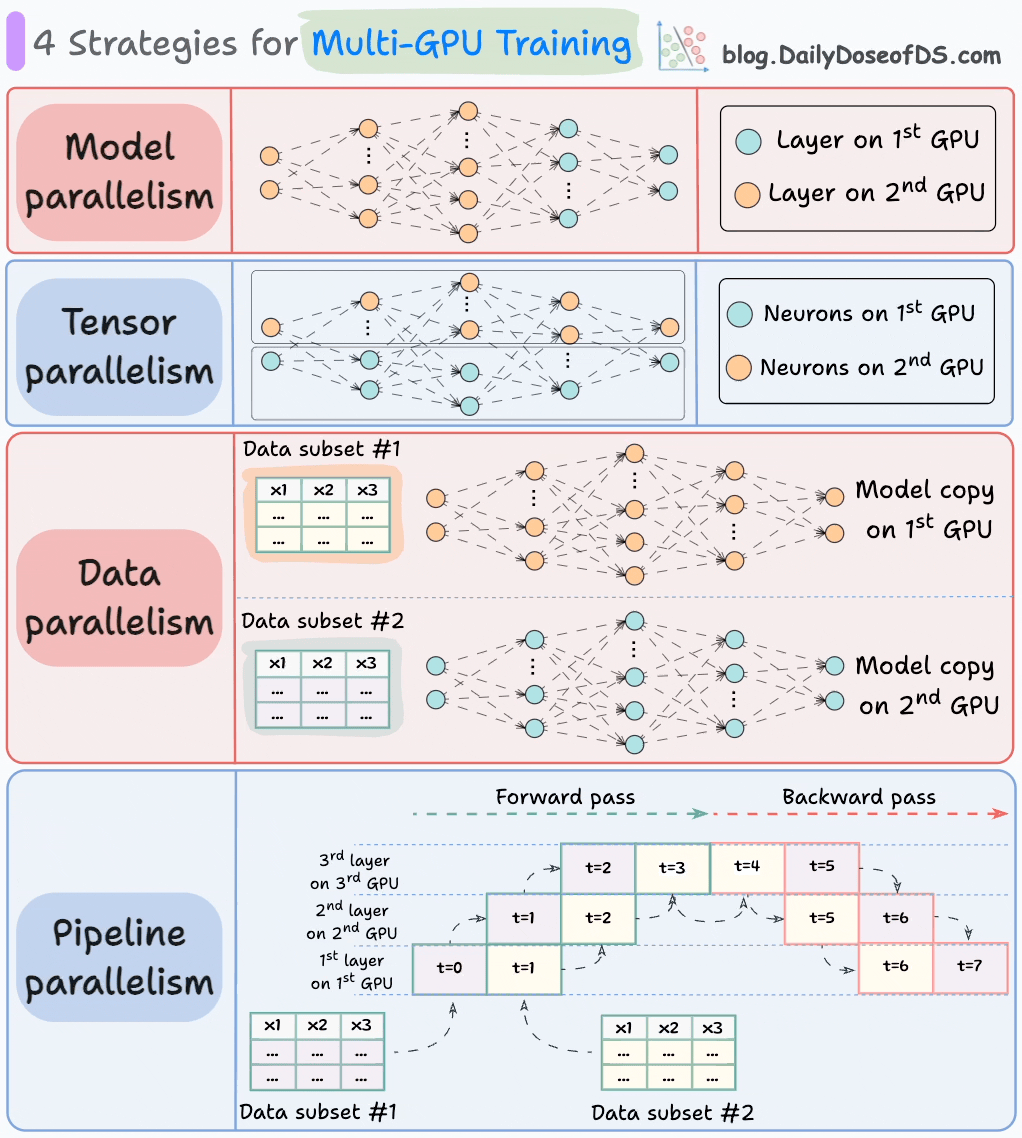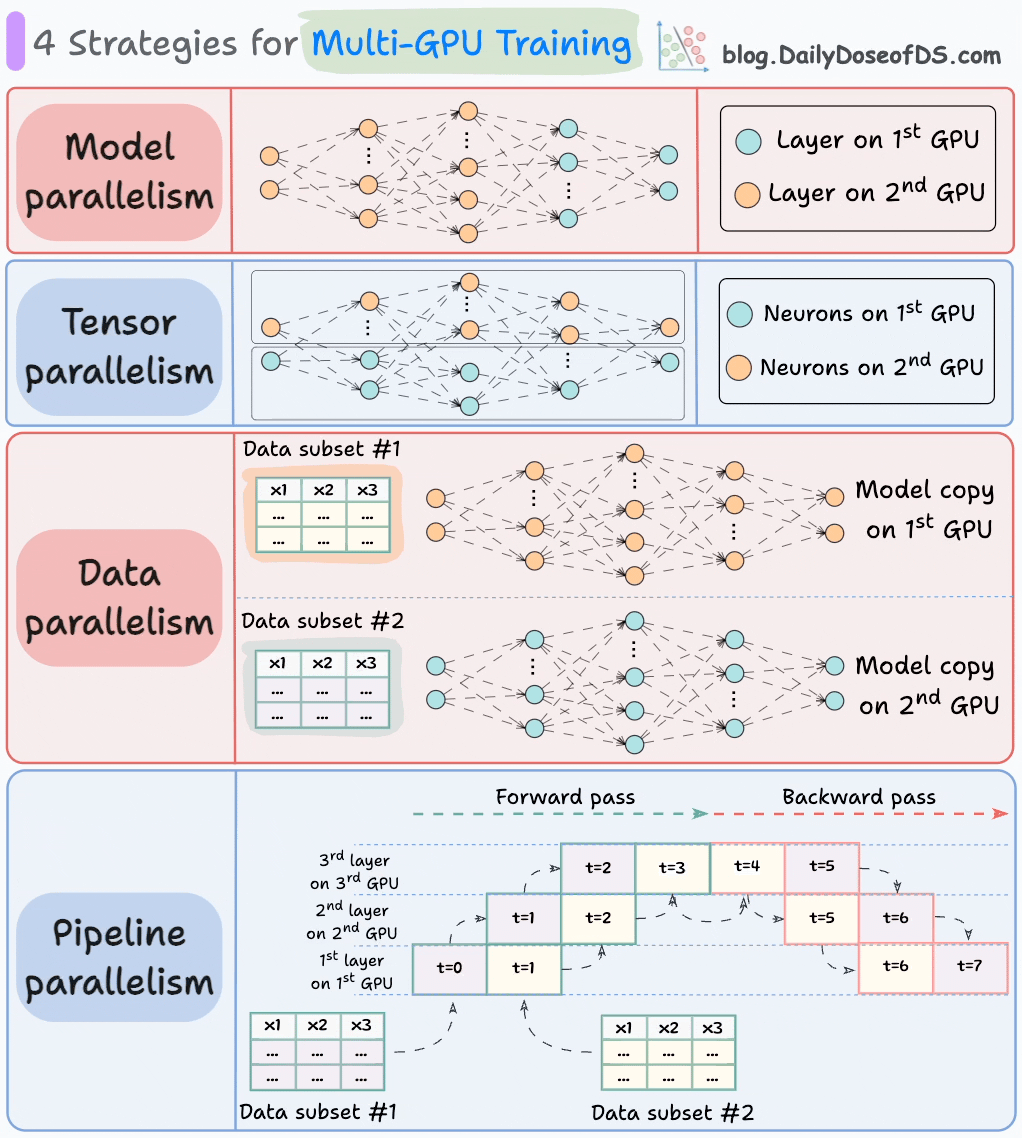