LLMs
Transformer vs. Mixture of Experts in LLMs
A popular interview question.

Avi Chawla
A popular interview question.

TODAY'S ISSUE
Mixture of Experts (MoE) is a popular architecture that uses different "experts" to improve Transformer models.
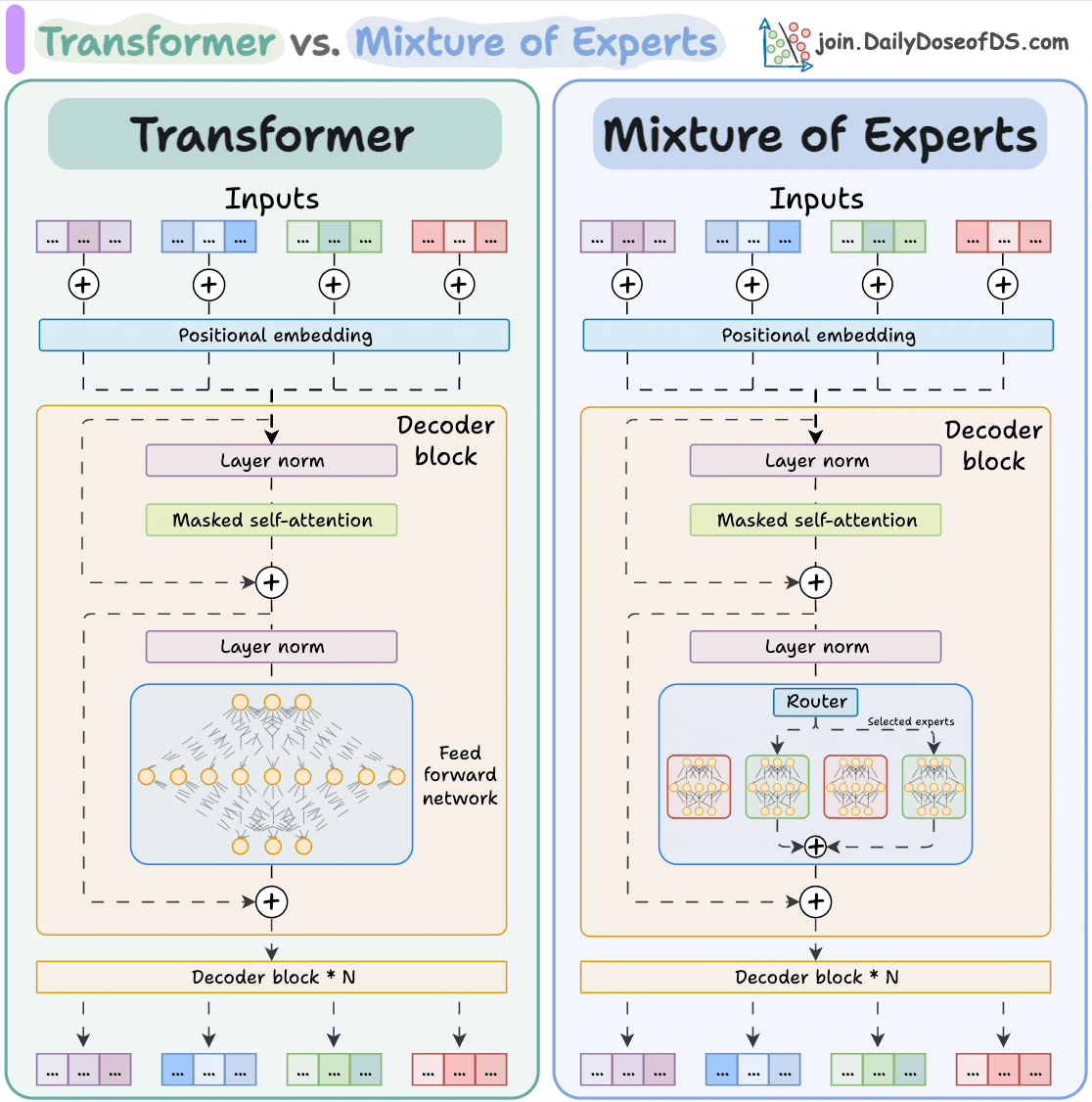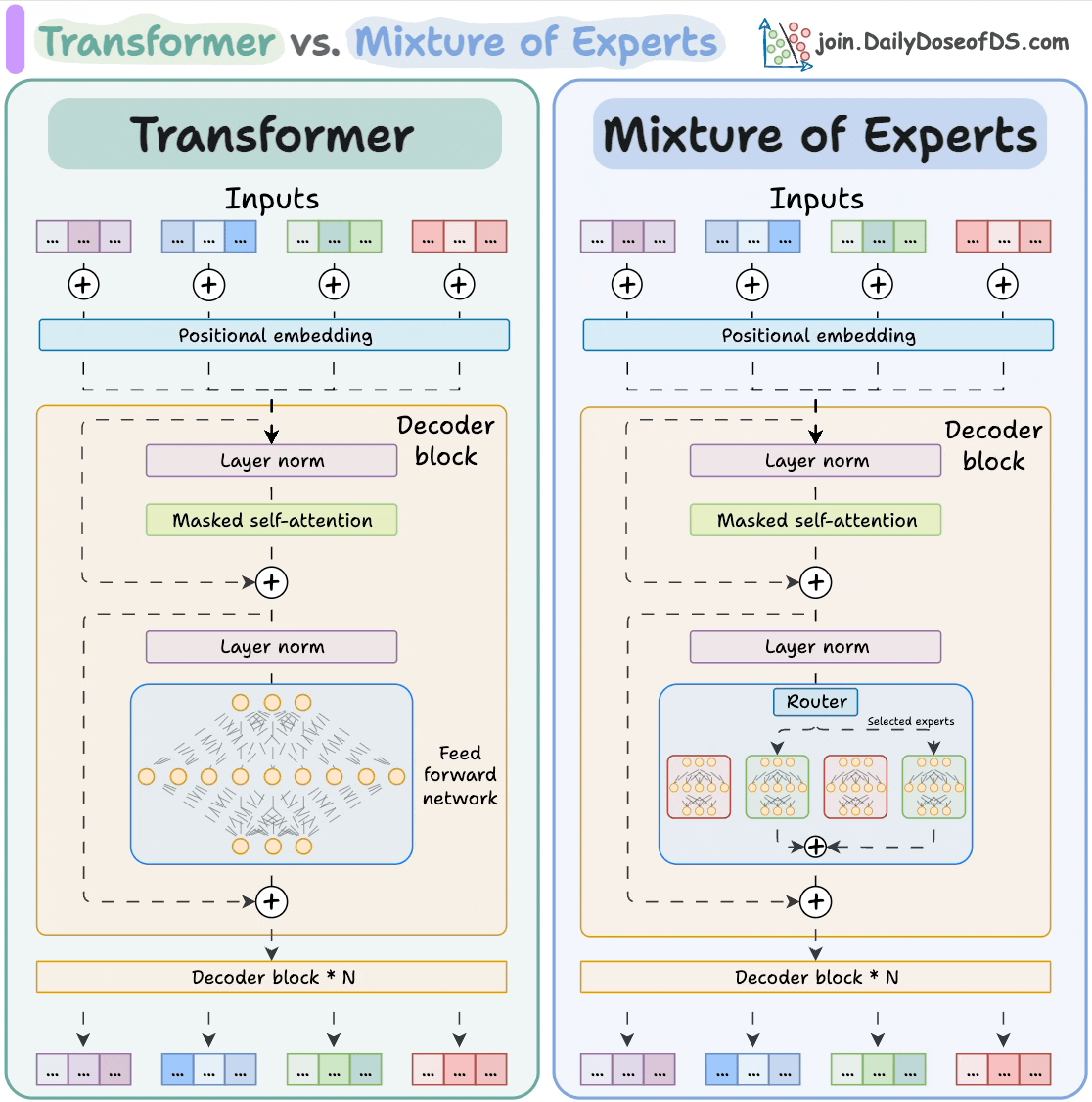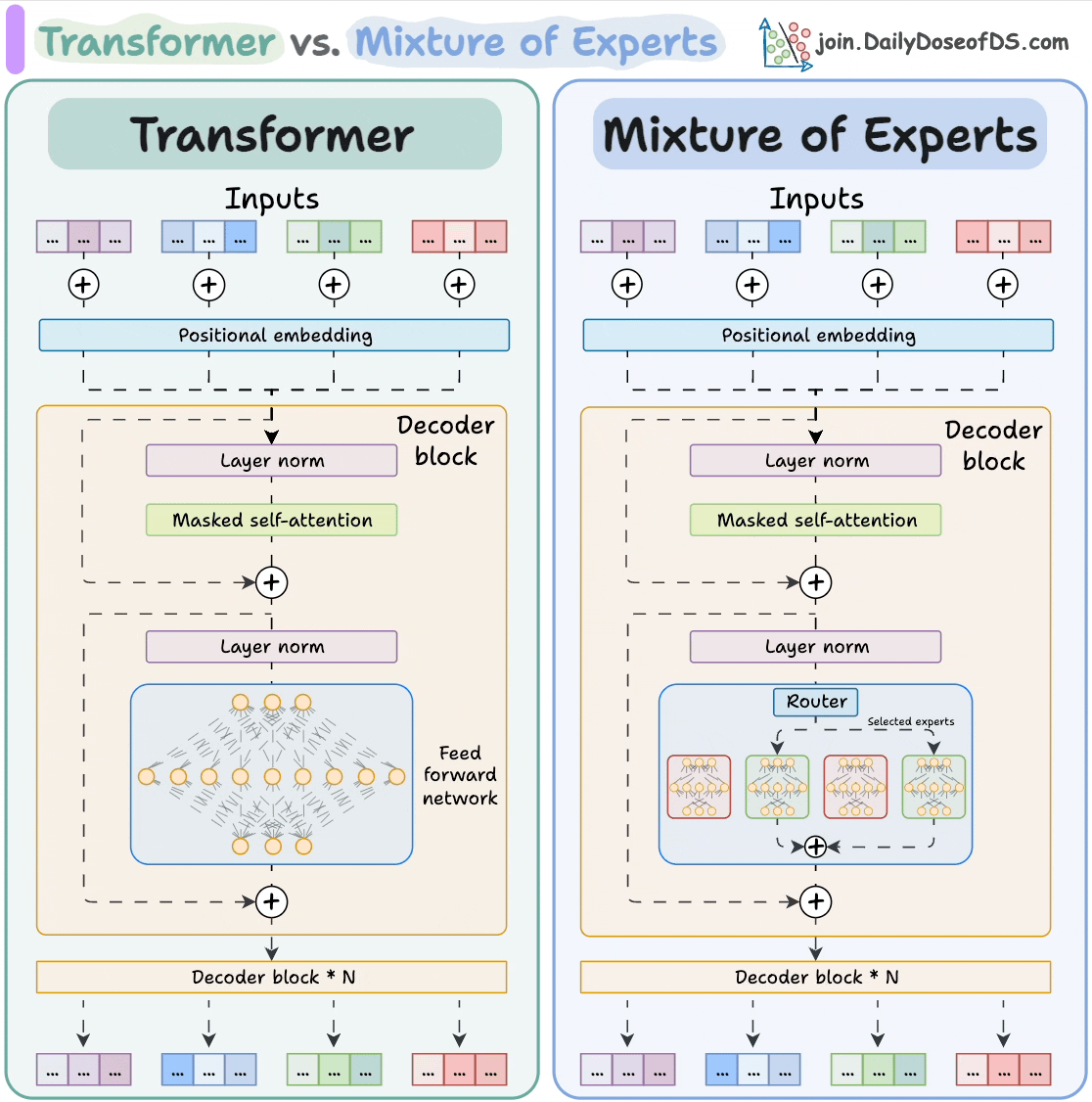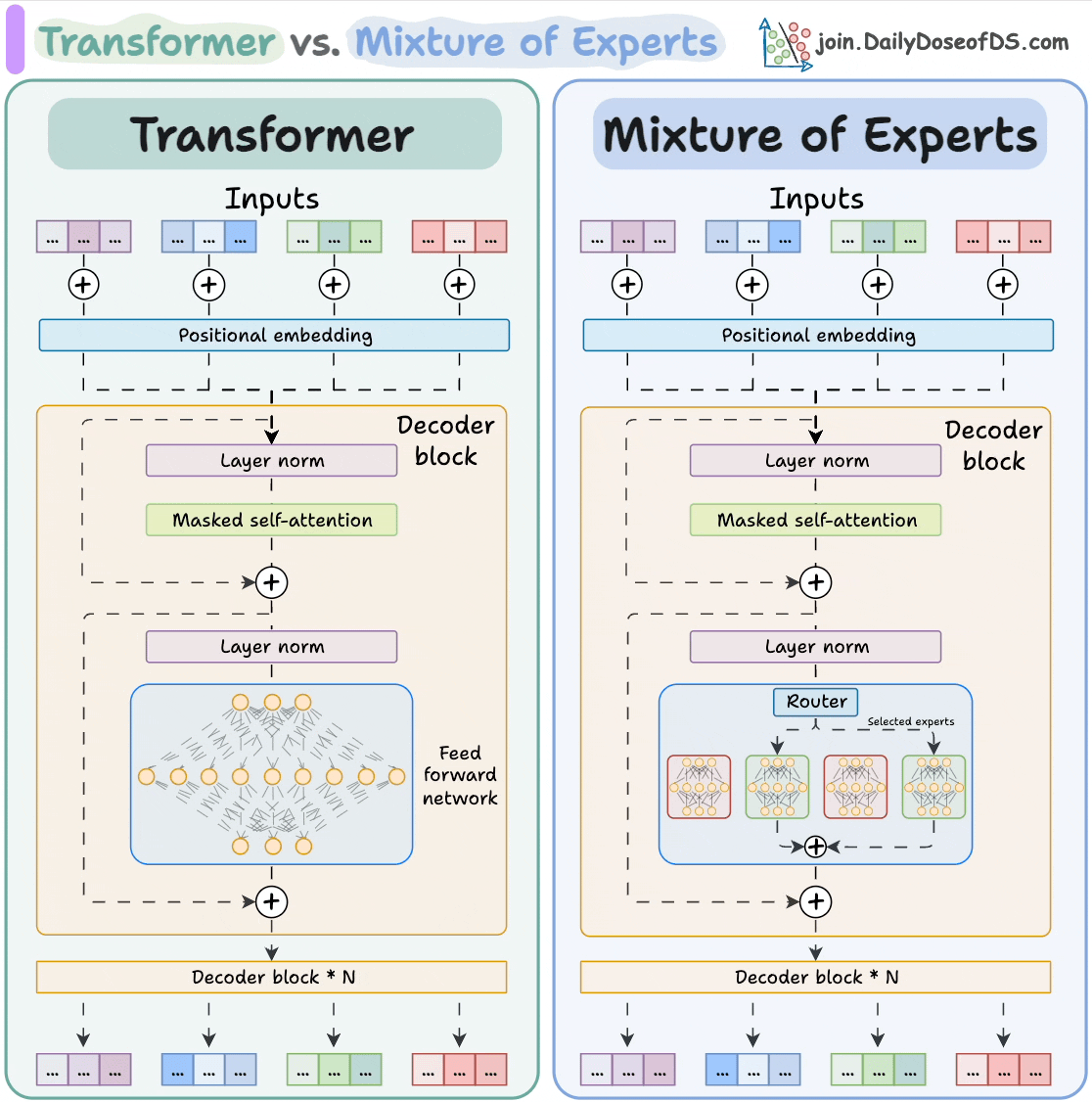
The visual below explains how they differ from Transformers.
