Concepts of LLM Serving
LLMOps Part 14: An overview of the fundamentals of LLM serving, including API-based access, inference with vLLM, and practical decisions.
Recap
In the previous chapter (Part 13), we explored how LLM inference actually works and how to optimize it.
We began by grounding ourselves in the core performance metrics such as TTFT, TPOT, throughput (TPS/RPS), latency percentiles, and goodput.
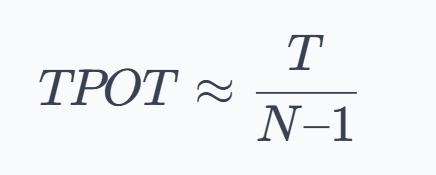
We then built a precise mental model of inference by breaking it into two distinct phases: prefill (compute-bound) and decode (memory-bound).
This distinction became central to understanding why different optimizations work the way they do.
From there, we explored key optimization techniques across the inference stack, starting with continuous batching to maximize GPU utilization and throughput under variable-length workloads.
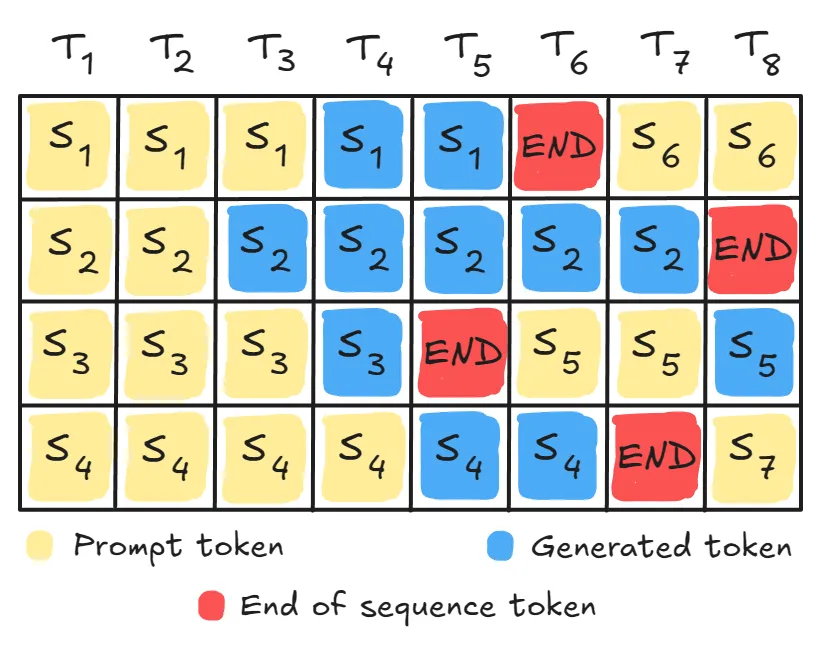
Then we understood about KV caching to eliminate redundant computation and essentially trade compute for memory.
After KV caching, we learned about PagedAttention & prefix caching to fix memory fragmentation and reuse shared prefixes across requests, significantly improving effective memory usage and throughput.
