Background, Foundations and Architecture
MCP Part 1: An introduction to model context protocol (MCP), covering background, need and an overview of the architecture and operational mechanics.
Introduction
Imagine you only know English. To get info from a person who only knows:
- French, you must learn French.
- German, you must learn German.
- And so on.
In this setup, learning even 5 languages will be a nightmare for you!
But what if you add a translator that understands all languages?
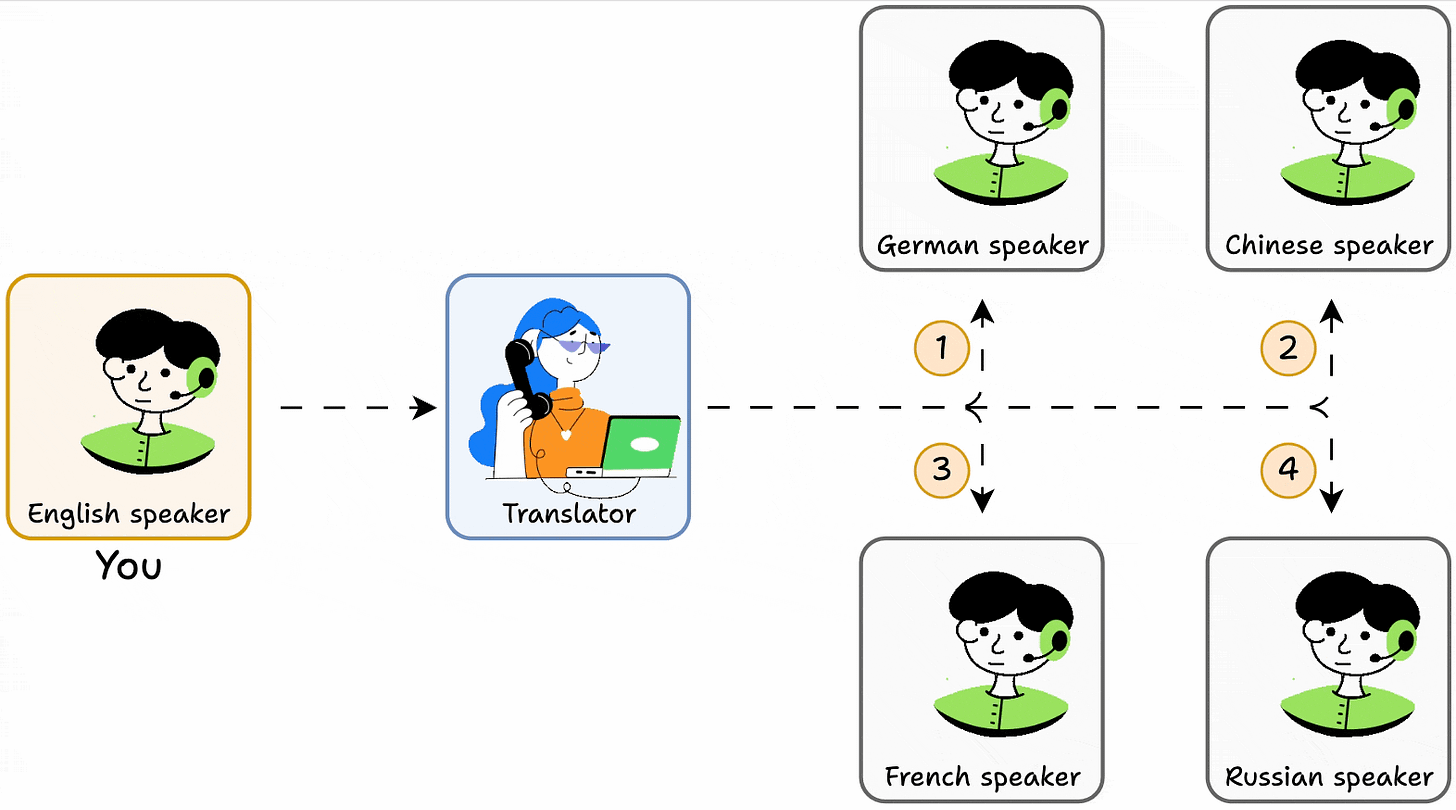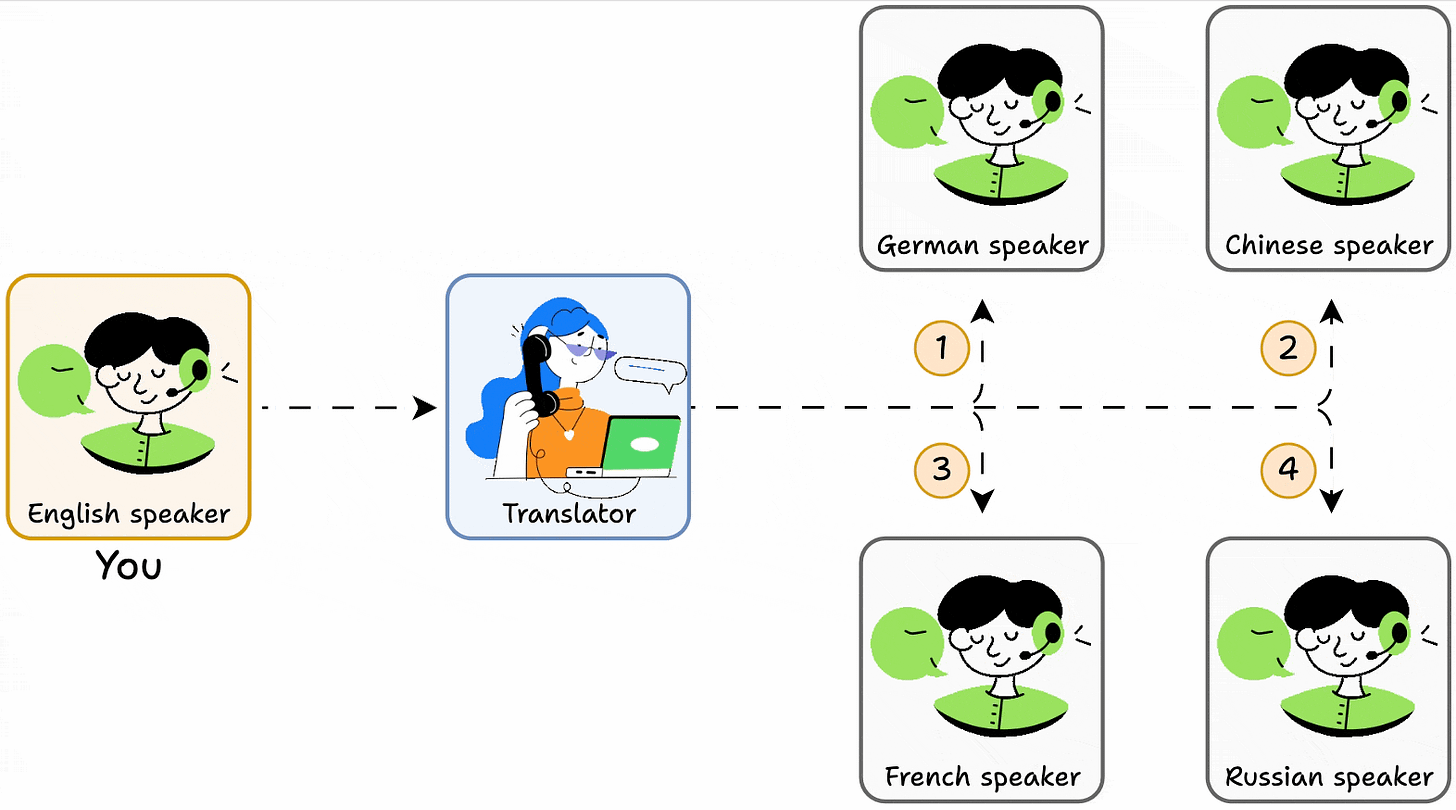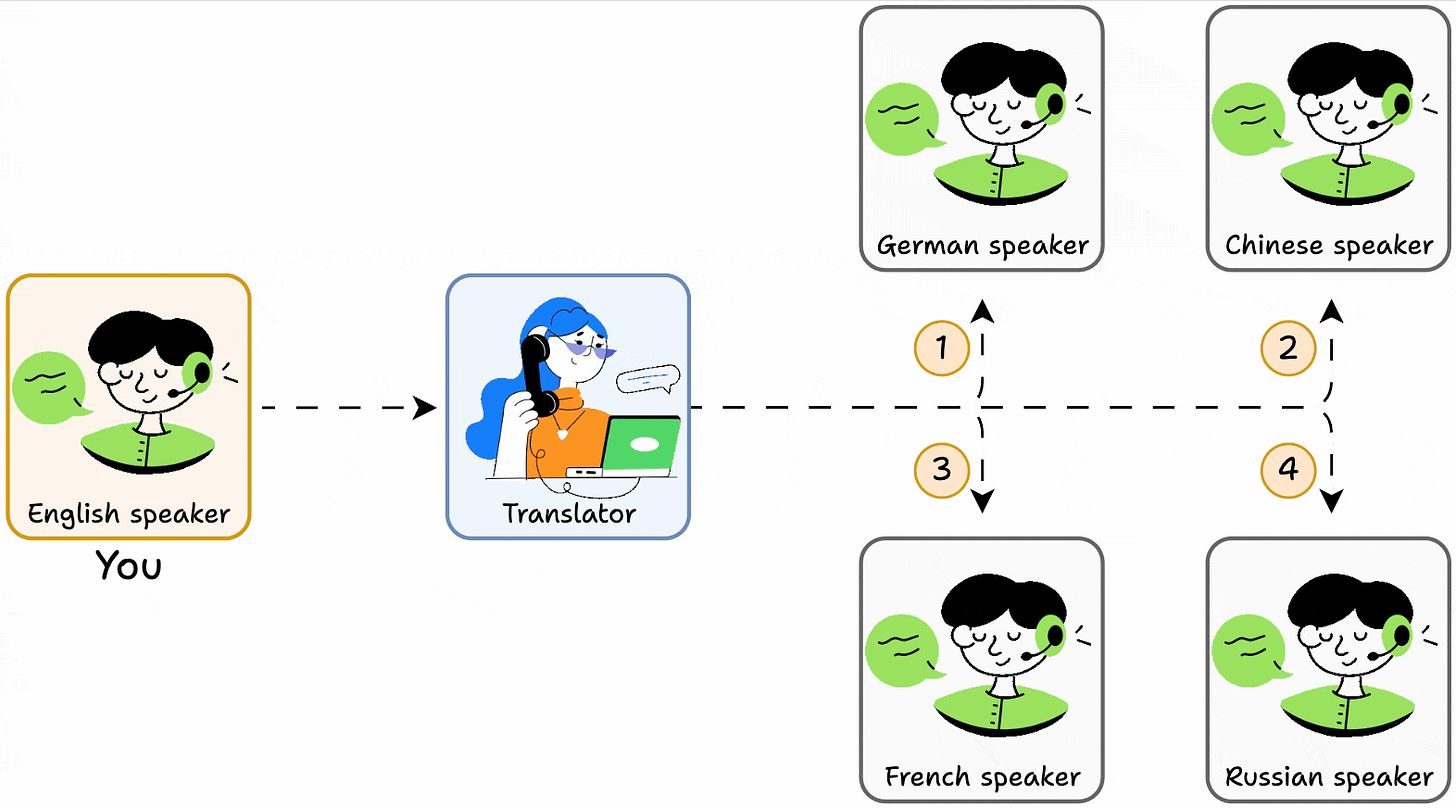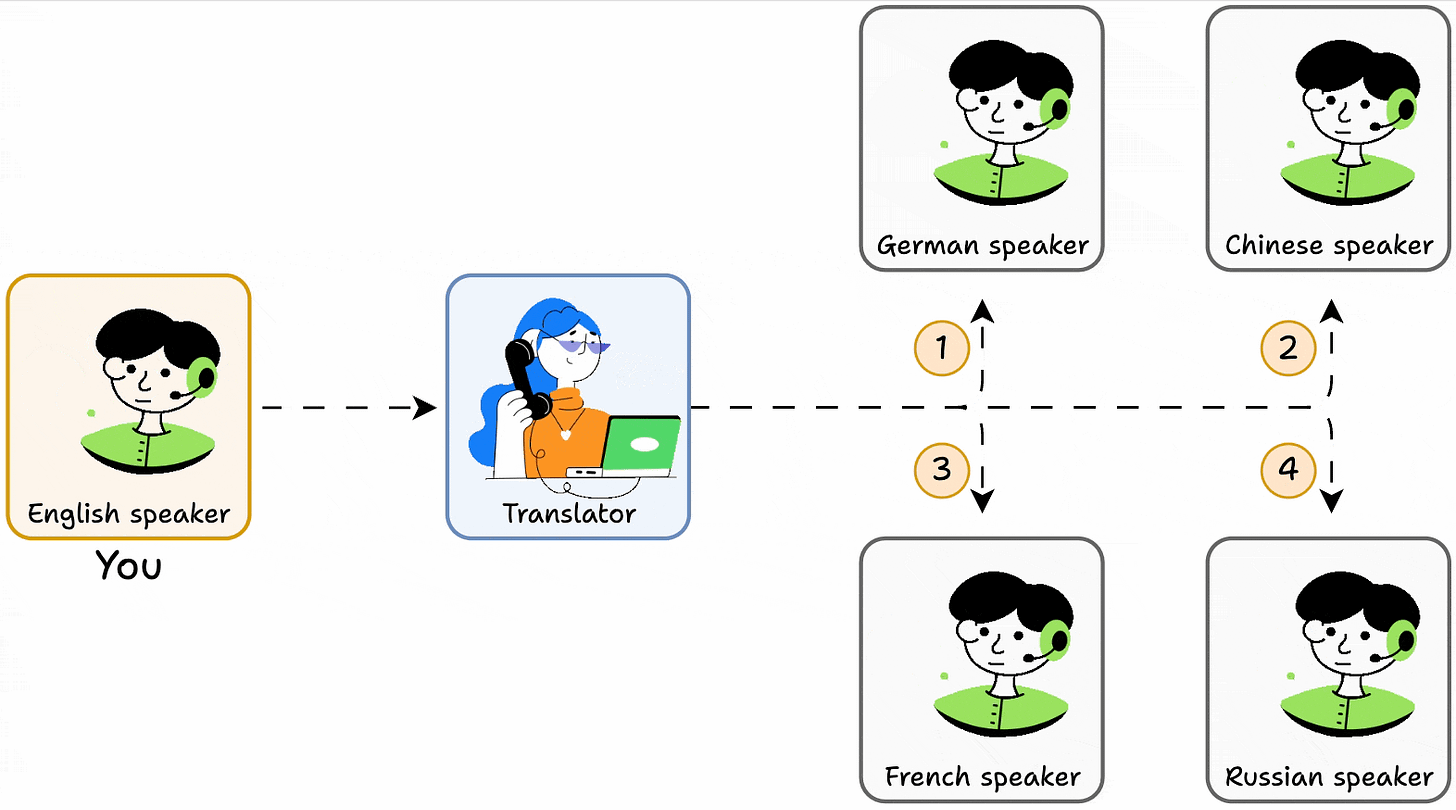
- You talk to the translator.
- It infers the info you want.
- It picks the person to talk to.
- It gets you a response.
This is simple, isn't it?
The translator is like an MCP!
It lets you (Agents) talk to other people (tools or other capabilities) through a single interface.
To formalize, while LLMs possess impressive knowledge and reasoning skills, which allow them to perform many complex tasks, their knowledge is limited to their initial training data.