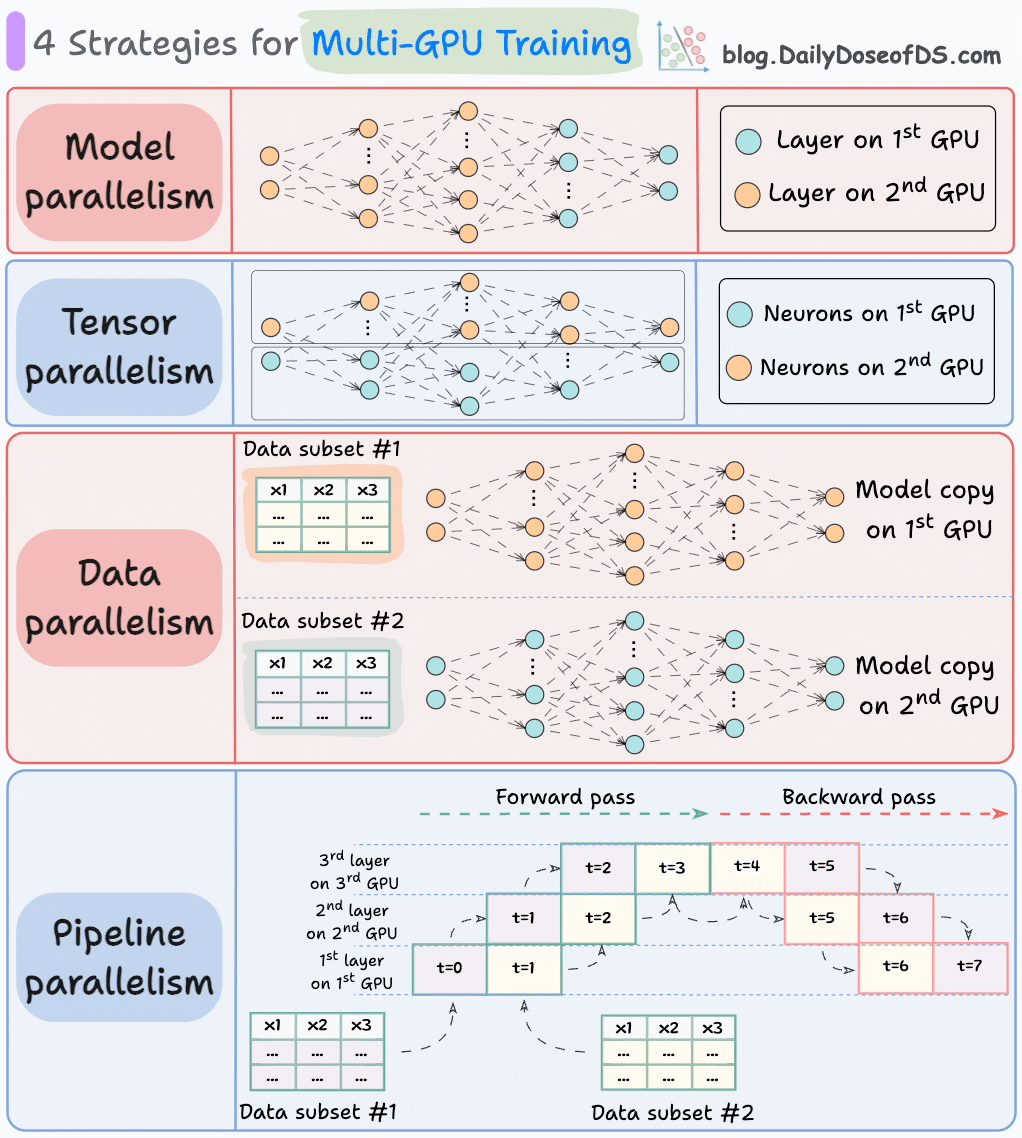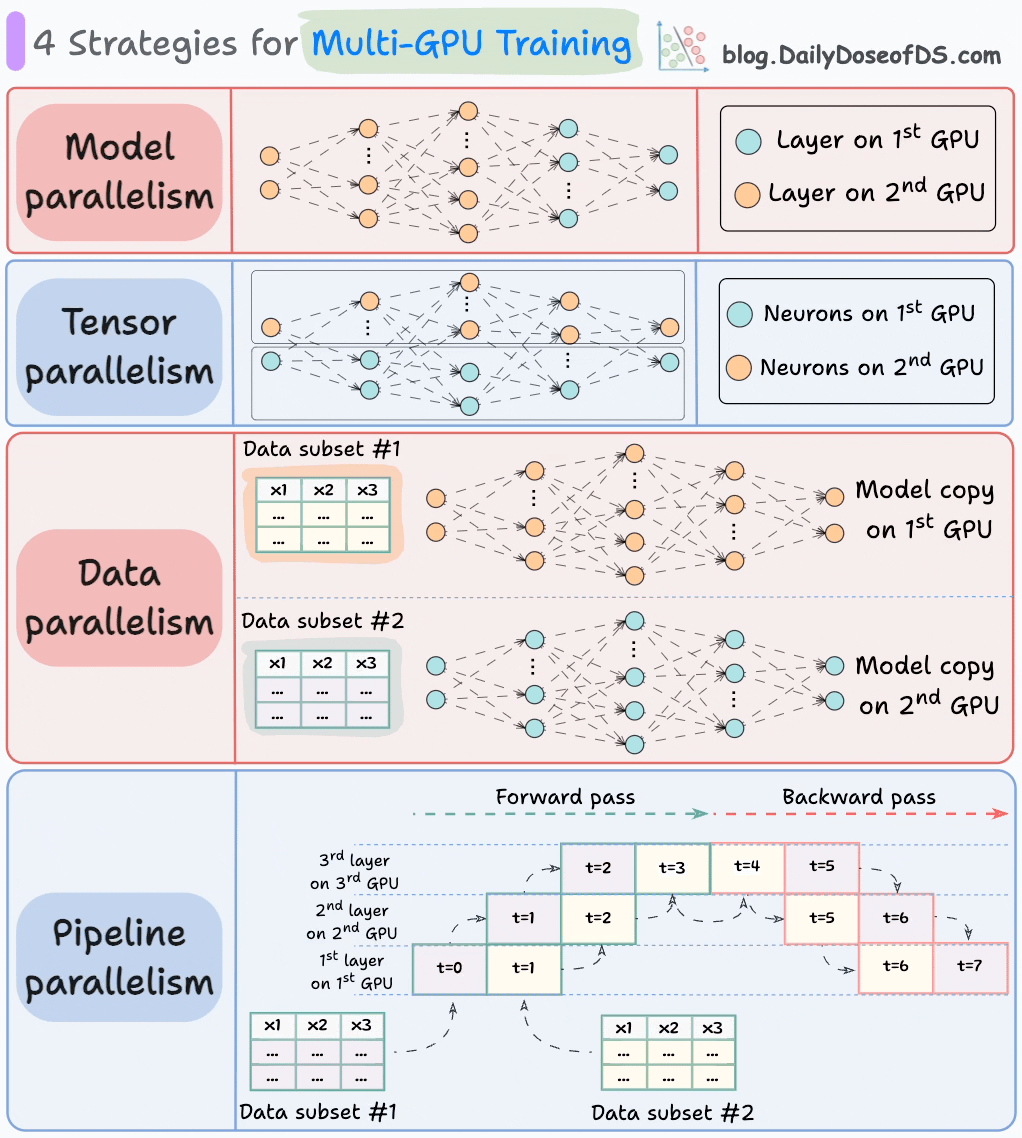
Different parts (or layers) of the model are placed on different GPUs.