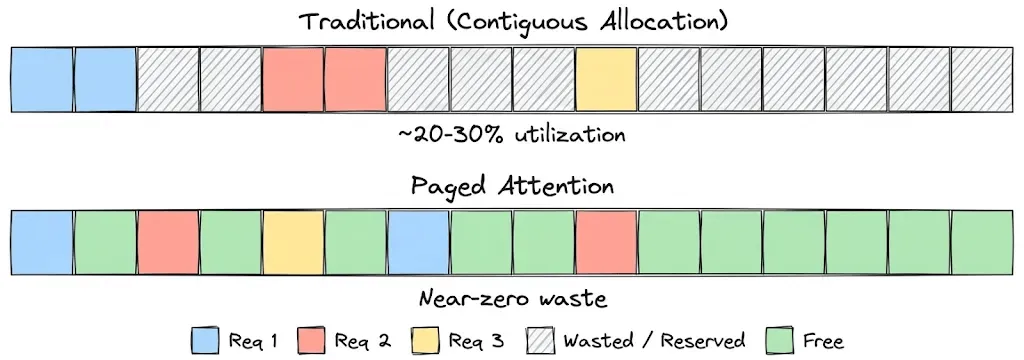
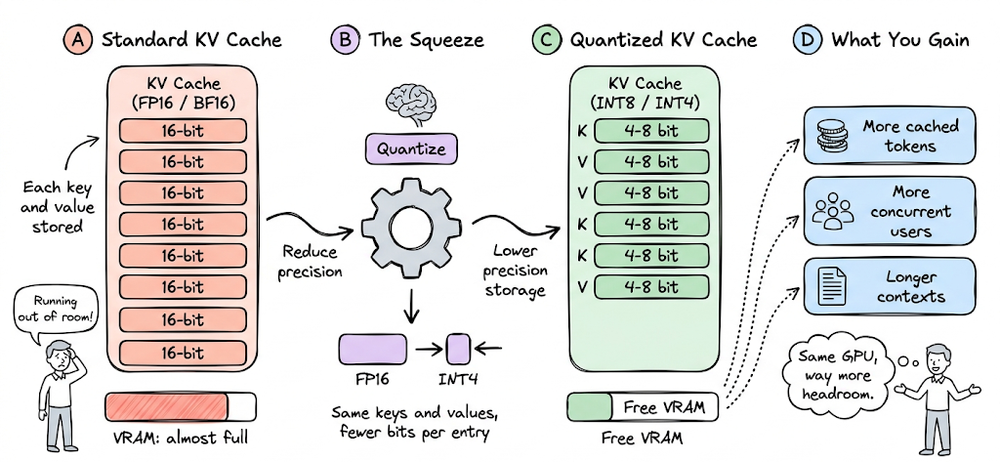
We also saw that KV cache quantization can further reduce memory footprint and enable larger batch sizes or longer contexts.
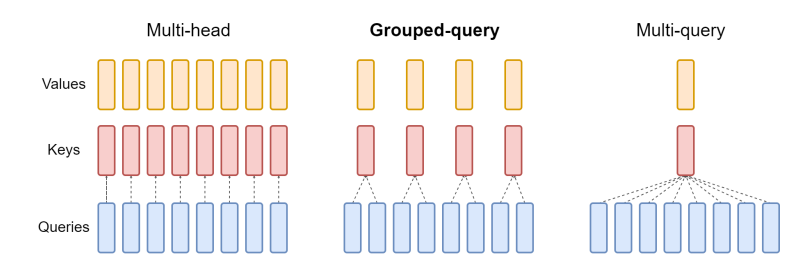
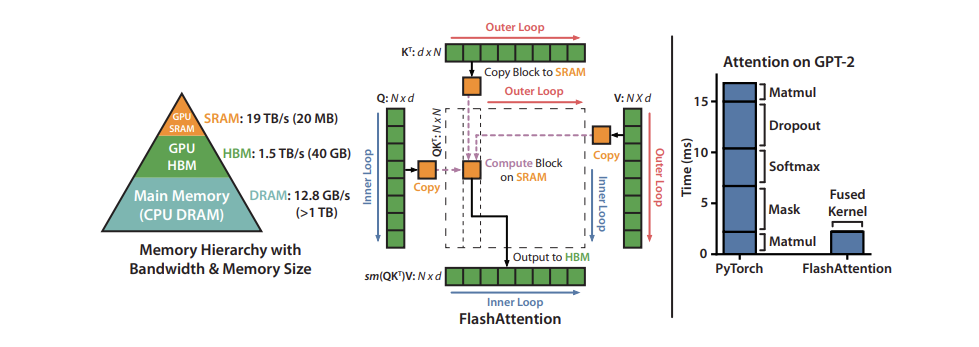
We then looked at attention-level optimizations, including MQA, GQA, and FlashAttention.
