Reinforcement Learning
How Top AI Labs Are Building RL Agents in 2026
The era of not writing custom reward functions.

Avi Chawla
The era of not writing custom reward functions.
Reinforcement learning, at its core, is straightforward: a system takes an action, the environment rewards it, and the agent updates its behavior to maximize that reward over time.
The interaction above works in discrete steps. At each step, three things happen in order:
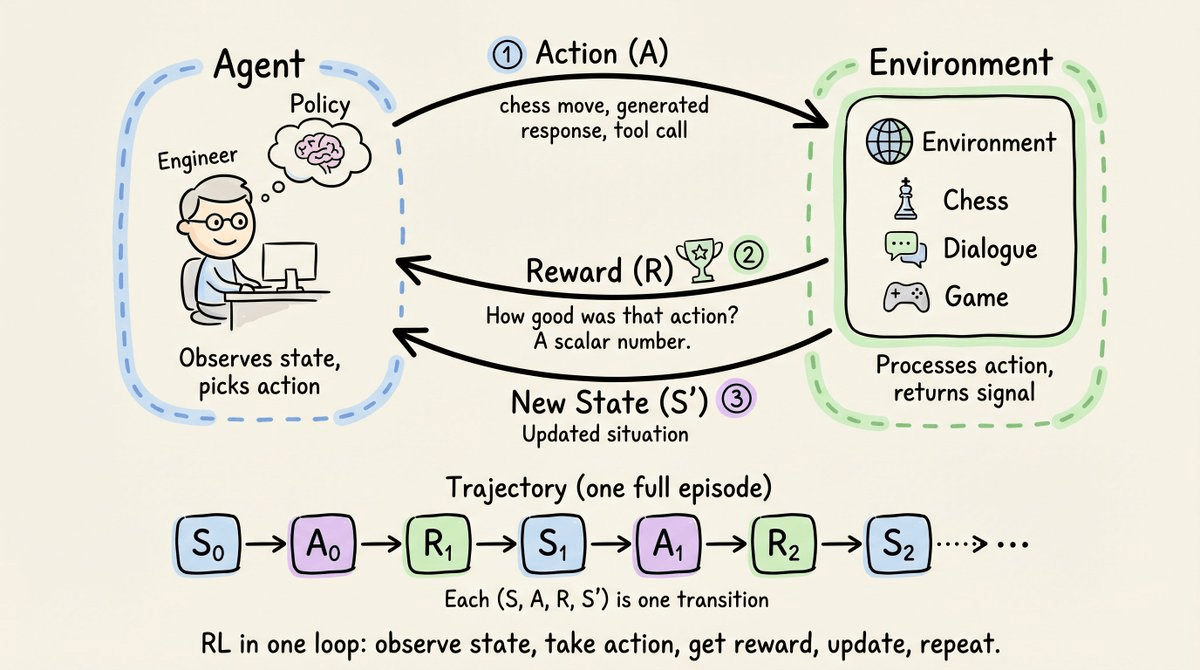
Stringing these steps together gives a trajectory:
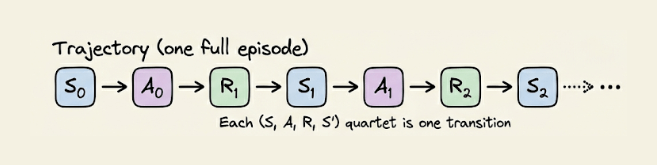
Reading left to right, this is the entire history of the agent’s interaction with the environment. Each (S, A, R, S’) quartet is one transition, and much of RL is about learning from these transitions.
When RL was first applied to LLMs, the environment was human preference.
