Agentic Systems 101: Fundamentals, Building Blocks, and How to Build Them (Part B)
AI Agents Crash Course—Part 2 (with implementation).
Introduction
In Part 1, we explored the fundamentals of Agentic systems:
- We saw how agents specialize in roles, collaborate dynamically, and adapt to real-time tasks, making them highly scalable and effective.
- We built single-agent and multi-agent systems to execute research tasks.
- We integrated tools into our Agents for better utility.
- We defined task dependencies and execution workflows to ensure logical processing.
- We experimented with YAML to decouple configuration from execution for better maintainability.
Now that we’ve covered the fundamentals, it’s time to deepen our understanding by implementing agentic systems as class modules, adding custom tools, handling structured outputs, comparing different execution strategies (sequential vs. hierarchical), and more.
A quick recap
While AI agents are powerful, not every problem requires an agentic approach. Many tasks can be handled effectively with regular prompting or retrieval-augmented generation (RAG) solutions.
However, for problems where autonomy, adaptability, and decision-making are crucial, AI agents provide a structured way to build intelligent, goal-driven systems.
Here are three major motivations for building agentic systems:
1) Beyond RAG
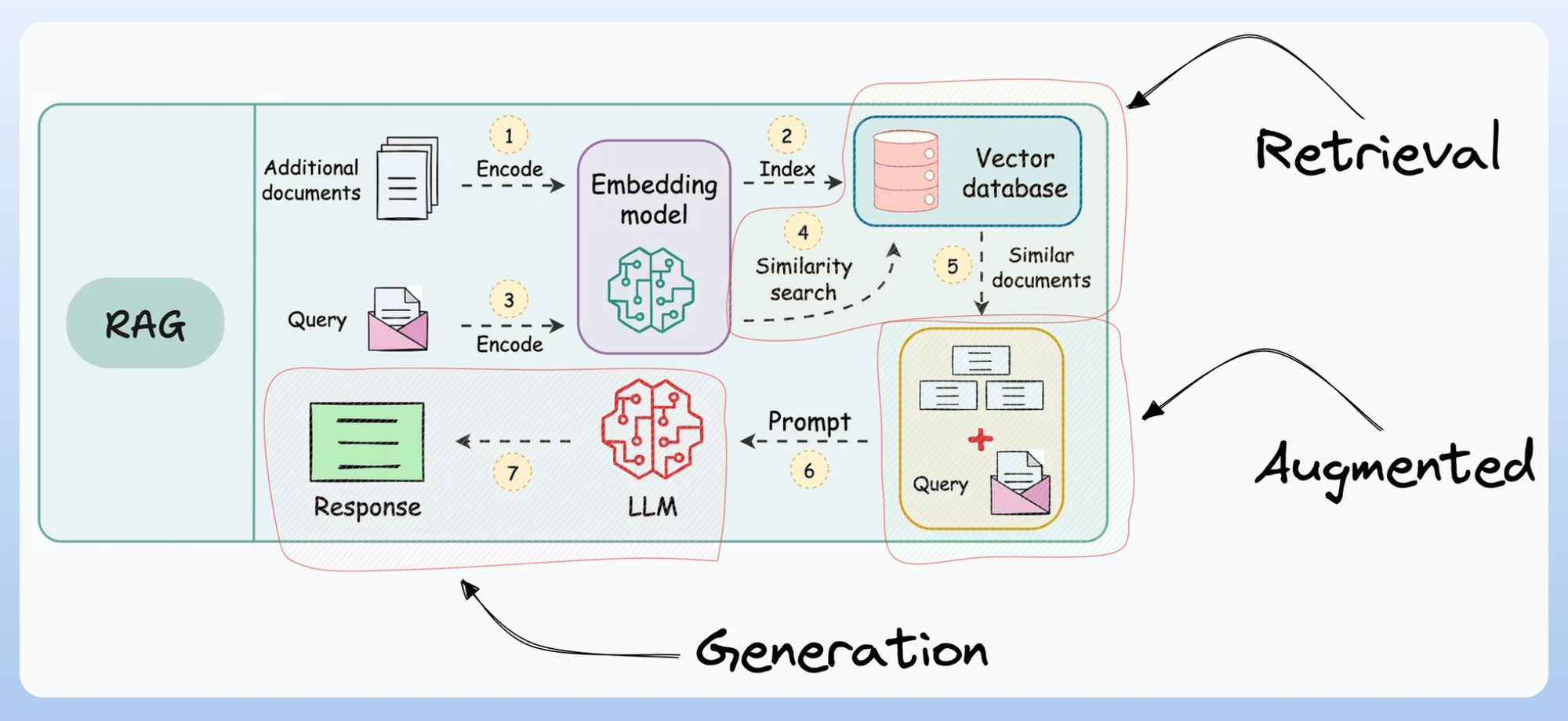
RAG was a major leap forward in how AI systems interact with external knowledge. It allowed models to retrieve relevant context from external sources rather than relying solely on static training data.
