Agents
Advisor Strategy in Agents
Reduce token costs and improve performance...and how to use it with Claude!

Avi Chawla
Reduce token costs and improve performance...and how to use it with Claude!
Yesterday, Anthropic shipped an “advisor tool” in the Claude API that lets Sonnet or Haiku consult Opus mid-task, only when the executor needs help.
The benefit is that you get near Opus-level intelligence on the hard decisions while paying Sonnet or Haiku rates for everything else. So frontier reasoning only kicks in when it’s actually needed, not on every token.
Back in February, UC Berkeley published a paper called “Advisor Models” that trains a small 7B model with RL to generate per-instance advice for a frozen black-box model.
The paper’s approach was to take Qwen2.5 7B, train it with GRPO to generate natural language advice, and inject that advice into the prompt of a black-box model.
The black-box model never changes, and the advisor learns what to say to make it perform better.
To test it, they found that GPT-5 scored 31.2% on a tax-filing benchmark. But adding the trained advisor took that to 53.6%.
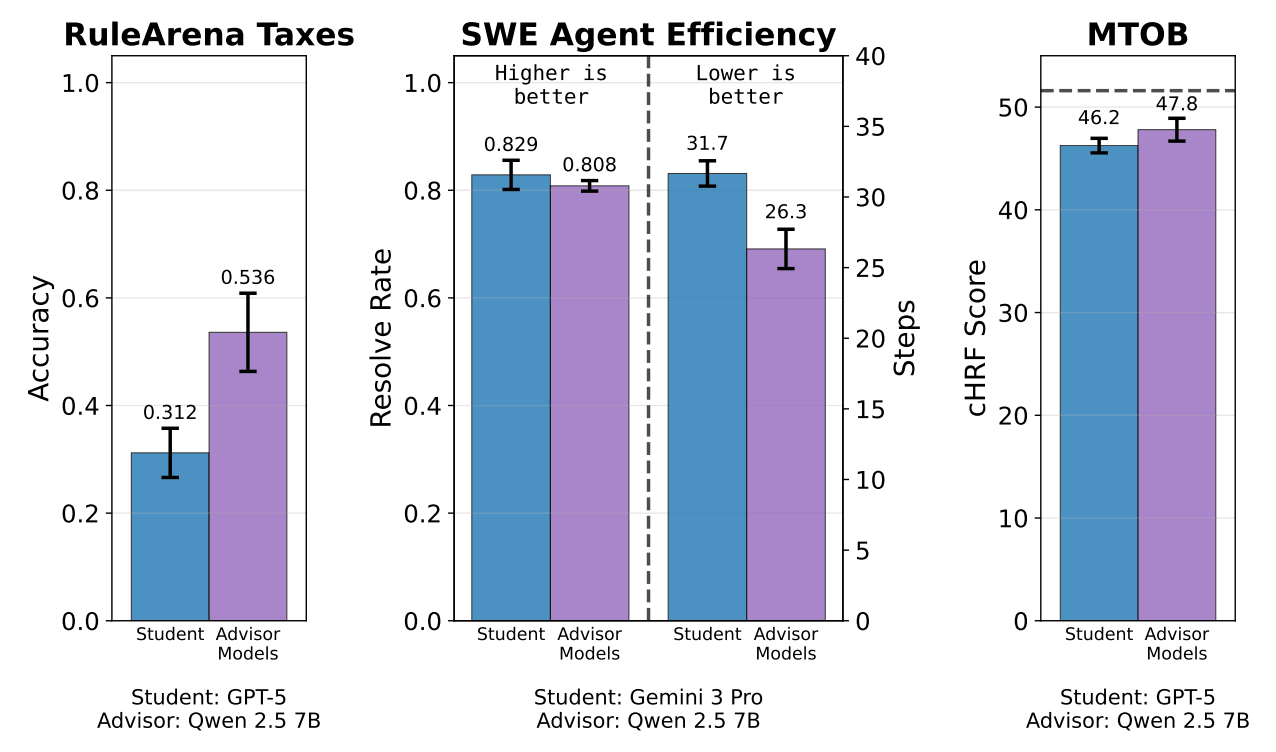
Moreover, on SWE agent tasks, a trained advisor cuts Gemini 3 Pro’s steps from 31.7 to 26.3 while keeping the same resolve rate.