OpenAI’s InstructGPT (2022) introduced RLHF (Reinforcement Learning from Human Feedback), where:
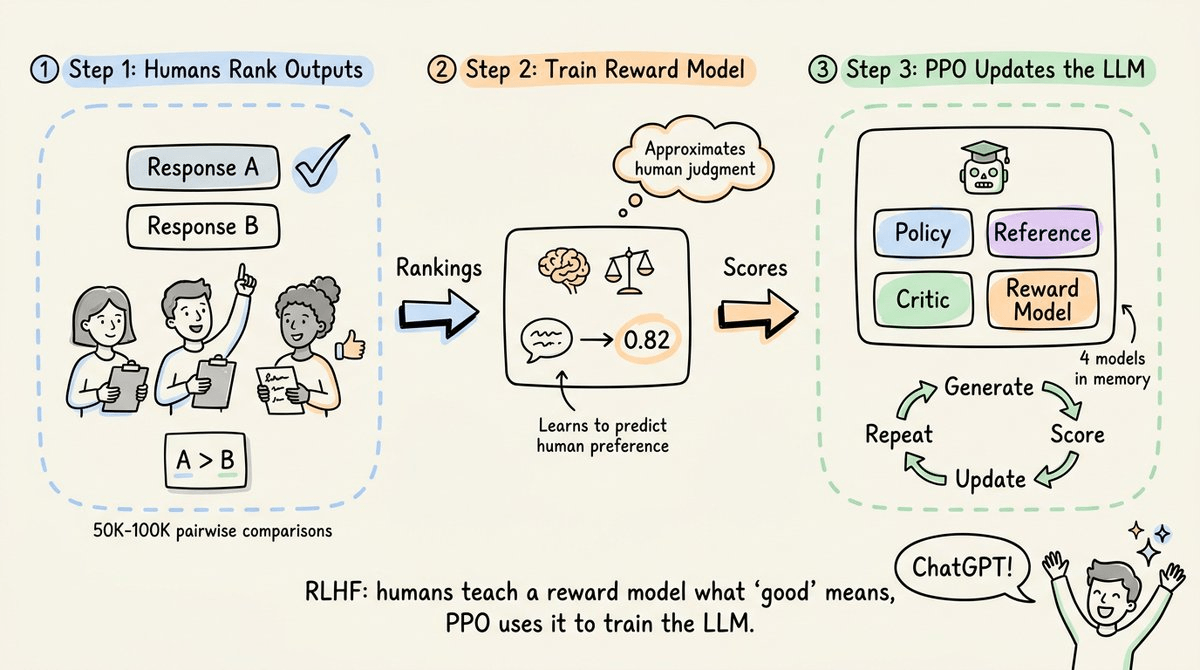
ChatGPT was built on this exact pipeline.
But humans can’t sit in the training loop rating every output in real time. If the model generates 16 responses per prompt across thousands of training steps, that’s hundreds of thousands of evaluations.
OpenAI solved this by splitting the process into two phases.
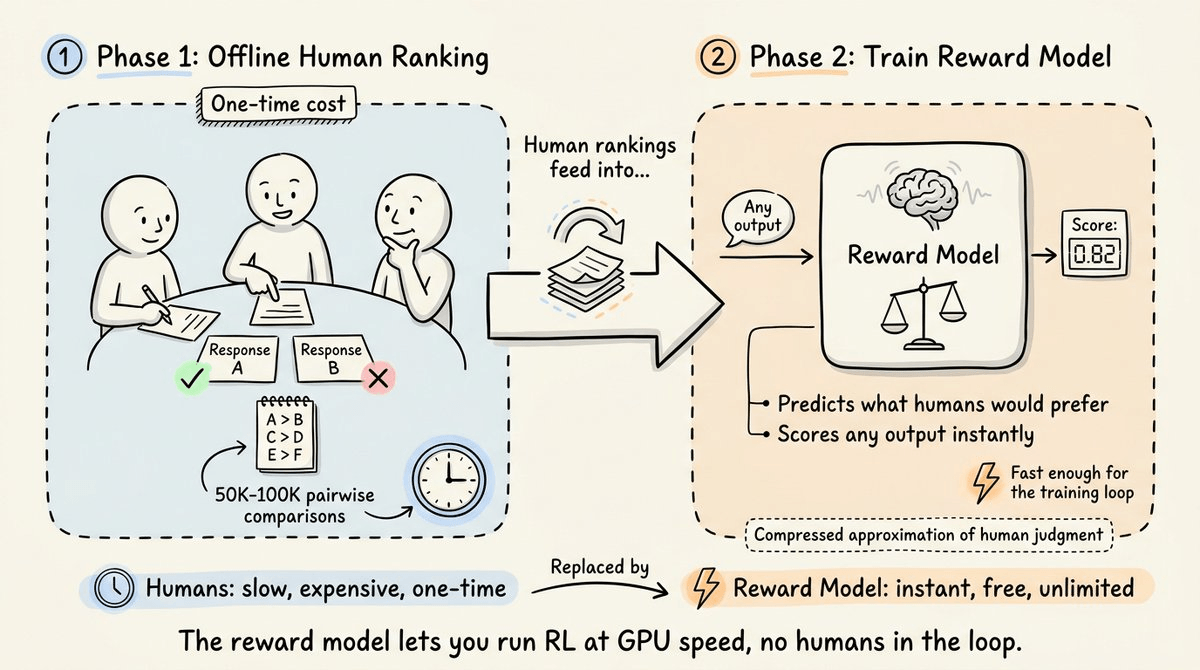
With the reward model in place, PPO could run the actual RL training at GPU speed. The model generated responses, the reward model scored them, and PPO updated the weights, without extensive need for humans.
