A Practical Deep Dive Into Memory for Agentic Systems (Part B)
AI Agents Crash Course—Part 9 (with implementation).
Introduction
In Part 8 of this AI Agents crash course, we took a practical look at how memory works in CrewAI-powered systems.
We covered how agents can:
- Track recent interactions using short-term memory.
- Learn from past performance with long-term memory.
- Retain structured facts about specific people or entities with entity memory.
We explored how to query memory with .search(), what kind of metadata is returned, and how agents use those memory chunks to answer questions, refine responses, or personalize behavior across tasks and sessions.
But that was just the surface.
While Part 8 gave us a high-level, hands-on understanding of how memory behaves in CrewAI, this part (Part 9) is where we get formal and technical.
In this part, we’ll:
- Formalize the 5 types of memories.
- Learn how to customize memory settings.
- Learn how memory works internally—including the vector storage and similarity matching logic behind the scenes.
- Learn how to reset or manage memory, at runtime or across sessions.
- and much more.
Let's dive in!
Why memory? A quick recap
So far in this AI Agent crash course series, we’ve built systems that can:
- Collaborate across multiple crews and tasks.
- Use guardrails, callbacks, and structured outputs.
- Handle multimodal inputs like images.
- Reference outputs of previous tasks.
- Work asynchronously and under human supervision.
We’ve also explored how to equip agents with Knowledge, allowing them to access internal documentation, structured datasets, or any domain-specific reference material needed to complete their tasks.
However, all of this still leaves one major gap…
So far, our agents have mostly been stateless. They could access tools, reference documents, or perform tasks—but they didn’t remember anything unless we passed it into their context explicitly.
What if you want your agents to:
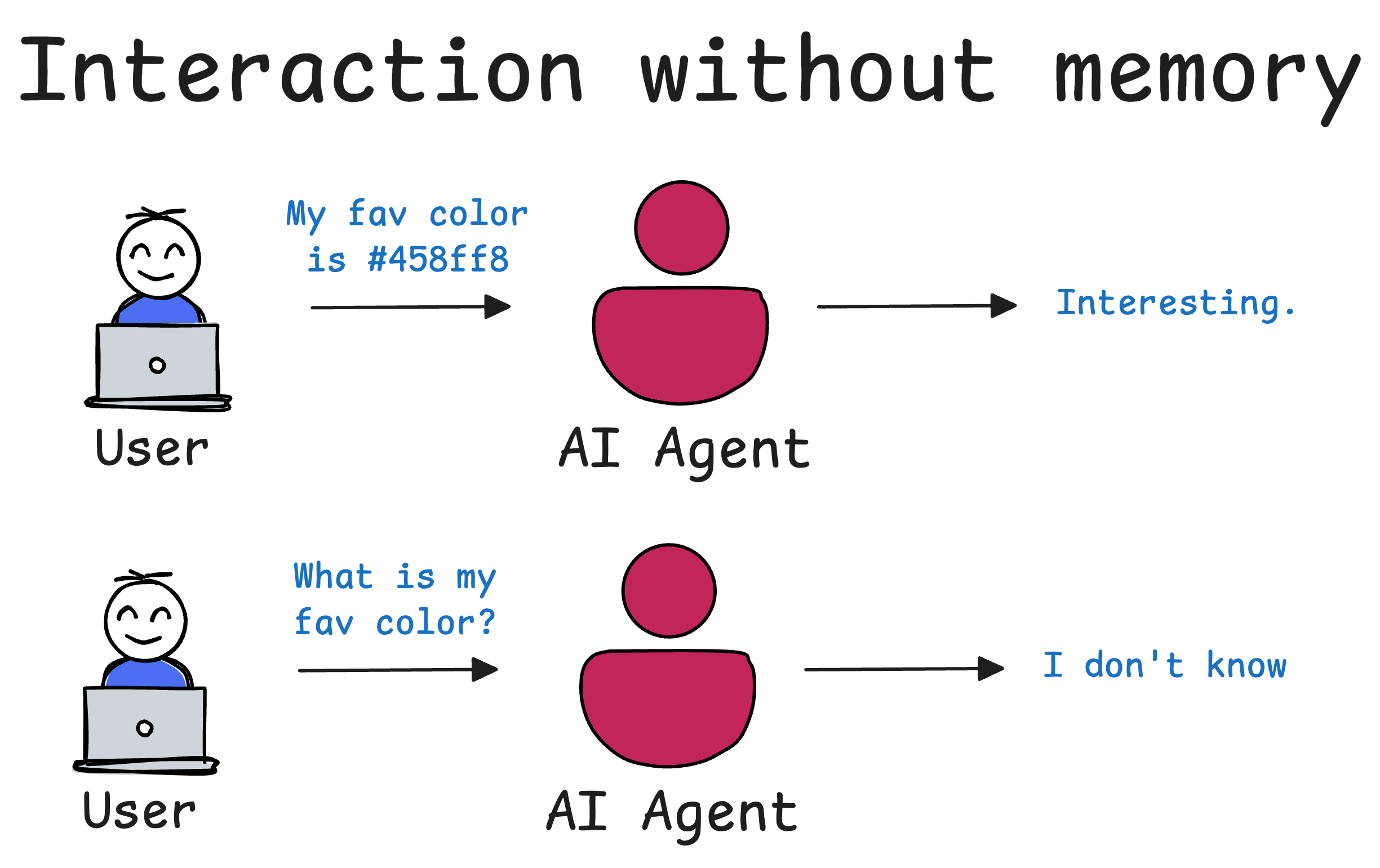
- Recall something a user told them earlier in the conversation.
