Evaluation: Multi-turn Conversations, Tool Use, Tracing, and Red Teaming
LLMOps Part 11: Understanding evaluation of conversational LLM systems, tool evaluations, tracing with Langfuse, and automated red teaming.
Recap
In part 10, we expanded our understanding of evaluation by exploring model benchmarks and the evaluation of LLM-powered applications within their real operational context.
We began by exploring model capability benchmarks. We understood that these benchmarks attempt to measure the general intelligence, reasoning ability, and knowledge breadth of large language models.
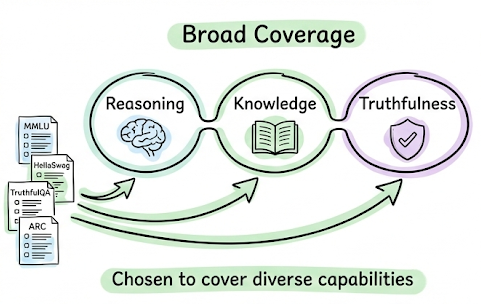
We discussed widely used benchmarks such as MMLU, HellaSwag, TruthfulQA, etc. An important takeaway from this discussion was that benchmark scores are useful for narrowing down candidate models, but they should not be treated as definitive indicators of performance for a particular application context.
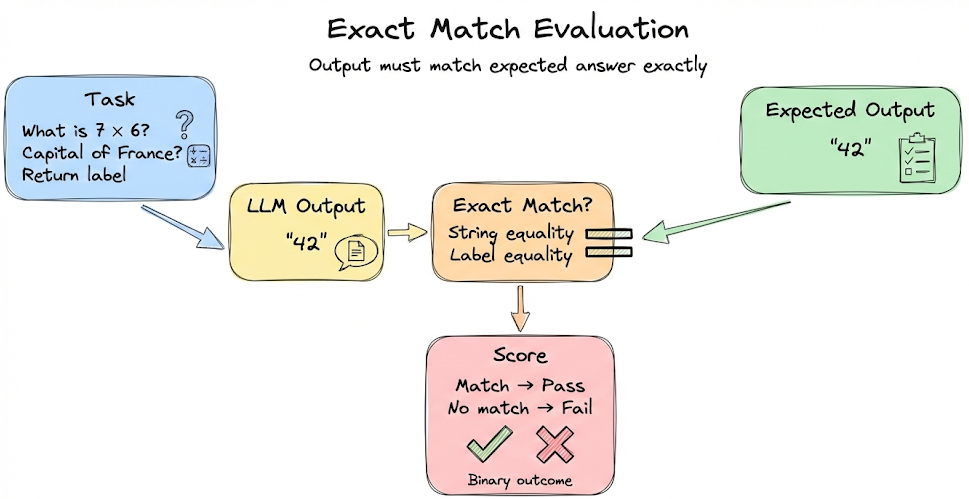
From there, we shifted our focus to application-level evaluation. We first discussed test sets. Then we examined several key evaluation metrics, including deterministic ones such as exact match, contains-answer, and token-level F1.
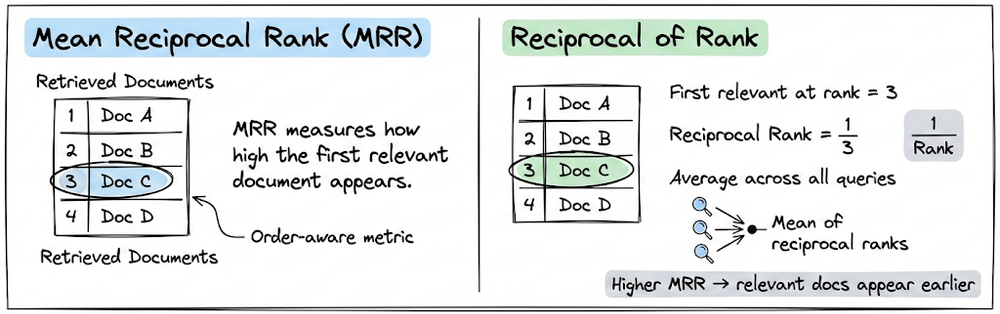
For RAG pipelines, we explored retrieval-specific metrics including Recall@K, Precision@K, and Mean reciprocal rank (MRR).