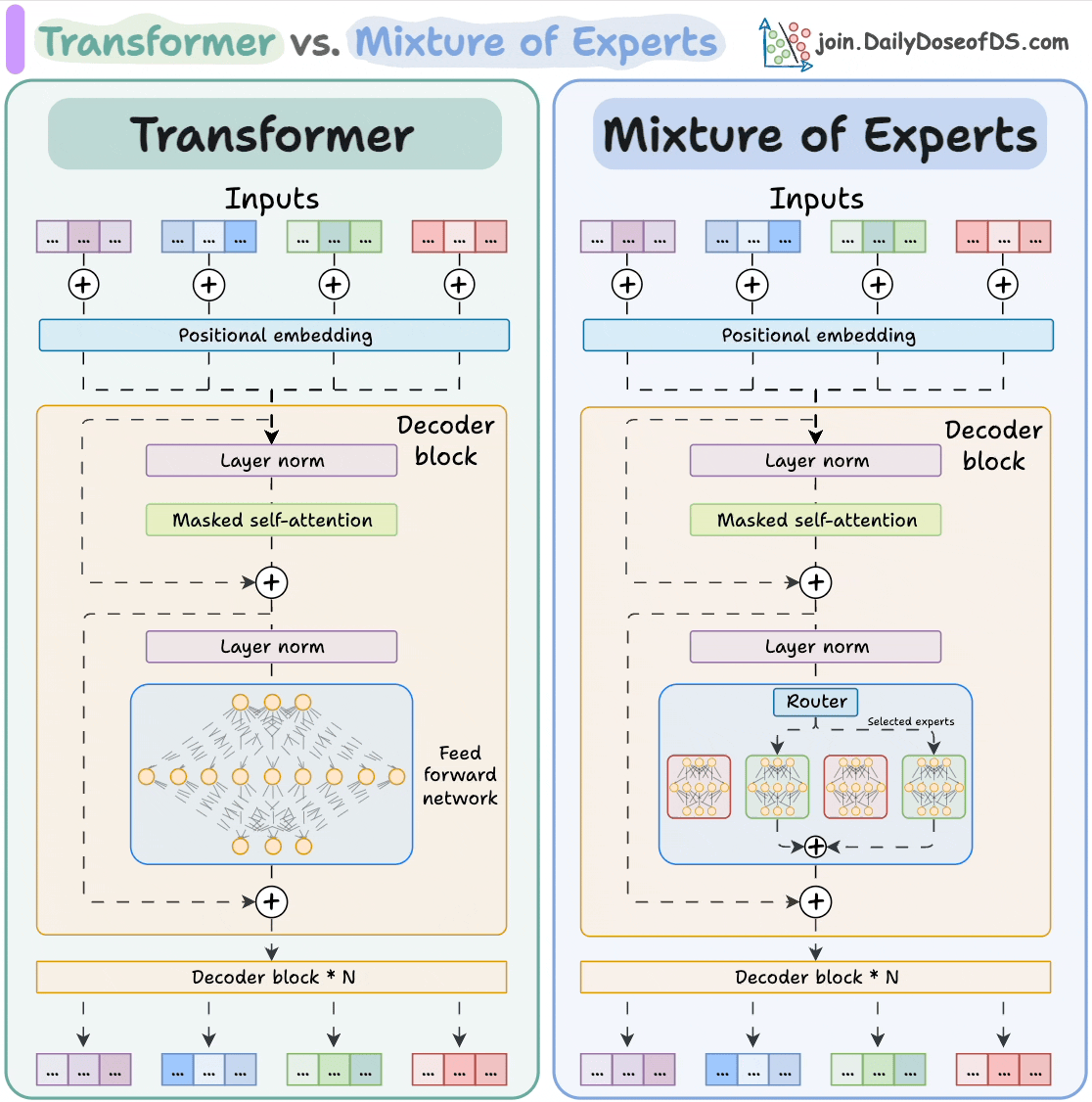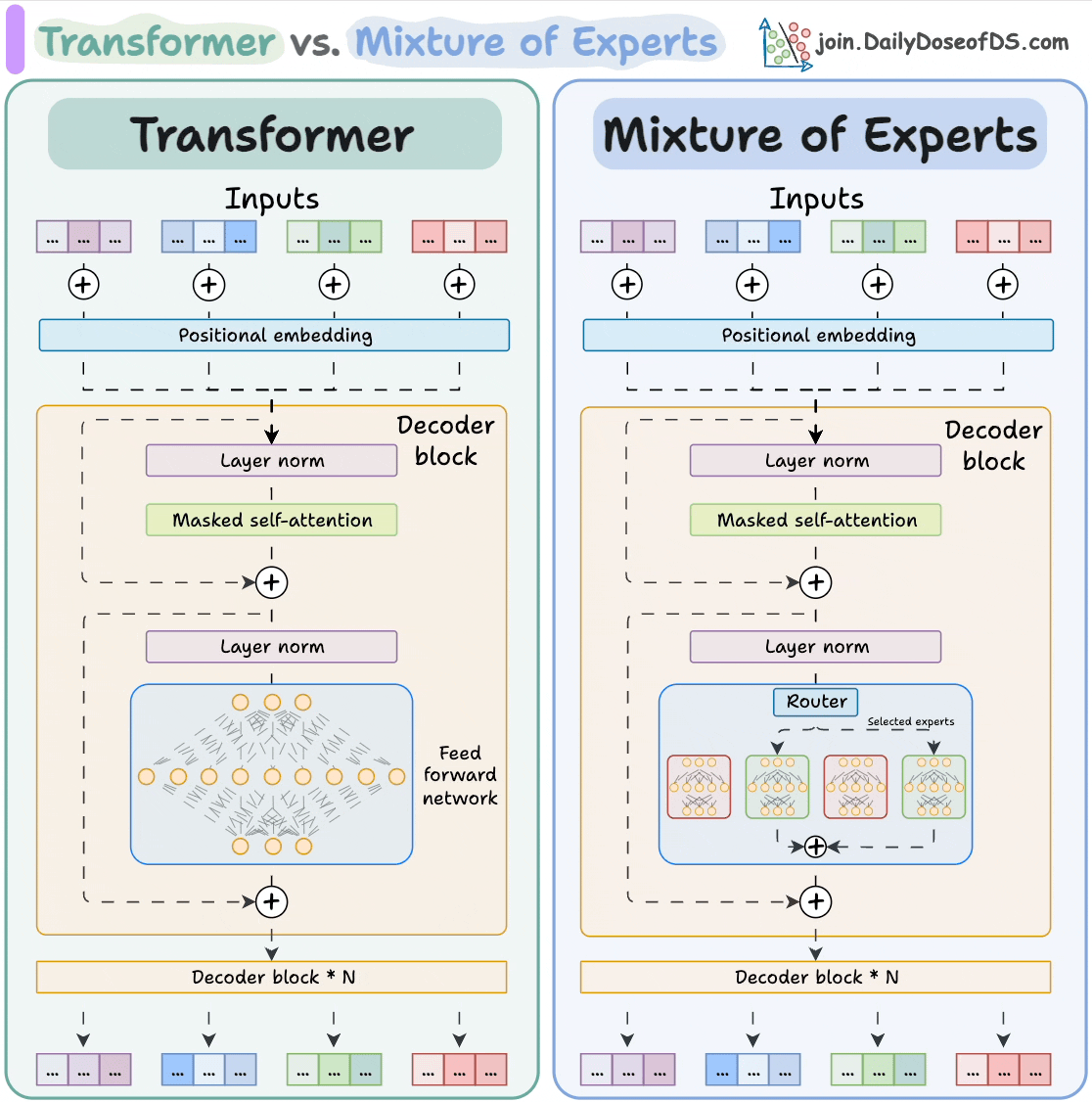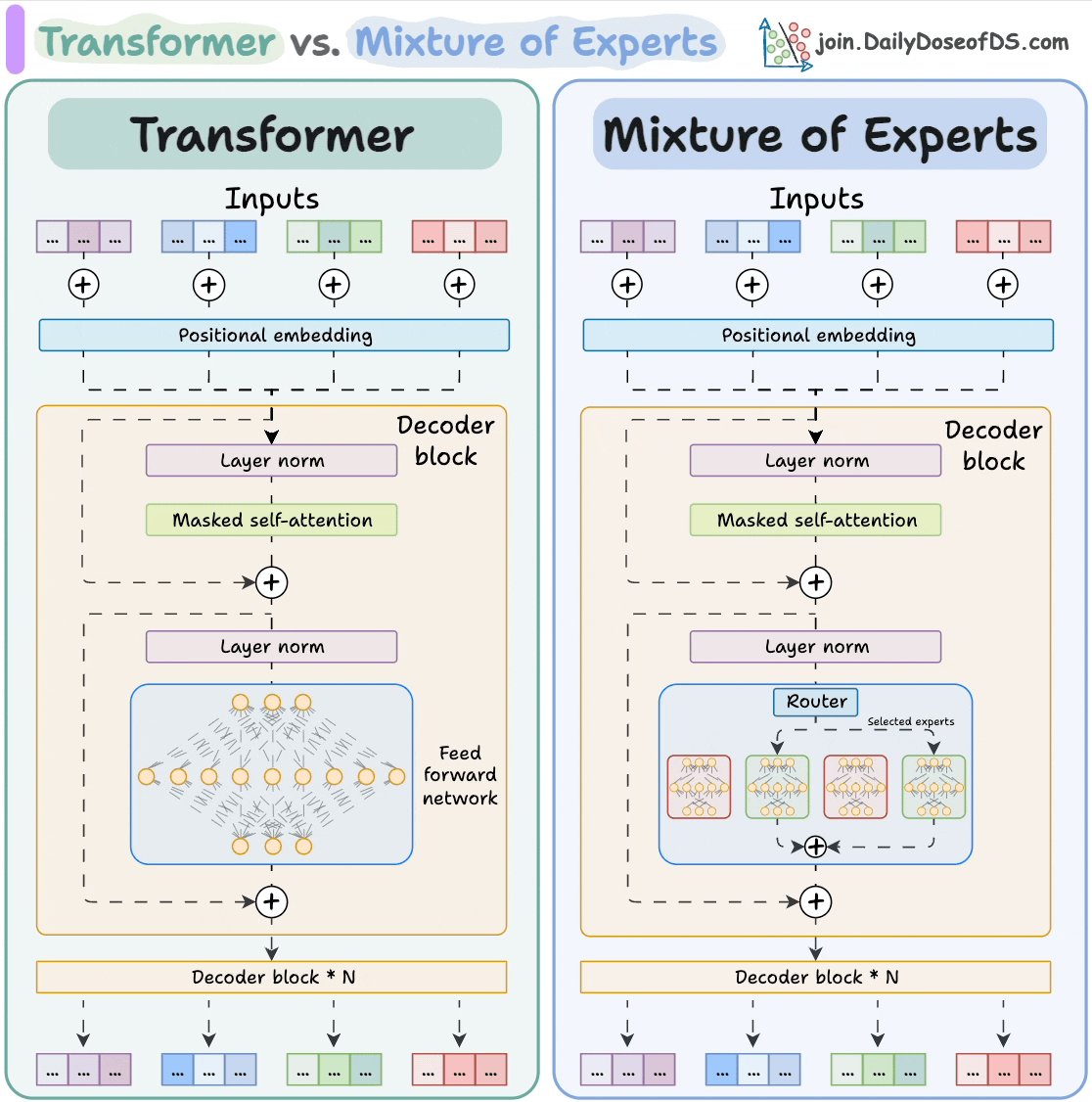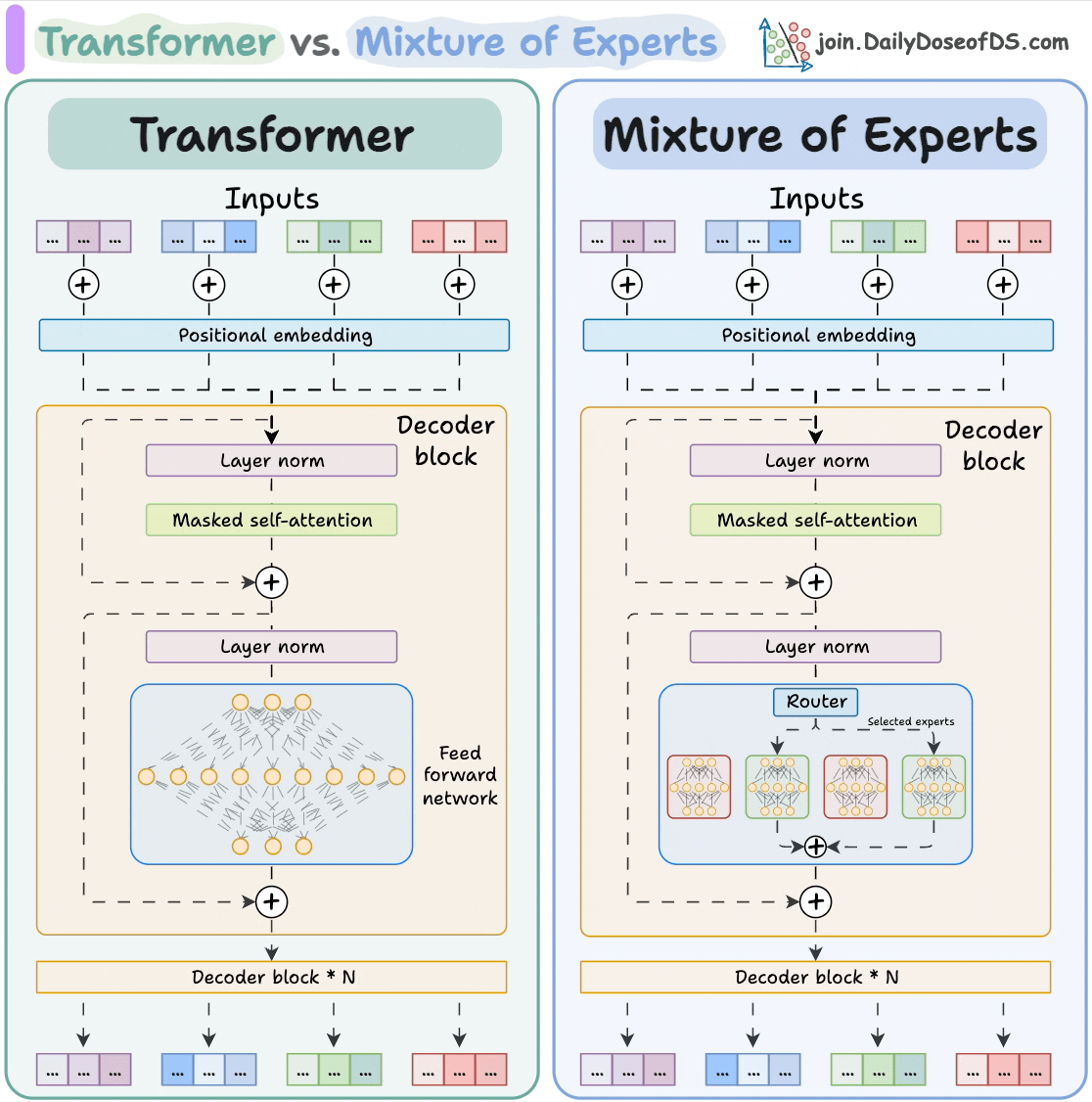
Let's dive in to learn more about MoE!
