LLMs
Paged Attention in LLMs
...explained visually!

Avi Chawla
...explained visually!
When you’re serving LLMs at scale, memory becomes your bottleneck before compute does.
The problem isn’t a lack of GPU memory; it’s how inefficiently we use it.
Let’s understand why this happens and how Paged Attention solves it elegantly!
During LLM inference, the model stores the key and value vectors of all previously generated tokens in memory. This is the KV cache (we covered KV caching in detail here).
Simply put, instead of recomputing attention over all previous tokens every time a new token is generated, the model just looks up the cached values and computes attention with them.
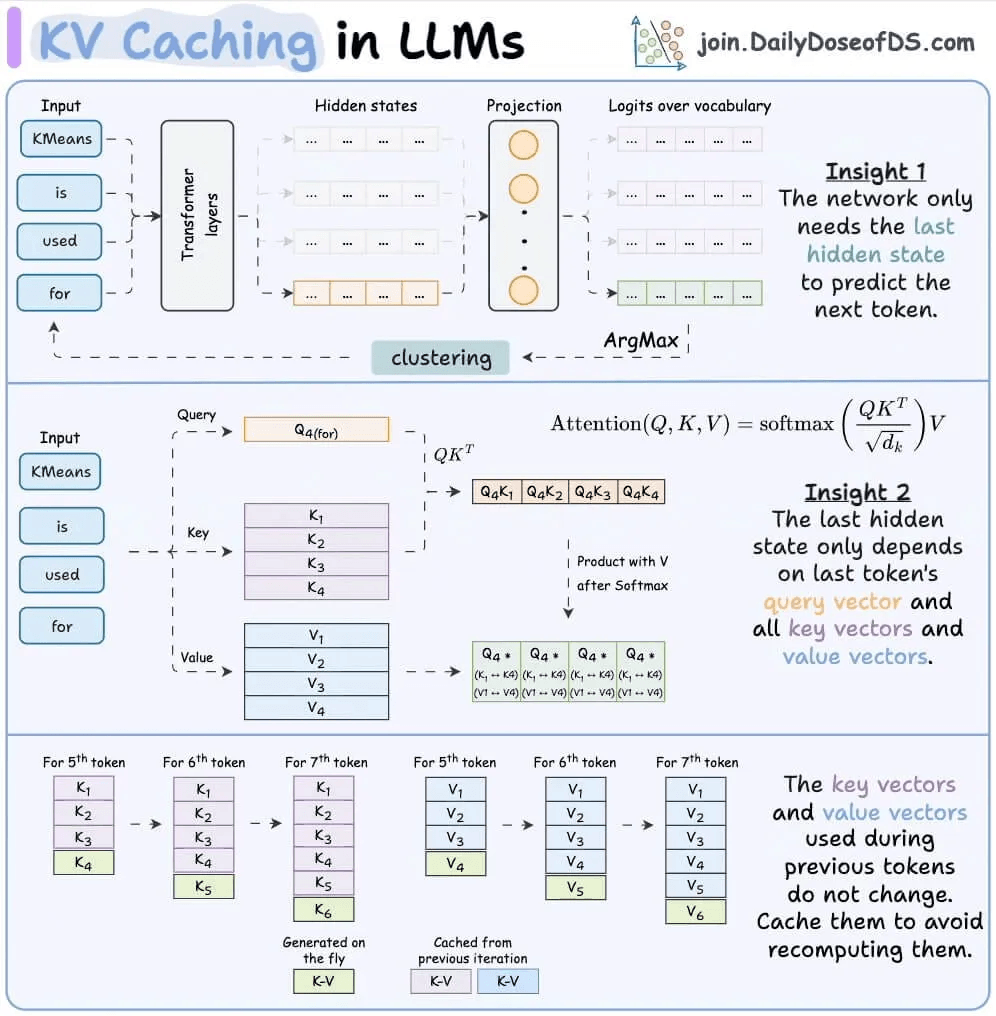
This is crucial for efficiency. Without it, generating a 1000-token response would require recomputing attention for all previous tokens at each step. That’s O(n²) operations instead of O(n) and the speed difference is evident below:
But there’s a problem.
