A Crash Course on Building RAG Systems – Part 6 (With Implementation)
A deep dive into building multimodal RAG systems on real-world data (with implementation).
Introduction
Coming into Part 6 of our RAG crash course series, we have covered all the foundational building blocks necessary to construct a multimodal RAG (Retrieval-Augmented Generation) system.
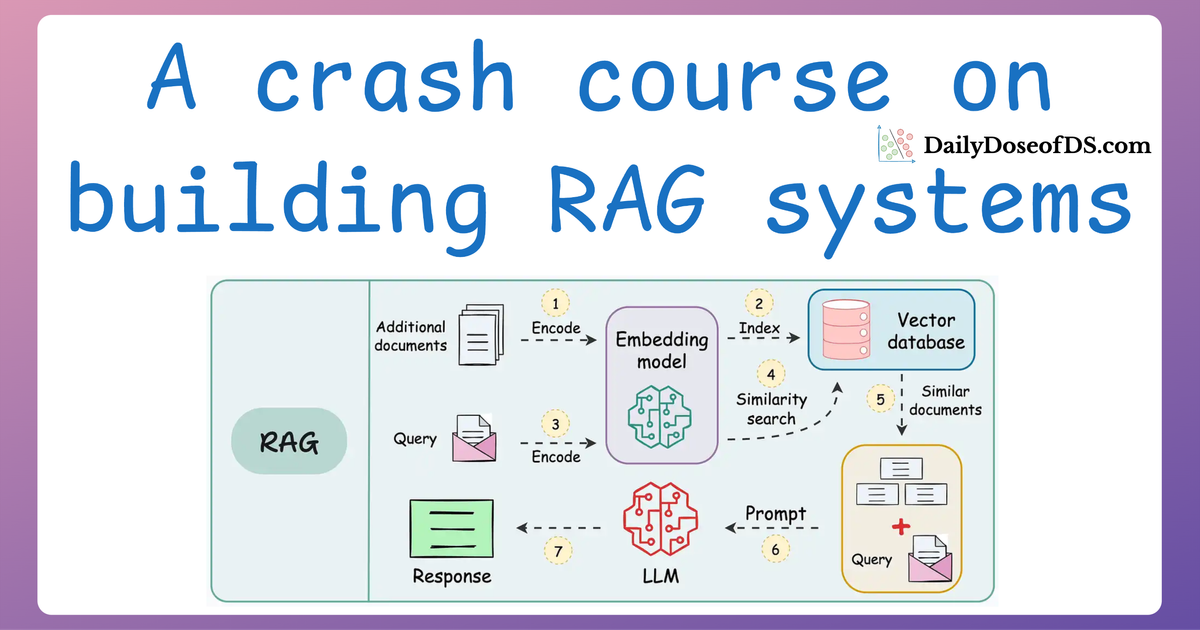
In the earlier parts, we explored the essentials of RAG systems, focusing on text-based architectures, evaluation, optimization, and the complexities of handling multimodal data.
In Part 5, we understood the fundamentals of multimodal RAG systems like:
- CLIP embeddings, which align text and image data in a shared semantic space.
- Multimodal prompting, which lets us prompt the model with different data formats like text, images, and tables.
- Tool calling, which allows dynamic invocation of external tools to enhance the system's versatility and real-time capabilities.
With that, we can bring everything together to build a practical multimodal RAG system that can process, retrieve, and reason about diverse types of data—text and images.
In this part, we’ll:
- Start with a dataset of image-text pairs.
- Generate embeddings for these pairs using CLIP.
- Store these embeddings in a vector database for efficient retrieval.
- Design a retrieval pipeline that handles multimodal queries (prompt includes text and images).
- Combine retrieval results to generate coherent and relevant responses.
By the end of this section, we'll have a working pipeline for a multimodal RAG system, and you will have the knowledge to adapt it to a variety of real-world scenarios.
Let’s dive in!
A quick recap
Before diving in, let's do a quick recap of what we covered last time, specifically CLIP embeddings and multimodal prompting.
CLIP (Contrastive Language–Image Pretraining) is a model developed by OpenAI that creates a shared representation space for text and images.
