Evaluation: Model Benchmarks and LLM Application Assessment
LLMOps Part 10: Understanding model benchmarks, LLM application evaluation, and tooling.
Recap
In Part 9, we began exploring the evaluation space of LLM applications, laying the groundwork, covering challenges and a practical taxonomy of evaluation methods.
We began by examining why LLM evaluation is different from traditional software or classical ML evaluation. Unlike deterministic systems, LLMs generate open-ended, probabilistic outputs. This introduces subjectivity, non-determinism, multi-dimensional quality criteria, and emergent failure modes such as hallucinations and bias.
From there, we introduced a structured taxonomy of evaluation methods: intrinsic, deterministic, and subjective.
We first explored intrinsic metrics, such as entropy, cross-entropy, and perplexity. These metrics quantify how well a model approximates the true data distribution. The key takeaway was that intrinsic metrics are measure of language modeling, not task-level usefulness.
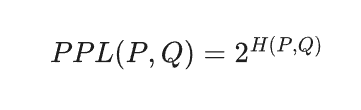
We then moved to deterministic evaluation methods, which apply when ground truth or structural correctness exists. These included functional correctness, exact match and classification metrics, n-gram overlap metrics such as BLEU and ROUGE, embedding-based similarity metrics such as BERTScore, and strict format validation using schema checks.
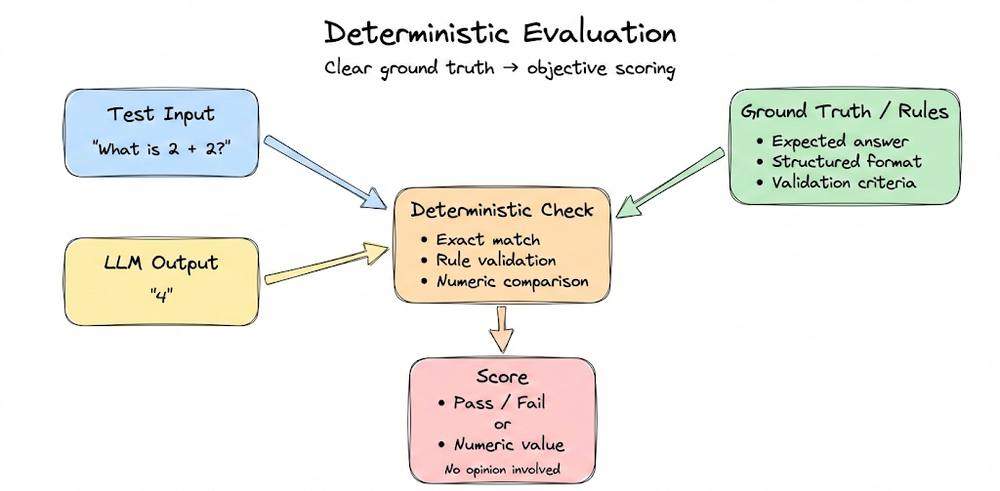
We emphasized that deterministic metrics are objective and automatable, but often fail to capture nuances of open-ended language generation.
Next, we examined subjective evaluation methods, which become essential when outputs are open-ended and multi-dimensional. We discussed human evaluation (ratings, rankings, open feedback), along with its cost, scale and variability constraints.
We then explored LLM-as-a-judge, where strong models are prompted to score outputs based on explicit rubrics.
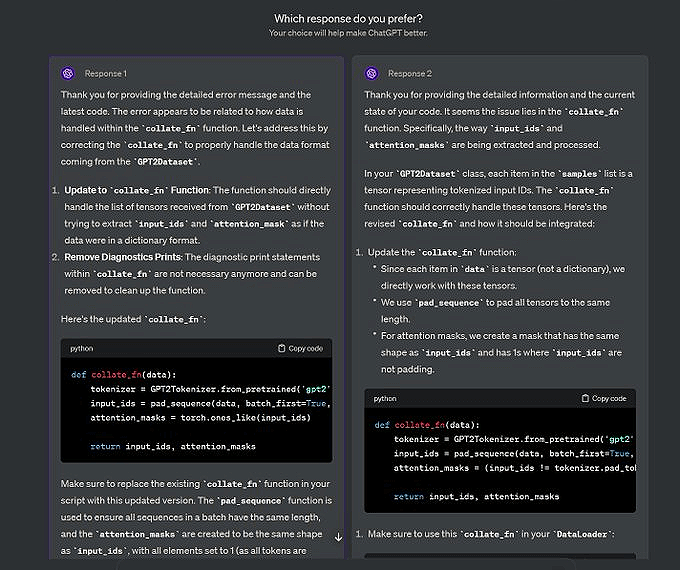
We also introduced pairwise comparative evaluation and Elo rating systems, explaining how relative comparisons can produce more stable rankings.