We also examined groundedness (faithfulness) evaluation, which measures whether the generated answer is supported by the retrieved context. One widely used technique here is Question-Answer Generation (QAG), which decomposes generated outputs into claims, converts them into verification questions, and checks them against the source context.
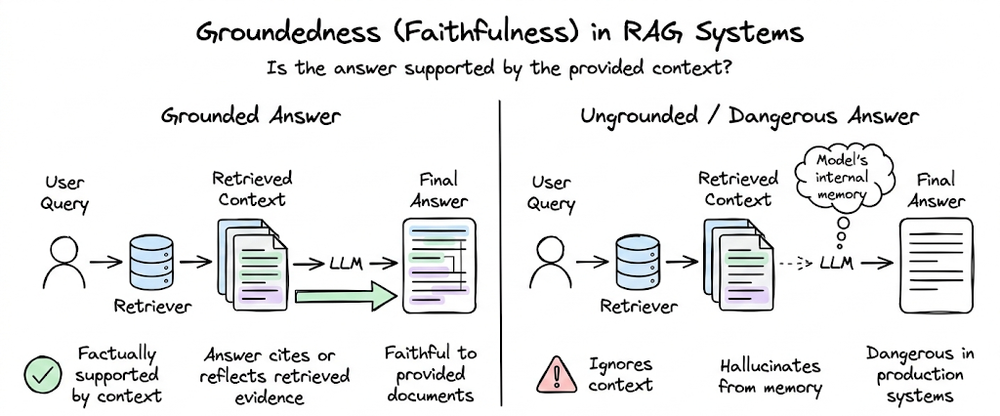
We then explored the role of LLM-as-a-Judge methods. We emphasized that the reliability of an LLM judge depends heavily on prompt, rubric design and policy layer. Building on this, we examined G-Eval, a structured LLM-based evaluation framework.
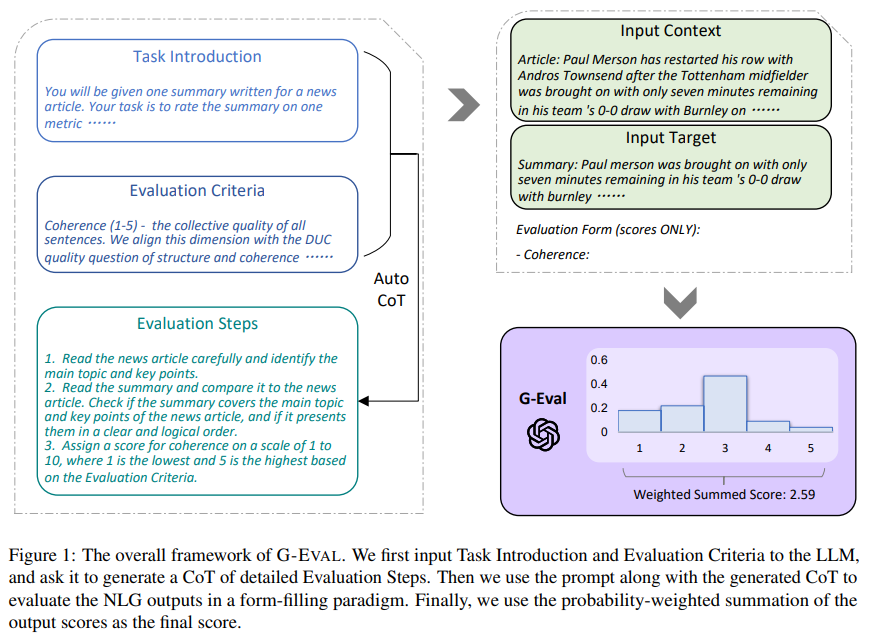
Finally, we moved into practical tooling, focusing on the DeepEval framework. Using DeepEval, we demonstrated how to define test cases, attach evaluation metrics, and run evaluation programmatically. We also looked at how DeepEval supports RAG evaluation. Additionally, we explored DAG-based evaluation. DAG metrics are particularly useful for evaluations such as checking structure, verifying the presence of required sections, or enforcing formatting constraints.