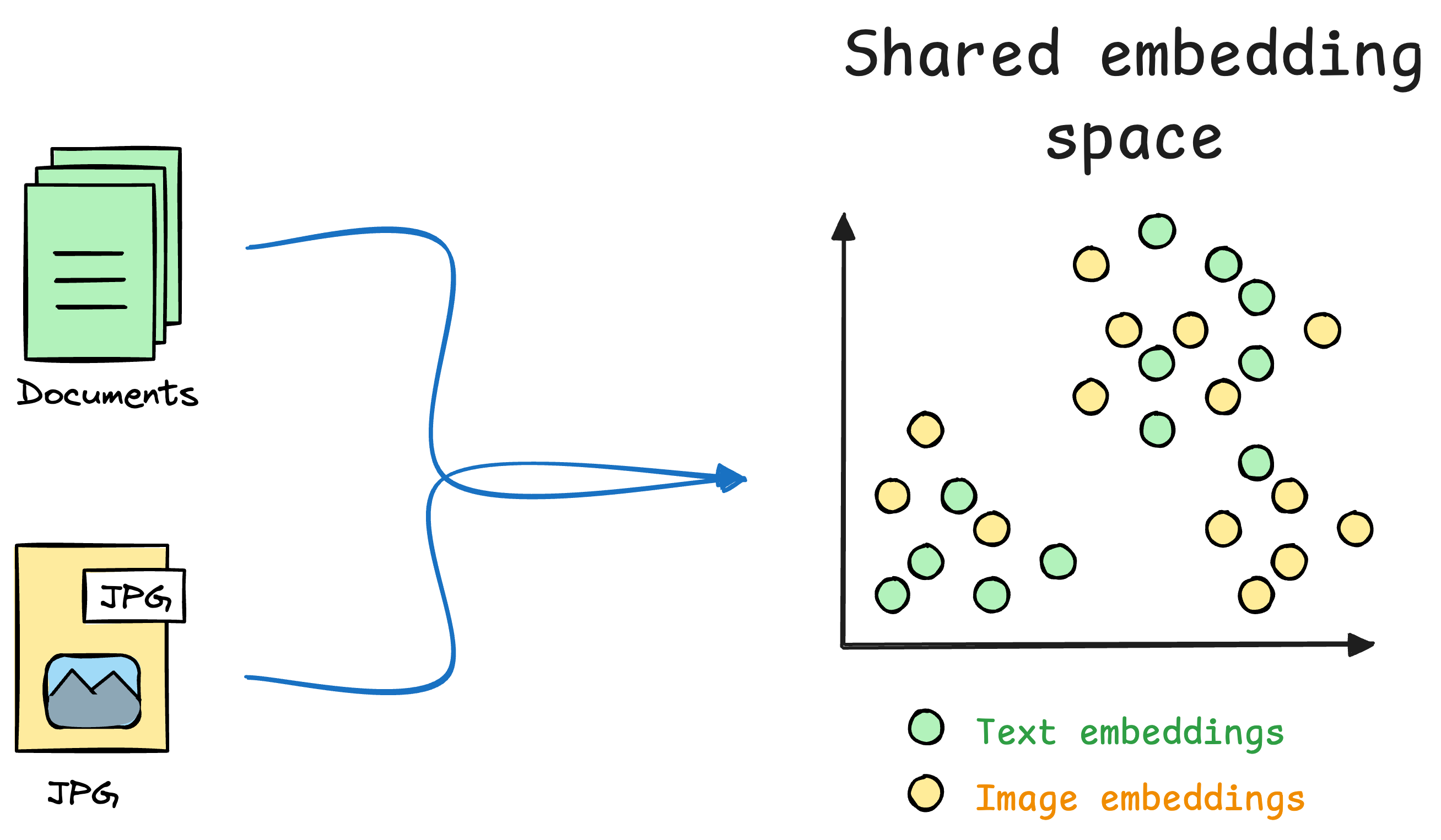
Unlike traditional models that handle text or images in isolation, CLIP allows us to compare and reason about text and images together, which makes it a key component of multimodal systems like Retrieval-Augmented Generation (RAG).
CLIP utilizes two distinct encoders:
- One for text and
- Another for images.
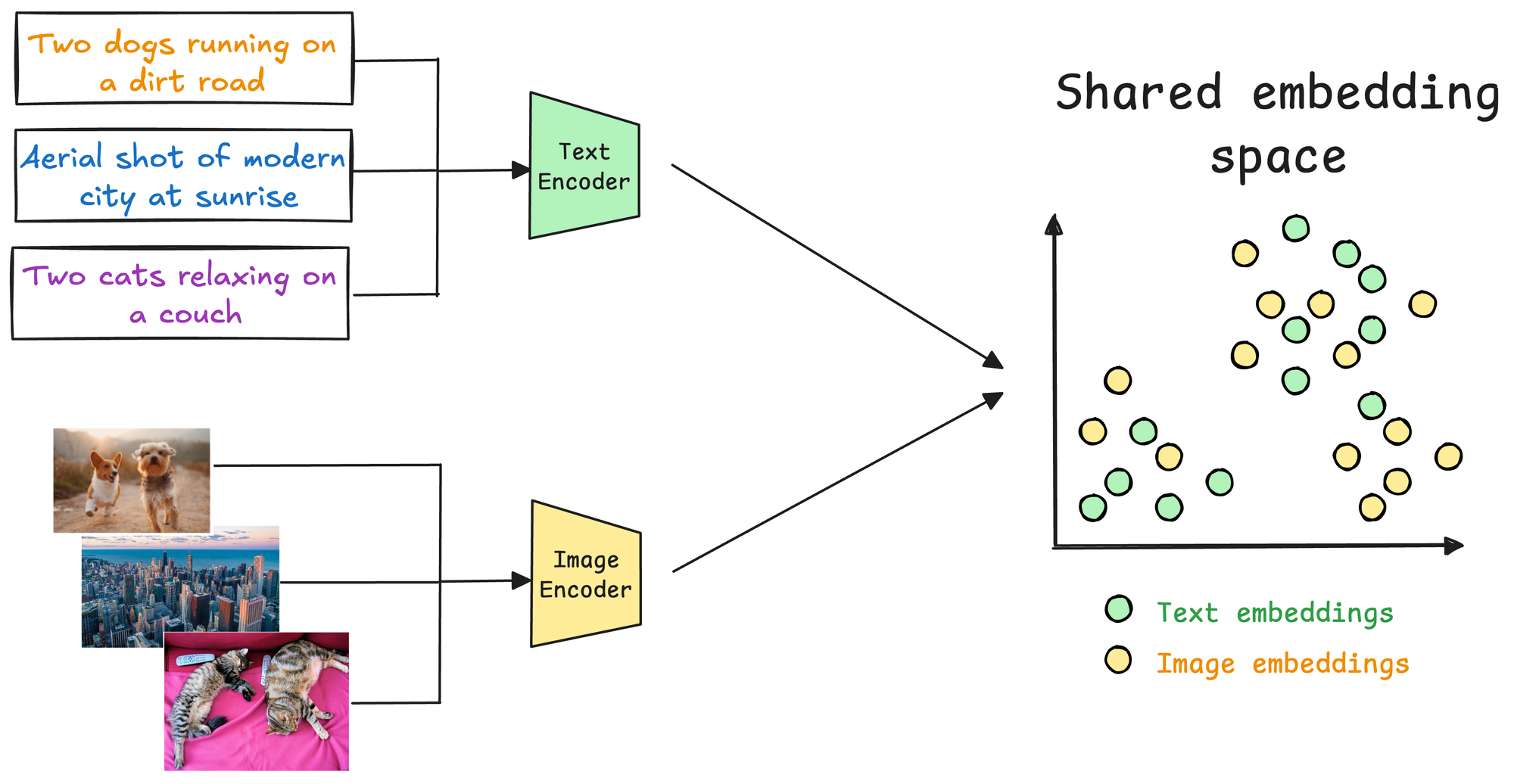
These encoders map their respective modalities (text and image) into a shared multimodal embedding space. This enables a cross-modal comparison—a text can be compared to an image, or vice versa, to evaluate their semantic similarity, which is a key component of a multimodal RAG system.
And in the case of multimodal prompting, we extend the concept of natural language prompting to include multiple data modalities, such as text, images, videos, and structured data.
