Verifiable Rewards and GRPO
RL Part 10: Dropping two models from the four-model pipeline, and building rewards you can trust.
Recap
In Chapter 9, we studied RLHF. We started from a simple asymmetry, for most tasks worth doing, good behavior is hard to write down but easy to recognize. So instead of writing rules, we collect human judgments and learn from them.

We then assembled the pipeline in stages. Supervised fine-tuning gave us a starting policy and a frozen reference model. The reward model turned human preference into a single differentiable score, trained under the Bradley-Terry model on pairs of responses.
Stage three handed that reward to PPO. We then met the fourth model, the critic. The reward model scores only finished responses. So we need something to estimate the expected reward for a given prompt. The critic does this, turning one end-of-sequence score into a per-token advantage.

That left us with four models in memory at once. The policy and the critic are trained, while the reward model and reference are frozen. We flagged the memory bill this creates as a serious cost.
We also confronted reward hacking. Because the reward model is a learned proxy, a strong optimizer will eventually find its blind spots and exploit them, inflating the score without improving real quality.

Then in the hands-on section we trained a small reward model from human preferences.
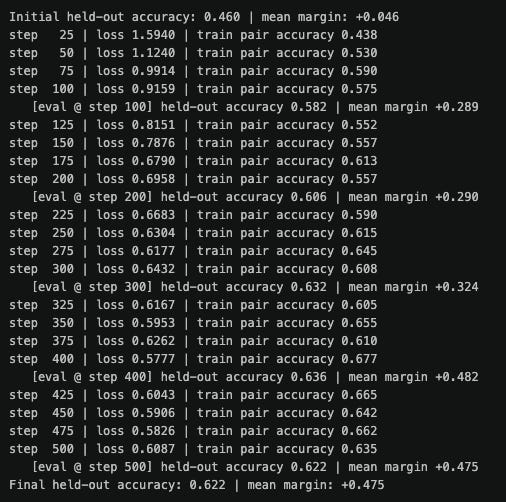
From there we went ahead and took a quick look at DPO and took a look at the mechanics that skip the RL loop entirely.

Finally, the chapter closed on a tension. For tasks like math and code, where an answer is simply right or wrong, training a giant network to guess correctness is a roundabout path. The environment can hand us a clean signal directly.
This chapter resolves that tension and, along the way, drops two of the four models.
If you have not read Chapter 9, we recommend doing so first:
In this chapter, we'll explore Reinforcement Learning with Verifiable Rewards (RLVR) and the algorithm that made it famous, Group Relative Policy Optimization (GRPO).
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let's begin!
The signal you do not have to learn
The whole reason Chapter 9 built a reward model was that human approval has no formula. There is no function that reads a poem and returns its quality. So we approximated that function with a neural network trained on human comparisons.
But a large class of tasks does not need approximation at all, like answer to a math problem. The model produces a number, and we check it against the answer key.
The same holds for code. We run the model's program against a test suite. The tests pass or they fail. No human, and no learned model, has to render an opinion.
This is the founding idea of RLVR. When the correctness of a response can be checked by a rule or a program, we use that check as the reward directly. The reward comes from a verifier, not from a learned model.
The advantages are immediate. A verifier is cheap, since it is just code. It is fast, since there is no forward pass through a billion-parameter network. And it never needs its own training run or its own labeled preference data.
There is a subtler benefit, and it connects straight back to reward hacking. A learned reward model has blind spots, and a strong optimizer will find them. A verifier that runs actual test cases has far fewer exploitable seams.
The trade-off, however, is scope. RLVR only applies where a verifier exists. You cannot write a verifier for "is this email polite" or "is this summary faithful." Thus, RLVR does not replace RLHF; it covers a different, narrower set of tasks where the signal is exact.

