Proximal Policy Optimization
RL Part 8: Trust regions, the clipped surrogate, and the workhorse of modern RL.
Recap
Chapter 7 taught us about the policy gradient approach. Instead of learning values and acting greedily, we parameterized the policy directly and pushed its parameters in the direction that increases expected return.
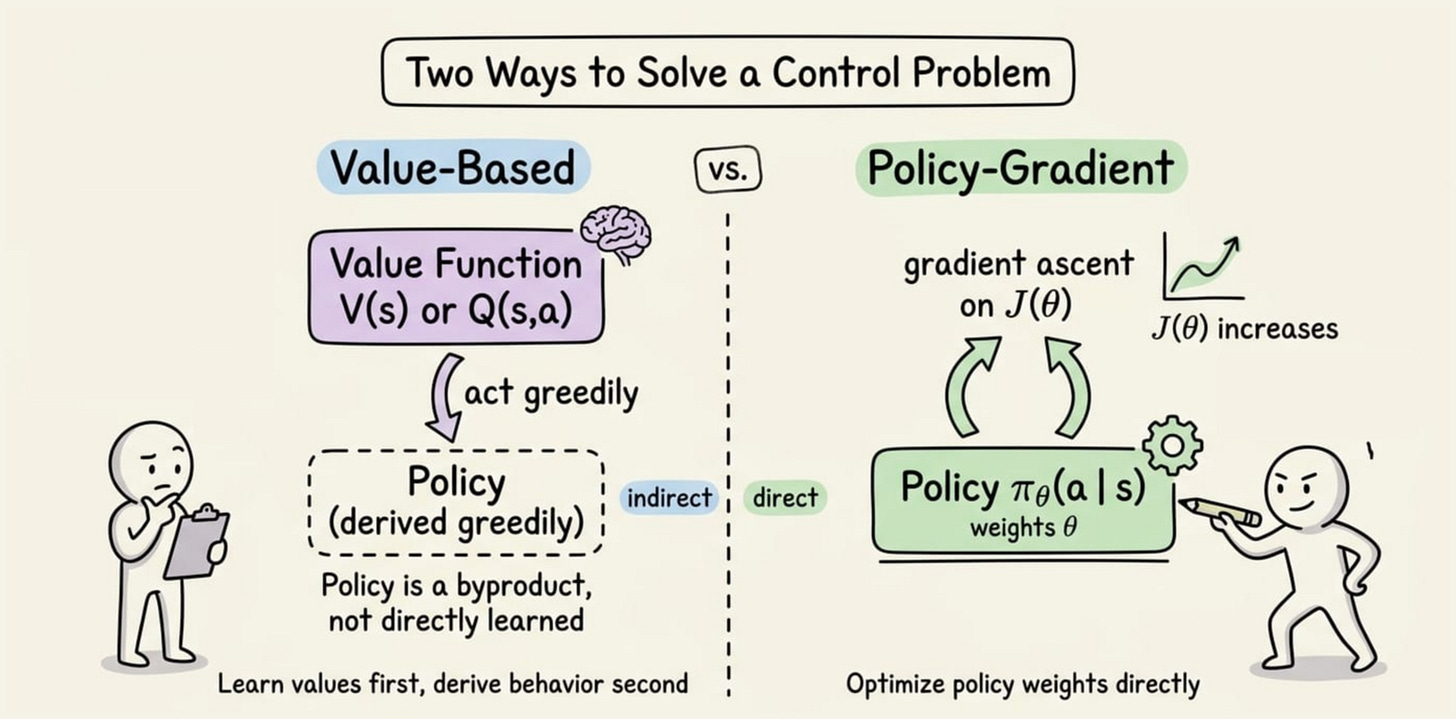
The log-derivative trick turned an intractable gradient into something we could estimate from sampled experience.
REINFORCE was the first algorithm built from that gradient. It worked, but it suffered from high variance since the return of a single trajectory is a noisy signal.

We reduced that variance in stages:
- A baseline subtracted a reference value without adding bias.

- The best baseline turned out to be the value function, which further gave us the advantage, i.e., how much better an action was than the typical behavior for that state.
 for several actions as bars, V(s) as a horizontal line at their average, and the advantage as the signed gap between each bar and the line")
Moving ahead, we saw that learning the value function alongside the policy produced actor-critic:
- The actor chooses actions.
- The critic estimates values, and the critic's estimate serves as the baseline.
GAE then gave us a smooth knob to trade a little bias for a lot less variance when estimating the advantage.

We also briefly discussed about language models in the RL setting, and finally, in the hands-on section, we implemented the REINFORCE algorithm and trained it on CartPole.