In traditional text-only prompting (early versions of ChatGPT, for instance), users provide textual instructions or queries to guide the behavior of a model.
Multimodal prompting builds on this by allowing prompts that combine text with other modalities, such as:
- Images: Provide visual context or ask questions about visual content.
- Tables: Supply structured data for reasoning.
- Audio or Video: Enable dynamic, context-aware queries based on audio-visual inputs.
Consider you have this image stored in your local directory (download below):
{kind=link}

You can prompt the multimodal LLM with the image as follows:

If you have multiple images, you can pass them as a list in the images key of messages parameter.
Simple, isn't it?
We have already covered a detailed practical demo of CLIP in Part 5, so we won't discuss it in much detail again. You can read Part 5 linked below if you haven't read it yet.
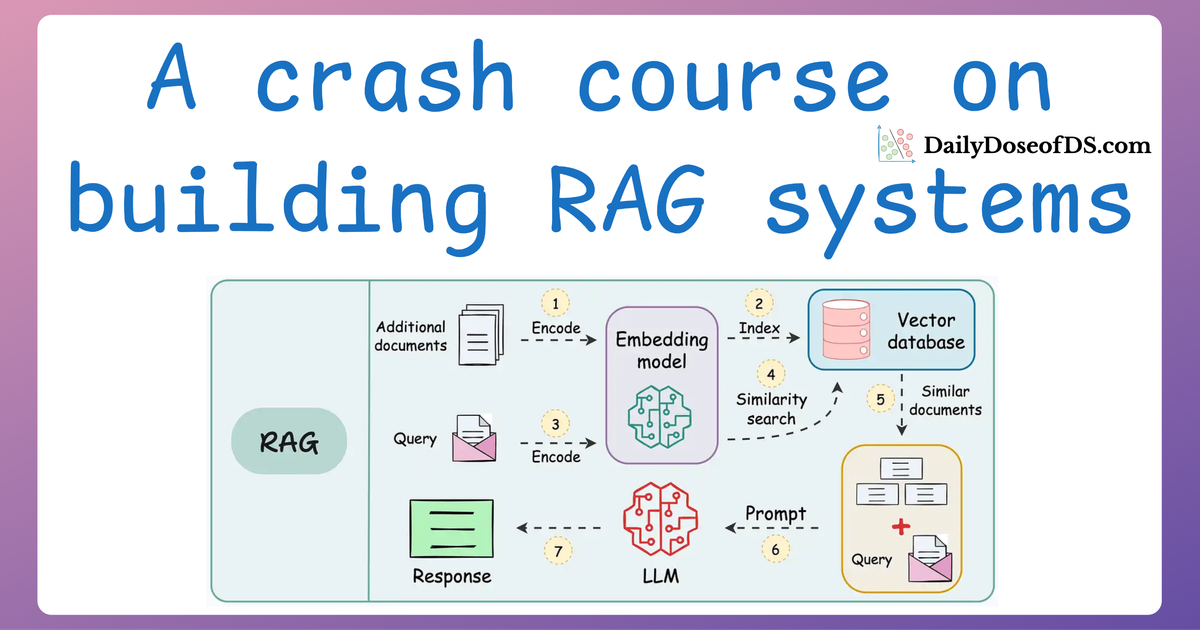
That said, let's get into building the multimodal RAG now.
