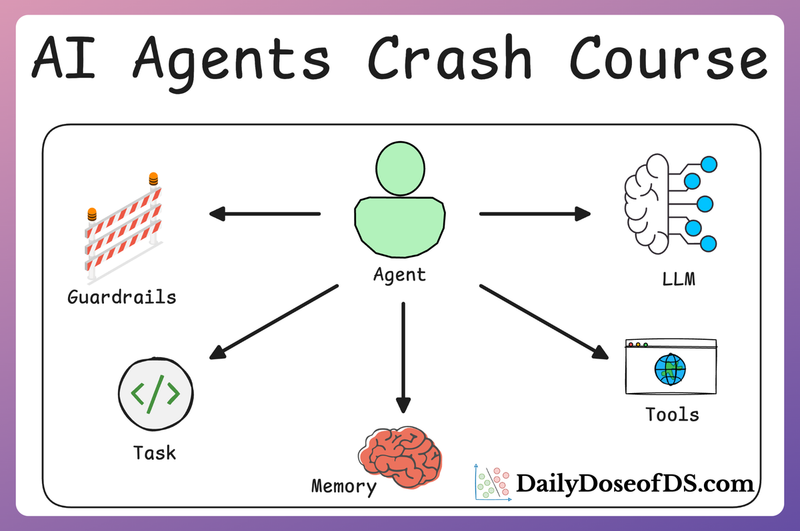
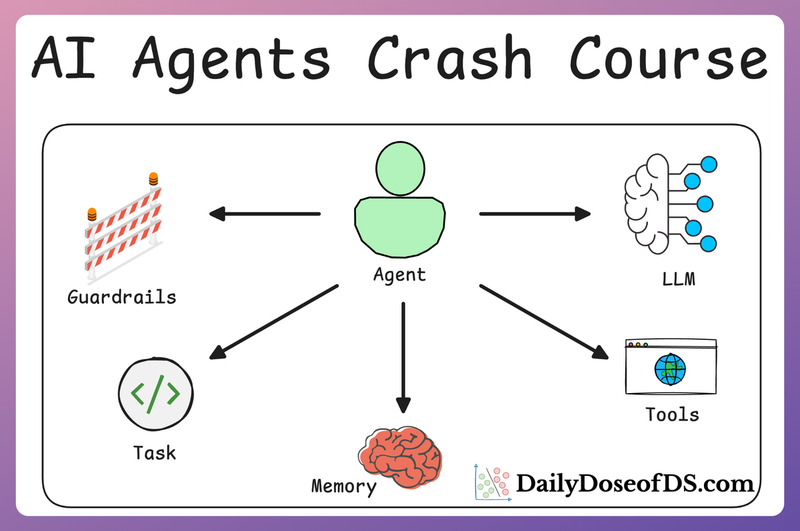
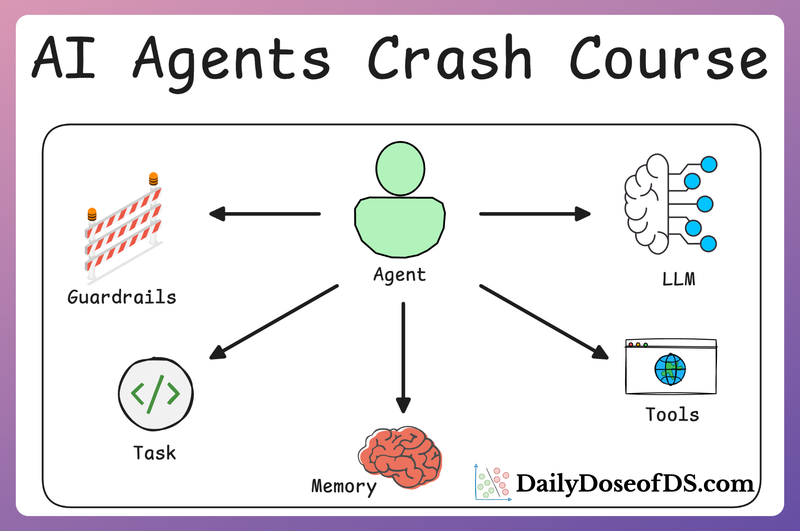
MLOps/LLMOps Course
LLM Inference and Optimization: Fundamentals, Bottlenecks, and Techniques
LLMOps Part 13: Exploring the mechanics of LLM inference, from prefill and decode phases to KV caching, batching, and optimization techniques that improve latency and throughput.