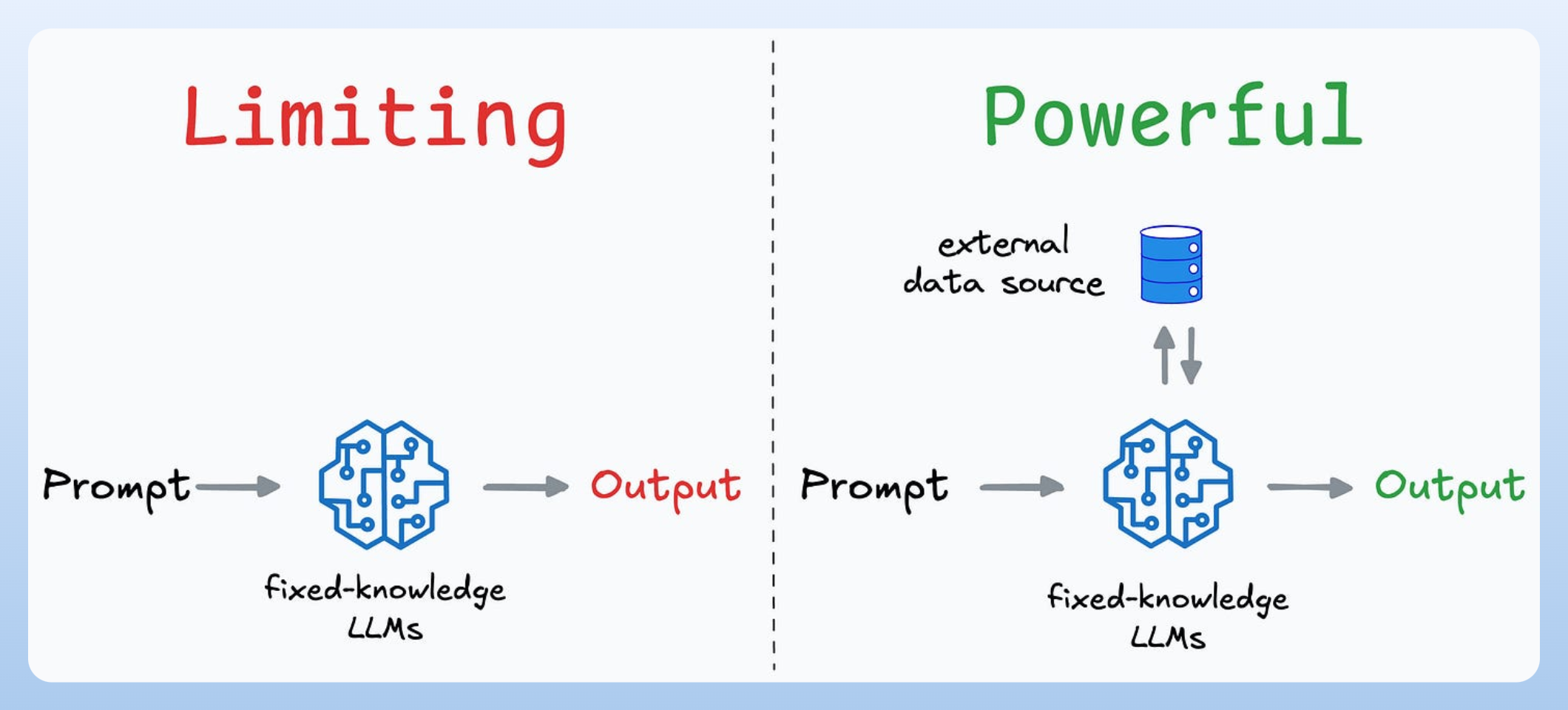
However, most RAG implementations follow predefined steps—a programmer defines:
- Where to search (vector databases, documents, APIs)
- How to retrieve data (retrieval logic)
- How to construct the final response
This is not a limitation per se, but it does limit autonomy—the model doesn’t dynamically figure out what to retrieve or how to refine queries.