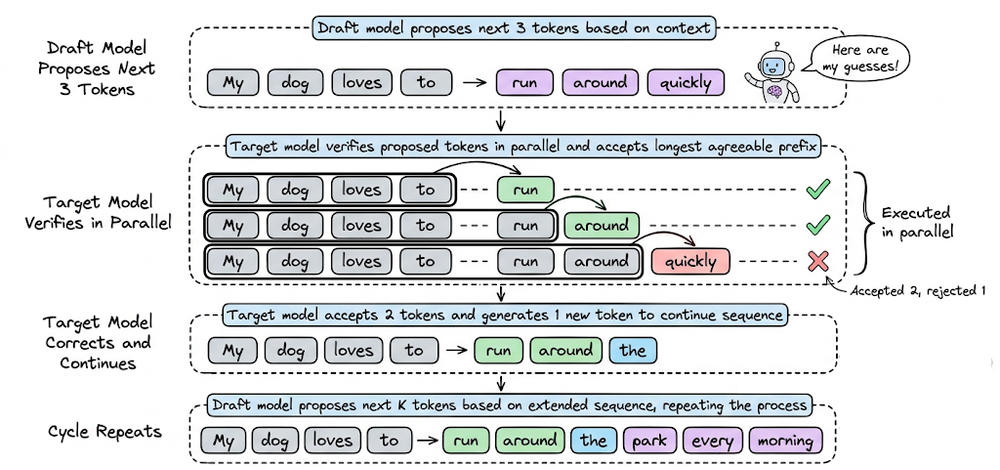
Next, we explored speculative decoding, which leverages a smaller draft model to accelerate generation without sacrificing output quality, along with its practical trade-offs like acceptance and memory overhead.
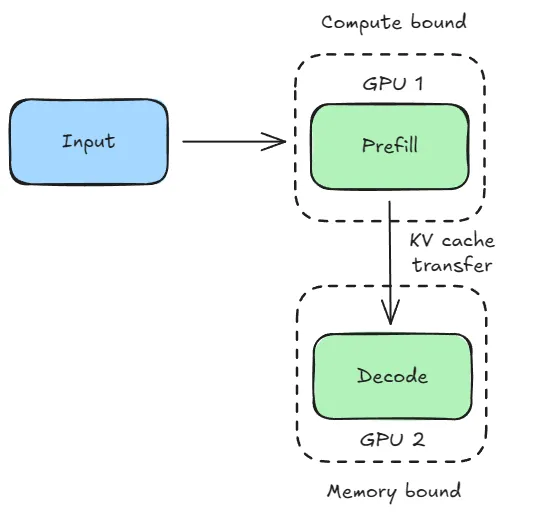
We also discussed prefill-decode disaggregation, where systems separate compute-bound and memory-bound workloads across different hardware pools, and how its effectiveness depends on workload characteristics.
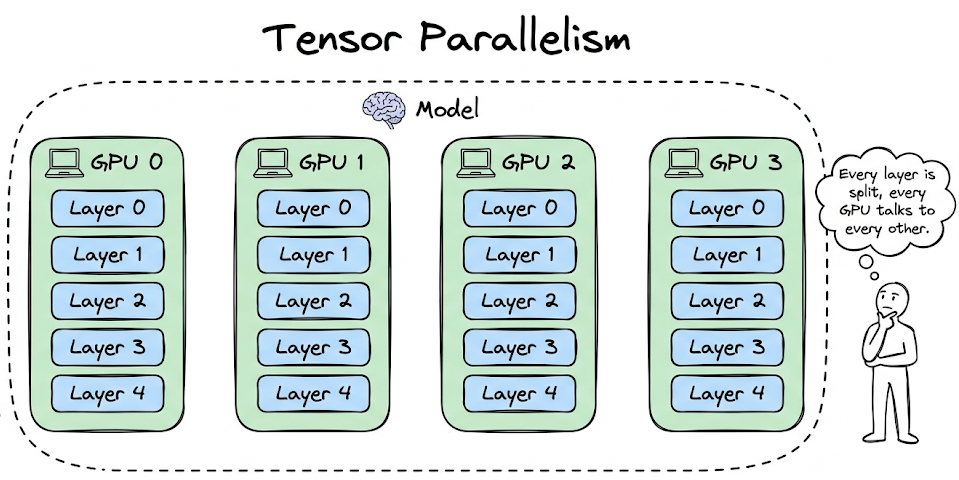
Finally, we covered parallelism strategies (data, tensor, pipeline, and expert parallelism) to scale inference across multiple devices.
