Building Flows in Agentic Systems (Part A)
AI Agents Crash Course—Part 3 (with implementation).
Introduction
In the previous parts of this crash course, we explored the foundational elements of building agentic systems:
- In Part 1, we introduced the concept of AI agents, discussing their roles, goals, and how they can autonomously perform tasks.
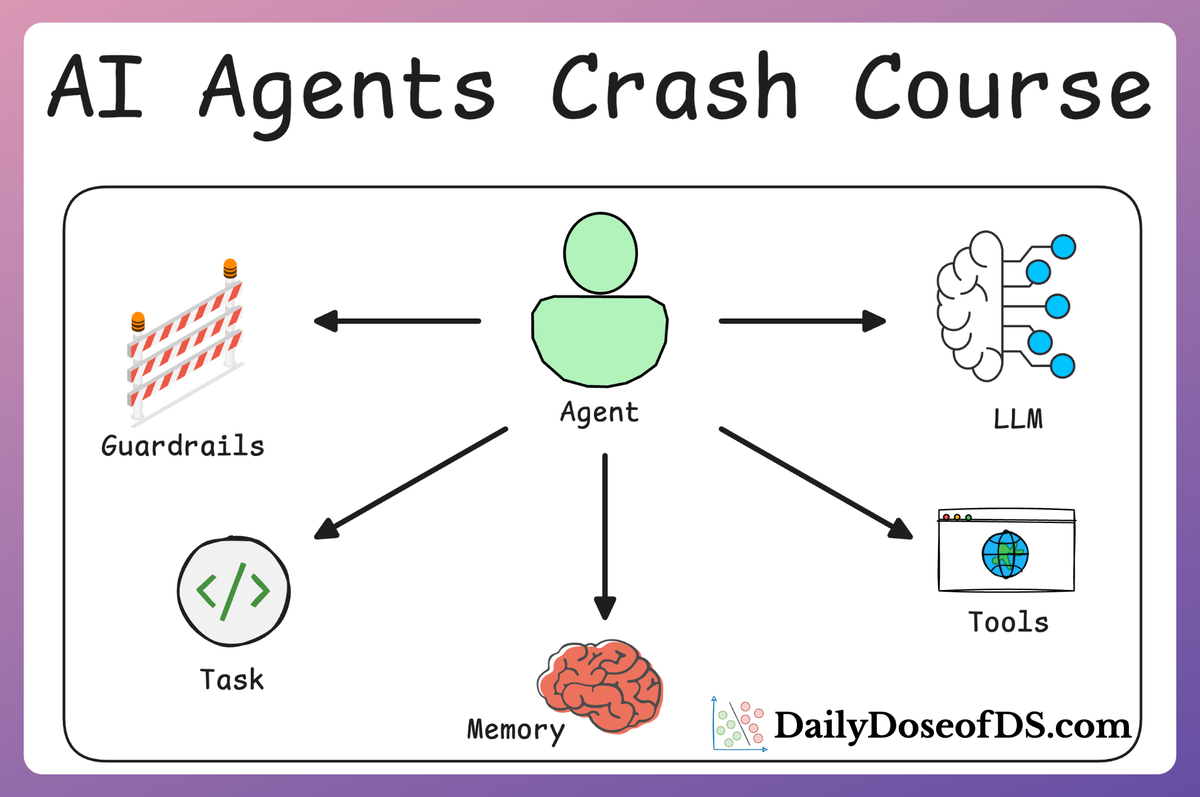
- In Part 2, we dived into structuring AI workflows by integrating custom tools for better multi-agent collaboration. This included building modular Crews and implementing structured outputs to enhance efficiency and scalability.