Transformer and MoE differ in the decoder block:

During inference, a subset of experts are selected. This makes inference faster in MoE.
Also, since the network has multiple decoder layers:
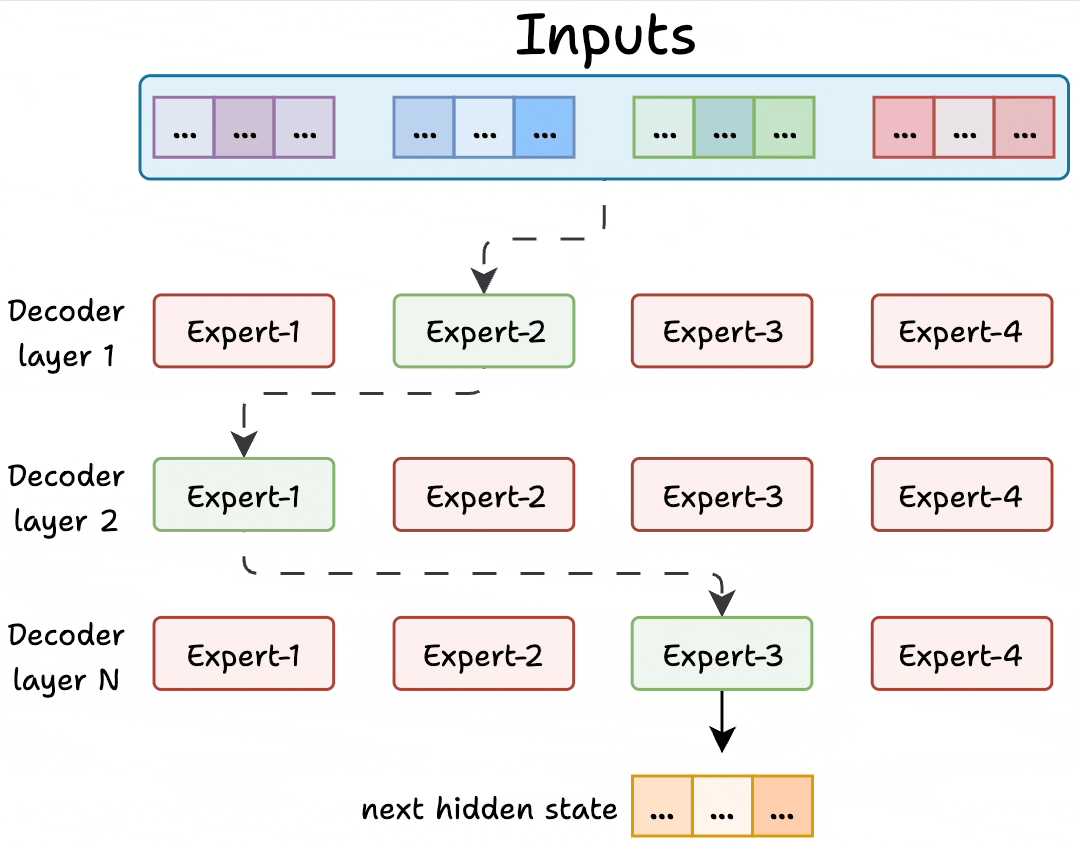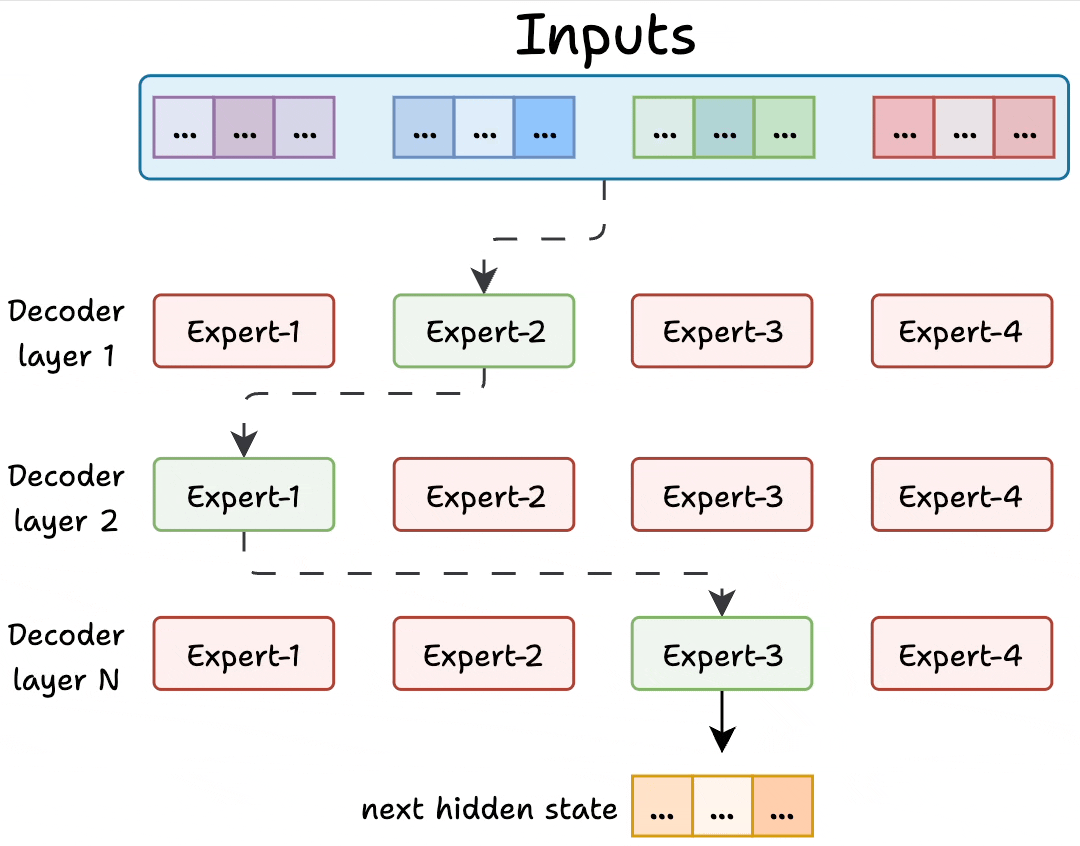