Finally, we explored hands-on experiments demonstrating: the impact of KV caching, the speedup from speculative decoding, and the performance gains of vLLM.

Overall, this chapter established that LLM inference is not just about running a model, but about carefully managing compute, memory, and the trade-offs.
If you haven’t yet gone through Part 13, we recommend reviewing it first.
Read it here:

In this chapter, we will discuss the fundamentals of LLM serving, exploring self-hosting of models, API-based access, and inference with vLLM.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Introduction
If you have a language model and want to make it accessible through an API that can be invoked by others, then this article serves as the operations manual for the fundamentals of that journey.
While there are many similarities with traditional ML deployment, serving a large language model introduces a different set of challenges.
LLMs are resource-intensive, often consuming significant VRAM even when idle. In naive setups, requests might be handled sequentially, meaning a single long-running generation can block all subsequent users. Cold starts are slower, and scaling is more complex due to the heavy compute and memory requirements.
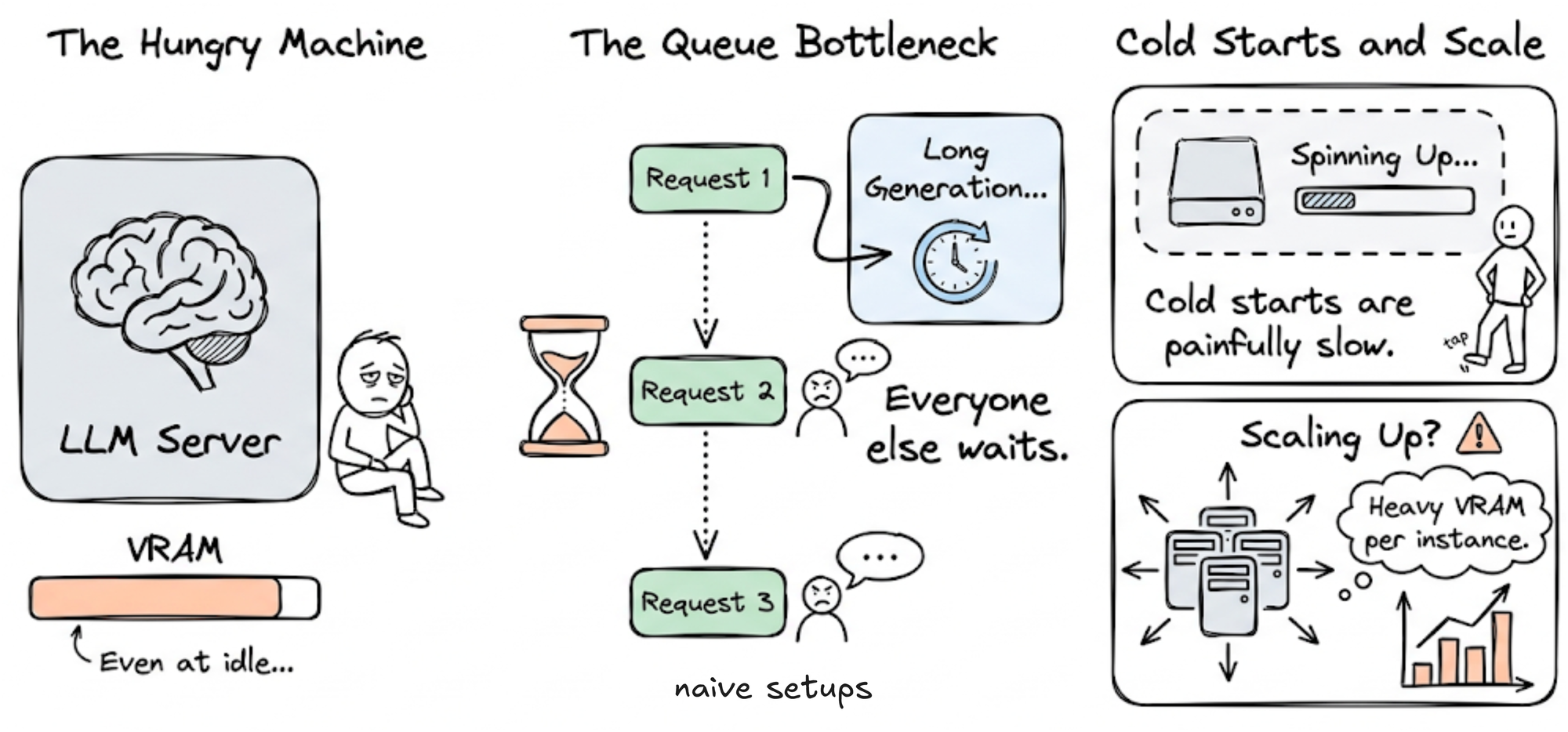
In contrast, conventional ML systems typically assume lightweight models with fast initialization and low per-request latency, assumptions that might not hold strong in the case of LLMs.
In the sections ahead, we’ll build an understanding of the core fundamentals and concepts behind serving LLMs. We'll try to leave you with enough clarity and intuition to replicate, adapt, and extend the setup demonstrated.
Accessing inference
The very first thing we need to understand is how an application will access LLM API for inference.
The LLM deployment and serving landscape broadly splits into two categories:
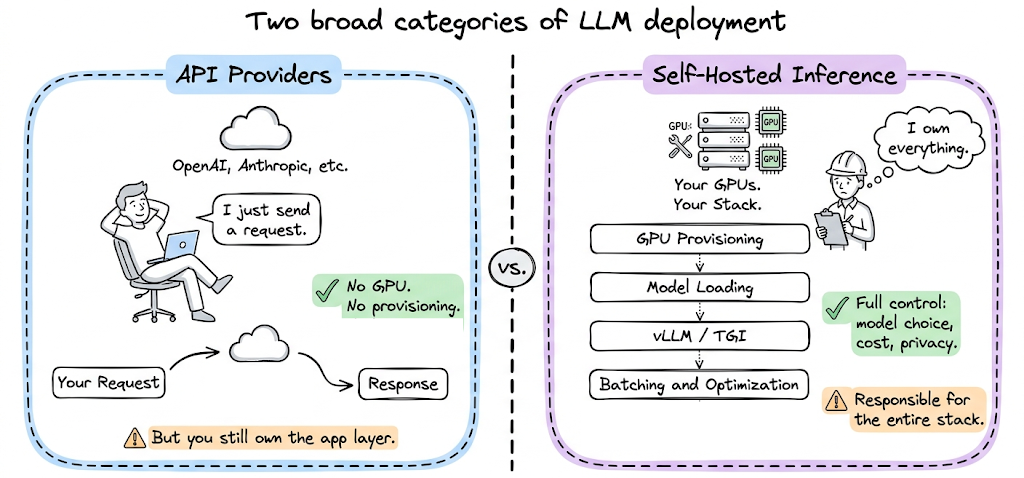
- API providers (OpenAI, Anthropic, etc.): These are inference services. You send a request, you get a response. You do not manage hardware, you do not worry about GPU provisioning, and you do not implement optimizations. The provider handles all of that. However, you still need to manage your application layer.