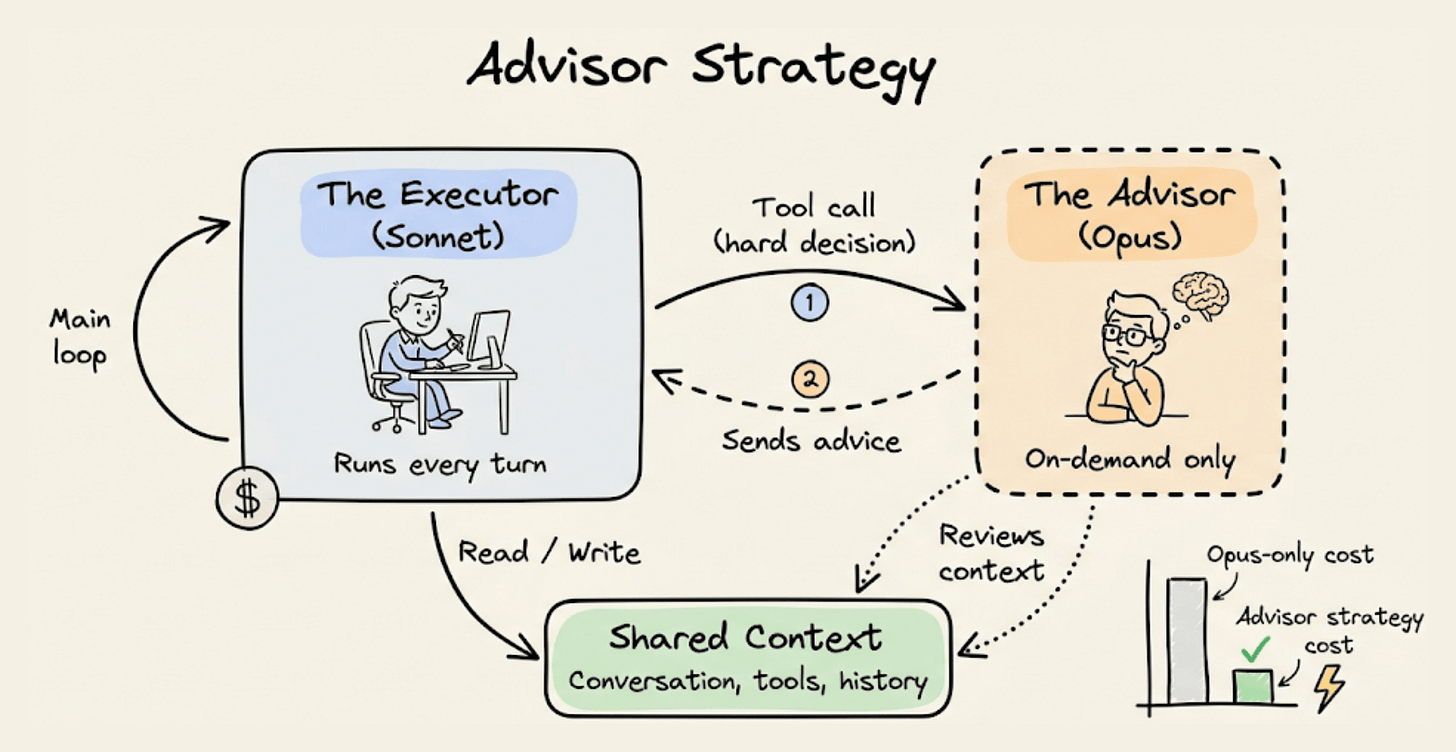
Anthropic’s advisor tool takes a different path to the same idea. Sonnet runs as the executor to handle tools and iteration.
When it hits something it can’t resolve, it consults Opus, gets a plan or correction, and continues.
Sonnet with Opus as advisor gained 2.7 points on SWE-bench Multilingual over Sonnet alone, while costing 11.9% less per task.
Haiku with Opus scored 41.2% on BrowseComp. Haiku alone scored 19.7%.
Implementation-wise, it’s a one-line API change. The advisor tokens bill at Opus rates, and the advisor typically generates only 400-700 tokens per call.
response = client.messages.create(
model="claude-sonnet-4-6", # executor
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
"max_uses": 3,
},
# ... your other tools
],
messages=[...]
)
So the combined cost stays well below running Opus end-to-end.
Both approaches point to the same thing that you don’t need the most powerful model on every token.
You need it at the right moments, for the right inputs.
Here’s the paper by UC Berkeley →
Thanks for reading!