If you have not read Chapter 7, we recommend doing so first:
Introduction
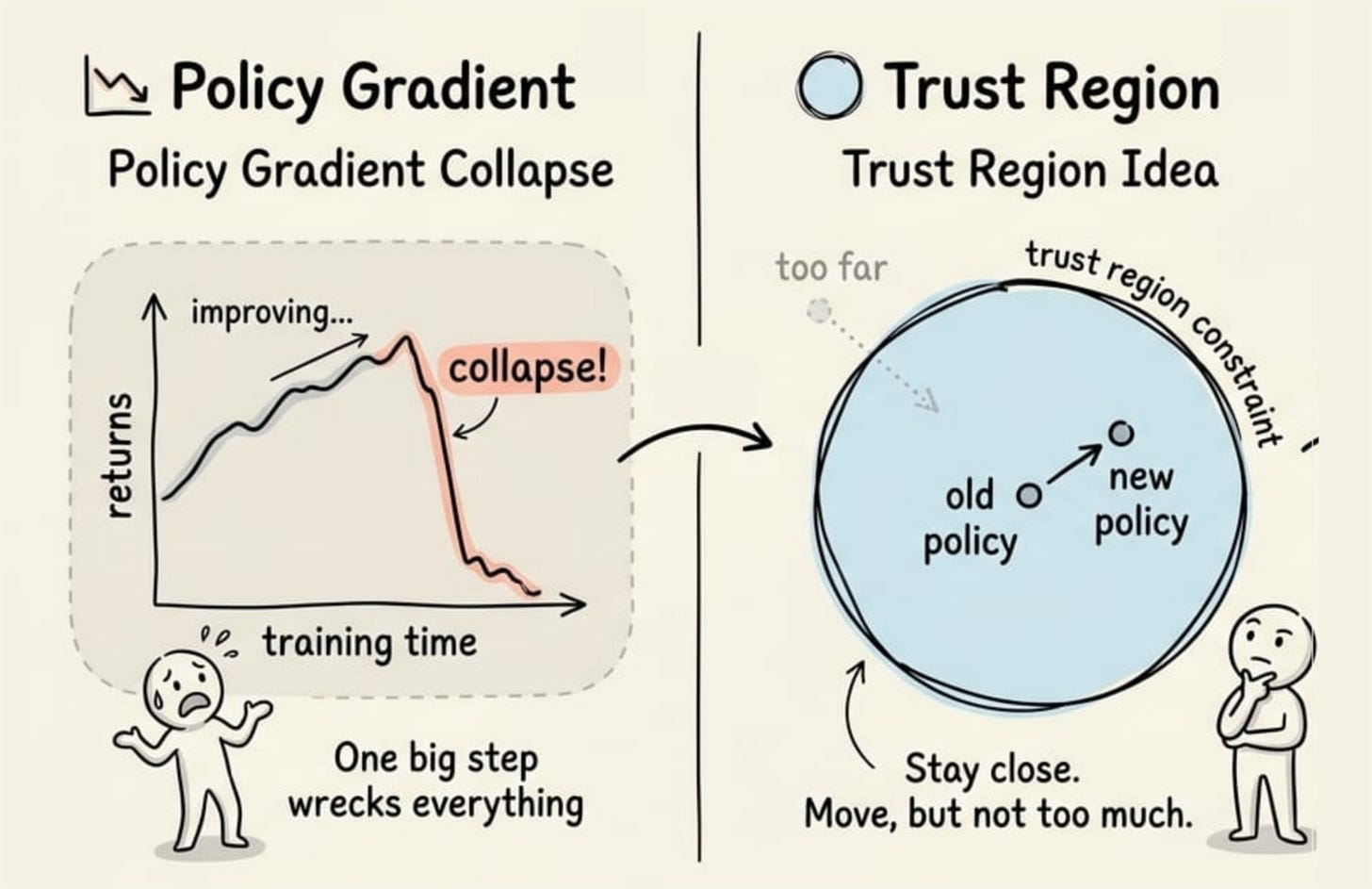
It is worth being precise about what the actor-critic did and did not solve. It addressed variance. By subtracting a learned baseline and bootstrapping value estimates, the gradient became far less noisy than REINFORCE's. What it left untouched was the size of each update.
So suppose we already have a working actor-critic agent. The question this chapter answers is narrow but important: why is updating that agent so dangerous, and what is the safe way to do it?
The answer is a family of methods built around a single idea, which is that you do not let the policy change too much in one step. That idea is called a trust region. The algorithm that made it practical is Proximal Policy Optimization (PPO).
As always, every idea will be explained through clear examples and walkthroughs to develop a solid understanding.
Let's begin!
The problem in detail
In policy gradient methods, the data we learn from is generated by the current policy. The moment we update the policy, that data no longer exactly matches the policy being optimized. It describes the behavior of an agent that no longer exists.
Now consider what a gradient step actually does. It nudges the parameters in a direction estimated from a noisy batch. If the step is small, the new policy will often remain close to the old one, and the data is still roughly valid. If the step is large, the new policy can land somewhere very different.