- Self-hosted inference: This means you run the model yourself. You provision GPUs (either on-premises or in the cloud), use a model inference and serving mechanism (like vLLM, TGI, etc.), and manage the entire stack. This gives you full control over model selection, inference configuration, data privacy, and cost structure. It also means you are responsible for everything: GPU allocation, model loading, optimization, and more.
Deployment topology
Where the model runs is a strategic decision, not just a technical one. The choice affects data security, cost structure, operational overhead, and the teams responsible for keeping things running.
On-premises
Teams choose on-prem LLM deployments primarily for three reasons: data security and compliance, predictable cost at scale, and performance control.
For regulated industries like healthcare, finance, and government, sending user data to a third-party inference API is often not an option. An on-prem deployment keeps all inference traffic inside the organization's own network perimeter. There is no data leaving the building.
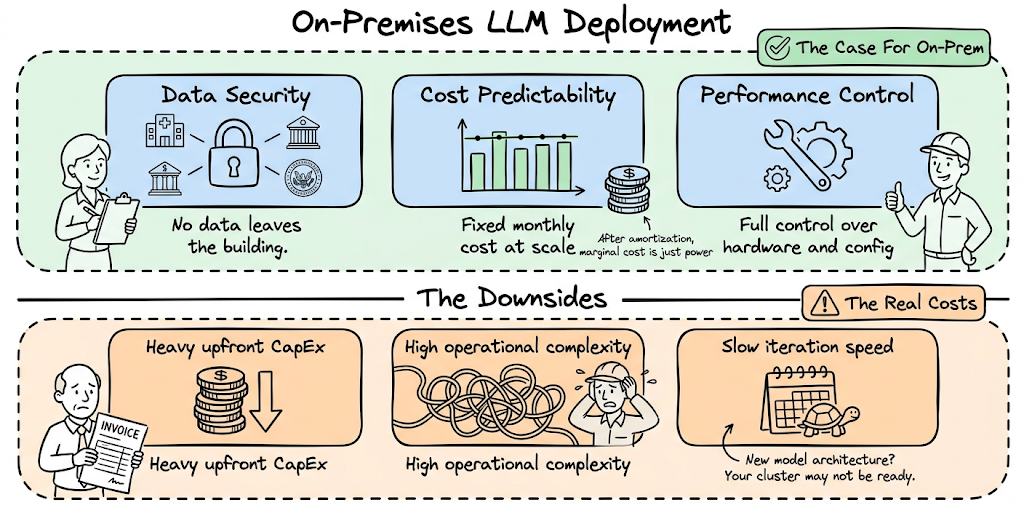
Cost predictability is the second driver. Cloud GPU pricing can be volatile, and token-based pricing from hosted API providers becomes expensive at scale. A fleet of owned or co-located GPUs has a roughly fixed monthly cost. Once the infrastructure investment is amortized, the marginal cost of additional inference is just power and operations. For steady, high-volume workloads, this math often favors on-prem.
The downsides however are also quite real:
- Upfront capital expenditure is substantial
- Operational complexity is high
- Iteration speed suffers when a new model architecture requires different hardware or driver versions and your on-prem cluster may not be ready for that.
Cloud deployments
Cloud deployments, whether managed inference APIs or self-hosted models on rented GPU instances, offer the inverse tradeoffs.
- No upfront cost.
- Access to the latest GPU generations on demand.
- Horizontal scaling in minutes.
- No capacity planning headache.
