RLHF: Aligning Language Models with Human Feedback
Part 9: From human preferences to a trained reward signal, and the four-model PPO pipeline.
Recap
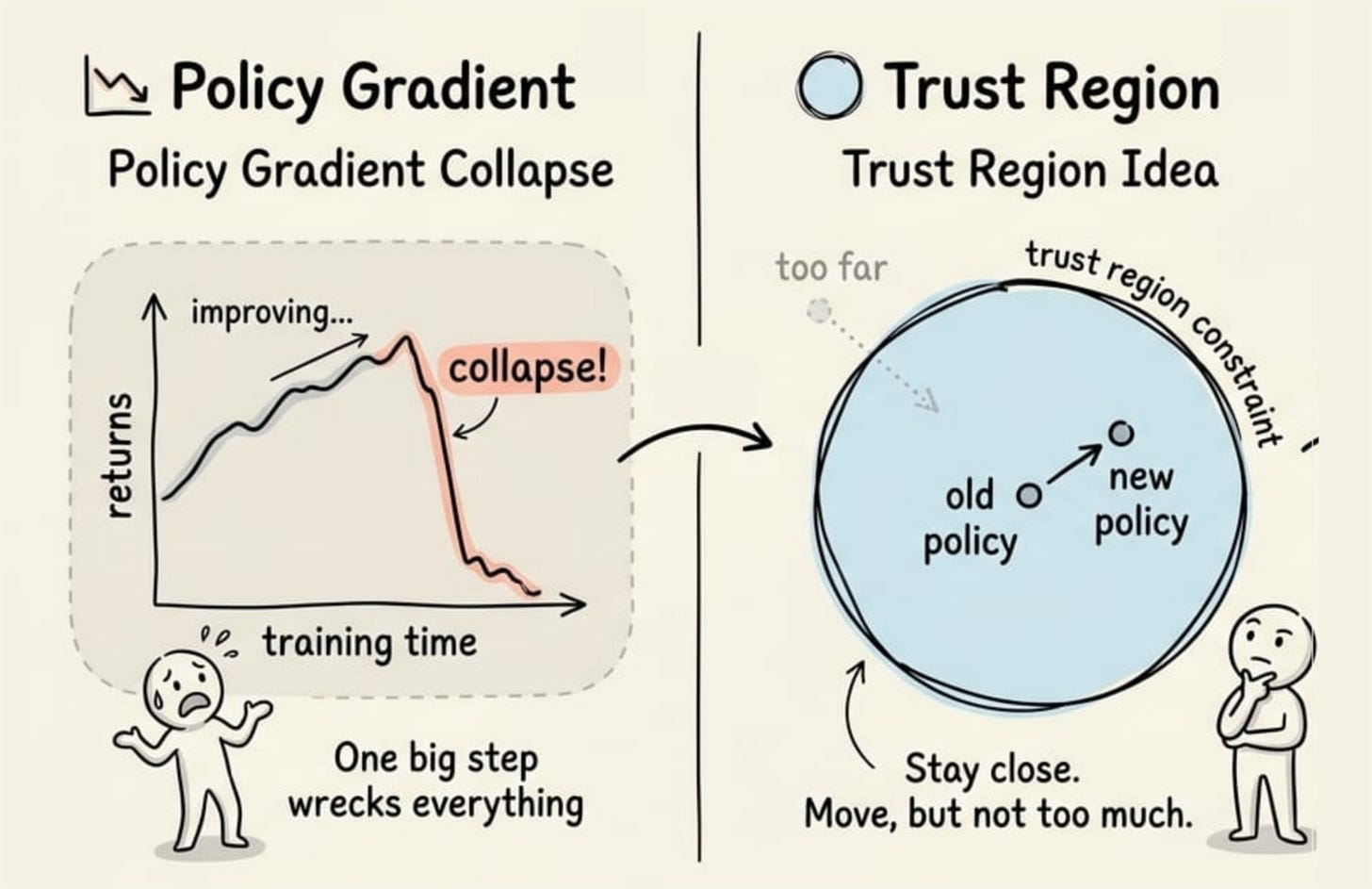
In Chapter 8, we studied proximal policy optimization (PPO). We started from the concern that on-policy data is only valid near the policy that produced it. A single oversized update can therefore push the agent off a cliff. The fix was the trust region, which meant a limit on how far each update may move the policy.