If they need to access real-time information, they must use external tools and resources on their own, which tells us how important tool calling is to LLMs if we need reliable inputs every time.
MCP acts as a universal connector for AI systems to capabilities (tools, etc.), similar to how USB-C standardizes connections between electronic devices.
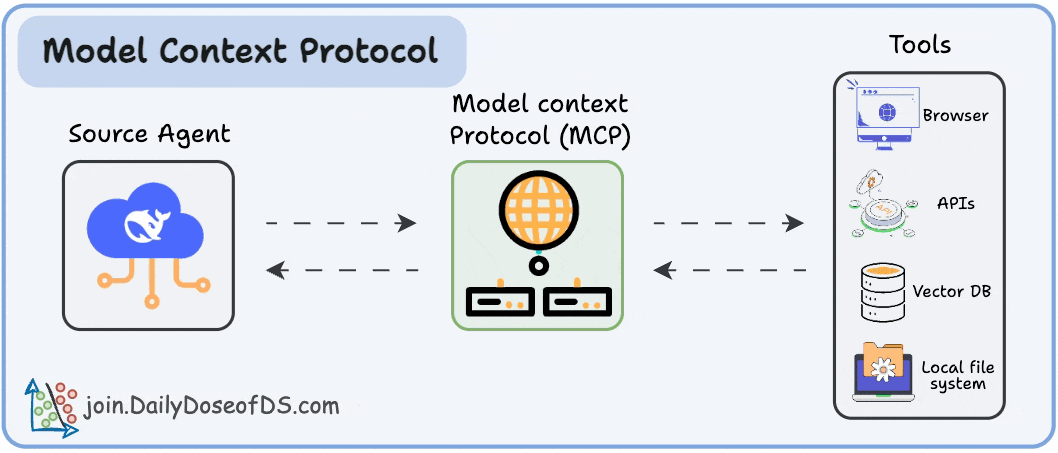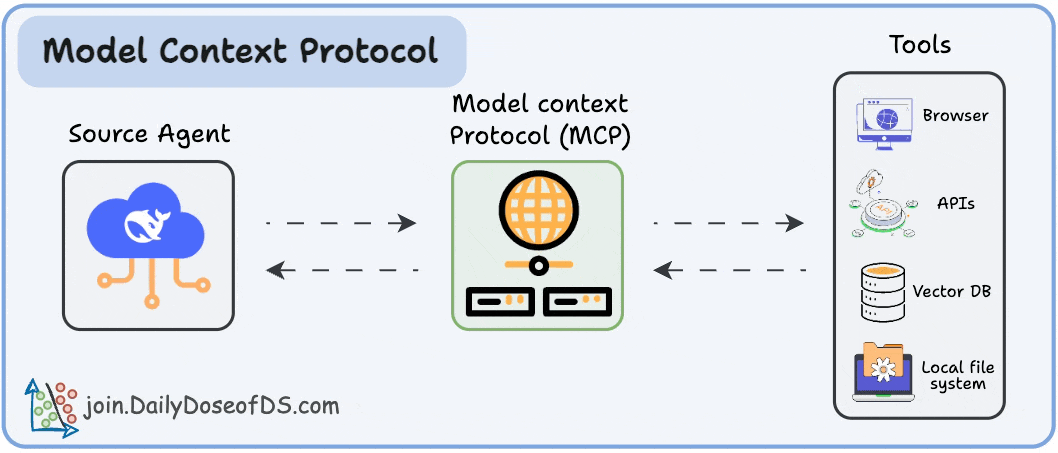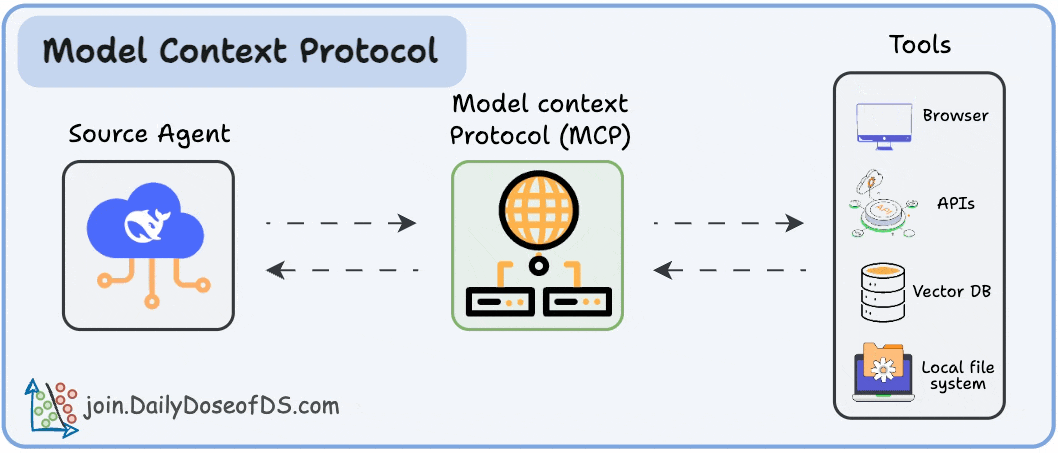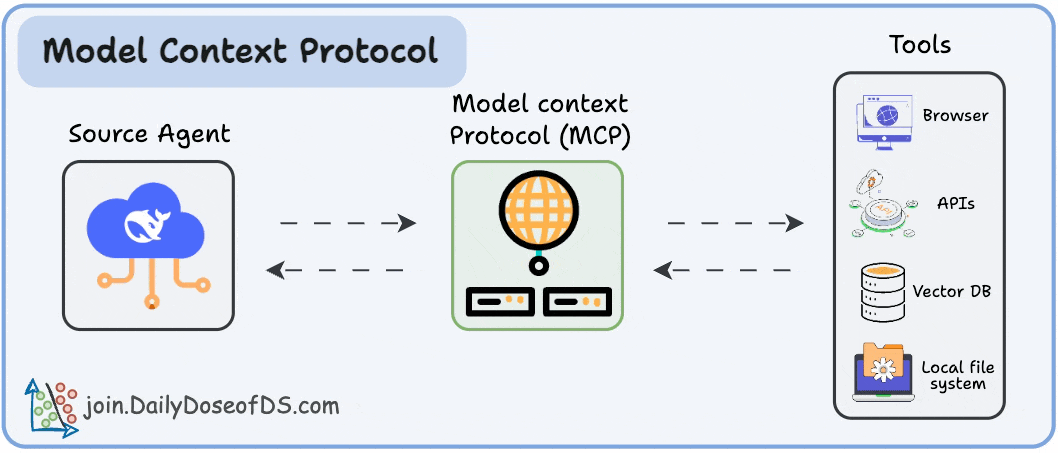
It provides a secure, standardized way for AI models to communicate with external data sources and tools.
We are starting this MCP crash course to provide you with a thorough explanation and practical guide to MCPs, covering both the theory and the application.
Just as the RAG crash course and AI Agents crash course, each chapter will clearly explain MCP concepts, provide real-world examples, diagrams, and implementations, and practical lab assignments and projects.
As we progress, we will see how MCP dynamically supplies AI systems with relevant context, significantly enhancing their adaptability and utility.
By the end, you will fully understand:
- What MCP is and why it’s essential
- How MCP enhances context-awareness in AI systems
- How to use MCP to dynamically provide AI systems with the necessary context.
In this part, we shall focus on laying the foundation by exploring what context means in the realm of LLMs, why traditional prompt engineering and context-management techniques fall short, and how MCP emerges as a robust solution to these limitations.