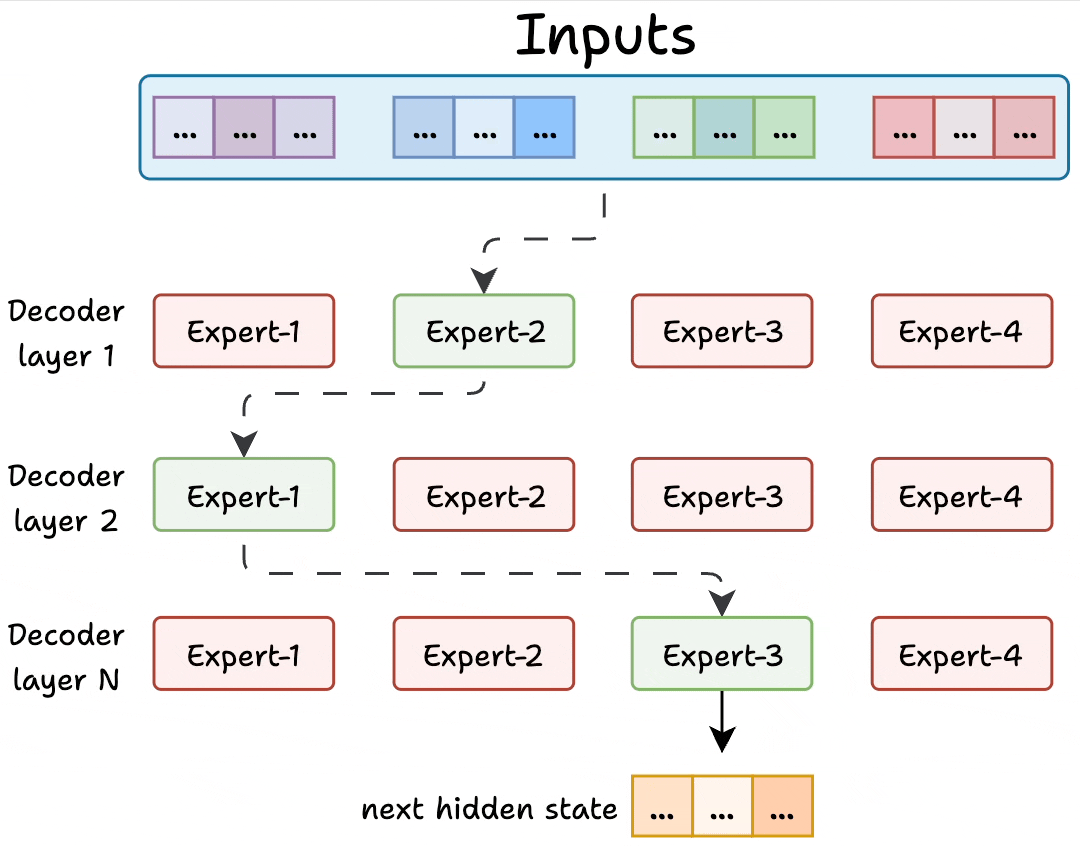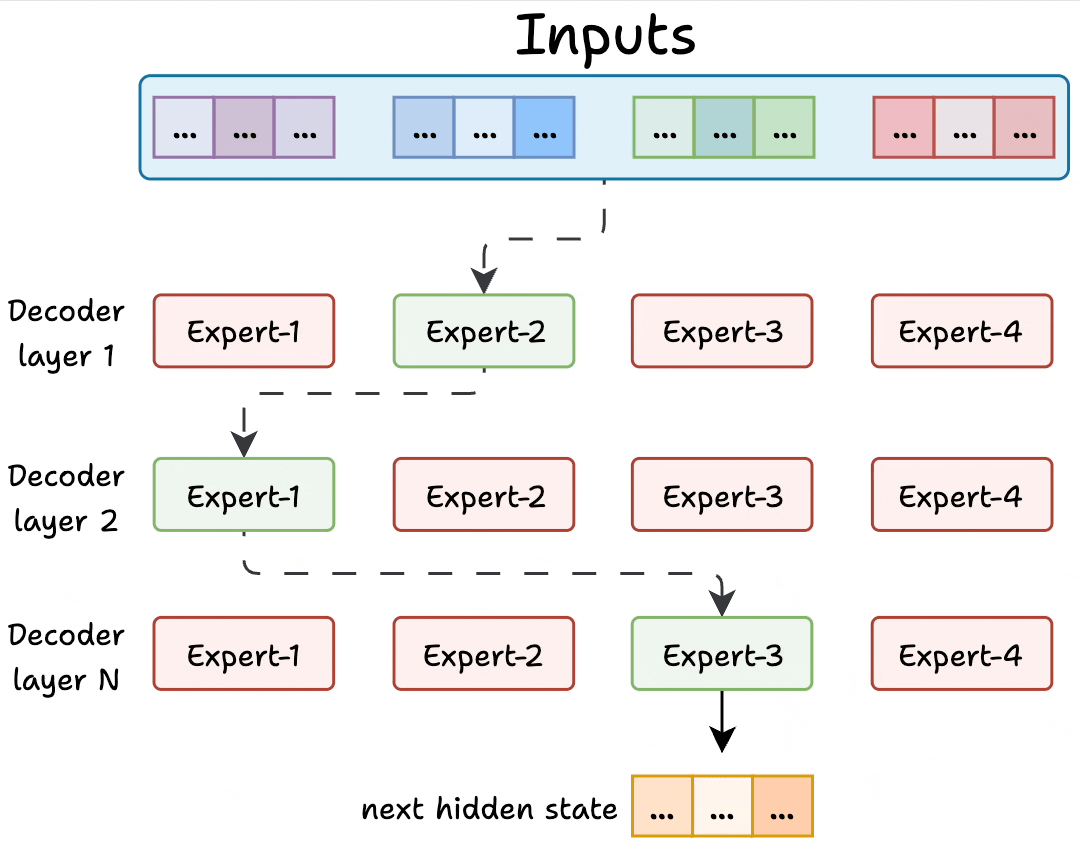
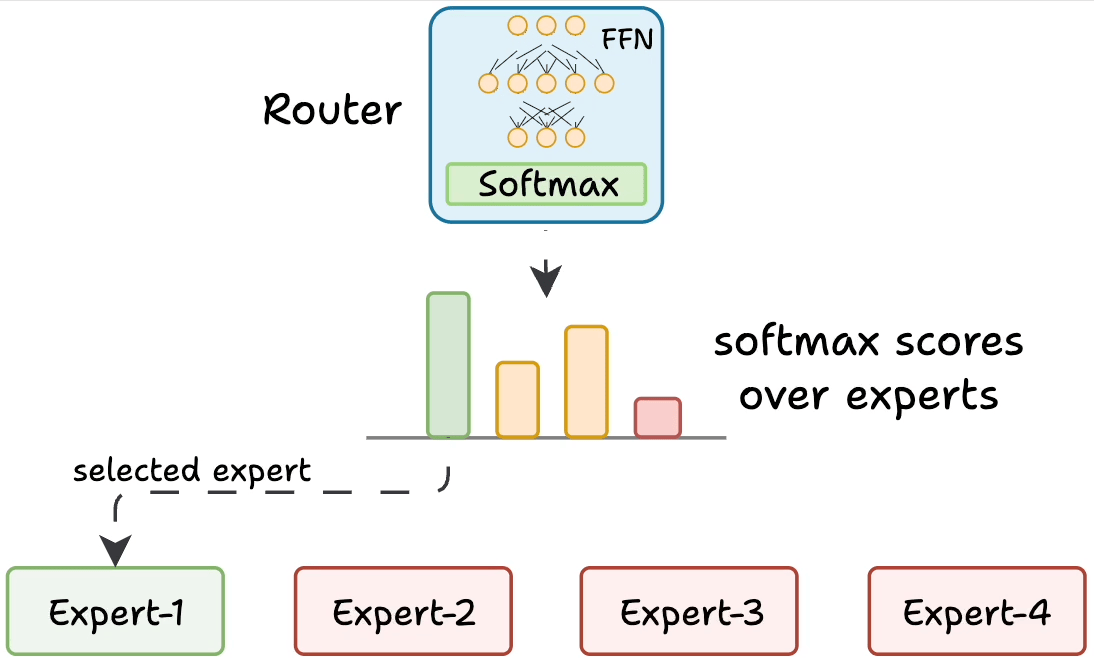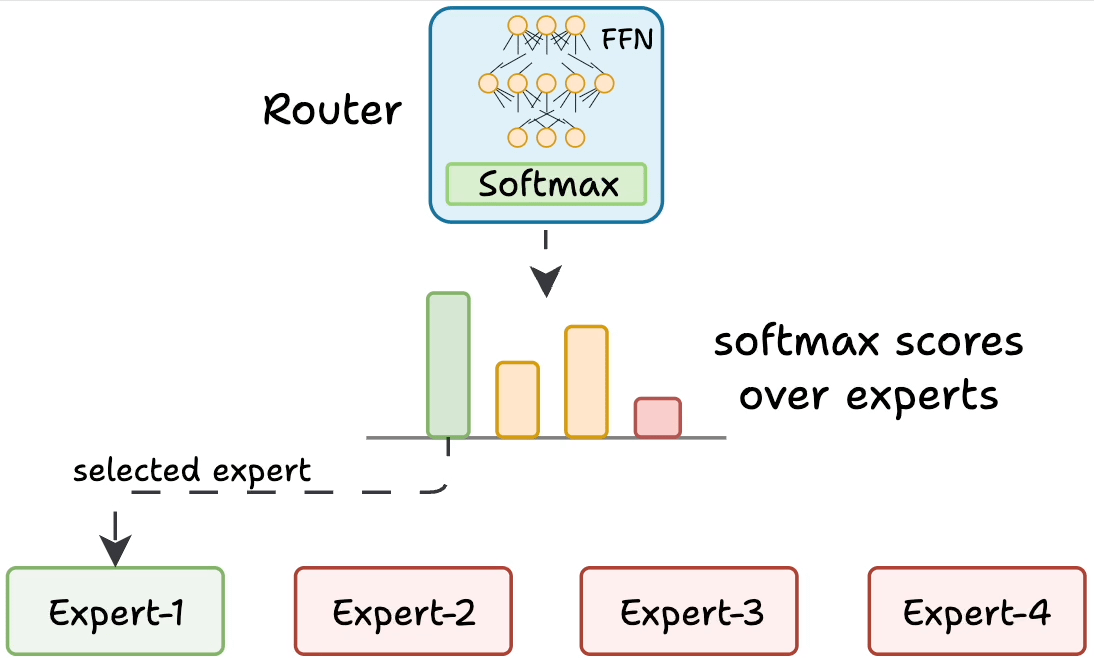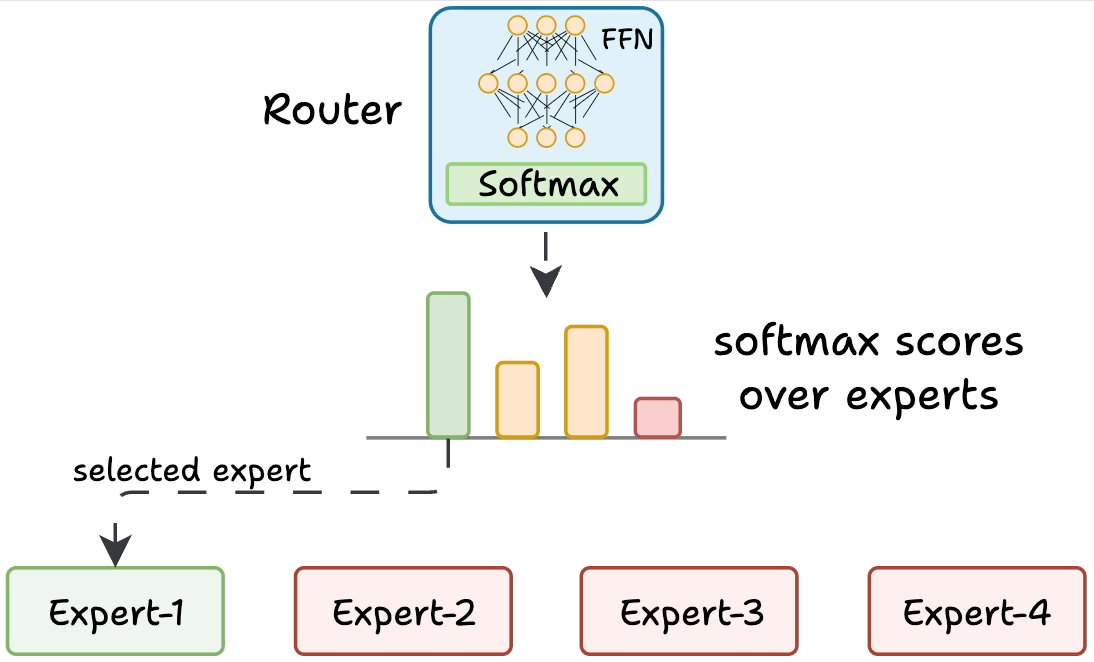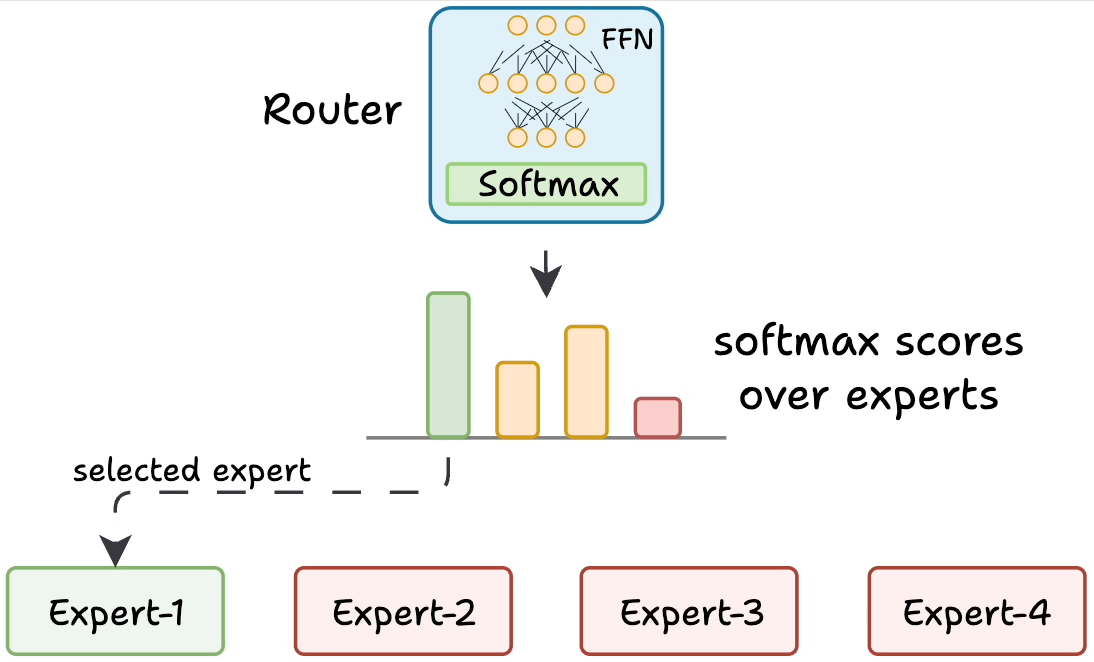
But how does the model decide which experts should be ideal?