We then built the machinery in stages. The importance ratio let us reuse a batch of data. It re-weights old samples for the new policy, giving the surrogate objective.
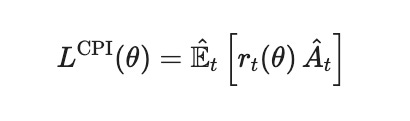
Left unconstrained, that objective invites ruinous updates. TRPO fenced it with a hard KL constraint, paying with expensive second-order optimization.
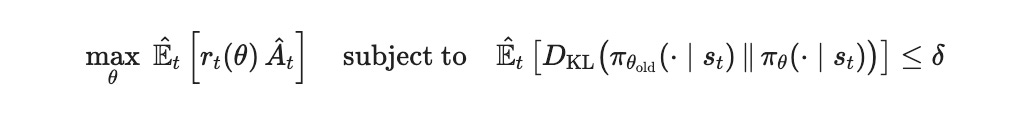
PPO replaced the hard fence with a soft one, the clipped surrogate objective. Clipping removes the incentive to step too far. It needs only ordinary first-order optimizers.
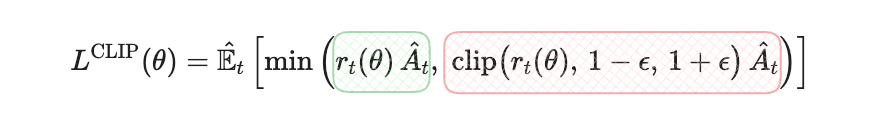
We then grounded the advantage in GAE and added advantage normalization. Then we saw the full PPO algorithm in plain English and implemented PPO from scratch and solved LunarLander with it.

Finally, we sketched the connection to language models. The model is a policy over tokens and a reward model supplies the reward.

If you have not read Chapter 8, we recommend doing so first:
Now, as a natural progression, in this chapter, we will learn about Reinforcement Learning from Human Feedback (RLHF).
We will cover why imitation alone falls short, and supervised fine-tuning as the starting policy. We will understand the reward model, then the four-model PPO setup and the full RLHF loop. We will also study reward hacking, its central failure mode and finally briefly explore DPO, a shortcut that skips the RL loop entirely.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let's begin!
The problem with imitation
Before RLHF, the standard way to make a language model behave was imitation. You collect examples of good behavior, written by humans and then fine-tune the model to predict those examples, token-by-token (supervised fine-tuning).
Now the thing is, imitation works, but it has a ceiling built into its objective. The model is trained to reproduce the demonstrations. It is never told why one response is better than another.
It cannot exceed the demonstrators, because matching them is the entire goal. And it treats all token errors equally, a factual error and a slightly awkward synonym receive similar penalties.
There is a deeper, more nuanced point. For most tasks we care about, "good" is hard to write down but easy to recognize. Try writing a precise rule for what makes a summary good, or a joke funny, or an answer helpful but not preachy. The rule slips away. Yet shown two candidate responses, almost anyone can point at the better one in seconds.
This asymmetry is the founding insight of RLHF. If judging is easier than producing, then collect judgments. Comparisons are cheap, fast, and fairly consistent across people.

Now one might think, why comparisons instead of asking people for a score out of 10? Absolute scores are noisy and inconsistent. Your 7 is another person's 9, and your own 7 drifts over a long labeling session.
Relative judgments ("A is better than B") are far more stable across people and time. This observation shapes the math of the next sections.
Stage 1: SFT
RLHF does not start from a raw pretrained model. It starts from a model that has already been taught the basic shape of the task. That teaching step is supervised fine-tuning.
The mechanics are plain. We have a dataset with prompts paired with their ideal response. The pretrained model is then fine-tuned on these pairs with the standard language modeling loss. It learns to maximize the probability of the demonstrated response, token-by-token, given the prompt.
Now the question is, why bother, if we just argued imitation has a ceiling? Because RL needs a sane starting point. A raw pretrained model continues text; it does not answer questions or follow instructions.
SFT helps place the policy in the right neighborhood. RL then climbs from there.
The SFT model plays a second role, and this connects directly to Chapter 8. A frozen copy of it becomes the reference model, written $\pi_{\text{ref}}$.