Let's begin!
Context management in LLMs
LLMs generate responses based on their "context window," which is the text input provided to the model.
This usually includes the user’s prompt, conversation history, instructions, or extra data given to the model. The model’s responses are completely determined by this context and its training.
However, there are a few important points to note:
- Models have a limited maximum context length. If the required information exceeds this window, the model cannot directly “see” it during a single interaction.

- Models come pre-trained on vast data up to a certain cut-off date, after which their knowledge is frozen in time. They lack awareness of any events or facts beyond their training data. Context management involves supplying updated or specialized information to augment the model’s static knowledge, which is exactly what we learned in the RAG crash course as well.
Early approaches to context management
Before advanced protocols like MCPs, developers used basic techniques to manage context in LLM applications:
- Truncation and sliding windows: For multi-turn conversations (like chatbots), a common approach is to include as much recent dialogue/chats as fits in the window, while removing older messages or summarizing them. While this ensures the model sees the latest user query and some history, important older context might be lost.

- Summarization: Another strategy is to summarize long documents or conversation histories into a shorter form that the model can handle. The summary is then given to the model as context. While this can capture key points, it introduces an additional layer where errors can occur. For instance, a poor summary can omit critical details or even introduce inaccuracies. It’s also quite intensive to create good summaries for every potential context on the fly.

- Template-based prompts: Developers learned to craft prompts that include structured slots for context. For instance, a Q&A prompt might be:
Here is some information: [insert relevant info].
Using this, answer the question: [user question].
This ensures the model explicitly receives needed data. However, the burden is on the developer (or an automated pipeline) to retrieve or generate the [insert relevant info] part, which can be complex for large knowledge sources.
Despite these efforts, limitations persist.
The context window remains a hard cap; if the data doesn’t fit or isn’t fetched, the model won’t magically recall it.
This leads us to consider prompt engineering more deeply and why it alone is often insufficient.
Pre-MCP techniques
To appreciate why MCP was developed, we need to look at how developers tried to extend AI capabilities with traditional prompting techniques, retrieval-based methods, and custom tool integrations, and where those approaches fell short that led us to develop MCP.
Static prompting (pre-tools)
Initially, using an LLM meant giving it all the necessary information in the prompt and hoping it would produce the answer.
If the model didn’t know something (e.g., today’s weather or a live database record), there was no straightforward way for it to find out.
Retrieval-augmented generation
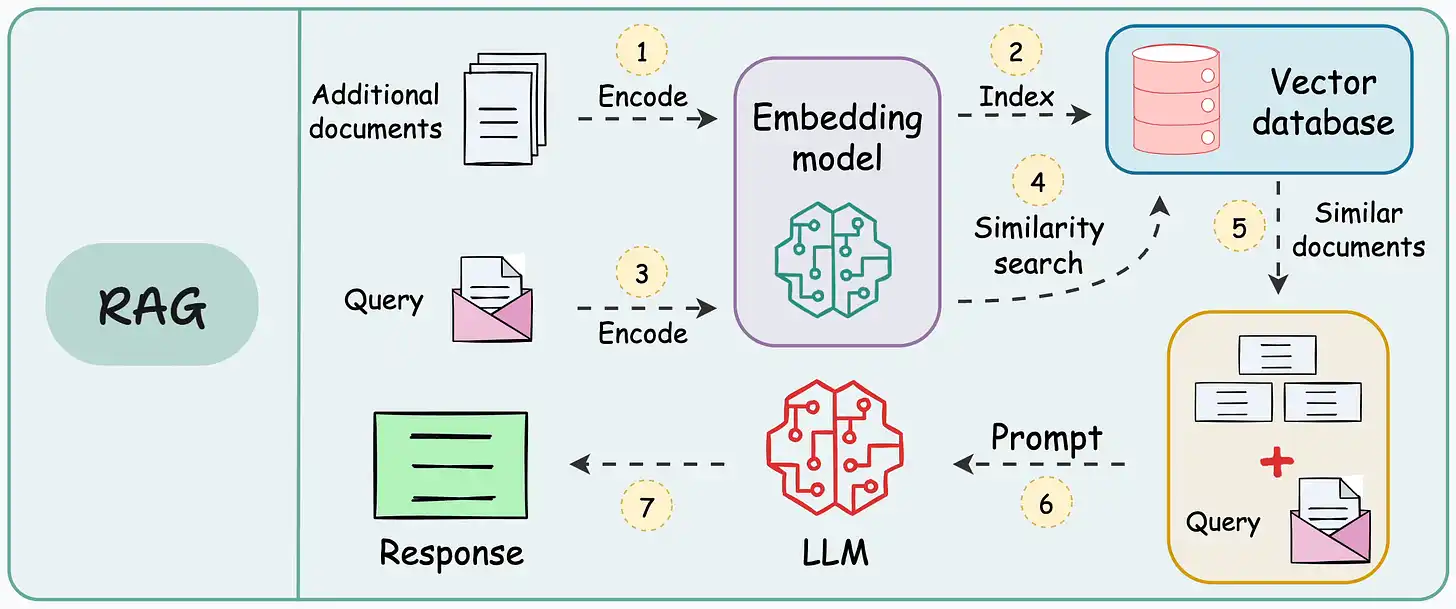
A big step was letting models leverage external data by retrieving documents or facts and adding them to the prompt.