The router does that.
The router is like a multi-class classifier that produces softmax scores over experts. Based on the scores, we select the top K experts.
The router is trained with the network and it learns to select the best experts.
But it isn't straightforward.
There are challenges.
Challenge 1) Notice this pattern at the start of training:
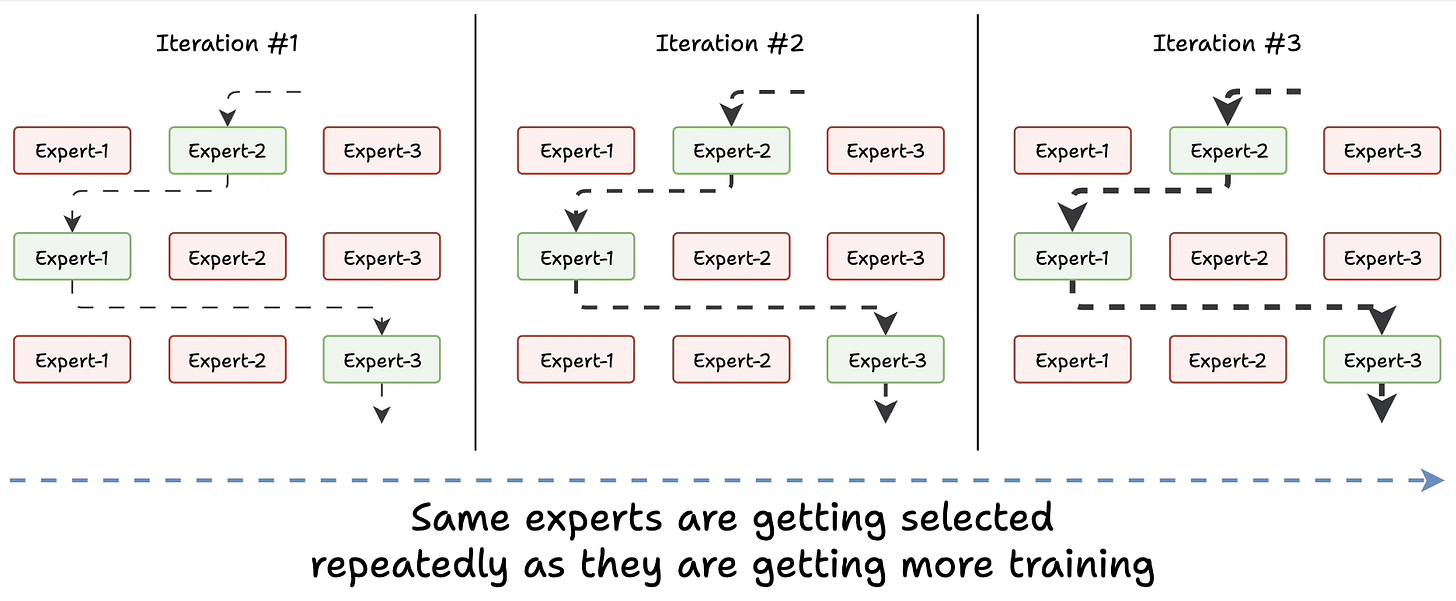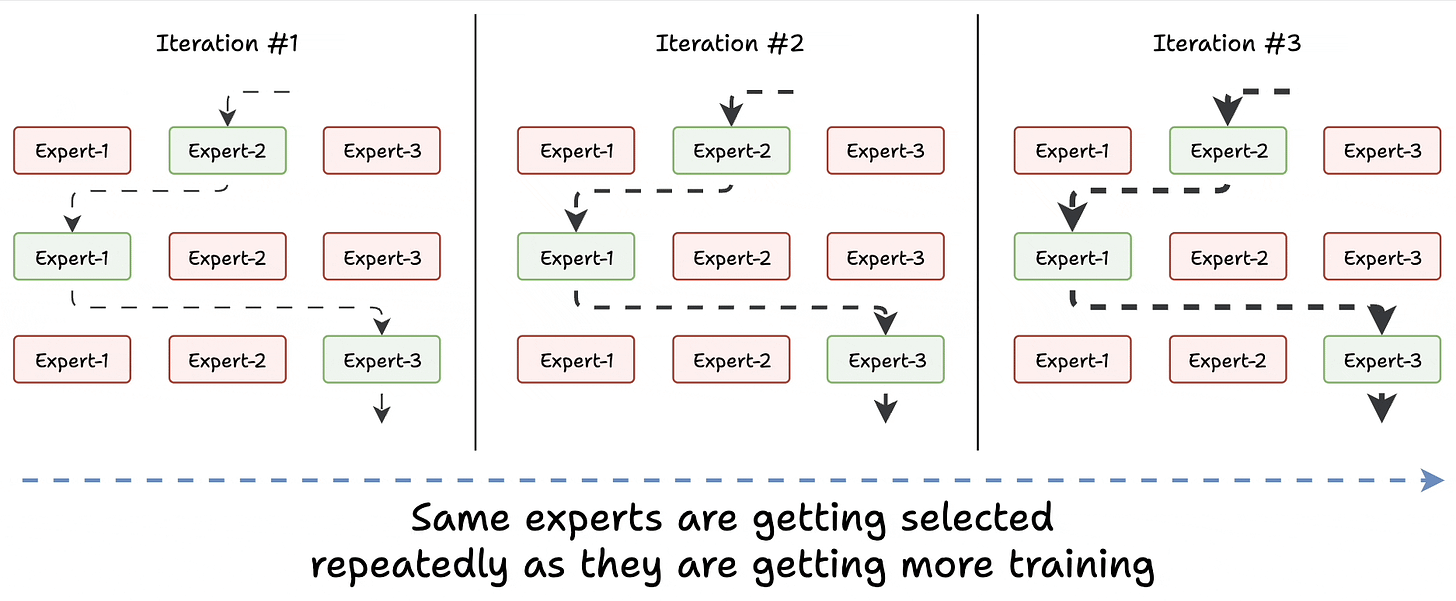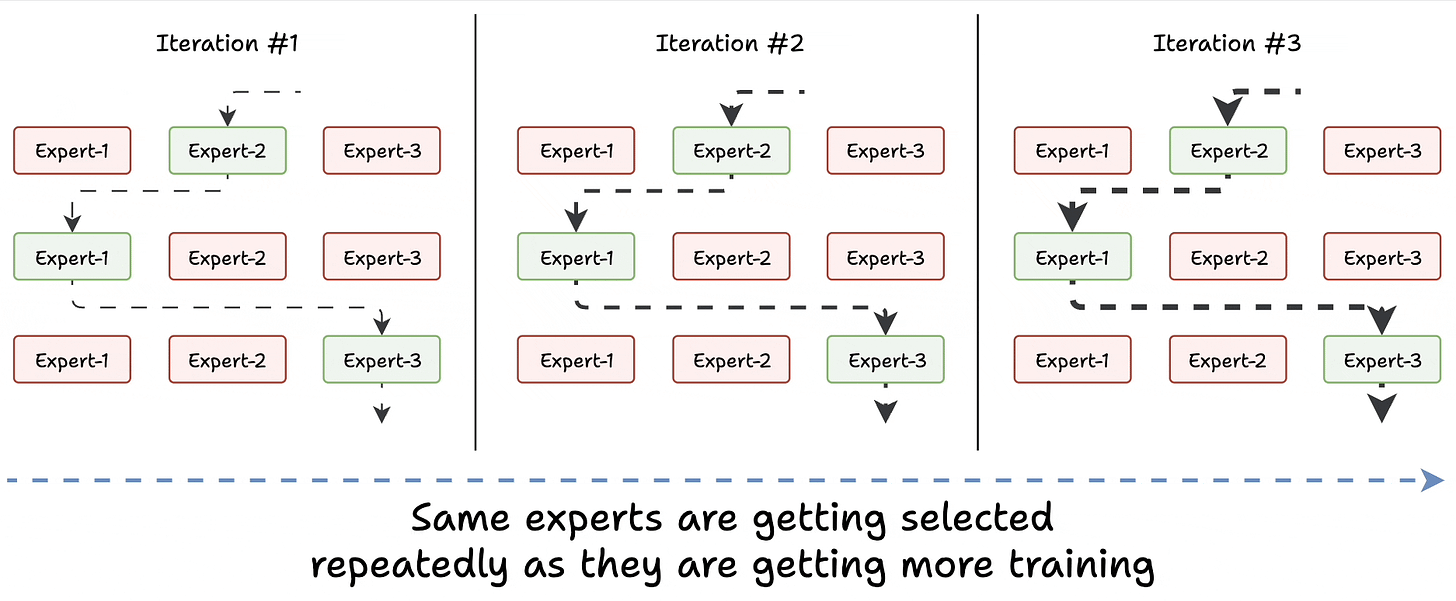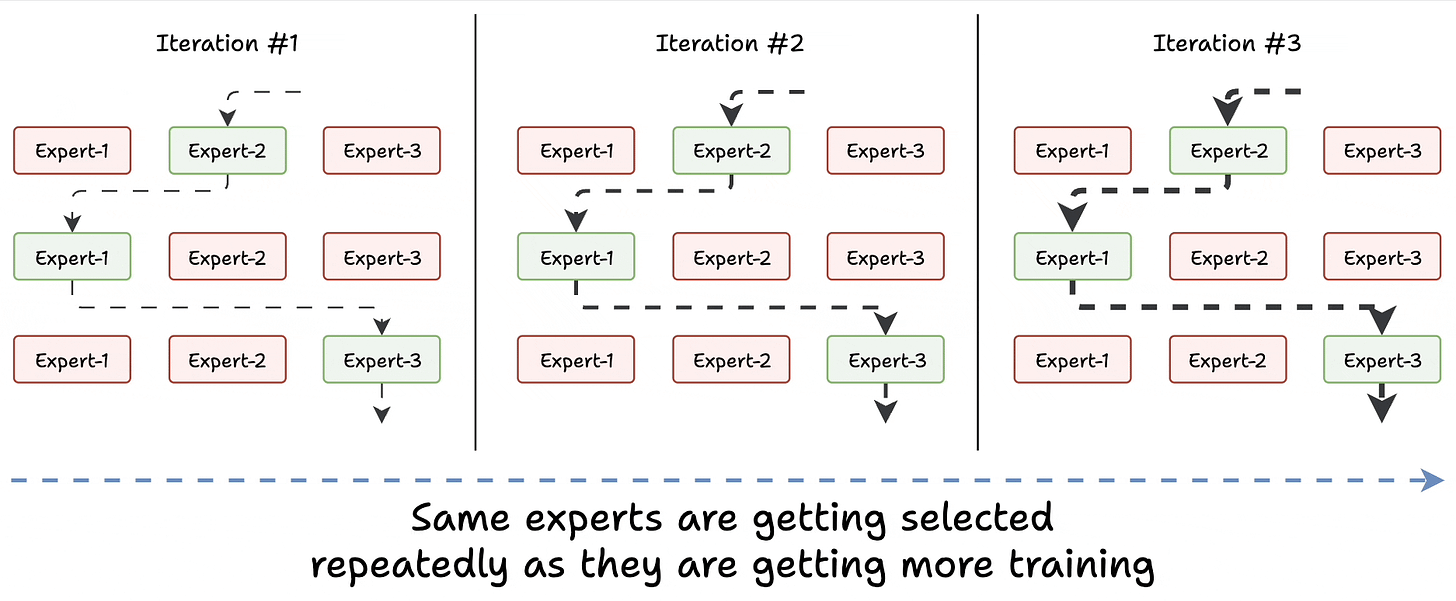
Essentially, this way, many experts go under-trained!
We solve this in two steps:
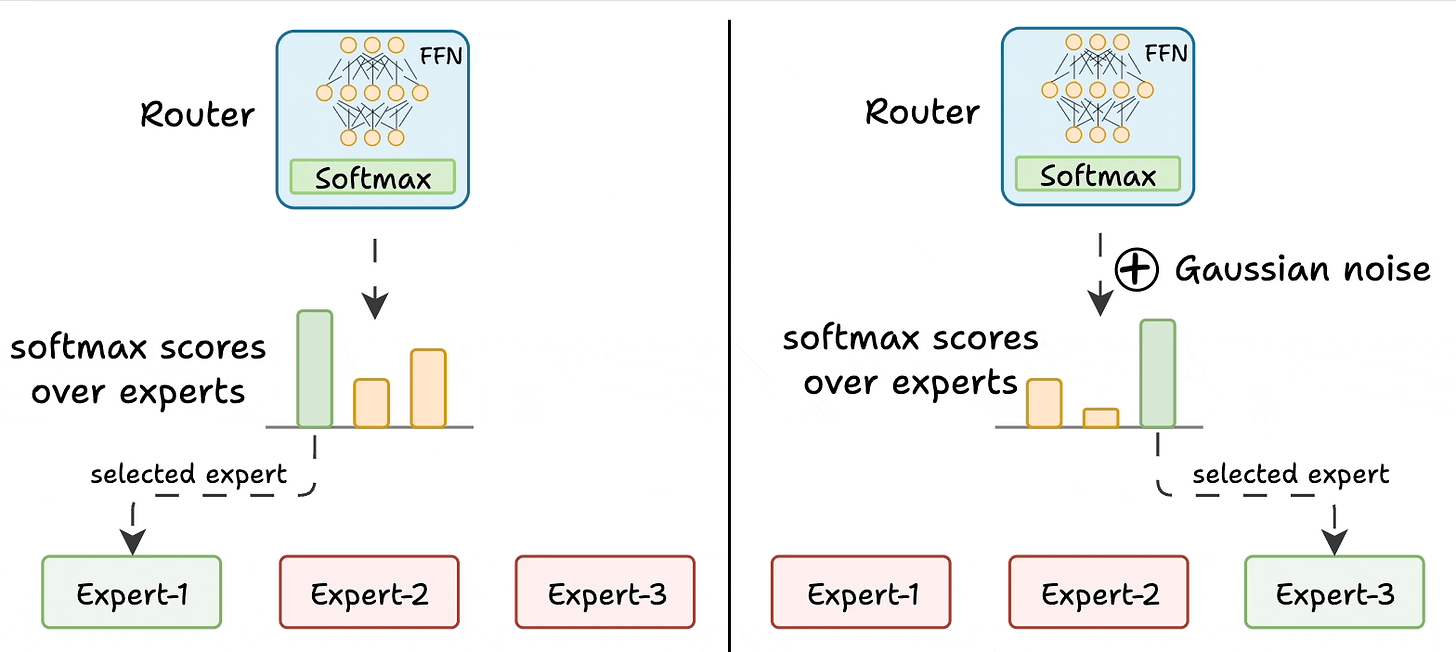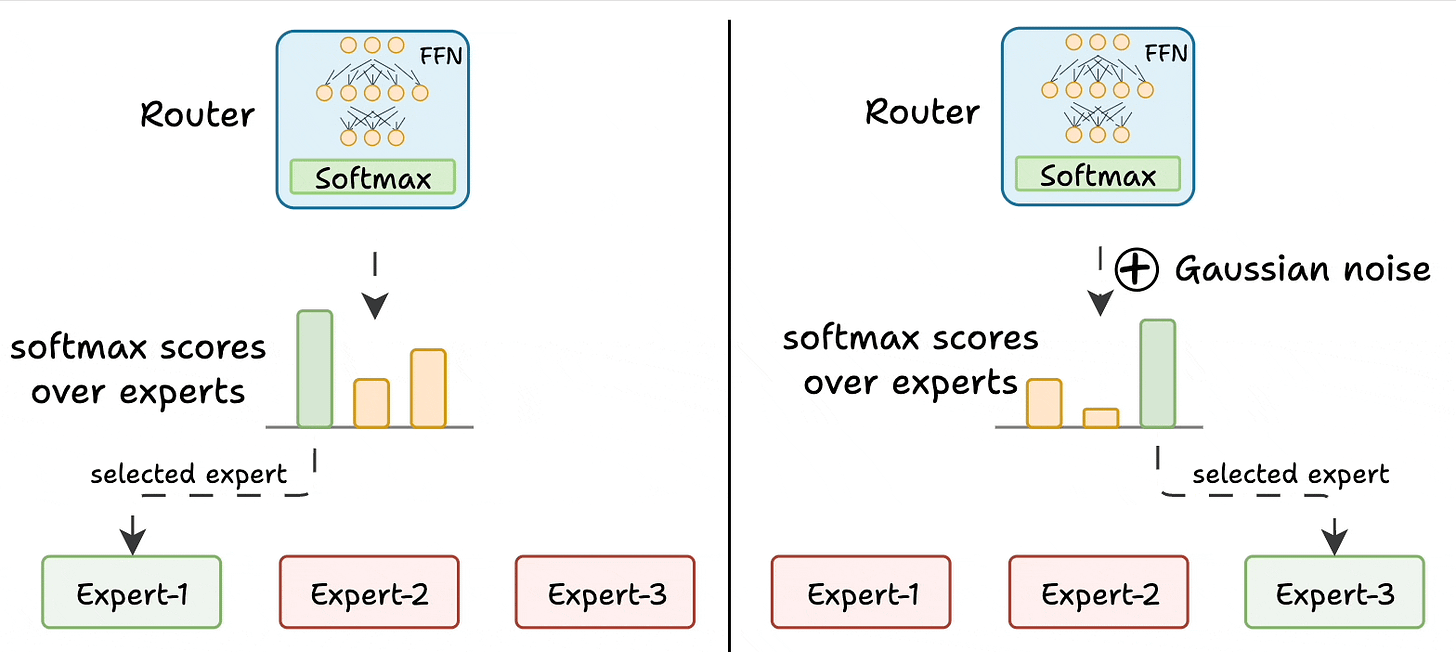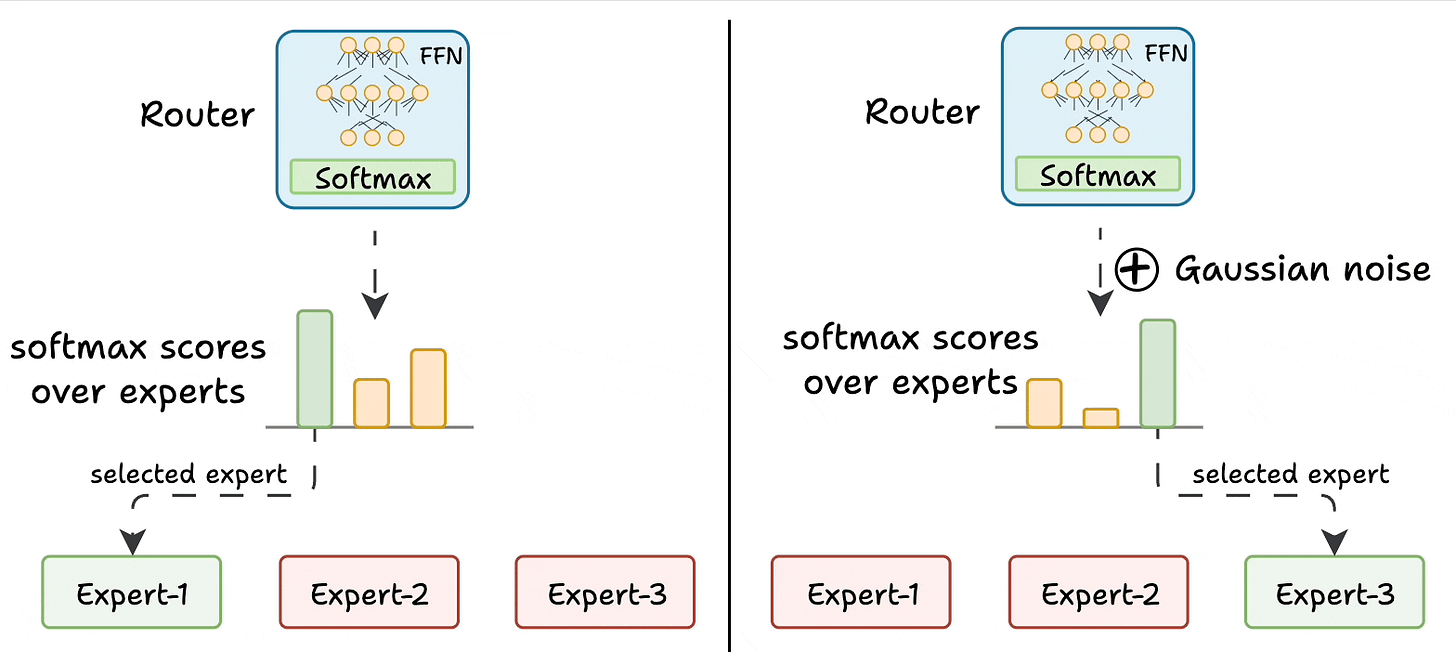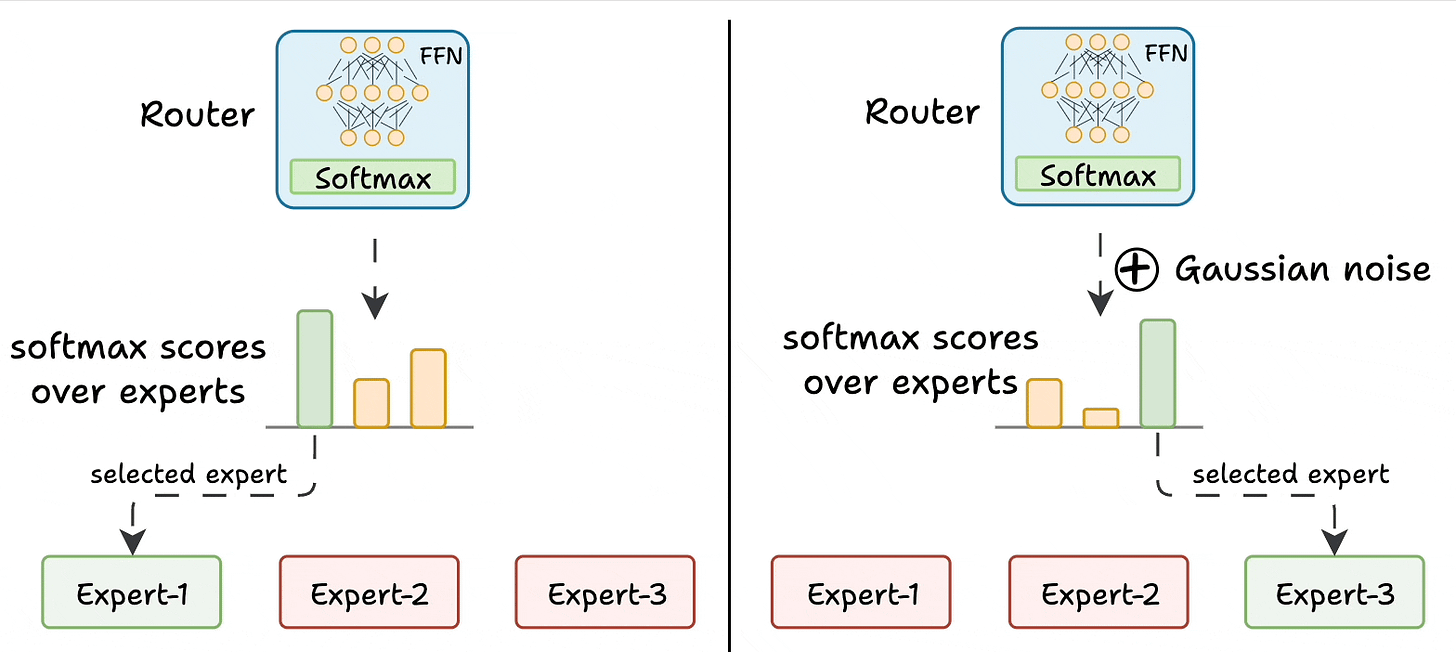