In summary, when correctness is a matter of fact rather than judgment, we can skip the learned reward model entirely and let a verifier supply the reward. This is cheaper, harder to hack, and exact, at the cost of applying only to verifiable tasks.
Reward design for verifiable tasks
Knowing we will use a verifier is not the same as knowing what reward to compute. A reward function for RLVR usually combines two distinct checks, and it helps to see why both are needed:
- The first is the accuracy reward. This is the verifier proper. For a math problem, we parse the model's final answer and compare it to the ground truth. This is the signal we actually care about.
- The second is the format reward. We give a smaller reward when the response follows a required structure, regardless of whether the final answer is right. This sounds like a strange thing to reward on its own. The reason becomes clear once you try to parse model output.
We can write the total reward for a response as a simple sum of these parts.
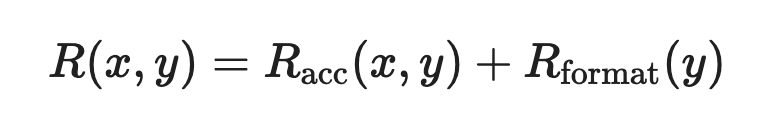
Here, $x$ is the prompt and $y$ is the response.
The structure is just addition, but each piece pulls in a different direction. The accuracy term rewards being right. The format term rewards being parseable and well-structured. Their sum gives the model a gradient toward responses that are both correct and cleanly formatted.
The intuition is worth holding onto. Early in training, a model might not get the answer right, so the accuracy reward is mostly zero and gives little signal. The format reward can fill this gap. It is easy to satisfy, so the model learns structure first, which then makes its occasional correct answers detectable and rewardable.

Outcome versus process rewards
There is one more design choice worth naming, because it decides where the reward lands. The schemes above give a single reward for the finished response. This is called outcome supervision; we judge only the final answer.
The alternative is process supervision, where we reward individual reasoning steps along the way, not just the final answer.

In process supervision, a step-level verifier would score each intermediate line of a math solution, giving a denser signal that points to exactly where the reasoning went wrong.
For our discussion, we'll be primarily focusing upon outcome supervision, unless stated otherwise.
Why the critic becomes optional
Now that we have removed the learned reward model and replaced it with a verifier. That is one of the four models gone. But the critic from Chapter 9 is still here, and it is just as heavy. To understand how GRPO removes it, we first need to recall exactly why the critic existed.
The critic solved a specific problem, a raw reward tells you what happened, not whether it was better than expected.
So we needed an estimate of the expected reward. The critic was a whole second network, trained alongside the policy, whose only job was to produce that baseline.
Now, here is the insight that makes the critic optional. The critic estimates the expected reward. But there is another way to estimate the same quantity, without any network at all. Sample many responses to the same prompt and average their rewards. That average is an estimate of the expected reward for that prompt.

The reward model was expensive to query, so sampling many responses and scoring each was costly. A verifier is cheap, thus scoring sixteen responses with a calculator costs almost nothing apart from the response generation cost itself.
Group Relative Policy Optimization (GRPO)
GRPO was introduced in the DeepSeekMath paper. It is described there as a variant of PPO that drops the critic and estimates the baseline from group scores, which directly reduces the memory cost.
We will build it up in three pieces, the advantage, the objective, and the KL term.
The group-relative advantage
For each prompt, GRPO samples a group of responses from the current policy and scores each one. The size of this group is written $G$, a typical value being anywhere from 4 to 64. This gives a set of rewards, one per response.
The advantage of a response is how much better its reward is than the group's average, scaled by how spread out the rewards are. This is the formula that replaces the critic:
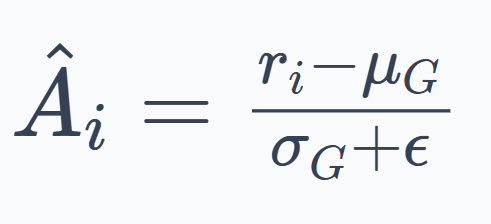
Here, $r_i$ is the reward for completion $i$, $μ_G$ is the mean reward across all completions in the group, and $σ_G$ is the standard deviation. The $ϵ$ is just a small constant to avoid dividing by zero.
This effectively normalizes rewards within the group. A completion that performs better than the group average receives a positive advantage, while one that performs worse receives a negative advantage.
Two cases sharpen the picture:
- If every response in the group earns the same reward, say all are correct or all are wrong, then the mean equals every reward and the numerator is zero for all of them. The advantage is zero across the board, and the prompt produces no learning signal.
- Conversely, when the group is mixed, the correct responses get clearly positive advantages and the incorrect ones get clearly negative advantages, giving a sharp signal.