Useful for huge models that do not fit on a single GPU.
However, model parallelism also introduces severe bottlenecks as it requires data flow between GPUs when activations from one GPU are transferred to another GPU.
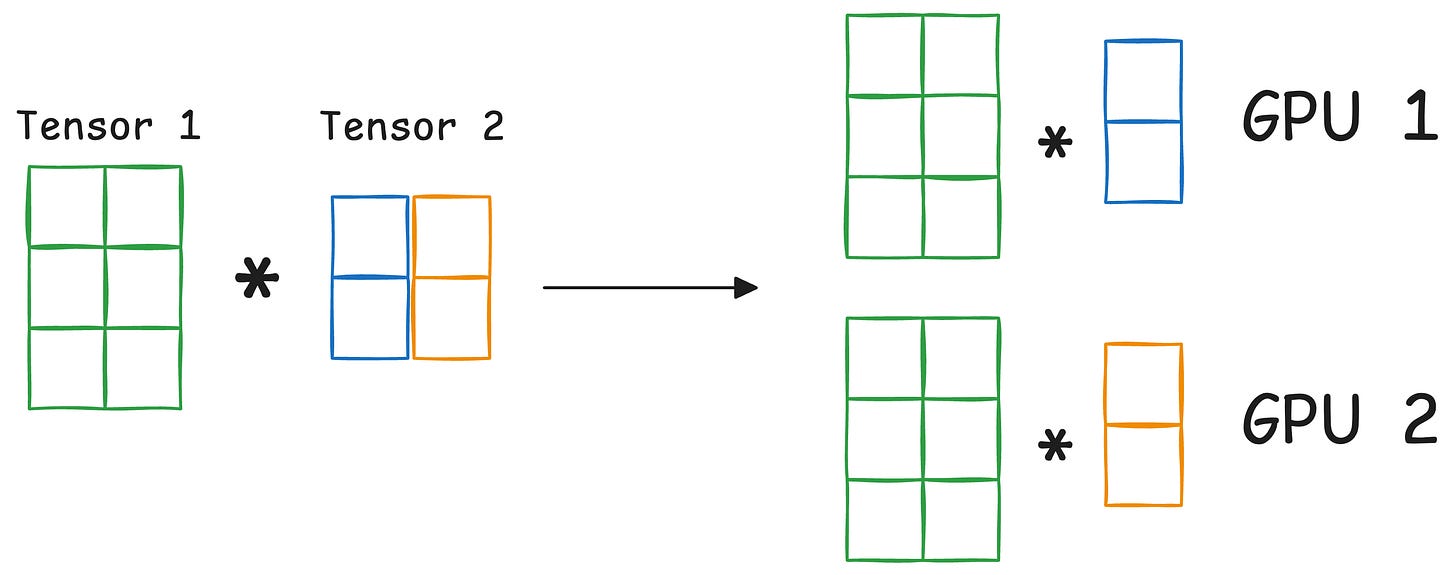
#2) Tensor parallelism
Distributes and processes individual tensor operations across multiple devices or processors.
It is based on the idea that a large tensor operation, such as matrix multiplication, can be divided into smaller tensor operations, and each smaller operation can be executed on a separate device or processor.
Such parallelization strategies are inherently built into standard implementations of PyTorch and other deep learning frameworks, but they become much more pronounced in a distributed setting.