Multimodal RAG
Now that we’ve laid a solid foundation with CLIP embeddings and multimodal prompting, it’s time to build a fully functional multimodal RAG (Retrieval-Augmented Generation) system.
In this section, we’ll cover the step-by-step process of building a multimodal RAG system. Specifically, we’ll:
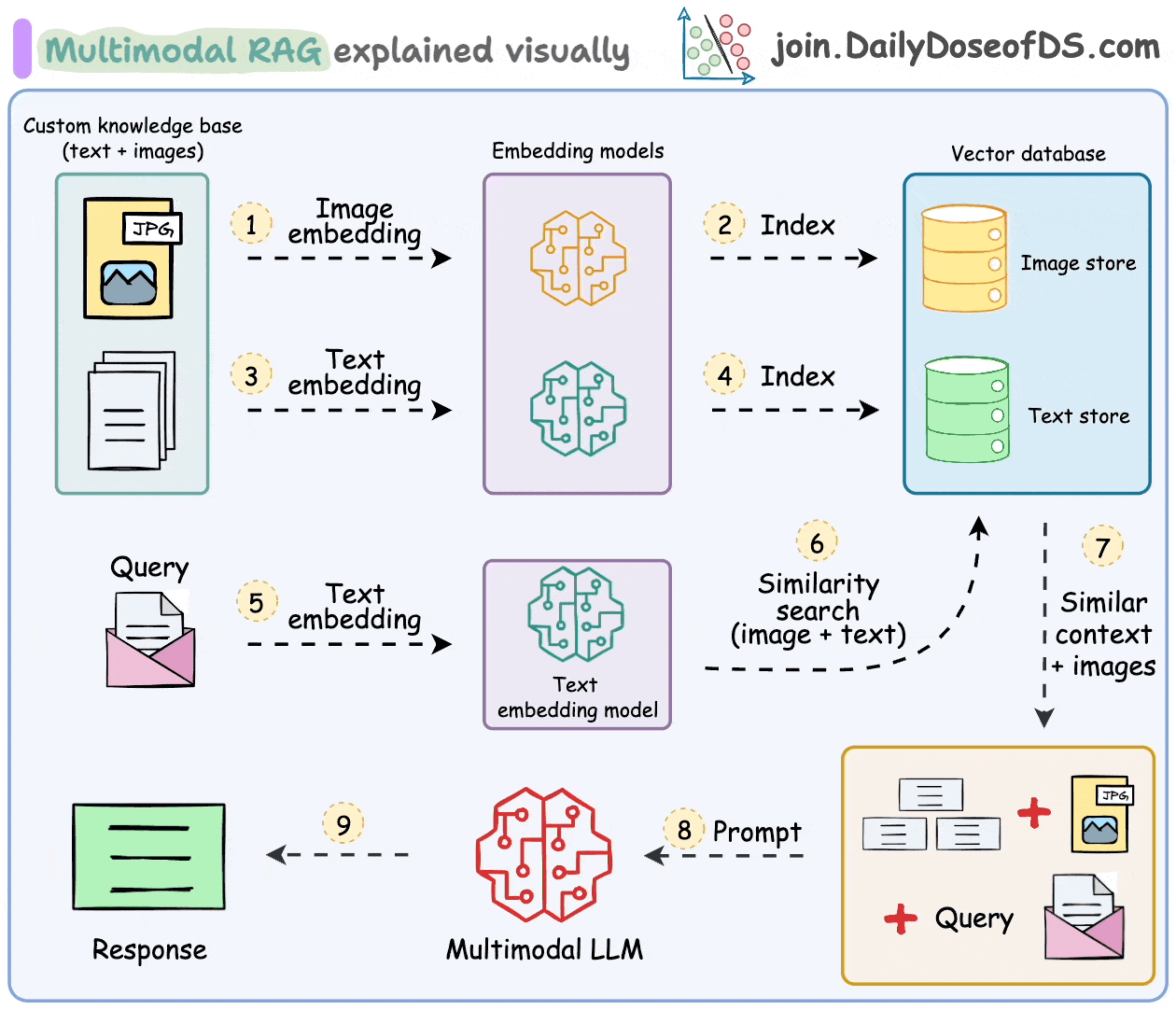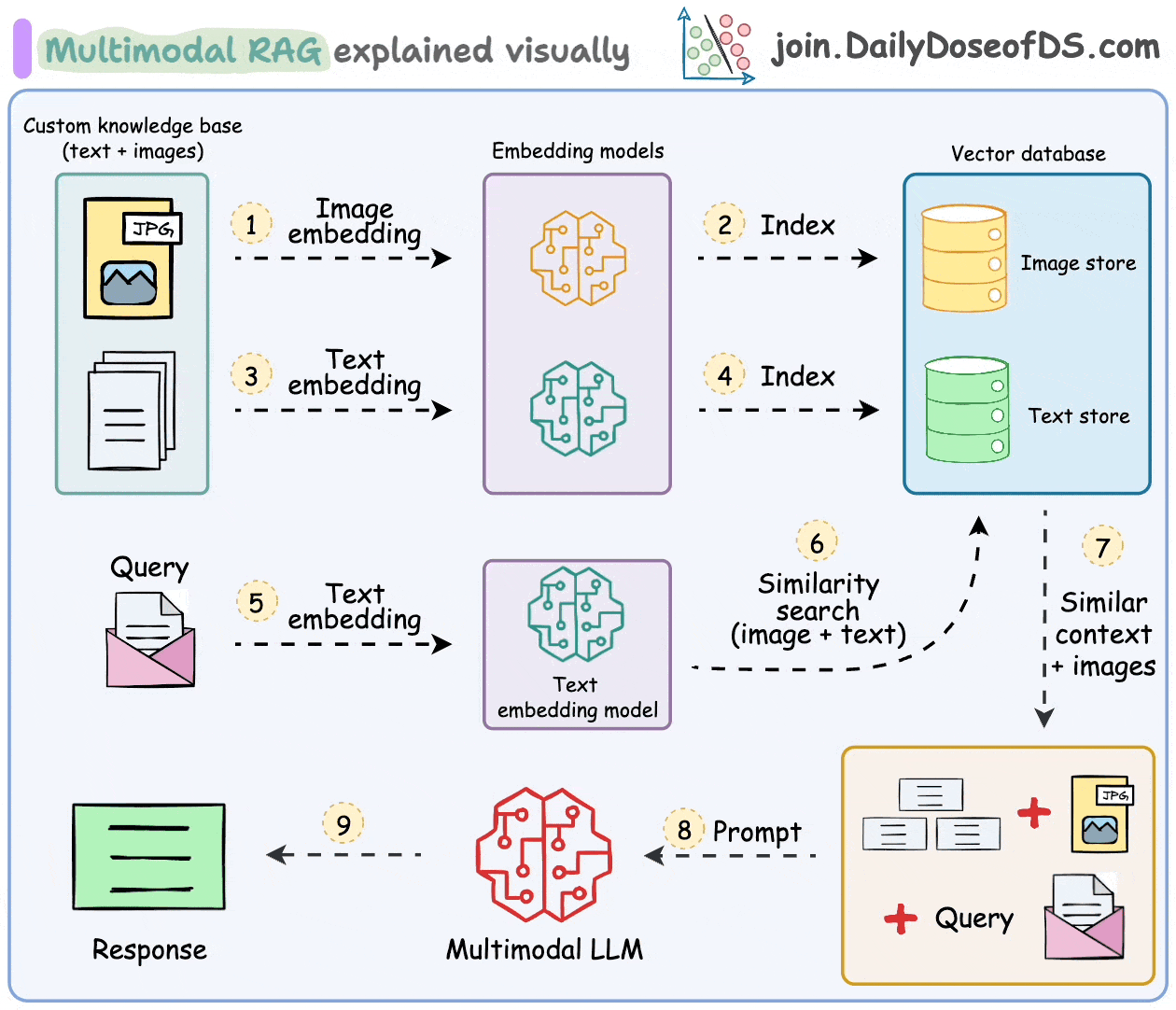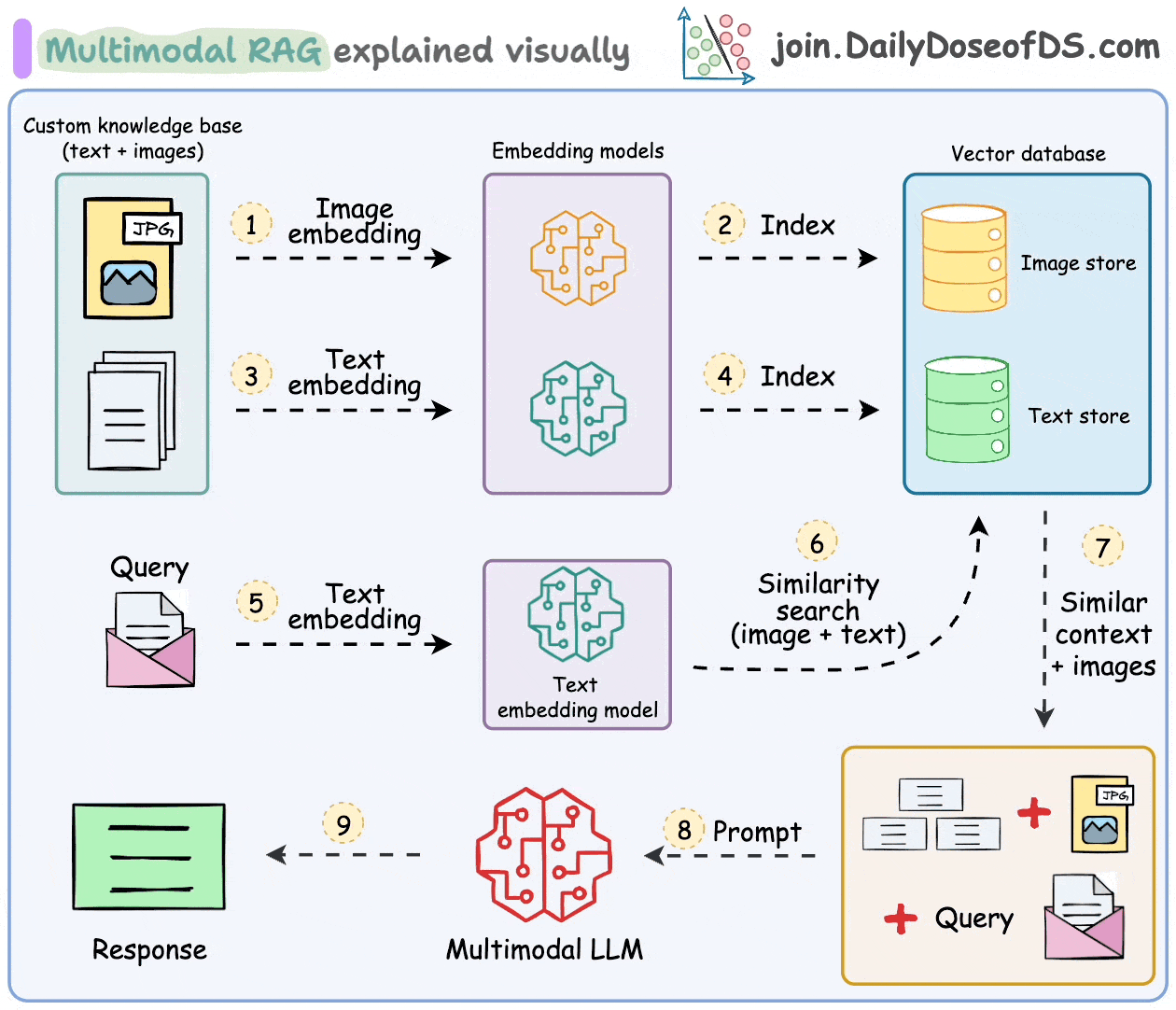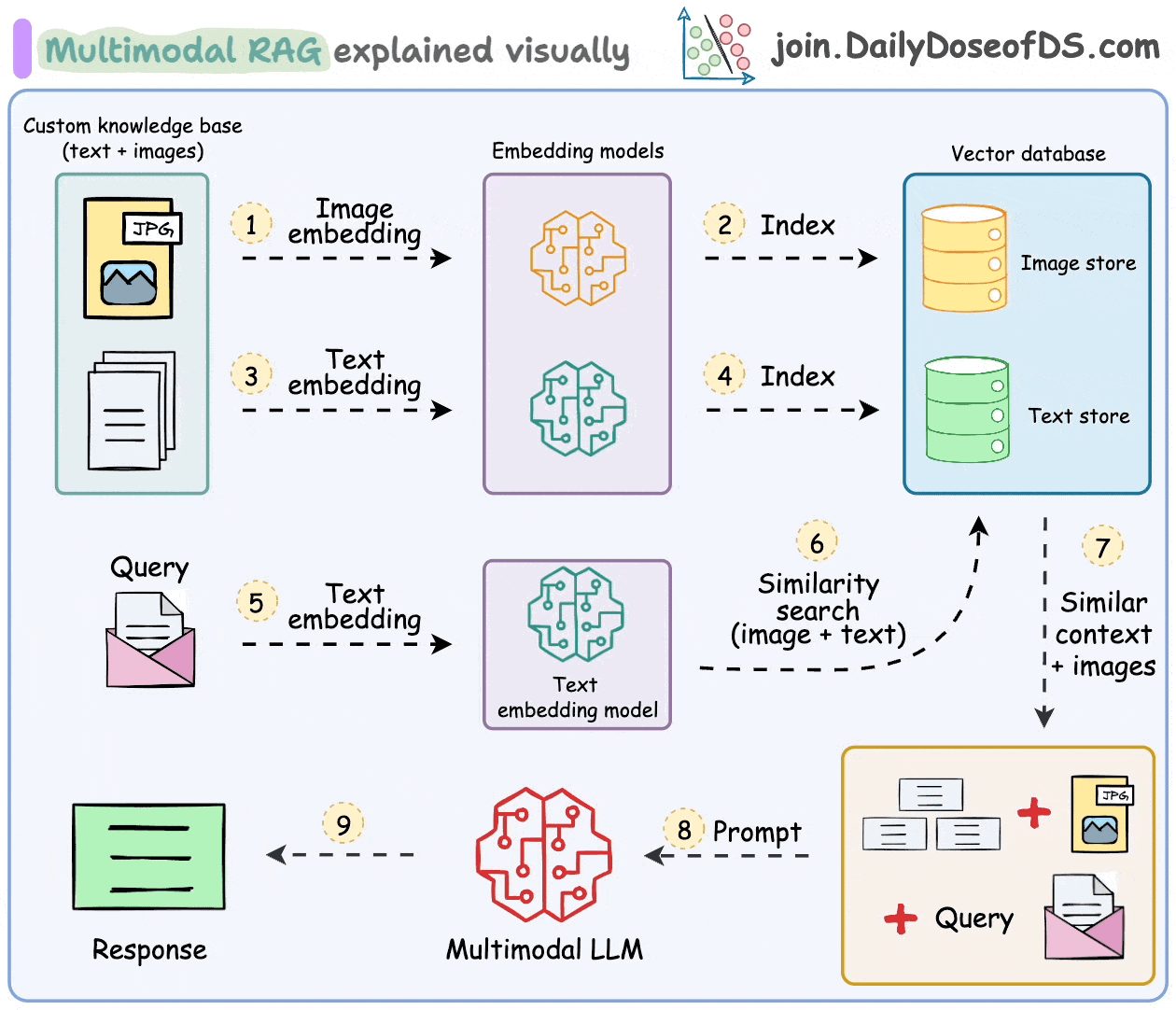
- Gather the dataset of text-image pairs.
- Generate embeddings: Create embeddings for each modality using CLIP for images and transformers for text.