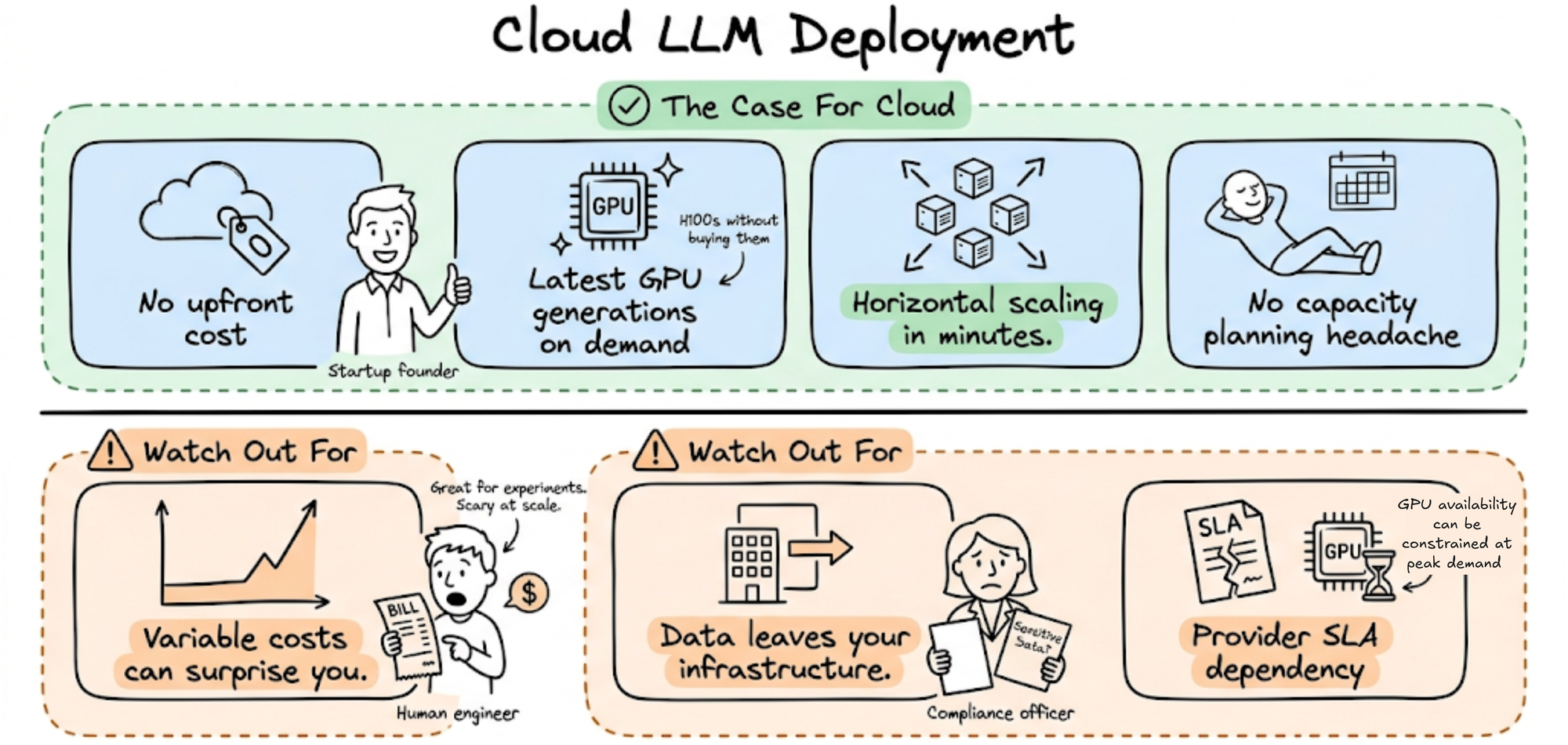
However, the costs are variable and can surprise you at scale. You pay for what you use, which is great for experimentation and bursty workloads but can scale quickly as volume grows.
Data leaves your infrastructure, which creates compliance complexity for sensitive workloads. You are also dependent on provider SLAs and GPU availability, which can be constrained during periods of high demand.
Cloud is the right default for early-stage deployments, development and staging environments, workloads with highly variable or unpredictable traffic, and any use case where speed of iteration matters more than cost optimization.
Hybrid setup
Similar to inference access patterns, many deployments end up hybrid, combining on-prem baseline capacity with cloud overflow. The pattern works as follows: steady, predictable traffic runs on owned on-prem hardware (lower marginal cost). When traffic spikes beyond on-prem capacity, overflow traffic routes to cloud GPUs that spin up on demand.