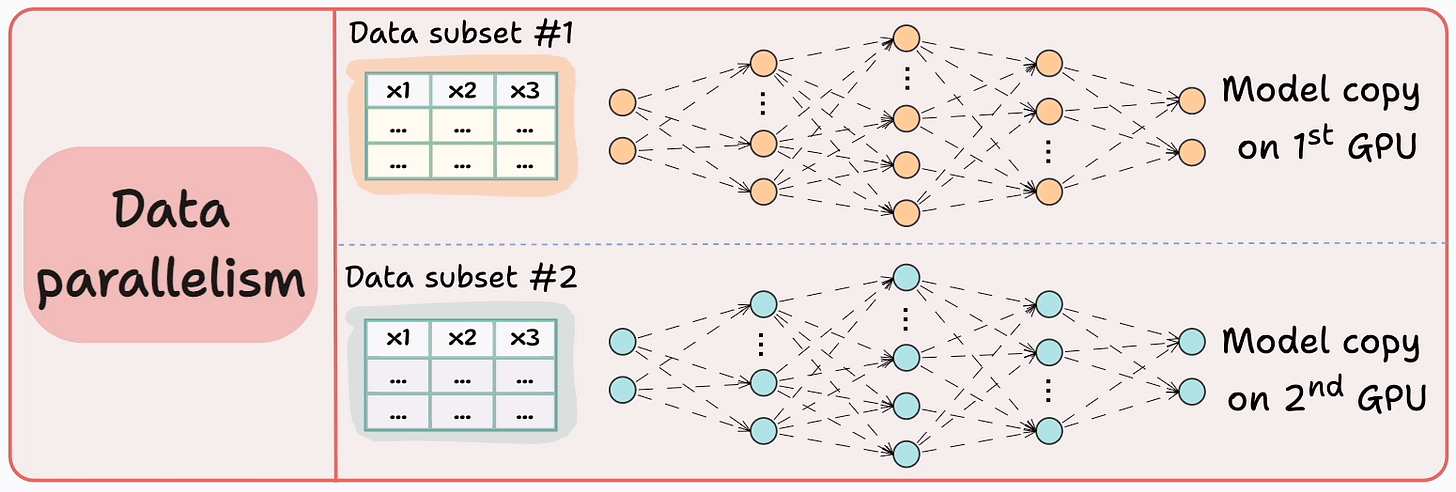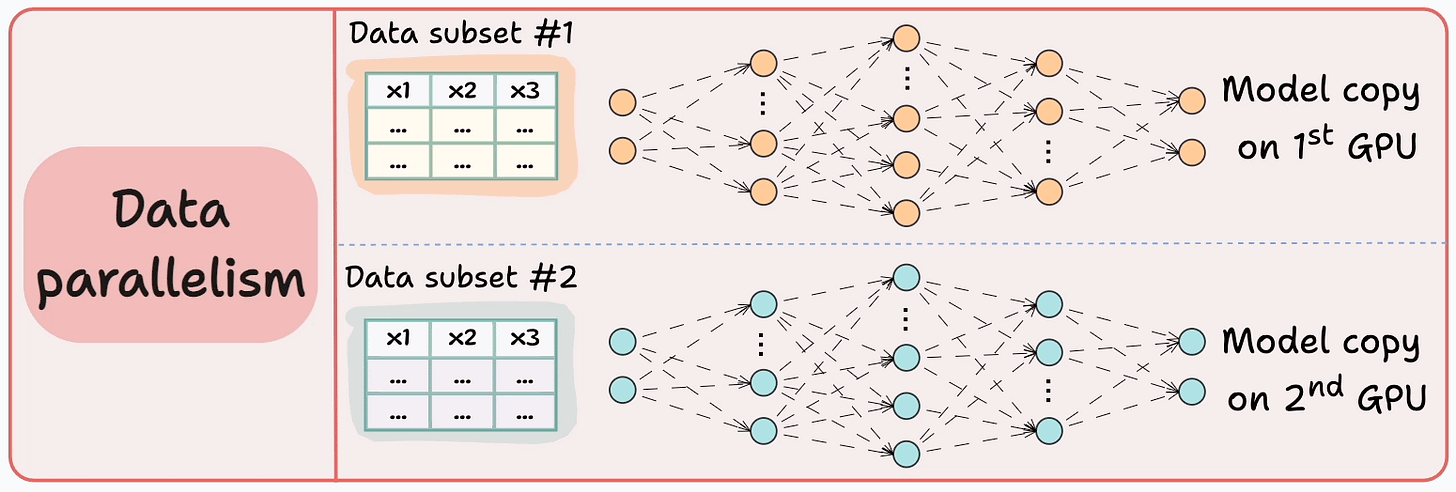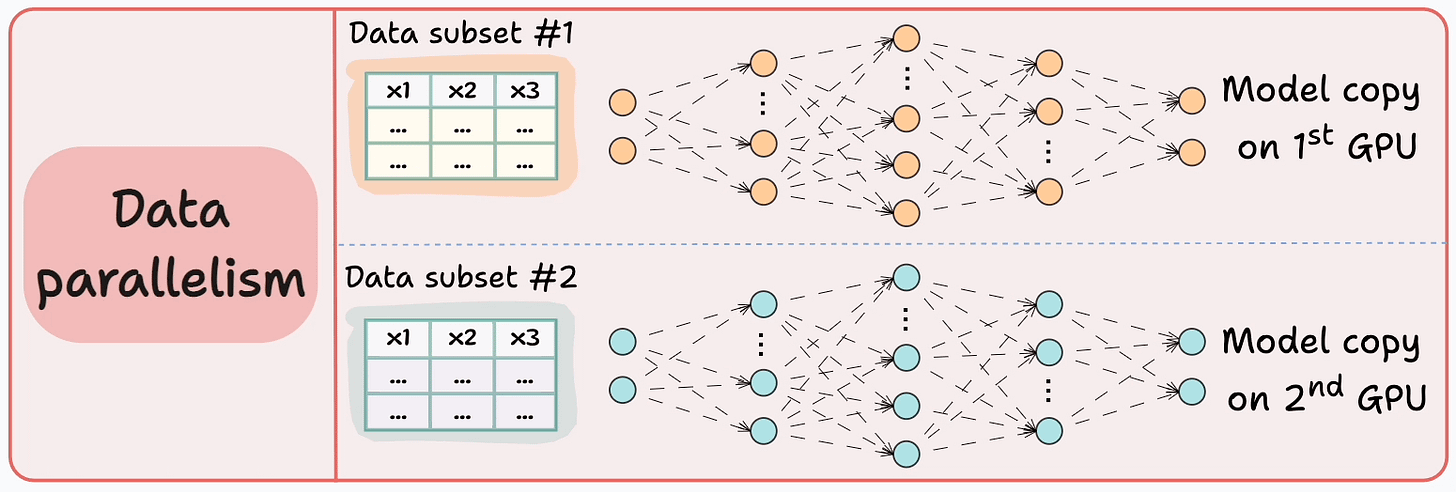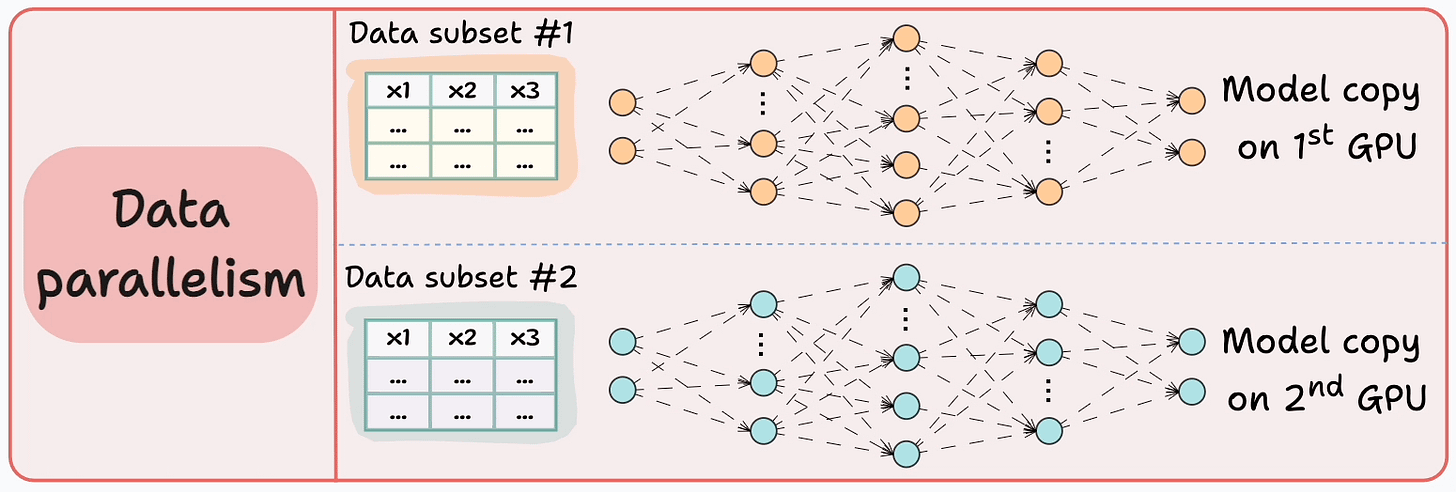
#3) Data parallelism
Replicate the model across all GPUs.
Divide the available data into smaller batches, and each batch is processed by a separate GPU.
The updates (or gradients) from each GPU are then aggregated and used to update the model parameters on every GPU.
#4) Pipeline parallelism
This is often considered a combination of data parallelism and model parallelism.