The trust region for the whole RLHF run is therefore anchored at the SFT model. The policy may improve on it, but never drift unrecognizably far from it.
In summary, SFT teaches the format and gives RL a usable starting point. It also supplies the frozen reference that anchors the trust region.
Stage 2: the reward model
The reward model is the heart of RLHF. It is a neural network that takes a prompt and a response and returns a single number that tells how good that response is.
Once it exists, the RL problem looks exactly like Chapter 8. Everything new in this stage is about how to build it.
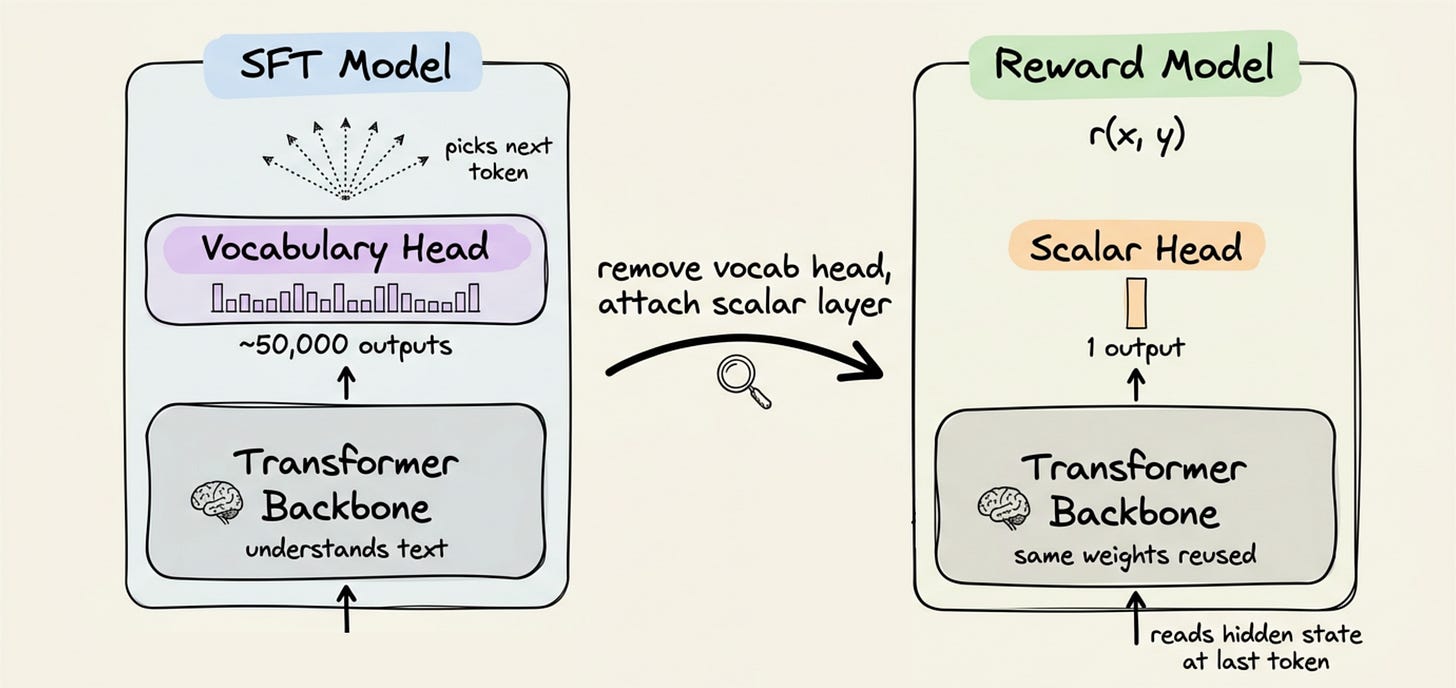
Architecture: a language model with a scalar head
The reward model is not built from scratch. We take a copy of the SFT model and perform one surgery on it. The final layer, which predicts a probability for every token in the vocabulary, is removed. In its place we attach a tiny linear layer that outputs one number.
To score a response, we feed the full prompt and response through the model. The scalar head reads the hidden state at the final token and produces the score.
We write this score as $r_\phi(x, y)$. The reward, with parameters $\phi$, for response $y$ to prompt $x$. The entire language backbone is reused, so the reward model understands text exactly as well as the policy does.