- Accumulate learnings across different sessions?
- Personalize answers for individual users based on their past behavior.
- Maintain facts about entities (like customers, projects, or teams) across workflows.
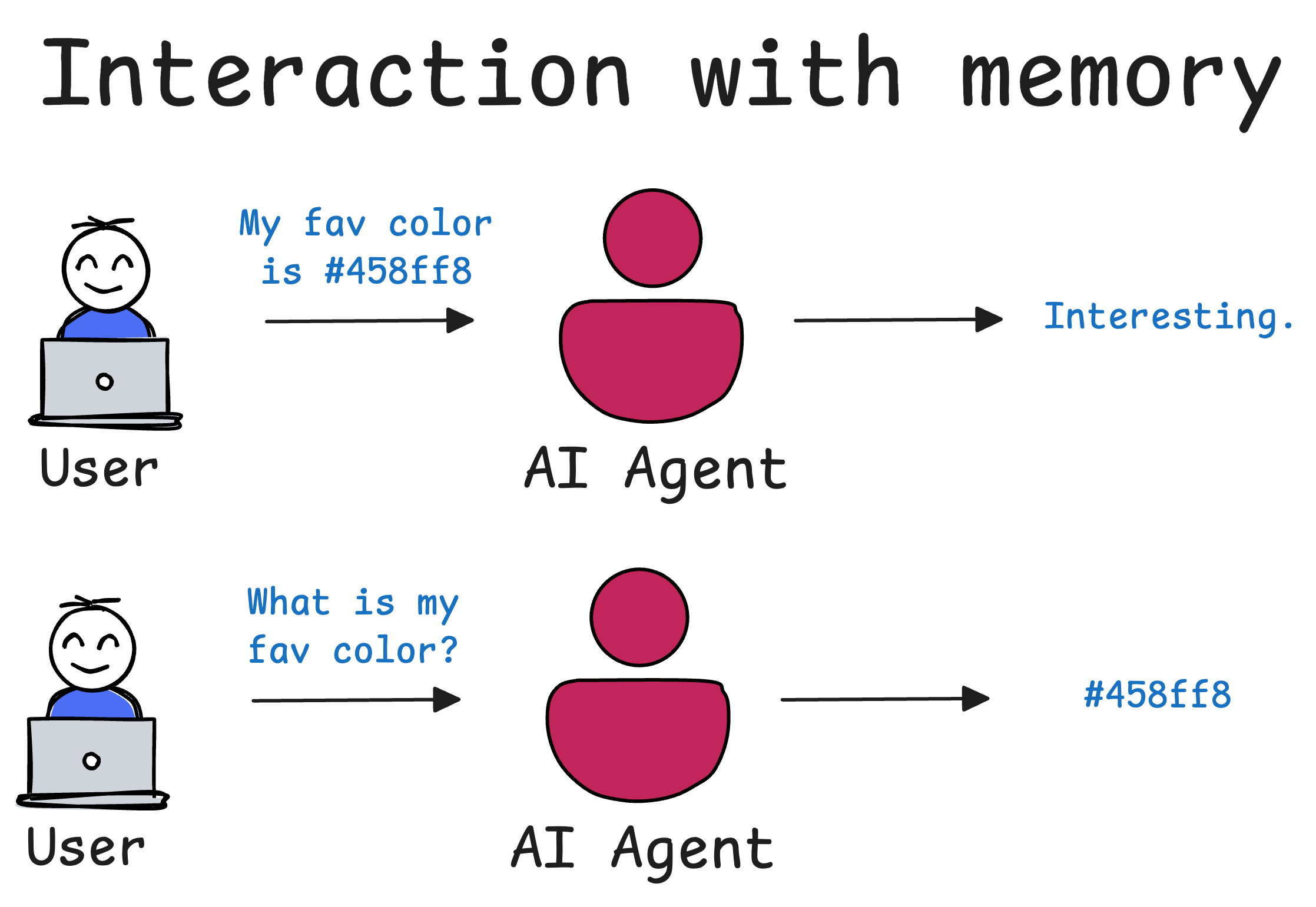
Memory solves this.
In an agentic system like CrewAI, memory is the mechanism that allows an AI agent to remember information from past interactions, ensuring continuity and learning over time.
This differs from an agent’s knowledge and tools, which we have already discussed in previous parts.
- Knowledge usually refers to general or static information the agent has access to (like a knowledge base or facts from training data), whereas memory is contextual and dynamic—it’s the data an agent stores during its operations (e.g. conversation history, user preferences).
- Tools, on the other hand, let an agent fetch or calculate information on the fly (e.g. web search or calculators) but do not inherently remember those results for future queries. Memory fills that gap by retaining relevant details the agent can draw upon later, beyond what’s in its static knowledge.
Memory matters because if you have an Agentic system deployed in production and it is running without memory, every interaction is a blank slate.
It doesn’t matter if the user told the agent their name five seconds ago—it’s forgotten. If the agent helped troubleshoot an issue in the last session, it won’t remember any of it now.
With memory, your agent becomes context-aware.
Talking specifically about CrewAI, it provides a structured memory architecture with several built-in types of memory (we'll discuss each of them shortly in detail):
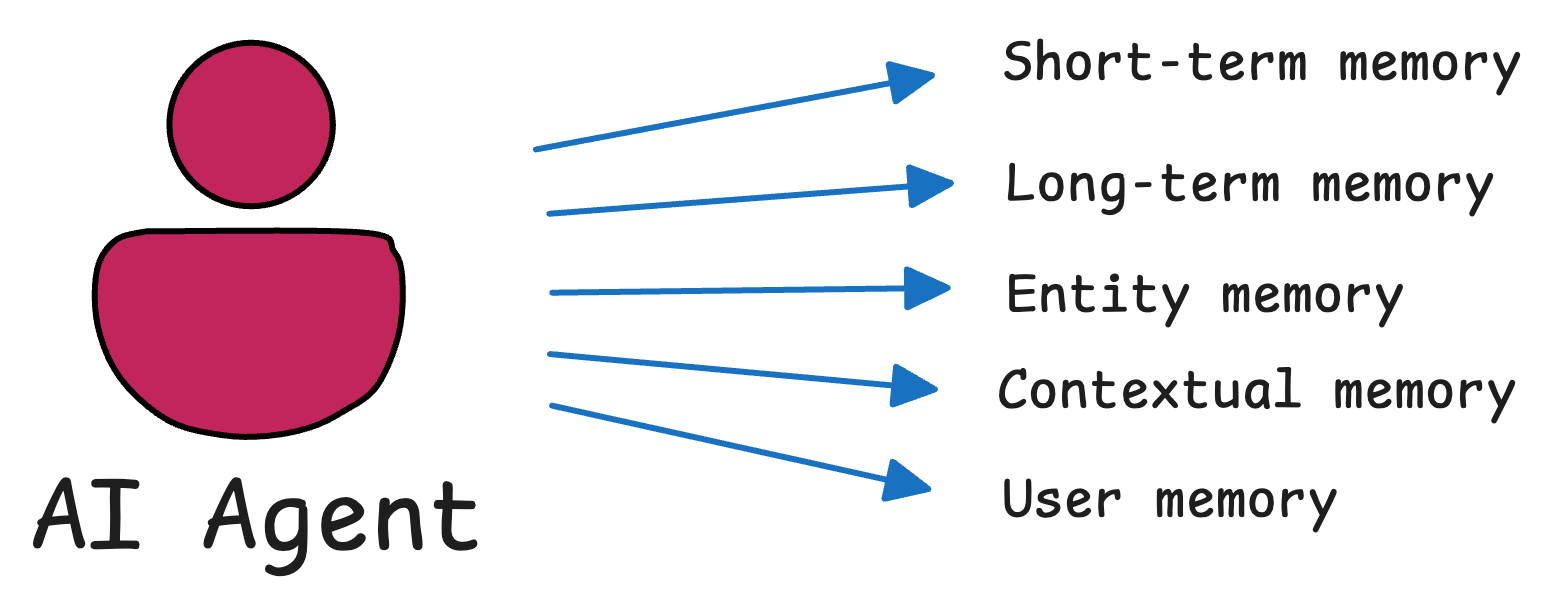
- Short-Term Memory
- Long-Term Memory
- Entity Memory
- Contextual Memory, and
- User Memory
Each of these serves a unique purpose in helping agents “remember” and utilize past information.
Let's understand them below conceptually and get into the technical details as well.
.env file with the OPENAI_API_KEY specified in it. It will make things much easier and faster for you. Also, add these two lines of code to handle asynchronous operations within a Jupyter Notebook environment, which will allow us to make asynchronous calls smoothly to your Crew Agent.If you haven't read Part 8 yet on Memory, we highly recommend doing so:
#1) Short-Term Memory
Short-term memory in CrewAI is the agent’s “working memory” for the current session or task sequence. It stores recent interactions and outcomes so the agent can recall information relevant to the ongoing context.
As we also saw in Part 8, under the hood, CrewAI implements short-term memory using a Retrieval-Augmented Generation (RAG) approach:

- It embeds the text of recent prompts and results into a vector store (by default using OpenAI embeddings and a local Chroma vector database)
- Retrieves relevant pieces as context for new queries.
This means even if a conversation or task involves many steps, the agent can fetch the most relevant bits from earlier in the session without exceeding the model’s immediate context window.