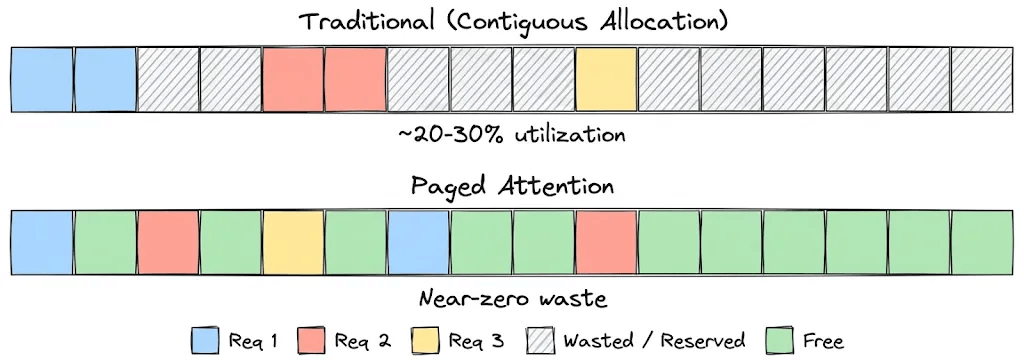
Traditional KV cache implementations pre-allocate large, contiguous memory blocks for each request.
Here’s why this is wasteful:
Imagine serving 100 concurrent users. You don’t know how long each response will be, so you pre-allocate space for the maximum possible length, say, 2048 tokens per request. But the average response turns out to be only 200 tokens.
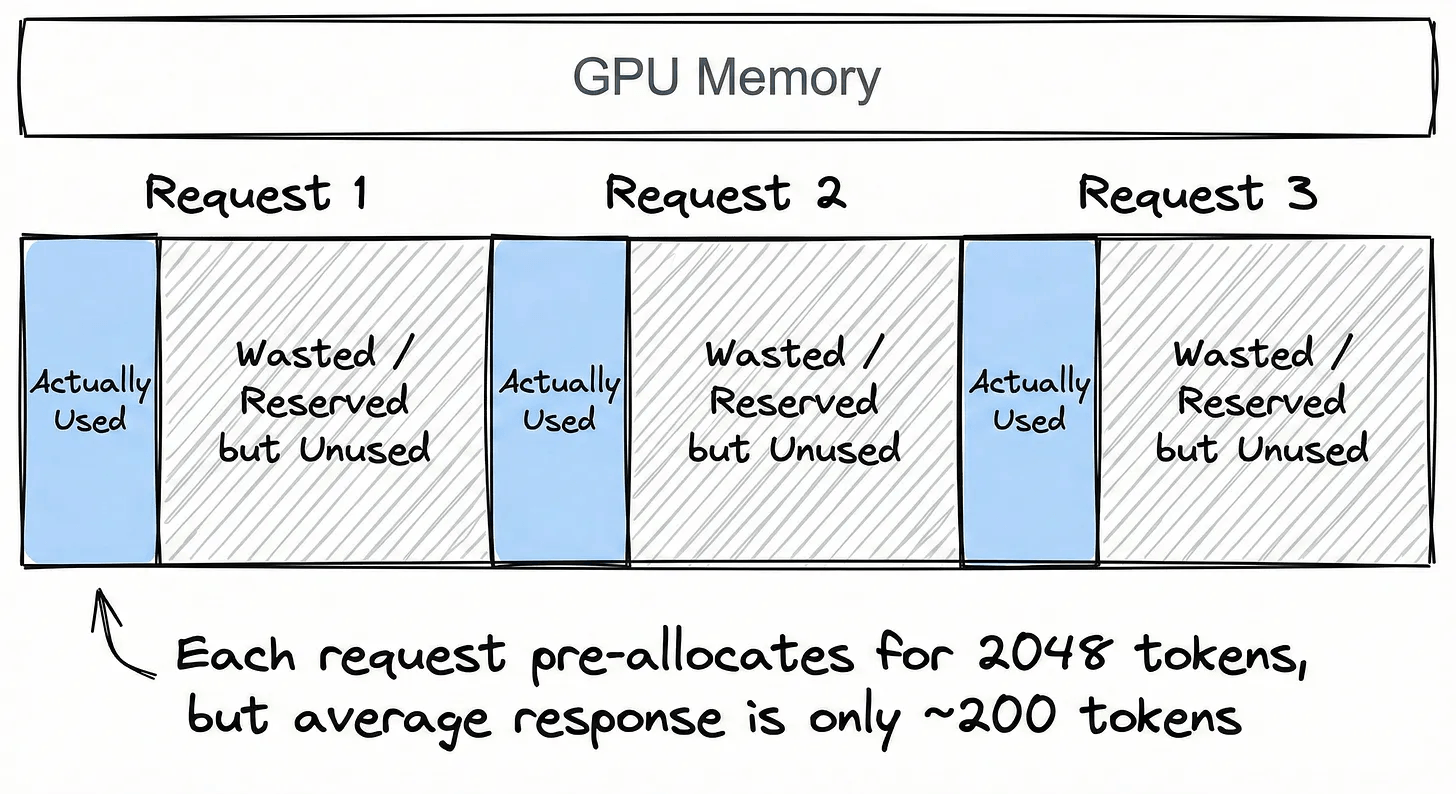
You’ve just reserved 10x the memory you actually need.