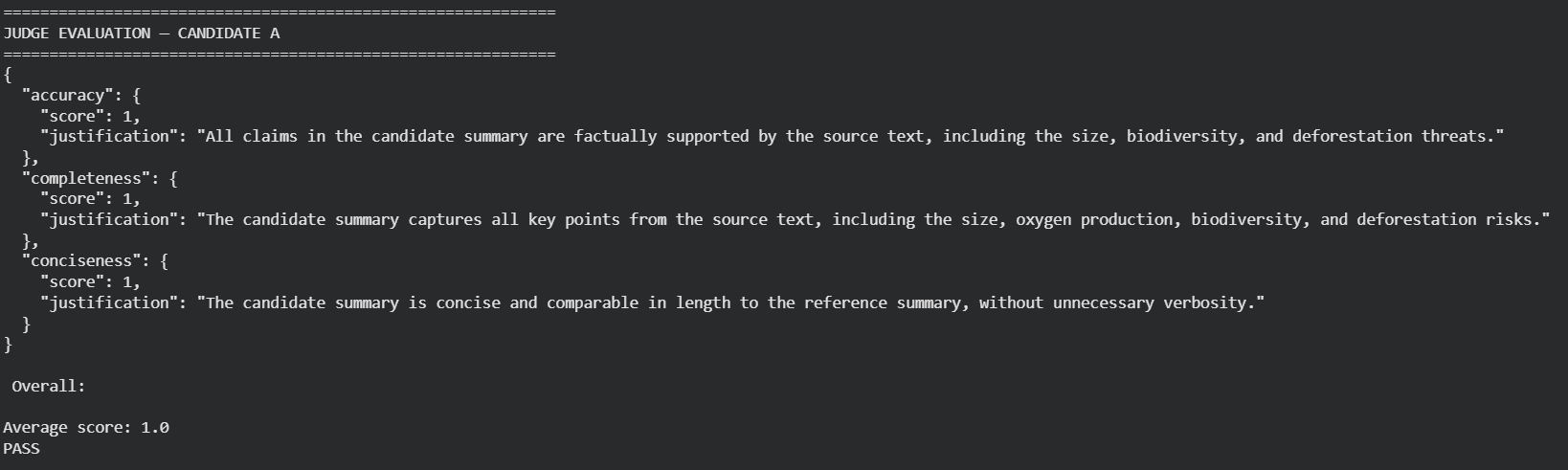
Finally, in the hands-on demo, we grounded these ideas in practice using a summarization task. Two candidate summaries were evaluated using BLEU, ROUGE, BERTScore, and an LLM-as-a-judge pipeline. The demo illustrated a crucial insight: no single metric captures the full picture.