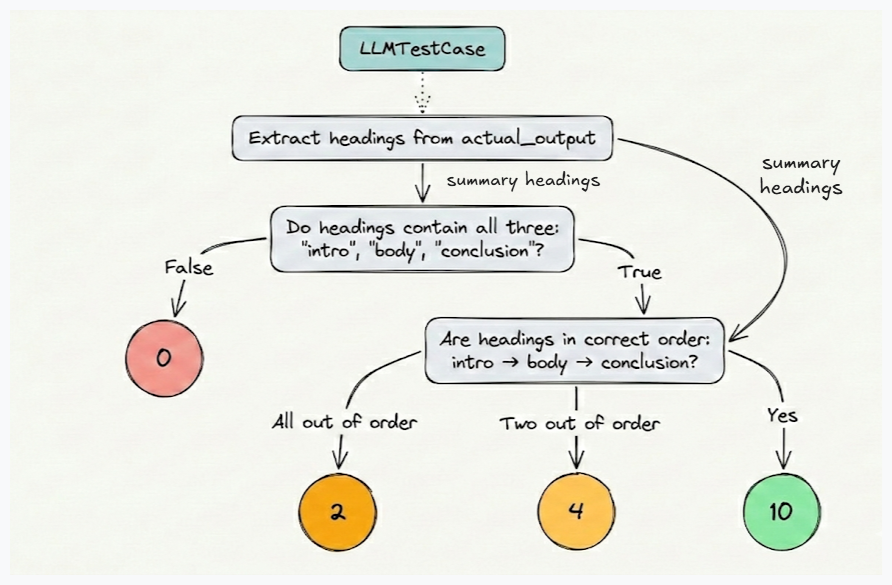
Overall, the chapter extended our evaluation toolkit beyond the fundamentals.
If you haven’t yet gone through Part 10, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
Read it here:

In this final chapter on LLM evaluation, we will understand evaluation of multi-turn systems, tool use evals, tracing, and red teaming.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Evaluating multi-turn conversation
By now, single-turn evaluation is a solved problem for us, more or less. You feed a prompt to a model, get a response, and compare it against a reference answer. Multi-turn evaluation is harder. The quality of turn five depends on everything that happened in turns one through four. A response that looks correct in isolation might contradict something the model said two turns ago.
This section covers the concepts and tooling that matter for multi-turn conversations.
Two levels of evaluation
Multi-turn evaluation can operate at two granularities:
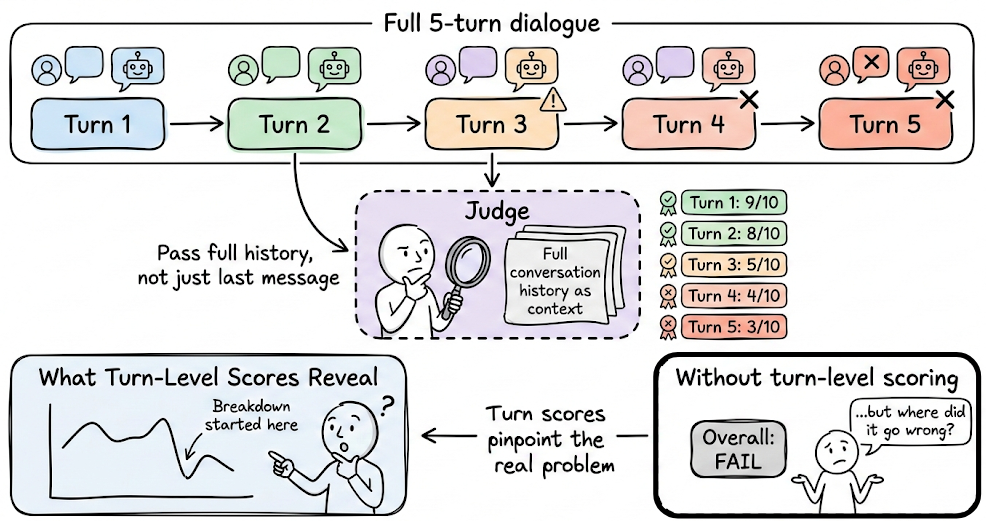
- Turn-level evaluation assesses each individual exchange. For pipelines, we can easily reuse most of your single-turn evaluation machinery here. The key difference is that we pass the full conversation history as context to the judge, not just the last user message. Turn-level scoring is how you pinpoint where a conversation breaks down. If a five-turn dialogue fails at the end, turn-level scores might reveal the real problem started at turn three (say).
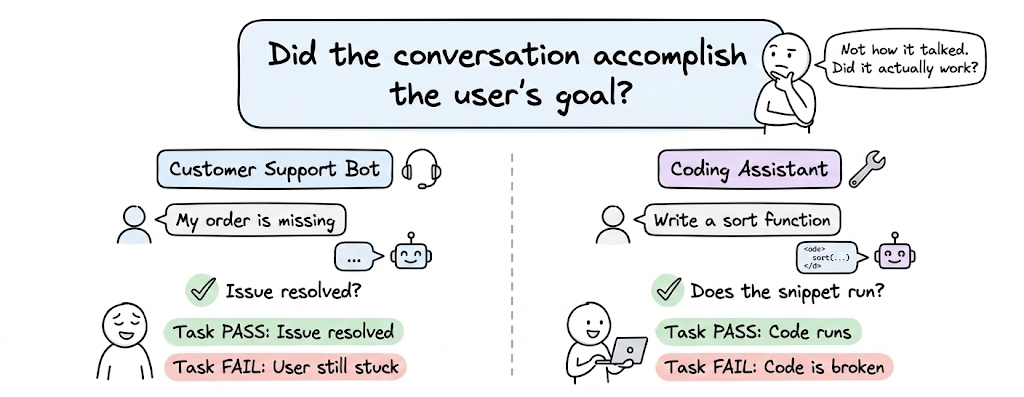
- Task-level evaluation answers a different question: did the conversation accomplish the user's goal? For a customer support bot, that might mean the issue was resolved. For a coding assistant, it might mean the final snippet runs. Task-level evaluation often requires either explicit success criteria embedded in the test cases or a goal-extraction step where it is inferred what the user was trying to accomplish and then check whether it happened.
Metrics
Some key signals to observe and evaluate in multi-turn systems include:
- Context retention: whether the model remembers and uses information from earlier turns. If it forgets, that is a failure.
- Coherence: whether the dialogue flows naturally from one message to another.
- Relevancy: whether the dialogue stays on topic or does the system deviate to nonsensical tangents.
Now, a point to note here is, we may not always need to manually implement all of these metrics ourselves. This is where evaluation frameworks become essential. Let’s now explore how DeepEval enables the evaluation of multi-turn conversations through its metrics.
Implementing multi-turn evaluation with DeepEval
DeepEval provides a practical framework for multi-turn evaluation. It represents a dialogue as a ConversationalTestCase, which is a sequence of Turns. We then apply the conversational metrics.
Here is a concrete example:
This script, instead of evaluating a single prompt-response pair, evaluates an entire dialogue between a user and an assistant.
- The
ConversationalTestCaseandTurnclasses are used to represent the conversation itself. Each message in the dialogue is represented as aTurn, with aroleand the corresponding messagecontent. - After defining the conversation, the script initializes three evaluation metrics.
TurnRelevancyMetricconstructs sliding windows of turns for each turn, before using the LLM to determine whether the last turn in every sliding window has an "assistant" content that is relevant to the previous conversational context found in the sliding window.KnowledgeRetentionMetric, evaluates whether the assistant correctly remembers and uses information from earlier turns in the conversation.- Finally
safe_advice, aConversationalGEvalmetric, which is a modified implementation of standard G-Eval LLM-as-judge evaluation. Using this we can determine whether our LLM chatbot responses are up to standard with our customcriteriathroughout the conversation.
- All three metrics are configured with thresholds and an evaluation model (
openai/gpt-4o-2024-08-06). - The script then runs the evaluations in a standalone manner by calling
.measure(test_case)on each metric.
evaluate(), standalone execution is useful for debugging or when integrating results into our own application or pipelines. The trade-off is that we won’t receive benefits like integration with the Confident AI platform, that the evaluate() function provides.- Finally, the results are printed.
Overall, this example illustrates how with DeepEval we can evaluate multi-turn dialogue quality, checking for relevance, context retention, and domain-specific safety rules.
Apart from these, DeepEval provides several other multi-turn evaluation metrics. We encourage readers to explore them in the documentation as a self-learning activity.