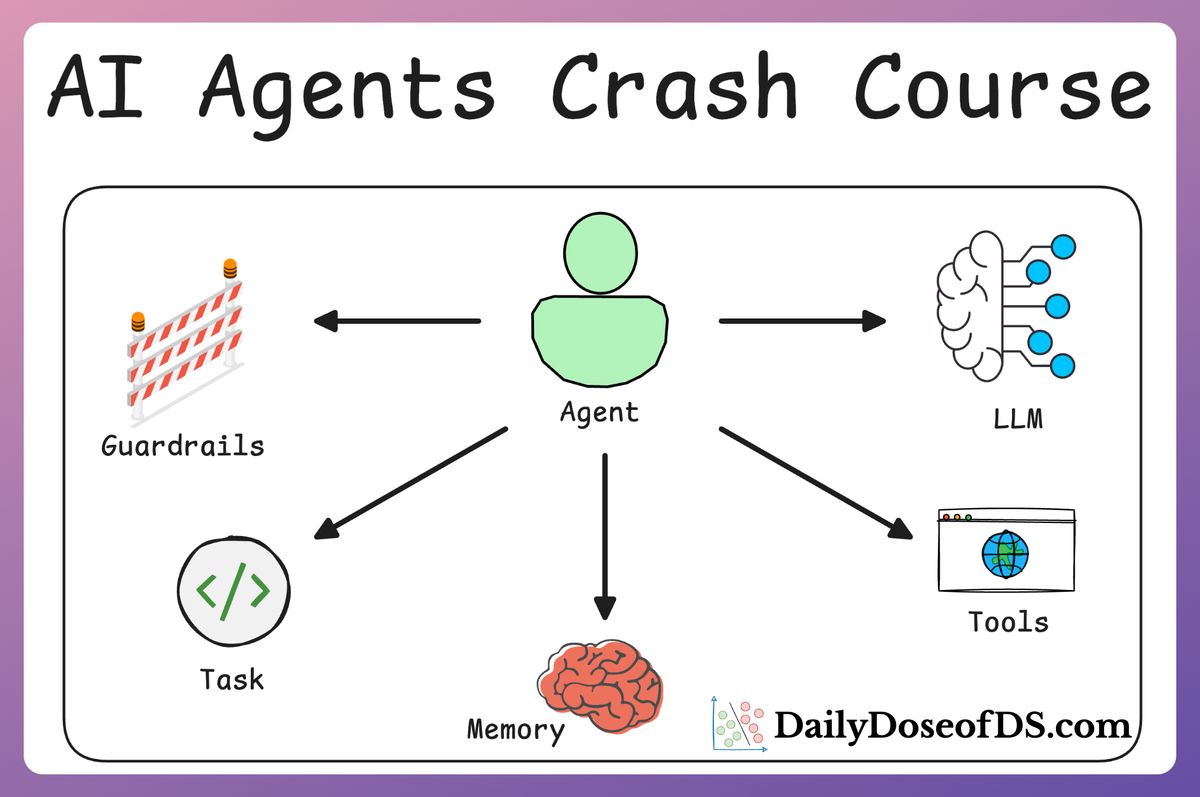
As we progress to Part 3, our focus shifts to CrewAI Flows—a powerful feature designed to streamline the creation and management of AI workflows.
With Flows, you can create structured, event-driven workflows that seamlessly connect multiple tasks, manage state, and control the flow of execution in your AI applications. This allows for the design and implementation of multi-step processes that leverage the full potential of CrewAI's capabilities.
In this part, we will explore how we can use Flows to:
- Bring together multiple Crews and tasks to build complex AI workflows.
- Set up event-driven AI workflows.
- Manage states across the entire AI workflow.
- Incorporate conditional logic and branching to build flexible AI workflows.
And of course, everything will be supported with proper implementations like we always do!
If you haven't read Part 1 and Part 2 yet, it is highly recommended to do so before moving ahead.
Why Flows?
As we learned in the previous parts, in traditional software development, workflows are meticulously crafted with explicit, deterministic logic to ensure predictable outcomes.