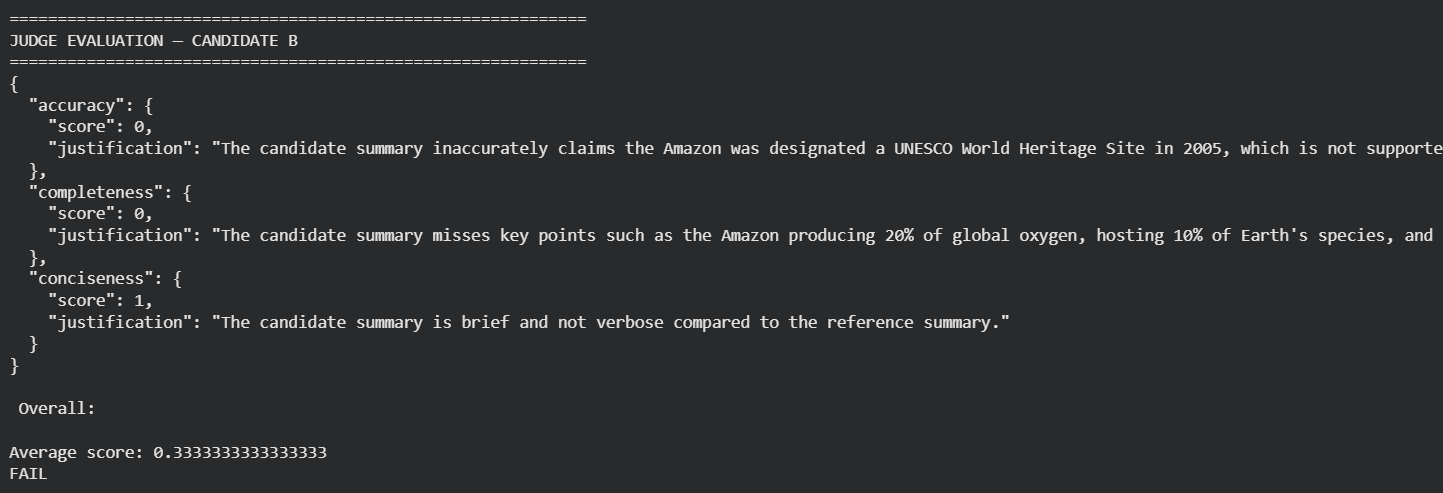
Altogether, the chapter served as a foundational guide to the evaluation of LLM applications.
If you haven’t yet gone through Part 9, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
Read it here:

In this chapter, we will briefly discuss about benchmarks and build on the foundations from the last chapter and move toward understanding deeper task-specific methodologies, and tooling for evaluation of LLM applications.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Evaluation benchmarks
In the previous part, we’ve covered how to evaluate a model’s outputs on particular tasks. Now, for a moment, let’s zoom out and discuss how do we assess the general capabilities and quality of an LLM in a broad sense.
This is important for model selection in LLMOps. Before using a model or building an app on it, you want to know its strengths, weaknesses, and how it compares to alternatives. The field has developed many benchmarks and standardized tests for this purpose.
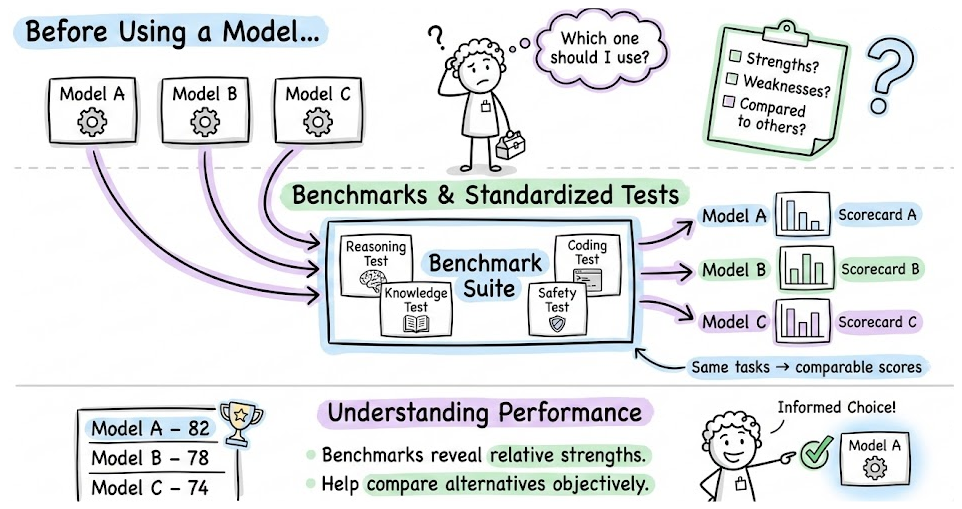
We’ll overview some common benchmarks and metrics used, and how to interpret them.
MMLU
MMLU (massive multitask language understanding) is a benchmark covering 57 subjects including history, math, science, law, etc., with difficulty from high school to expert level. It’s a set of multiple-choice questions. The metric is accuracy (%) on these questions.

It’s for measuring a model’s breadth of knowledge and reasoning. Non-expert human performance on MMLU is around 34%, whereas top models (Gemini 3 Pro, Claude Sonnet, etc.) go beyond 90% on it. If your use case requires broad knowledge, MMLU score is a good indicator. Many models report their MMLU in papers and on leaderboards.
