Building a Full-Fledged MCP Workflow using Tools, Resources, and Prompts
MCP Part 4: An in-depth exploration of MCP resources and prompts, followed by a hands-on demonstration of an MCP server utilizing tools, resources, and prompts for job search and analysis.
Recap
Before we dive into Part 4 of the MCP crash course, let’s briefly recap what we covered in the previous part of this course.
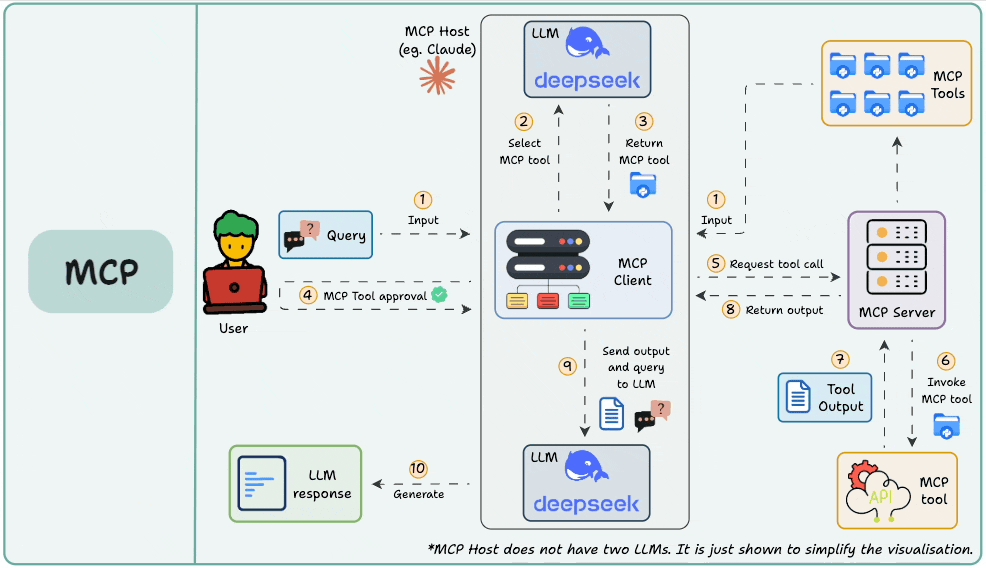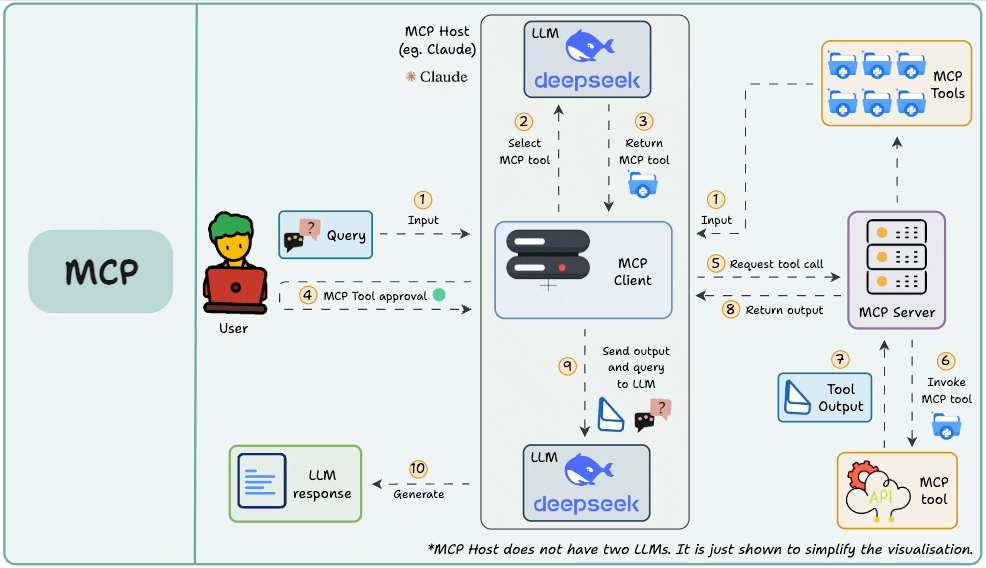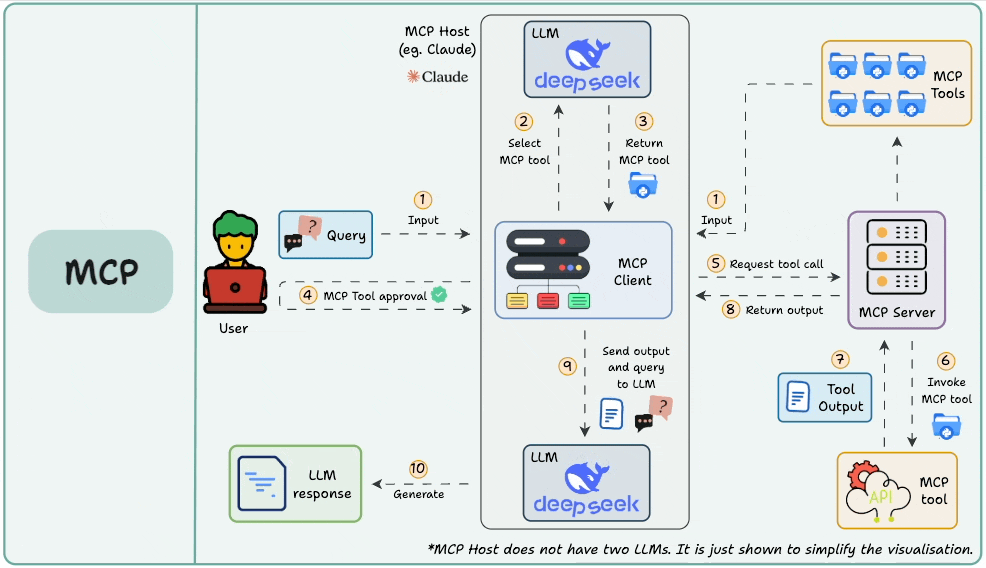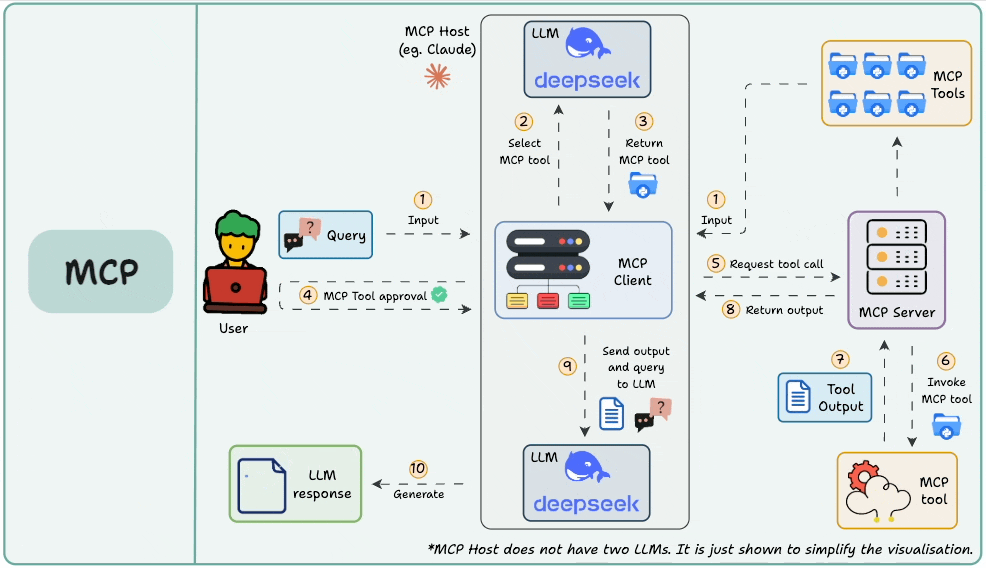
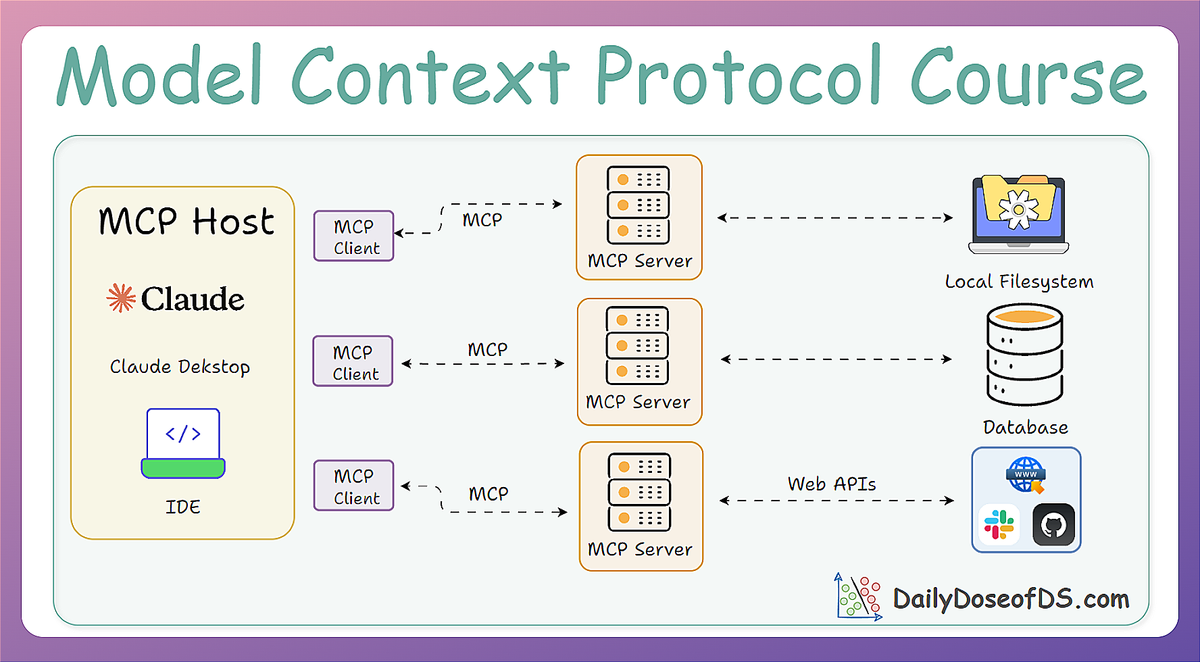
In Part 3, we built a custom MCP client from scratch, integrated an LLM into it (which acted as the brain), and understood the full lifecycle of the model context protocol in action.

We also explored the client-server interaction model through practical implementations, observed how tool discovery and execution are handled dynamically, and contrasted MCP’s design with traditional function calling and API-based approaches.

We concluded Part 3 with some "try out yourself" style exercises to reinforce practical learning, while our discussion emphasized how MCP streamlines integration through its decoupled and modular architecture.
The hands-on walkthrough in Part 3 not only demystified MCP as a protocol but also highlighted its core strengths, like scalability, extensibility, and seamless tool orchestration.
By learning how tools are registered, discovered, and executed without tight API coupling, we saw how MCP allows developers to build adaptable and maintainable AI systems with ease.
If you haven’t explored Part 3 yet, we highly recommend doing so first since it lays the essential groundwork for what follows in this part. You can read it below:
Introduction
Until now, our focus has primarily been on tools.
However, tools, prompts, and resources form the three core capabilities of the MCP framework.
While we introduced resources and prompts briefly in Part 2, this part will deep-dive into their mechanics, distinctions, and implementation.
We now shift gears to explore resources and prompts in detail and bring clarity to the key ideas around resources and prompts, like how they differ from tools, how to implement them, and how they enable richer, more contextual interactions when used in coordination.
