Pandas
15 Pandas ↔ Polars ↔ SQL ↔ PySpark Translations
Become a Quadrilingual Data Scientist.

Avi Chawla
Become a Quadrilingual Data Scientist.
I created the following visual, which depicts the 15 most common tabular operations in Pandas and their corresponding translations in SQL, Polars, and PySpark.
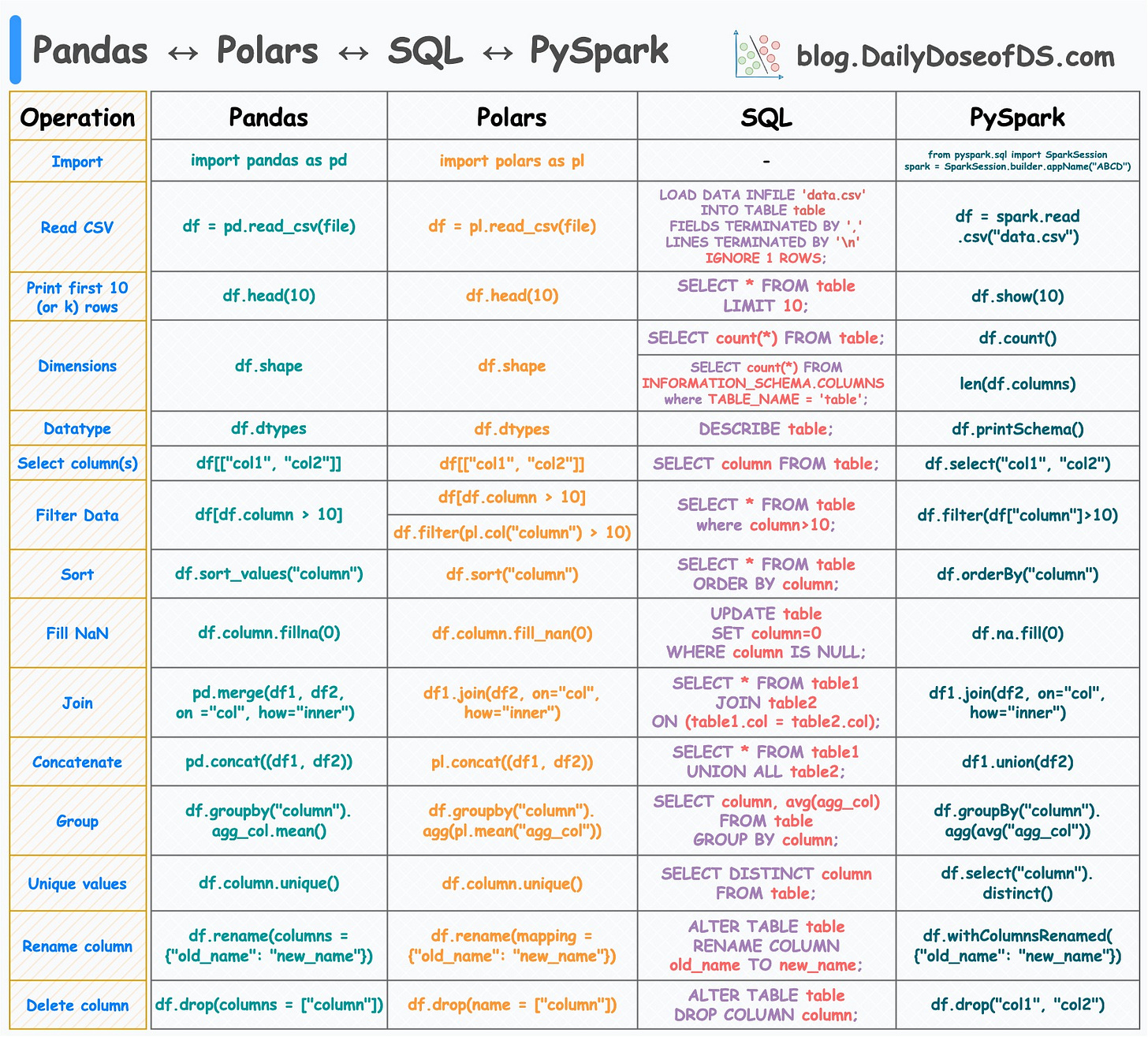
While the motivation for Pandas and SQL is clear and well-known, let me tell you why you should care about Polars and PySpark.