Agents take RAG a step further by enabling:
- Intelligent data retrieval—Agents decide where to search based on context.
- Context-aware filtering—They refine retrieved results before presenting them.
- Actionable decision-making—They analyze and take action based on the retrieved information.
2) Beyond traditional software development
Traditional software is rule-based—developers hardcode every condition:
- IF A happens → Do X
- IF B happens → Do Y
- Else → Do Z
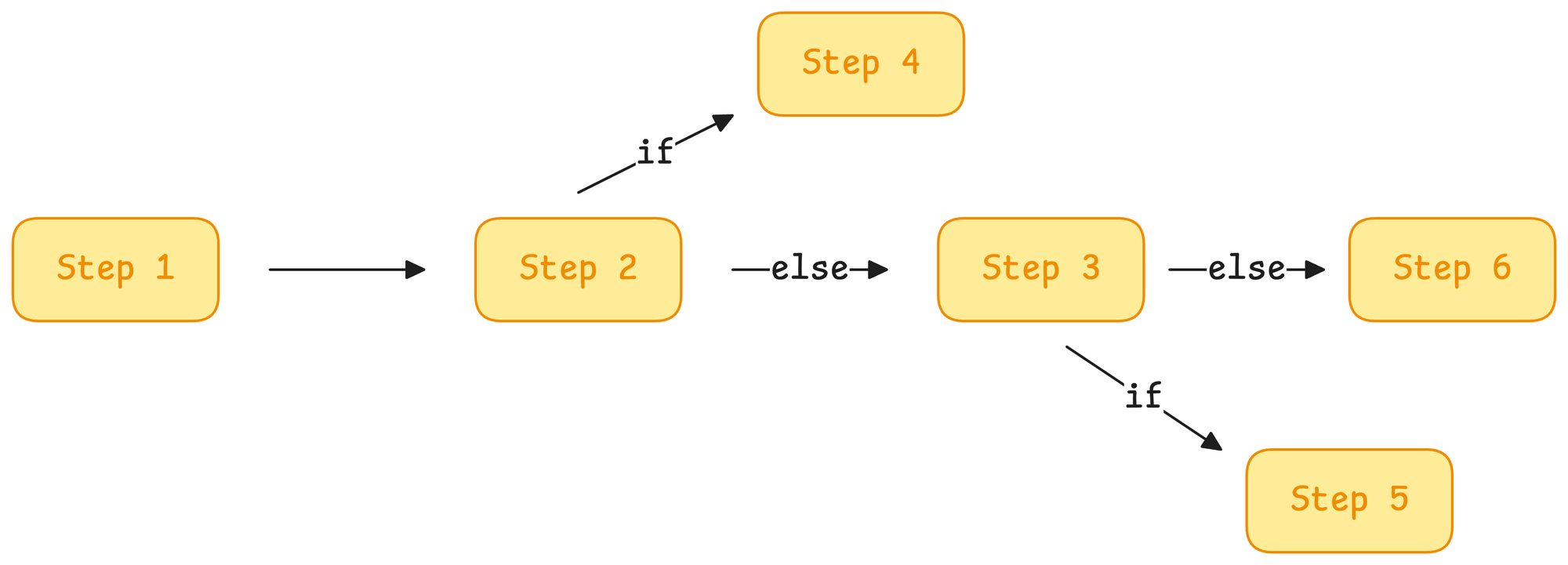
This works for well-defined processes but struggles with ambiguity and new, unseen scenarios.
AI agents break this rigidity by:

- Handling uncertain and dynamic environments (e.g., customer support, real-time analysis).
- Learning from interactions rather than following fixed rules.
- Using multiple modalities (text, images, numbers, etc.) in reasoning.
Due to the cognitive capabilities of LLMs, instead of writing hundreds of if-else conditions, AI agents learn and adapt their workflows in real-time.