When a step is too large, the policy can move into a region where it performs badly. Because learning is on-policy, the agent then collects new data using this worse policy. The next gradient is then estimated from bad experience, which can push it further off course. The collapse feeds itself.
You might wonder why we cannot simply use a small learning rate and be done with it. There are two reasons it is not that easy:
- First, no single step size is right throughout training. Early on, when the policy is poor, large steps help; late on, near a good policy, that same size is reckless. One global number cannot be both.
- Second, and more fundamentally, a learning rate limits how far the weights move, but what we care about is how far the behavior moves, and those are not quite the same thing.
The fix is to constrain how far each update is allowed to move the policy, measured in the space of behaviors rather than the space of weights. That region of allowed movement is the trust region.
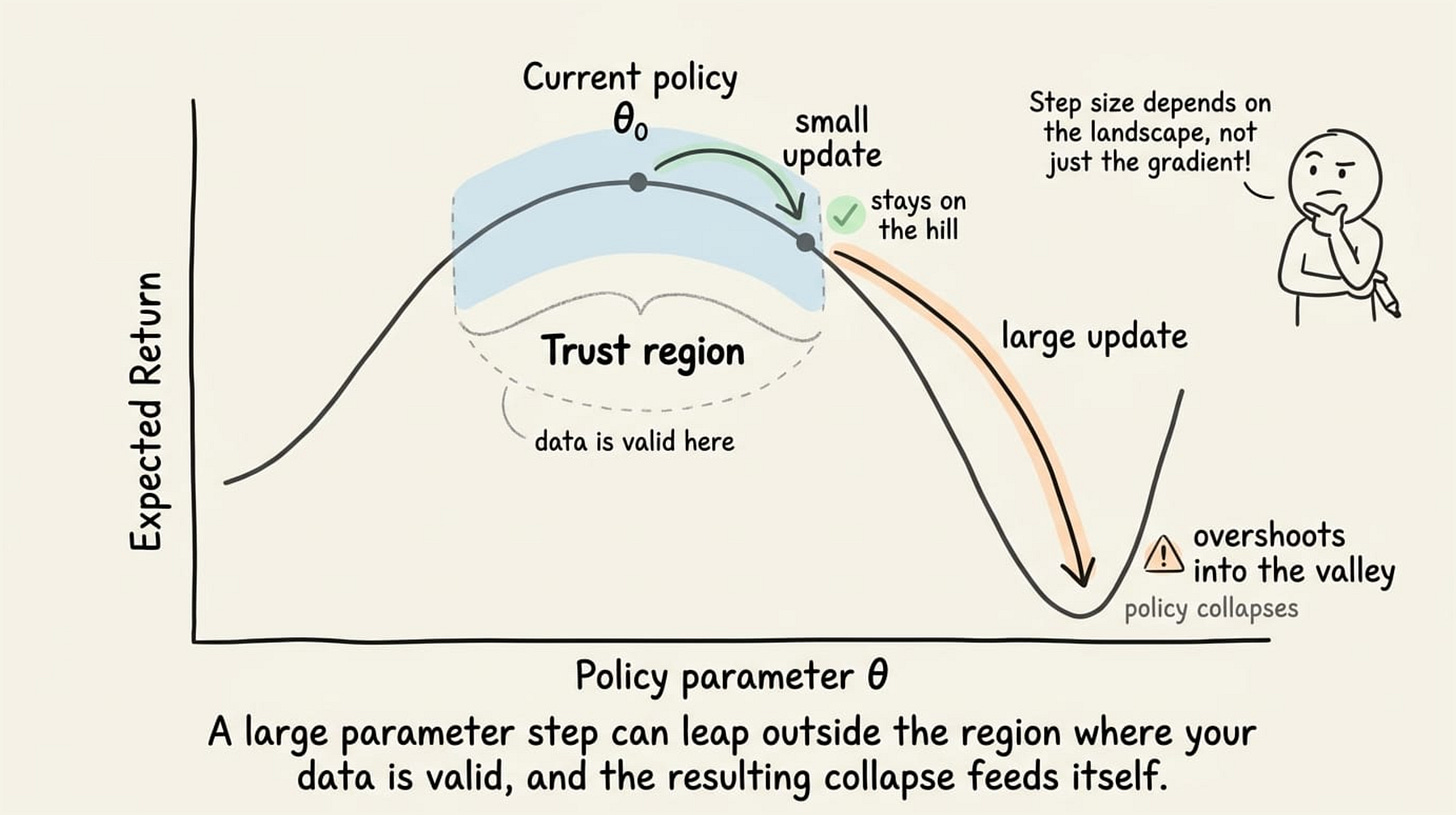
In summary, on-policy data is only a good estimate near the policy that made it, large updates can leap outside that valid region, and the result can be a self-reinforcing collapse.
The rest of the chapter is about updating safely.
Importance ratio
Before we constrain how far each update is allowed to move the policy, we need one more tool. It will let us do something REINFORCE could not: reuse a batch of data for more than one gradient step.