The cost, however, was that PPO required four full-size models in memory simultaneously.
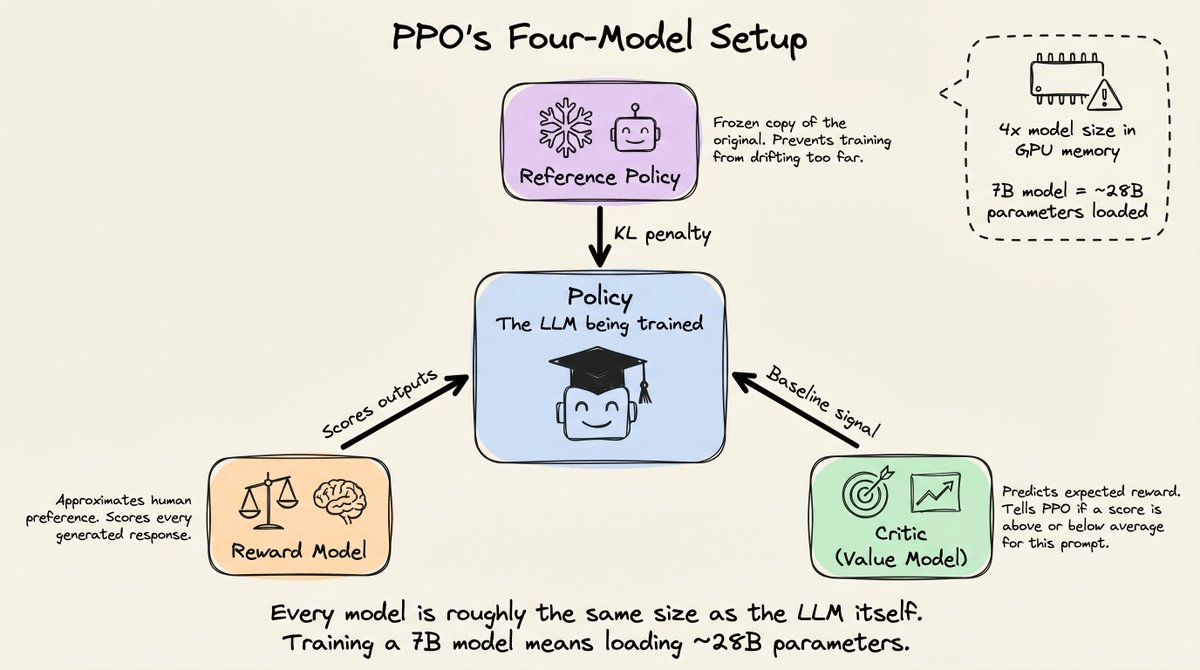
The critic exists to answer one question:
Was this reward good or bad relative to what we’d normally expect for this prompt?
We need this because a raw reward of 0.7 means nothing in isolation. For instance, on a simple factual question where most responses score 0.9, a 0.7 is below average.
But on a complex open-ended question where most responses score 0.4, a 0.7 is excellent.
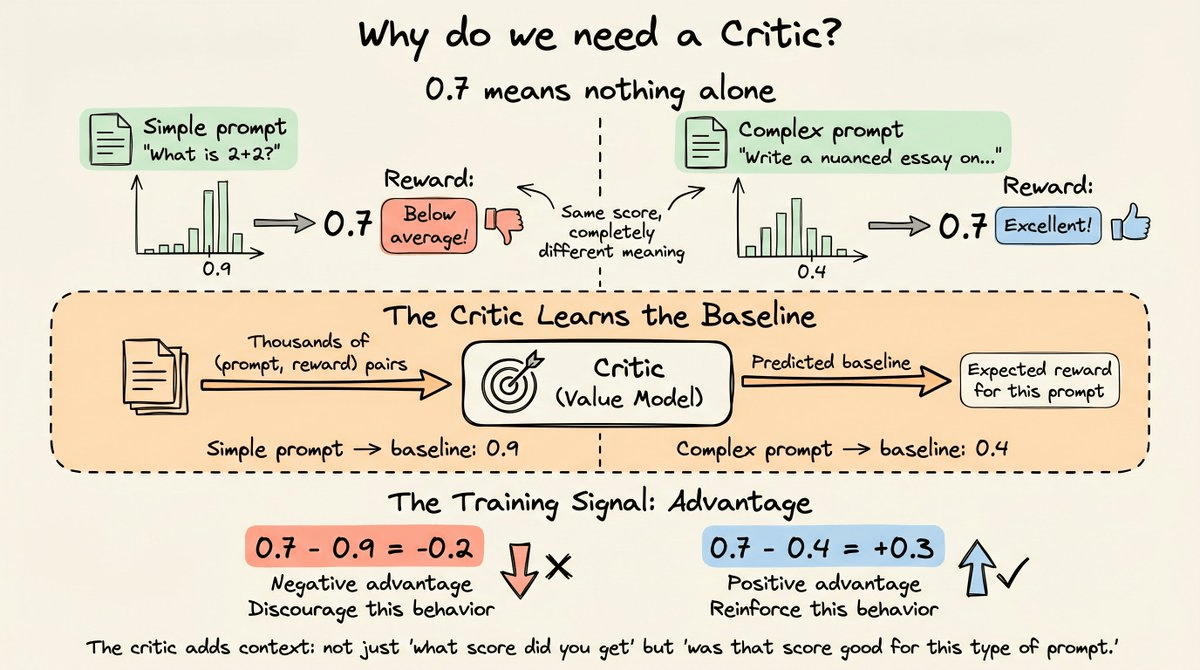
The critic learns this baseline by observing thousands of (prompt, reward) pairs during training.