3) Beyond human-interaction
One of the biggest challenges in AI-driven workflows is the need for constant human supervision. Traditional AI models—like ChatGPT—are reactive, meaning:
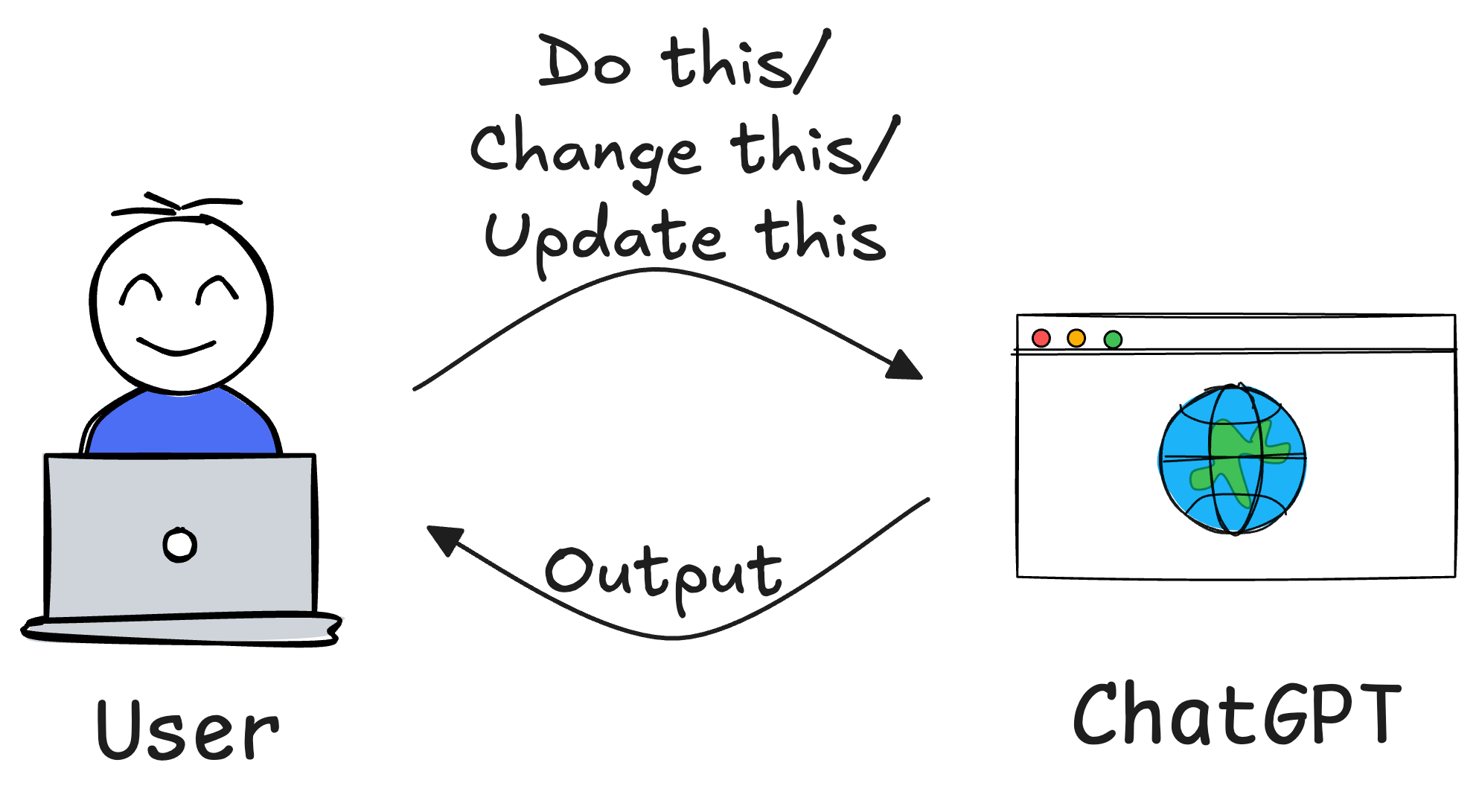
- You provide a query → Model generates a response.
- You review the response → Realize it needs refining.
- You tweak the query → Run the model again.
- Repeat until the output is satisfactory.
This cycle requires constant human intervention.
AI agents, however, can autonomously break down complex tasks into sub-tasks and execute them step by step without supervision.