K logits to -infinity. After softmax, these scores become zero.This way, other experts also get the opportunity to train.
Challenge 2) Some experts may get exposed to more tokens than others—leading to under-trained experts.
We prevent this by limiting the number of tokens an expert can process.
If an expert reaches the limit, the input token is passed to the next best expert instead.
MoEs have more parameters to load. However, a fraction of them are activated since we only select some experts.
This leads to faster inference. Mixtral 8x7B by MistralAI is one famous LLM that is based on MoE.
Here's the visual again that compares Transformers and MoE!
If you want to learn how to build with LLMs…
…we have already covered a full crash course on building, optimizing, improving, evaluating, and monitoring RAG apps (with implementation).
Start here → RAG crash course (9 parts + 3 hours of read time).
Over to you: Do you like the strategy of multiple experts instead of a single feed-forward network?
Thanks for reading!
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
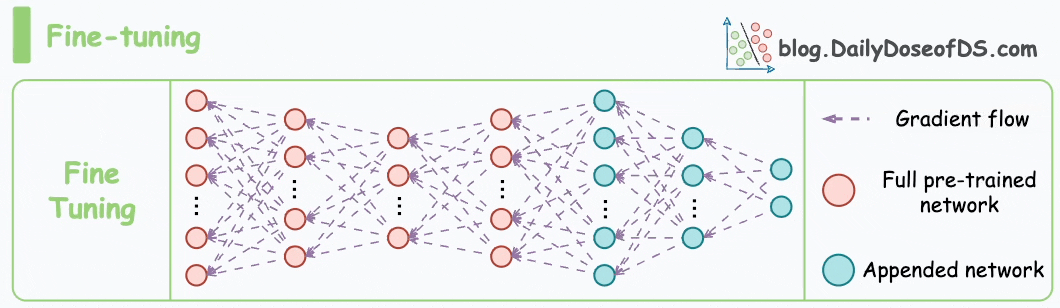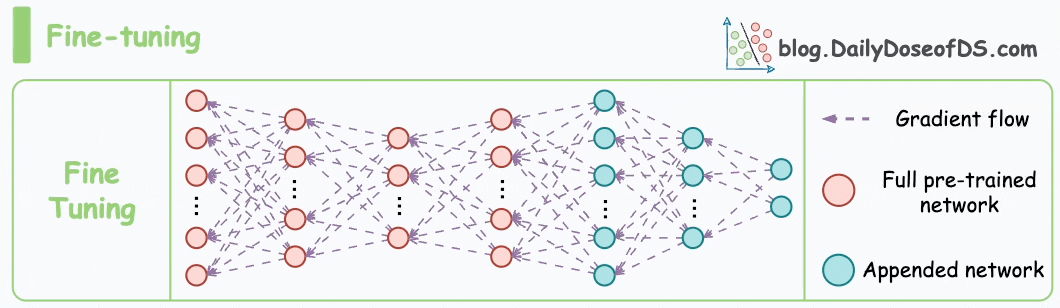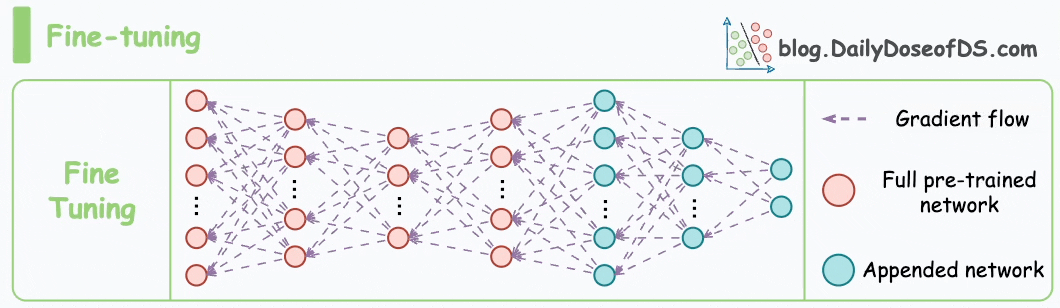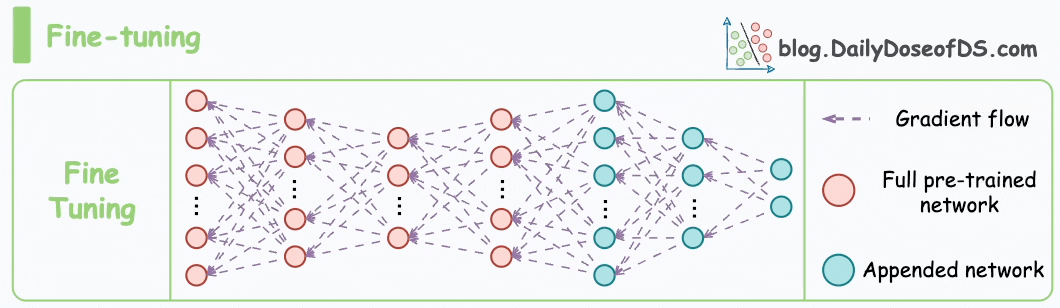
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.