- IF A happens → Do X
- IF B happens → Do Y
- Else → Do Z
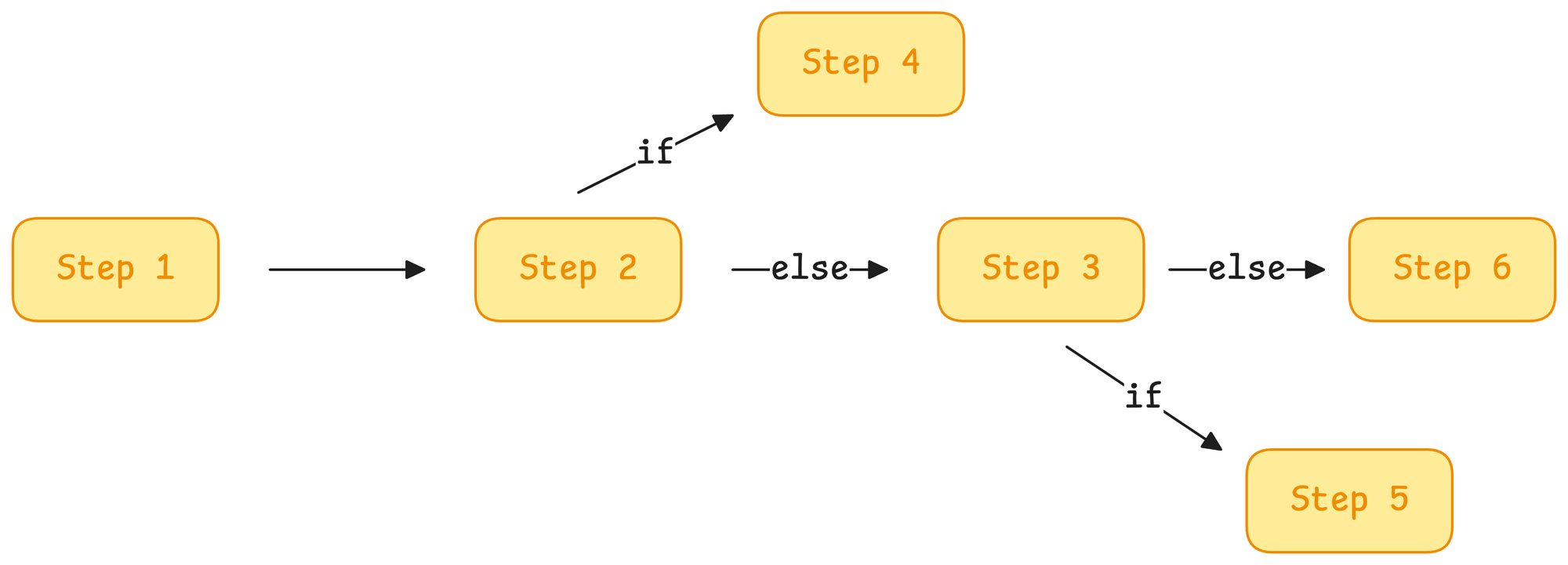
Of course, there's nothing wrong and this approach excels in scenarios where tasks are well-defined and require precise control.
However, as we integrate Large Language Models (LLMs) into our systems, we encounter tasks that benefit from the LLMs' ability to reason, interpret context, and handle ambiguity—capabilities that deterministic logic alone cannot provide.
For instance, consider a customer support system.
Traditional logic can efficiently route queries based on keywords, but understanding nuanced customer sentiments or providing personalized responses requires the interpretative capabilities of LLMs.
Nonetheless, allowing LLMs to operate without constraints can lead to unpredictable behaviour at times.
Therefore, it's crucial to balance structured workflows with AI-driven autonomy.
Flows help us do that.
Essentially, Flows enable developers to design workflows that seamlessly integrate deterministic processes with AI's adaptive reasoning.
By structuring interactions between traditional code and LLMs, Flows ensure that while AI agents have the autonomy to interpret and respond to complex inputs, they do so within a controlled and predictable framework.
In essence, Flows provide the infrastructure to harness the strengths of both traditional software logic and AI autonomy, creating cohesive systems that are both reliable and intelligent.
It will become easier to understand them once we get into the implementation so let's jump to that now!
Implementing Flows
Throughout this crash course, we shall be using CrewAI, an open-source framework that makes it seamless to orchestrate role-playing, set goals, integrate tools, bring any of the popular LLMs, etc., to build autonomous AI agents.

To highlight more, CrewAI is a standalone independent framework without any dependencies on Langchain or other agent frameworks.
Let's dive in!
Setup
To get started, install CrewAI as follows:
Like the RAG crash course, we shall be using Ollama to serve LLMs locally. That said, CrewAI integrates with several LLM providers like:
- OpenAI
- Gemini
- Groq
- Azure
- Fireworks AI
- Cerebras
- SambaNova
- and many more.
To set up OpenAI, create a .env file in the current directory and specify your OpenAI API key as follows:
Also, here's a step-by-step guide on using Ollama:
- Go to Ollama.com, select your operating system, and follow the instructions.
- If you are using Linux, you can run the following command:
- Ollama supports a bunch of models that are also listed in the model library:

Once you've found the model you're looking for, run this command in your terminal:
The above command will download the model locally, so give it some time to complete. But once it's done, you'll have Llama 3.2 3B running locally, as shown below which depicts Microsoft's Phi-3 served locally through Ollama:
That said, for our demo, we would be running Llama 3.2 1B model instead since it's smaller and will not take much memory:
Done!
Everything is set up now and we can move on to building our Flows.
You can download the code for this particular deep dive below: