.
Draft an initial prompt
Create a first version of the prompt. At a minimum, state the instruction clearly. Depending on the task, you might include some examples or a specific format.