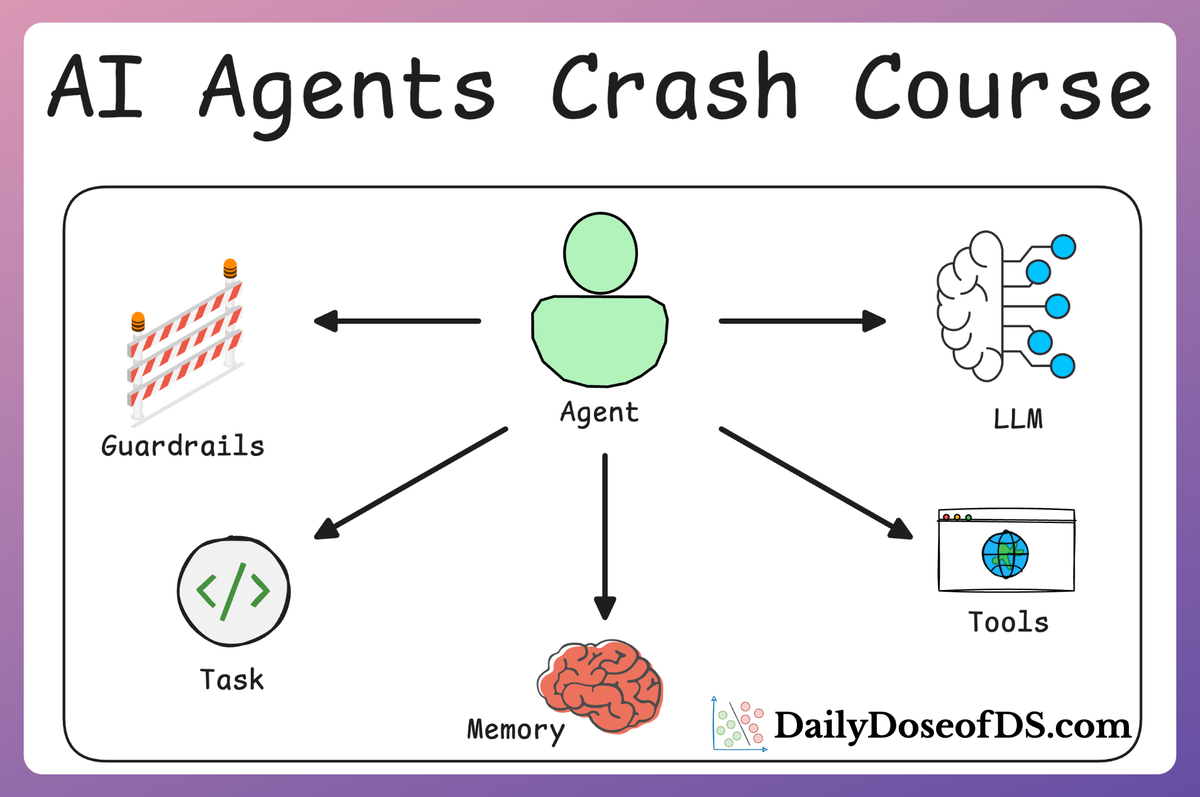
Building Blocks of AI Agents
AI agents are designed to reason, plan, and take action autonomously. However, to be effective, they must be built with certain key principles in mind.
There are six essential building blocks that make AI agents more reliable, intelligent, and useful in real-world applications:
- Role-playing
- Focus
- Tools
- Cooperation
- Guardrails
- Memory
We won't cover them in detail once again since we have already done that in Part 1. If you haven't read it yet, we highly recommend doing so before reading further:
Let's dive into the implementation now.
Building Agentic systems
Throughout this crash course, we shall be using CrewAI, an open-source framework that makes it seamless to orchestrate role-playing, set goals, integrate tools, bring any of the popular LLMs, etc., to build autonomous AI agents.

To highlight more, CrewAI is a standalone independent framework without any dependencies on Langchain or other agent frameworks.
Let's dive in!
Setup
To get started, install CrewAI as follows:
Like the RAG crash course, we shall be using Ollama to serve LLMs locally. That said, CrewAI integrates with several LLM providers like:
- OpenAI
- Gemini
- Groq
- Azure
- Fireworks AI
- Cerebras
- SambaNova
- and many more.
To set up OpenAI, create a .env file in the current directory and specify your OpenAI API key as follows:
Also, here's a step-by-step guide on using Ollama:
- Go to Ollama.com, select your operating system, and follow the instructions.
- If you are using Linux, you can run the following command:
- Ollama supports a bunch of models that are also listed in the model library:

Once you've found the model you're looking for, run this command in your terminal:
The above command will download the model locally, so give it some time to complete. But once it's done, you'll have Llama 3.2 3B running locally, as shown below which depicts Microsoft's Phi-3 served locally through Ollama:
That said, for our demo, we would be running Llama 3.2 1B model instead since it's smaller and will not take much memory:
Done!
Everything is set up now and we can move on to building our agents.