Reinforcement Learning Course
Bellman Equations and Dynamic Programming
RL Part 3: Bellman expectation and optimality equations, policy iteration, value iteration, and why dynamic programming needs a model.
RL Part 3: Bellman expectation and optimality equations, policy iteration, value iteration, and why dynamic programming needs a model.
RL Part 2: Markov decision processes, returns, policies, and value functions.
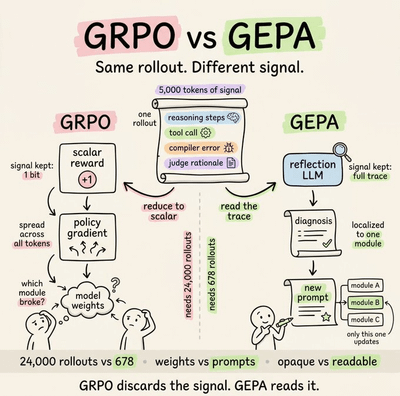
Berkeley beat GRPO by 10 points with 35× fewer rollouts and no GPU training,
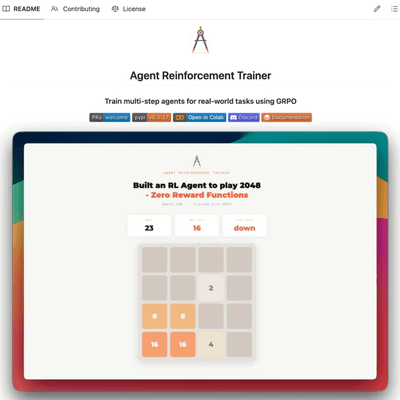
The era of not writing custom reward functions.
RL Part 1: Agents, environments, rewards, and why RL is different from supervised learning.
...using Karpathy's context engineering principles!
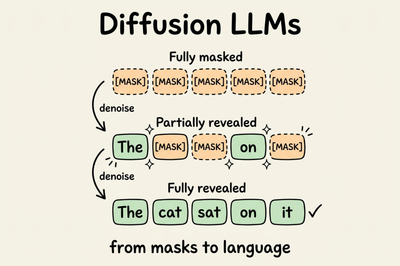
Diffusion LLMs Part 2: How dLLMs scale to 100B parameters, the inference stack that makes them fast, hands-on code, and when to actually use them.
...explained with usage.