- Store embeddings in a vector database: Use Qdrant to store these multimodal embeddings.
- Retrieve relevant data: Query the vector database to retrieve the most relevant information based on a multimodal input.
- Generate responses: Combine retrieved data to generate coherent and context-aware responses using an LLM.
Dataset preparation
For this demo, we have prepared a special and unique dataset for you.
We have gathered a handful of our posts on social channels (content + image) and gathered them in the following zip file.
Extract it in your current working directory.
The zip file contains:
- JPG Files: Images related to the posts.
- TXT Files: Text content associated with each image.
Each image and text file share the same filename, making it easy to pair them.

Here is a sample:
We'll use this content + image pair dataset to build a multimodal RAG system that can:
- Embed both the images and their corresponding text using CLIP.
- Store these embeddings in a vector database (Qdrant) for efficient retrieval.
- Query the system using either text, image, or a combination of both.
- Generate context-aware responses using an LLM (Llama3.2 Vision via Ollama) that integrates the retrieved multimodal information.
Let's extract this dataset and load it in Python.
First, we gather a list of txt file names and jpg files names as follows:
Printing an entry, we get:
As shown above, the corresponding file names are not identical, so bring them together in a list of dictionaries as follows:
Here's what the structure looks like:

Printing a random text entry of the above documents list and displaying the corresponding image, we get:
Great, we have loaded the dataset.
Now, our next task is to embed it.
Embed dataset
If you remember Part 4 of this RAG crash course, where we discussed multimodal RAG for the first time, here's what we did:
- First, we extracted the details from the document.