As models continue to become more capable, many now achieve exceptionally high scores on the original MMLU benchmark. To better differentiate performance at the higher end, we have MMLU-Pro, which introduces a more challenging 10-option multiple-choice format.
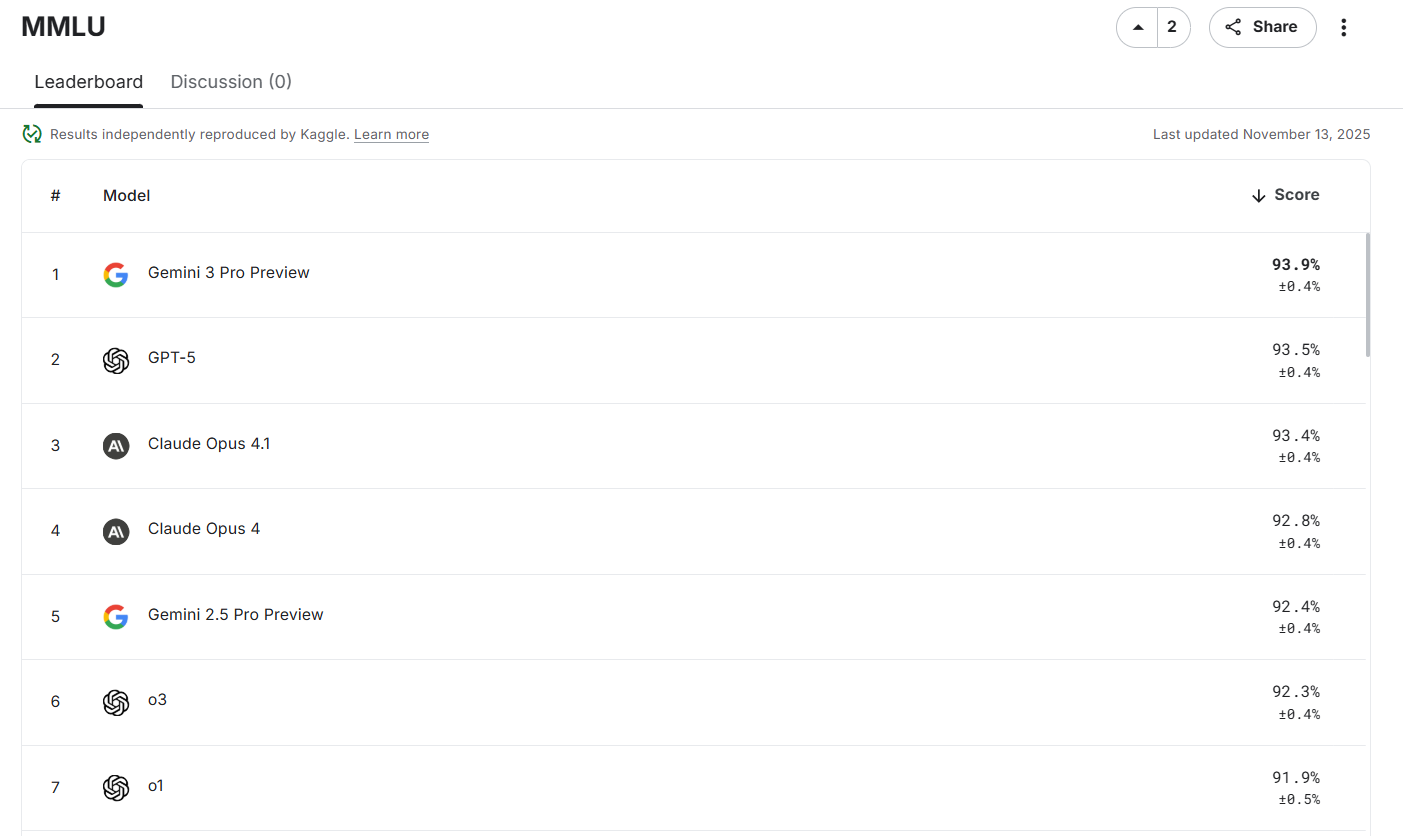
This increased difficulty leads to more realistic scores, making it a more discriminative benchmark for evaluating current AI models.