Pandas has many limitations, which Polars addresses, such as:
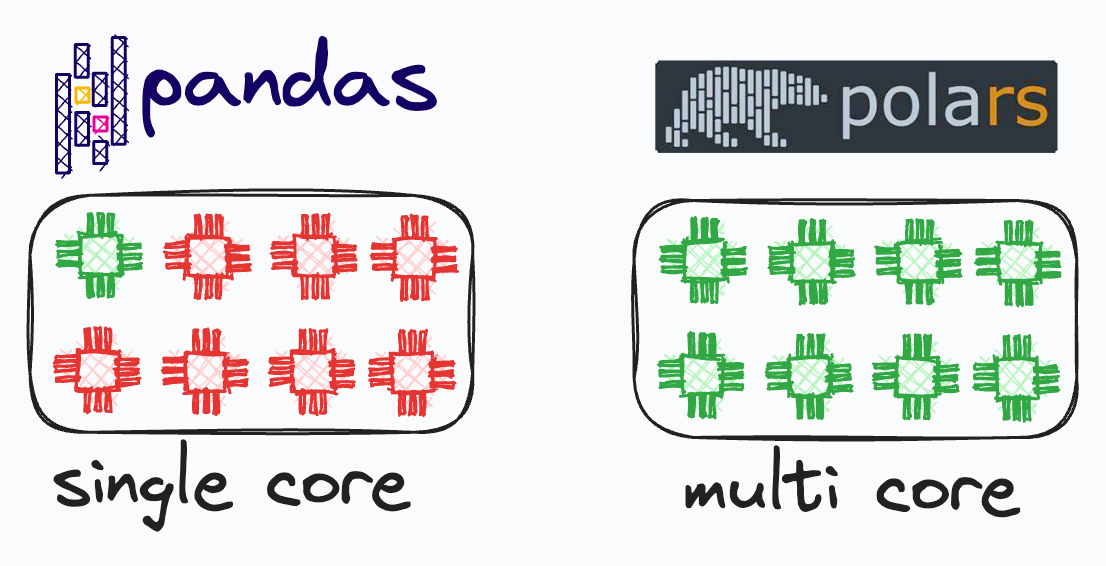
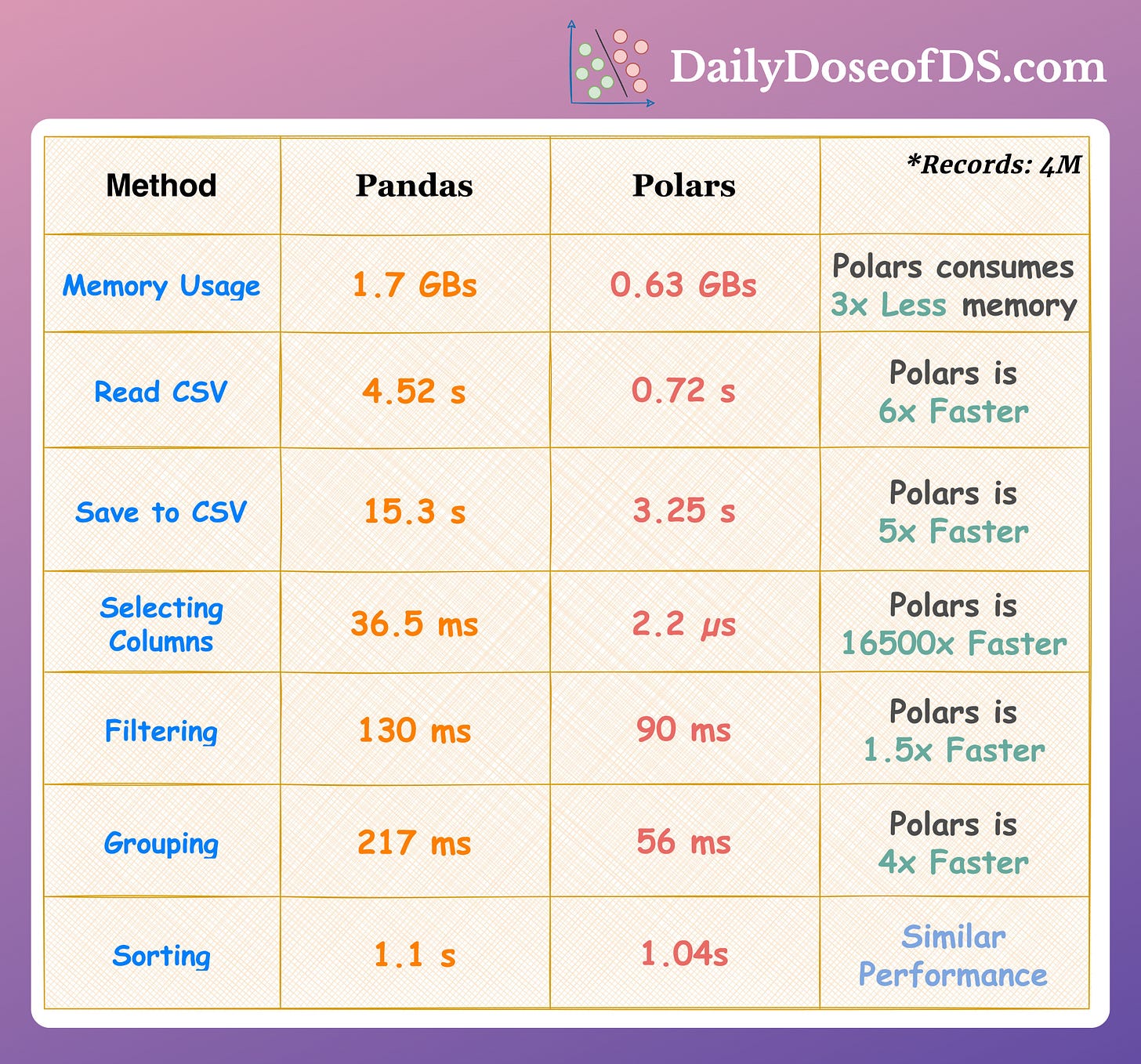
In fact, if we look at the run-time comparison on some common operations, it’s clear that Polars is much more efficient than Pandas:
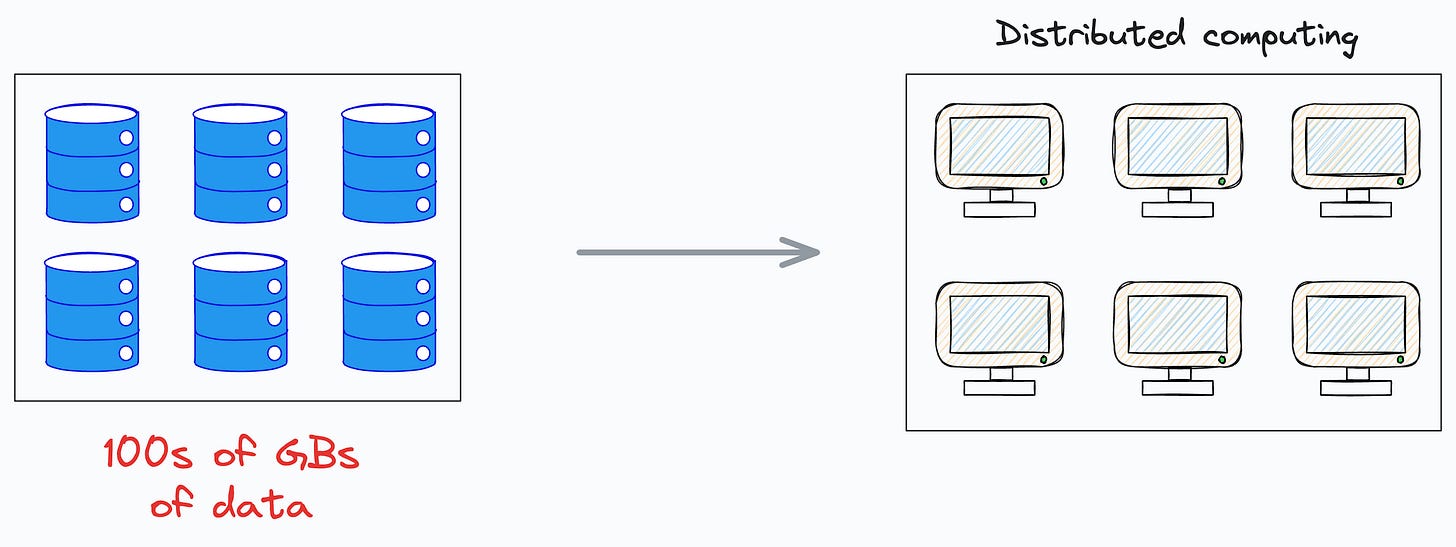
While tabular data space is mainly dominated by Pandas and Sklearn, one can hardly expect any benefit from them beyond some GBs of data due to their single-node processing.
A more practical solution is to use distributed computing instead — a framework that disperses the data across many small computers.
Spark is among the best technologies used to quickly and efficiently analyze, process, and train models on big datasets.
That is why most data science roles at big tech demand proficiency in Spark. It’s that important.
We covered this in detail in a recent deep dive as well: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
👉 Over to you: What are some other faster alternatives to Pandas that you are aware of?
Thanks for reading!