So the issue with standard model parallelism is that 1st GPU remains idle when data is being propagated through layers available in 2nd GPU:
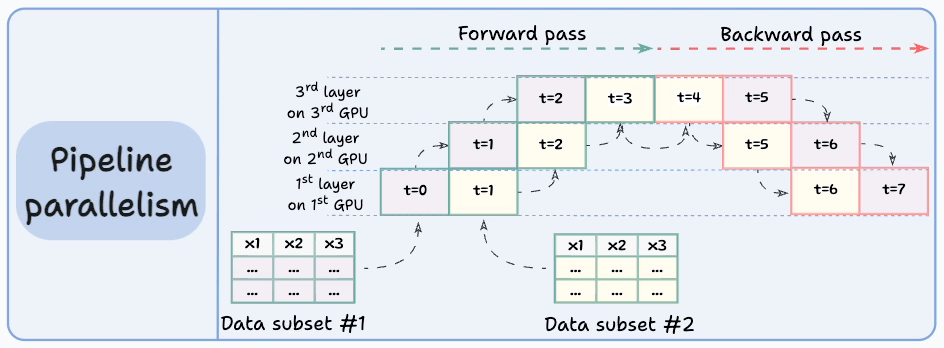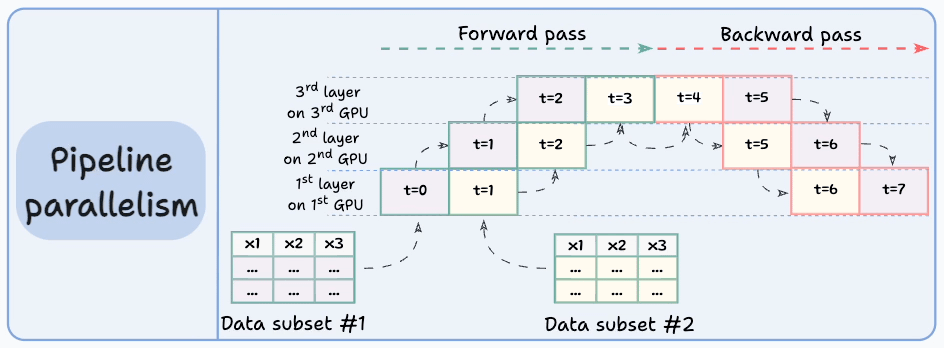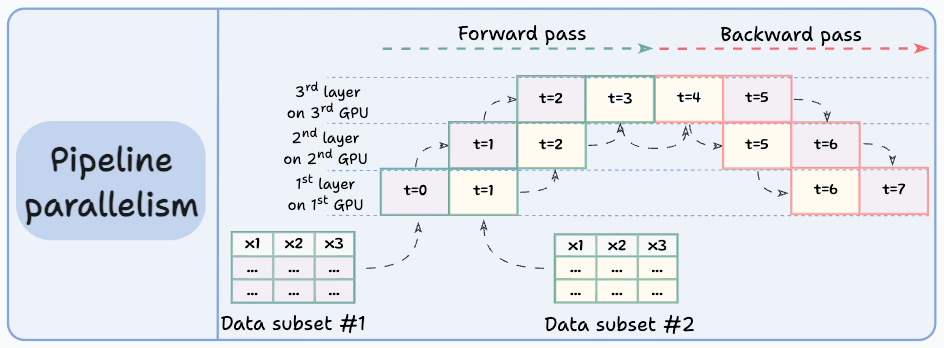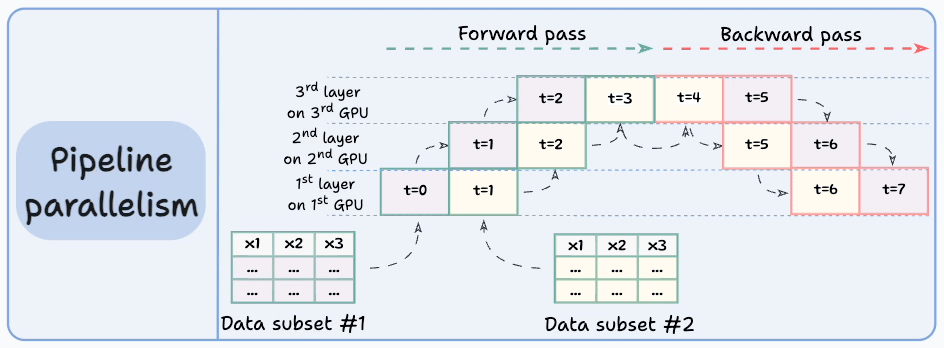
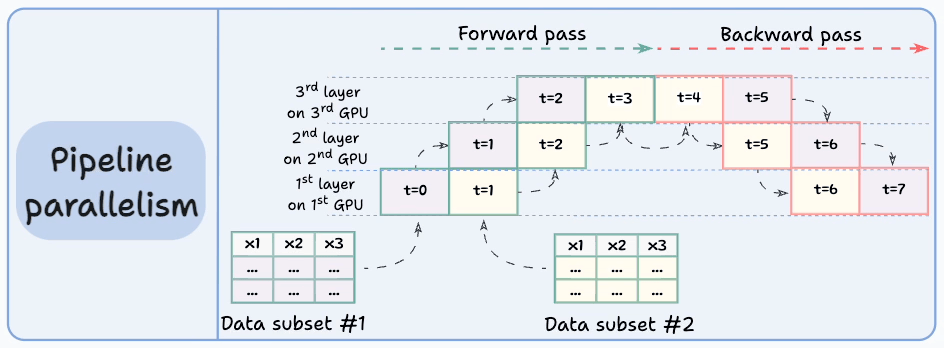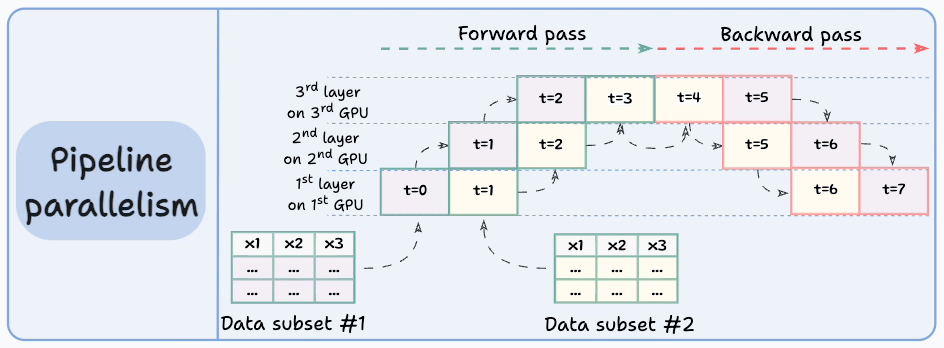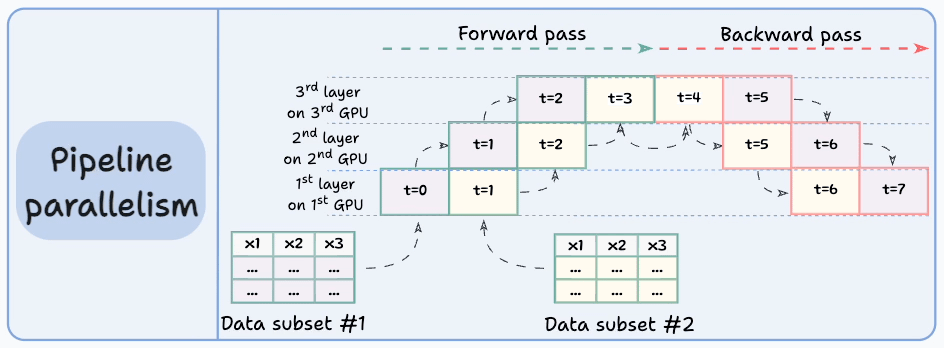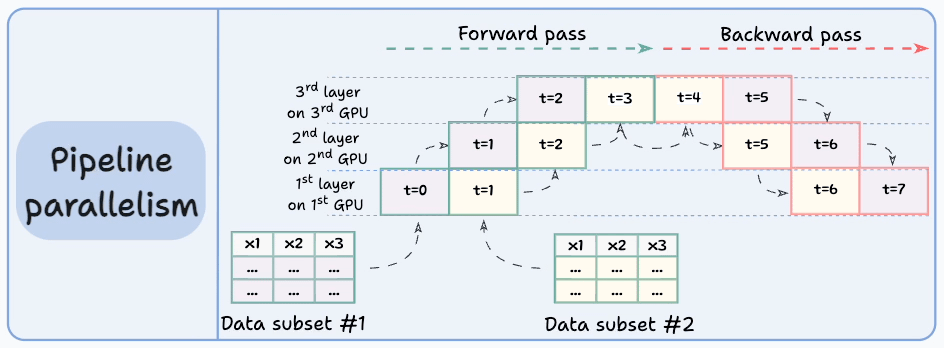
Pipeline parallelism addresses this by loading the next micro-batch of data once the 1st GPU has finished the computations on the 1st micro-batch and transferred activations to layers available in the 2nd GPU. The process looks like this:
1st micro-batch passes through the layers on 1st GPU.
2nd GPU receives activations on 1st micro-batch from 1st GPU.
While the 2nd GPU passes the data through the layers, another micro-batch is loaded on the 1st GPU.
And the process continues.
GPU utilization drastically improves this way. This is evident from the animation below where multi-GPUs are being utilized at the same timestamp (look at t=1, t=2, t=5, and t=6):
Those were four common strategies for multi-GPU training.