This helped with up-to-date information and domain-specific knowledge, but it still treated the model as a passive consumer of data. The model itself wasn’t initiating these lookups.
Instead, the developer had to wire in the retrieval logic.
Also, RAG mainly addresses knowledge lookup; it doesn’t enable the model to perform actions or use tools (other than searching for text).
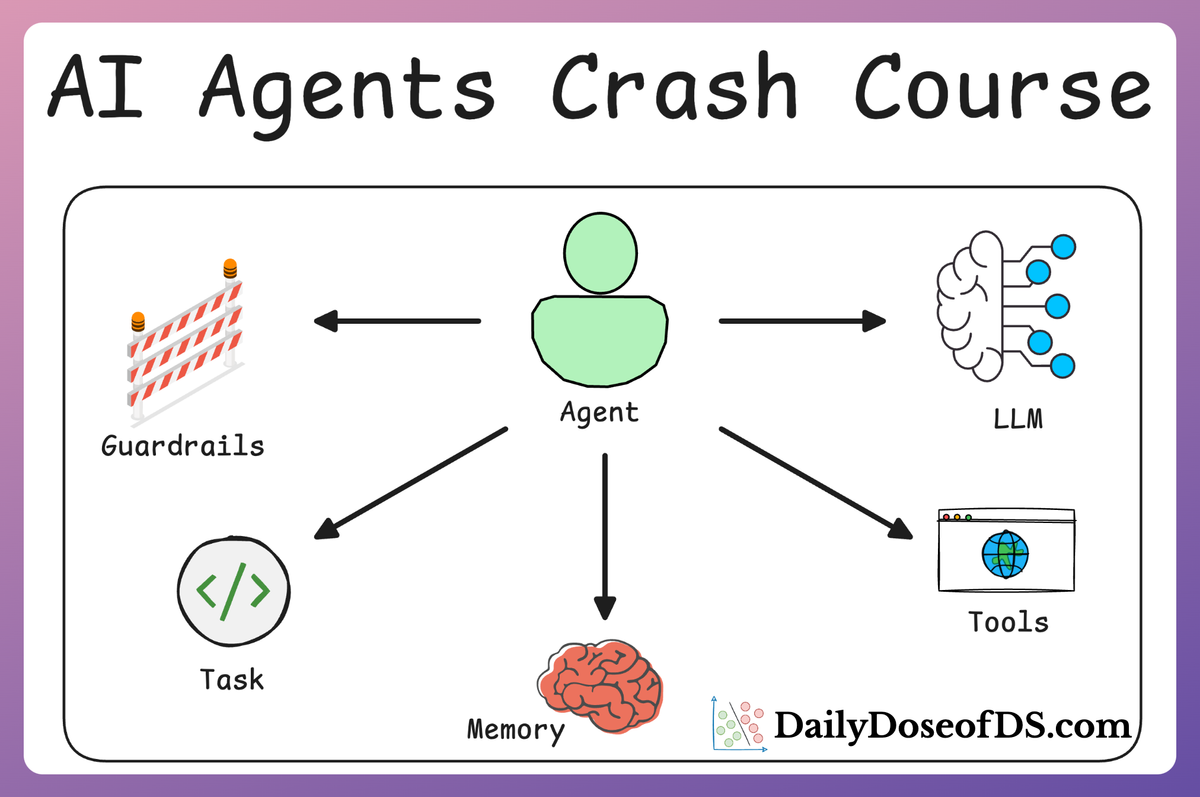
Prompt chaining and agents
Some advanced applications began using Agents (like those built with LangChain or custom scripts) where the model’s outputs could be interpreted as commands to perform actions.
For example, an LLM could be prompted in a way that it outputs something like, SEARCH: ‘weather in SF’ , which the system then recognizes and executes by calling a weather API, feeding the result back into the model.