And it gets worse. Each request gets its own isolated block. So even if 80 of those 100 users share the same system prompt, you’re storing 80 duplicate copies of the same KV cache entries. None of that memory can be shared or reclaimed.
As a result, you’re often using only 20-30% of your allocated GPU memory effectively. The rest is reserved but unused, and because it’s scattered across fragmented contiguous blocks, you can’t even fit new requests into the gaps.
This is the core inefficiency that kills throughput.
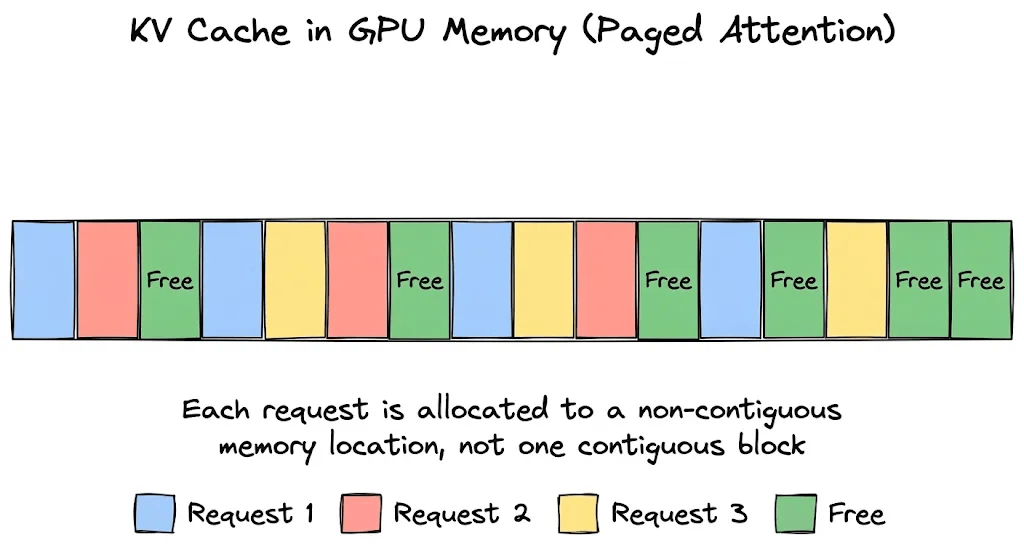
Paged Attention solves this by borrowing the concept of virtual paging memory from operating systems.
If you’ve studied OS fundamentals, you know that programs don’t get one big contiguous chunk of RAM. Instead, the OS breaks memory into small, fixed-size pages, scatters them anywhere in physical memory, and uses a page table to map each program’s virtual addresses to physical locations.
Paged Attention does the same thing for the KV cache. Here’s how:
Block-level allocation: Instead of reserving one large contiguous block per request, the KV cache is divided into small, fixed-size blocks (typically 16 tokens each). These blocks can live anywhere in GPU memory and don’t necessarily need to be next to each other.
Block table (page table): Each request maintains a block table which is a simple mapping from logical block index to physical block location in GPU memory. When the model needs the KV cache for token 33, it looks up which physical block holds it, fetches it, and computes attention. The LLM doesn’t care where the block is physically sitting.