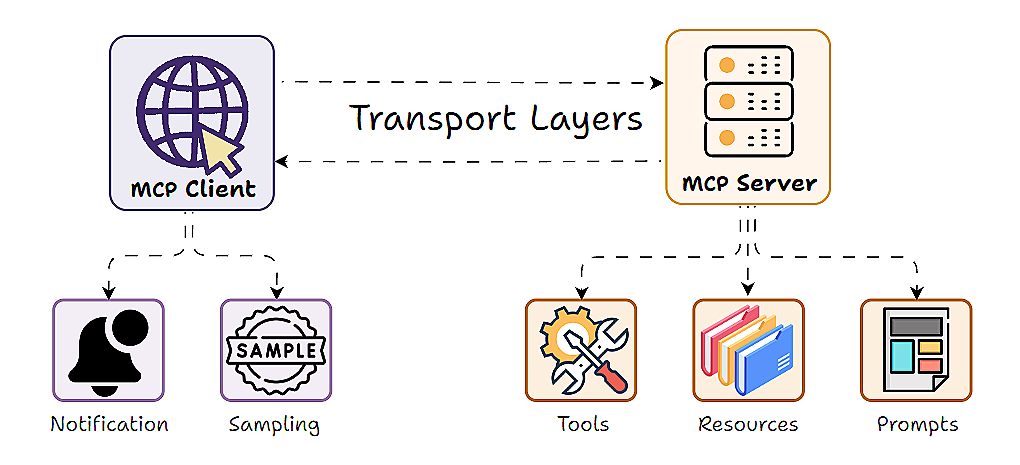
By the end of this part, you'll have a practical and intuitive understanding of:
- What exactly are resources and prompts in MCP
- Implementing resources and prompts server-side
- How tools, resources, and prompts differ from each other
- Using resources and prompts inside the Claude Desktop
- A full-fledged real-world use case powered by coordination across tools, prompts, and resources
Every concept will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Resources
Resources are one of the fundamental primitives of the model context protocol (MCP).
While tools are about doing (executing actions), resources are about knowledge.
They expose contextual data to language models, allowing them to reason without causing any side effects.
Intuition
Resources are read-only interfaces that expose data as structured, contextual information.
They act as intelligent knowledge bases or reference libraries, allowing models to access and reason about information.
Think of resources as a well-organized library: they provide access to books (data) that can be read and referenced, but the books themselves cannot be altered through the reading process.
What can resources represent?
Resources can represent various types of information:
- A file's contents
- An API's cached response
- A database snapshot
- An extracted snippet from a document
- System logs, configurations, or documentation
Since resources should not be used to execute or modify data, they offer a safe and predictable way to supply context into AI workflows, especially when dealing with static or semi-static knowledge.
URI-based resource identification
Resources are identified through unique URIs (uniform resource identifiers) following a structured format:
The protocol and path structure are entirely specific to the MCP server implementation, allowing servers to create custom URI schemes that fit their specific use cases.
For example:
Resource types
Resources can contain two distinct types of content: text or binary data. This gives us text resources and binary resources.
Let's understand them!
Text resources
Text resources contain UTF-8 encoded text data, suitable for:
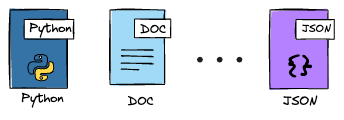
- Source code files
- Configuration files
- Log files
- JSON/XML data
- Plain text documents
Binary resources
Binary resources contain raw binary data encoded in base64, suitable for:
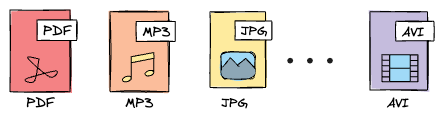
- Images and graphics
- PDF documents
- Audio and video files
- Any non-text file formats
Resource discovery mechanisms
MCP provides two complementary approaches for resource discovery:
Direct resources
In this mechanism, an MCP server can expose concrete resources through the resources/list endpoint, which also provides metadata including URI, human-readable name, optional description, MIME type, and size information.

This approach works well for known, static resources that are always available.
Resource templates
For dynamic content, servers can expose URI templates like file://{path}, following RFC 6570 standards.
Resource templates are particularly powerful for scalable implementations.
Instead of registering thousands of individual files, a server can expose a single template that covers entire families of resources, dramatically reducing complexity while maintaining full functionality.
Application-controlled access pattern
A crucial aspect of MCP resources is their application-controlled access pattern.
Unlike model-controlled primitives such as tools, resources require explicit client-side management.
To elaborate, when tools are invoked, the LLM returns the required tool call. The client, after permission from the user, invokes the tools that reside in the MCP server and receives the response. This depicts that the model is in control and the model decides what it is to be invoked:
But with resources, the client application must explicitly fetch and manage the data from the resources before providing it to the LLM, without the LLM initiating any action itself. This shows that the application is in the driver's seat for resources.
This design choice provides several important benefits.