This technique, often called the ReAct (Reasoning + Action) pattern or tool use via chain-of-thought prompting, was powerful but ad-hoc and relatively fragile. We implemented the ReAct pattern from scratch in the AI Agents crash course:
In that discussion, we saw how the LLM's output indicated a function call whenever it required a function call:
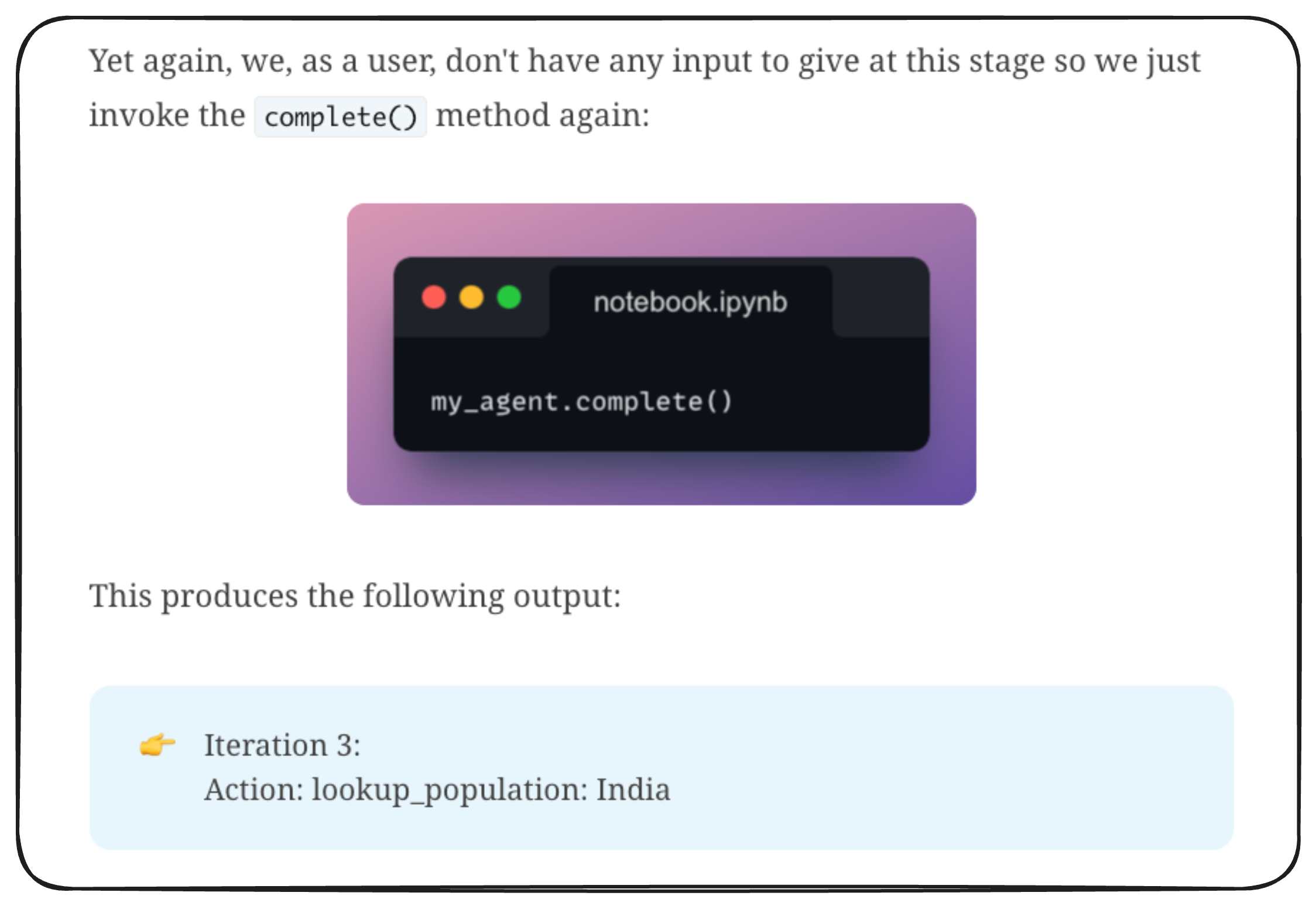
Coming back to prompt chaining, here, every developer built their own chaining logic, and each LLM had its own style for how it might express a tool call, making it hard to generalize.

There was no common standard, which means integrating a new tool meant writing custom prompt logic and parsing for each case.
Function calling mechanisms
In 2023, OpenAI introduced function calling. This allowed developers to define structured functions that the LLM could invoke by name.

The model, when asked a question, could choose to call a function (for example, getWeather) and return a JSON object specifying that function and arguments, instead of a plain text answer.
This was much more structured than hoping the model outputs SEARCH: ... in plain text.
For instance, the model might respond with a JSON, like the one below, indicating that it needs to call the weather function.