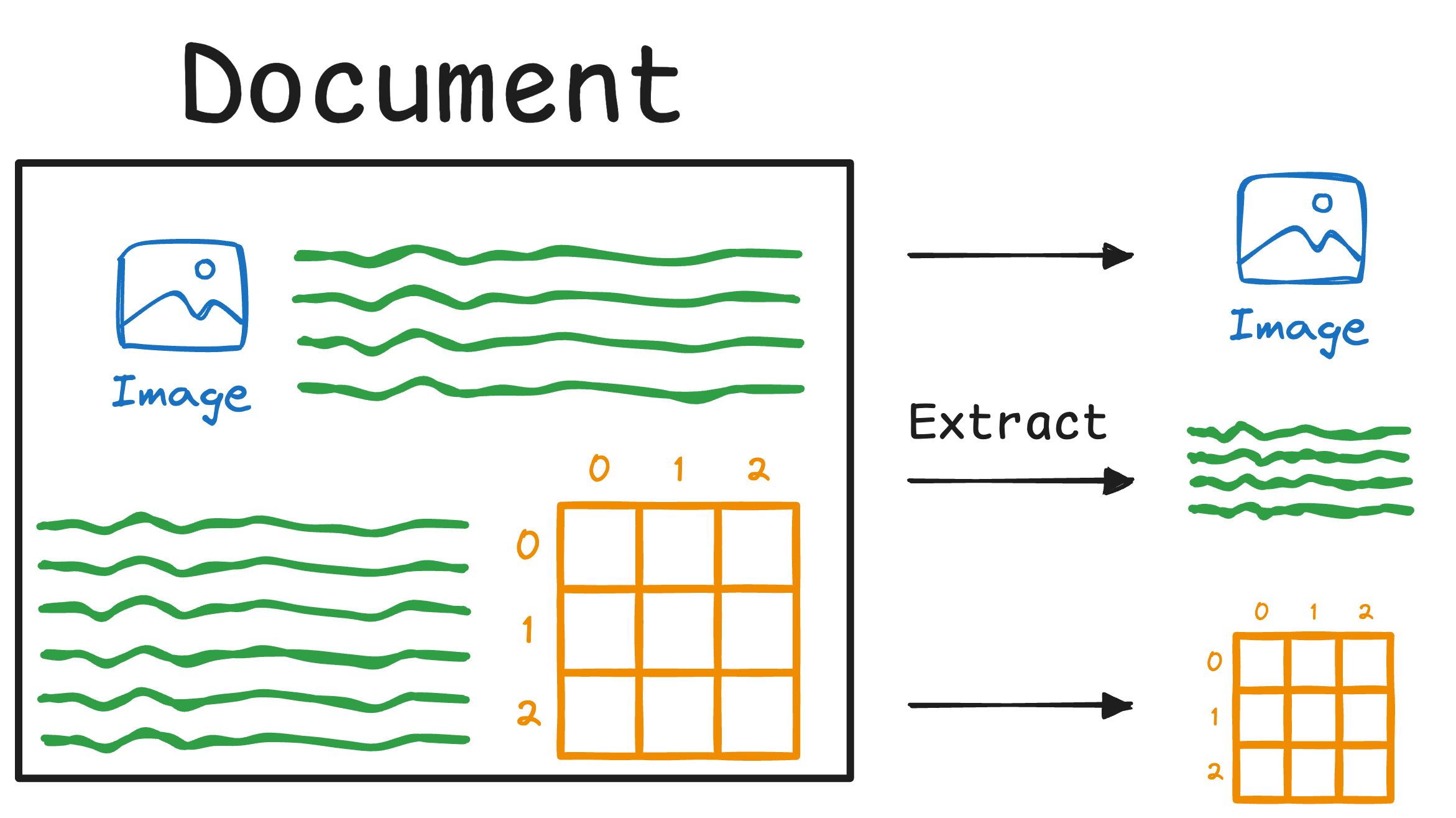
- This produced an array of images, texts, and tables:
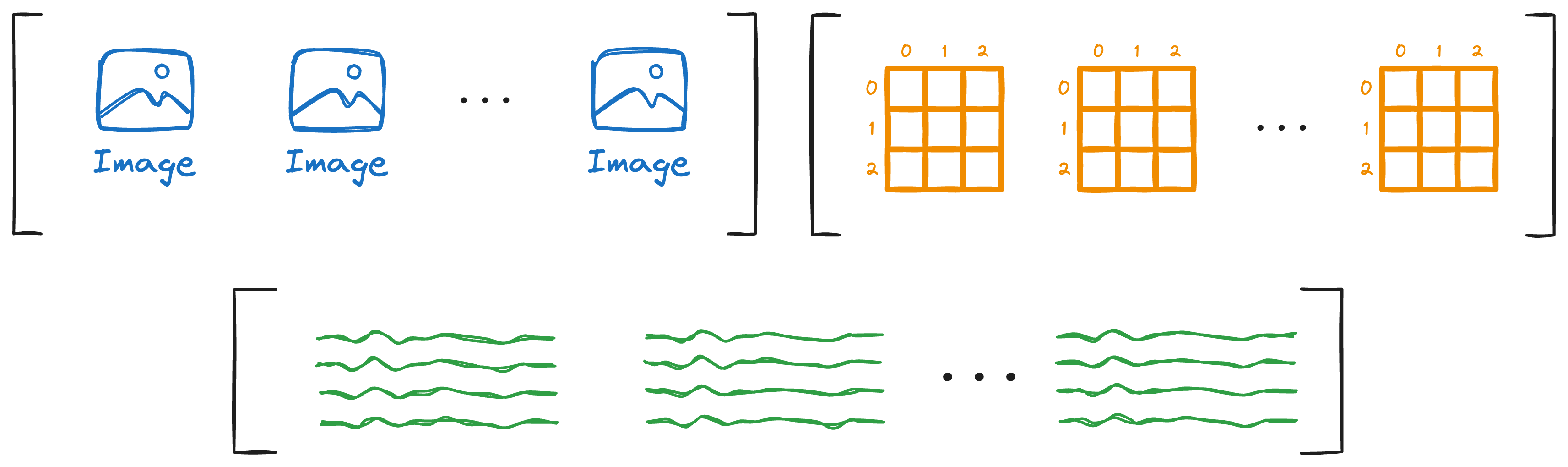
- Once done, our next objective was to figure out how we could store this data as embeddings in a vector database so that we could use it for retrieval.