HellaSwag
A commonsense reasoning benchmark where each question is a sentence or paragraph with a blank, and the model must choose the best ending from options.
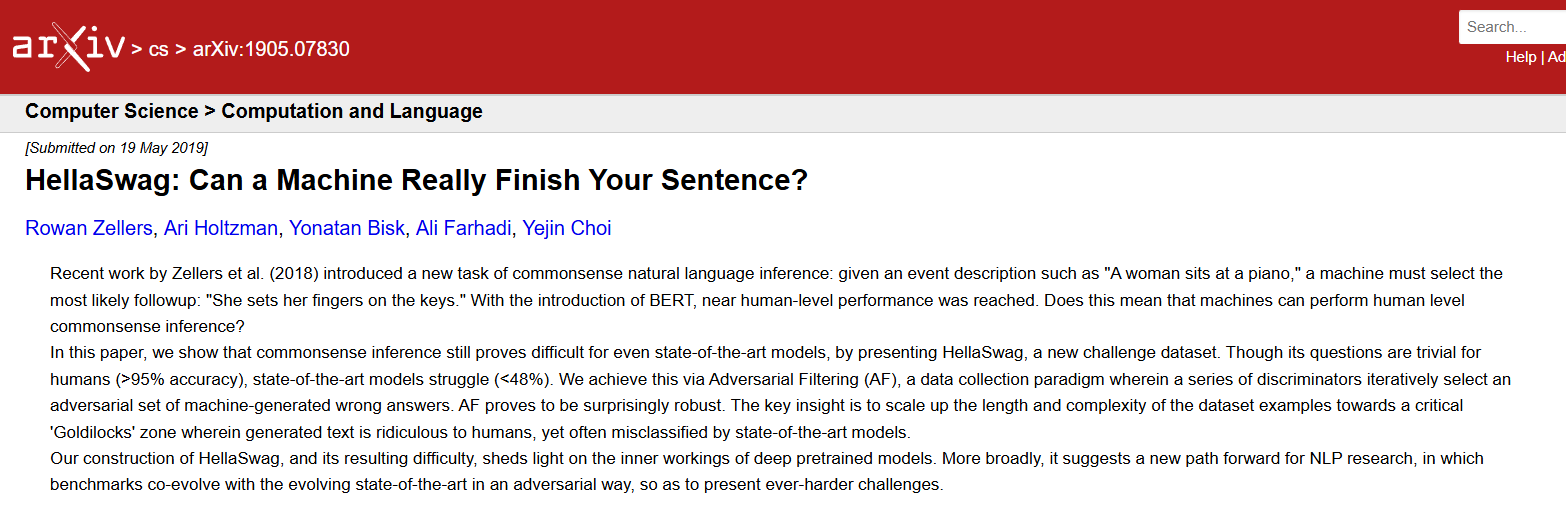
It was designed adversarially such that surface cues are misleading, so models really need deeper understanding. Accuracy on HellaSwag reflects a model’s commonsense reasoning ability. It’s often used in open LLM leaderboards.
TruthfulQA
A benchmark to test whether a model tells the truth versus repeating common myths or falsehoods. It has questions (many about common misconceptions, false beliefs and tricky facts) and checks if the model’s answer is true. It tests models in both free-form generation and multiple-choice formats.

Many models often struggle with TruthfulQA, tending to output plausible but incorrect answers if a misconception is popular (because they mimic training data). For applications where factual accuracy is crucial, a model’s TruthfulQA score can be an important indicator, in evaluating model choice.
BIG-Bench
Beyond the Imitation Game benchmark (BIG-Bench) is a collection of over 200 diverse tasks. It includes everything from logical puzzles and mathematics to creative tasks and novel problem types.

BIG-Bench was used to test models for emergent abilities, i.e., tasks where performance jumps as models get larger. It’s huge and eclectic; not typically one number but a suite of metrics. A subset called BIG-Bench Hard (BBH) consists of 23 particularly challenging tasks unsolved by smaller models. An even complex one is BIG-Bench Extra Hard (BBEH).
If a model does well on BBEH tasks, it’s considered quite advanced. BIG-Bench is mostly research-focused, but you might reference it if comparing frontier models’ advanced reasoning capabilities.