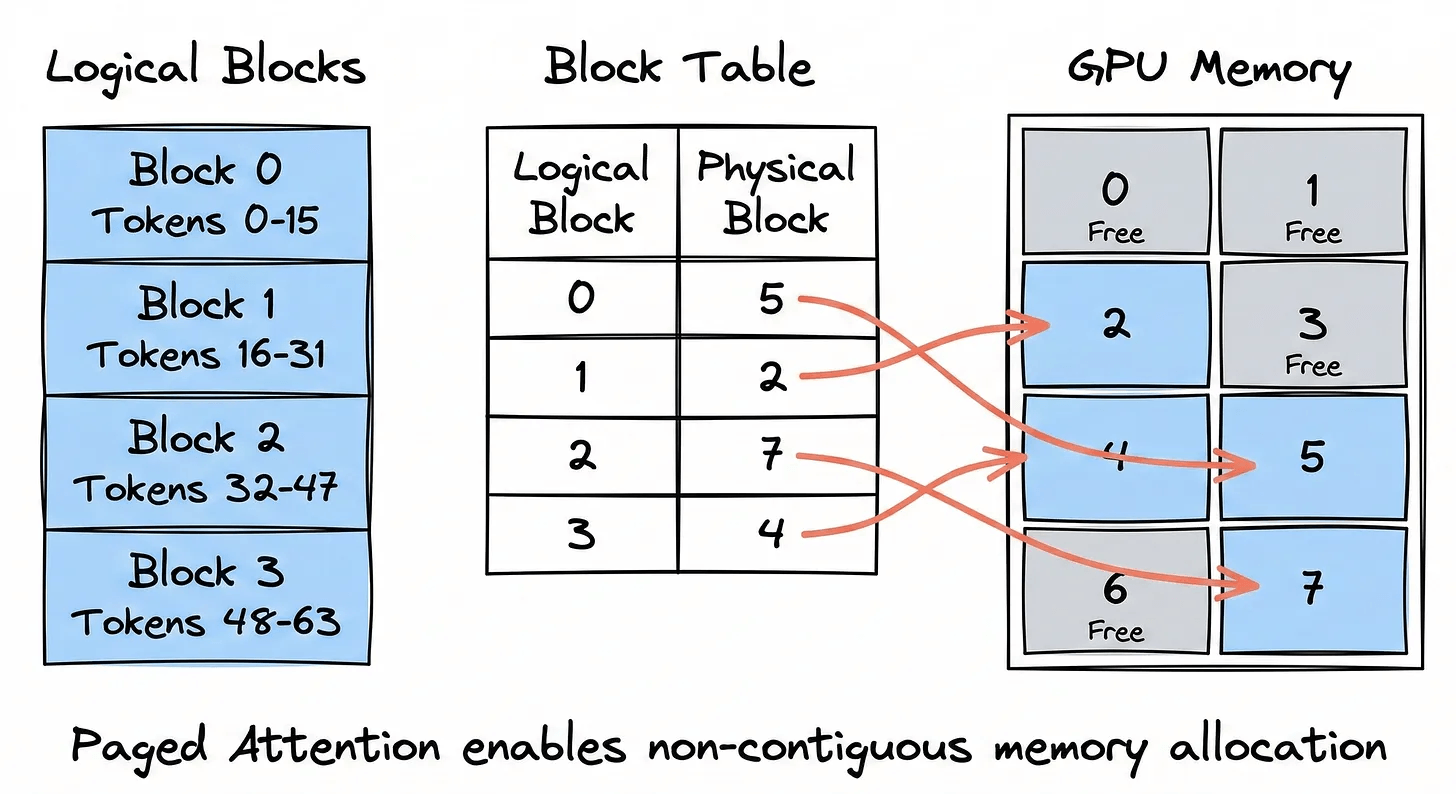
Shared prefixes: Here’s where it gets really clever. Multiple requests that share the same system prompt don’t need separate copies of the KV cache for that shared prefix. Their block tables simply point to the same physical blocks. Only when their responses diverge do new blocks get allocated for each request individually.
In a production setting, where every request typically shares a system prompt, the memory savings via shared prefix become massive.
In the original Paged Attention paper, the authors measured that existing systems only utilized 20-38% of the allocated KV cache memory effectively. The rest was wasted due to fragmentation and over-reservation.
Paged Attention can achieve:
Better batching leads to more concurrent requests on the same GPU hardware
This is why vLLM, which implements Paged Attention as its core algorithm, has become the go-to inference engine for production deployments. Other frameworks like TensorRT-LLM and SGLang have also adopted similar paging mechanisms for faster inference.
This optimization becomes even more crucial when running inference servers at scale, especially with variable request patterns, shared prompts, and cost-per-request constraints.
👉 Over to you: What other OS concepts do you think could be applied to optimize LLM inference?
Thanks for reading!