PPO’s actual training signal is the advantage, which is estimated as the reward minus the critic’s predicted baseline.
This makes the signal stable across prompts of different difficulty. But the cost involved here is that the critic is a full-size LLM itself, adding another model’s worth of memory.
For a 7B parameter LLM, that meant roughly 28B parameters in memory at once.
In January 2025, DeepSeek released R1 with a fundamentally different approach to the reward signal.
Instead of training a reward model from human preferences (Phases 1 and 2 of the RLHF pipeline), they used RLVR (Reinforcement Learning with Verifiable Rewards).
It’s a simple, rule-based verification where the environment itself provides the signal.
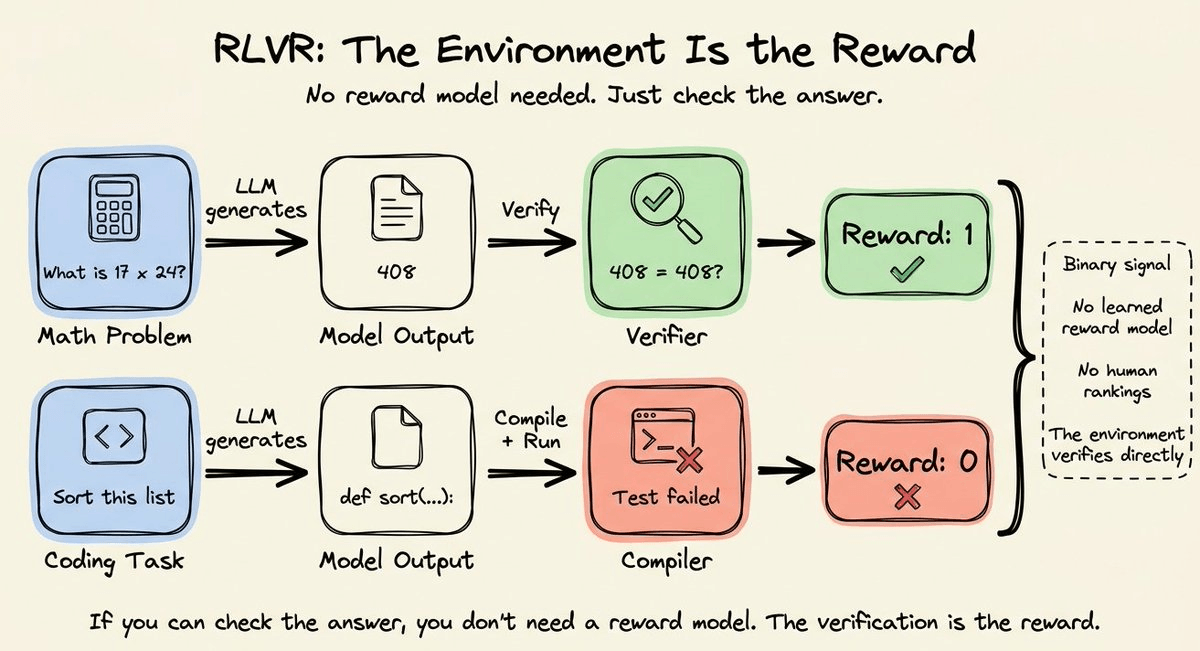
For instance:
There are no human rankings or explicit reward models required since the ground truth was available (or inferable) to be used as the reward.
The RL optimizer was GRPO (Group Relative Policy Optimization), which stripped away most of PPO’s infrastructure.
It removed the critic model entirely.
Instead of training a separate model to predict expected reward per prompt, GRPO generated multiple responses to the same prompt (typically 16) and normalized rewards within each group.
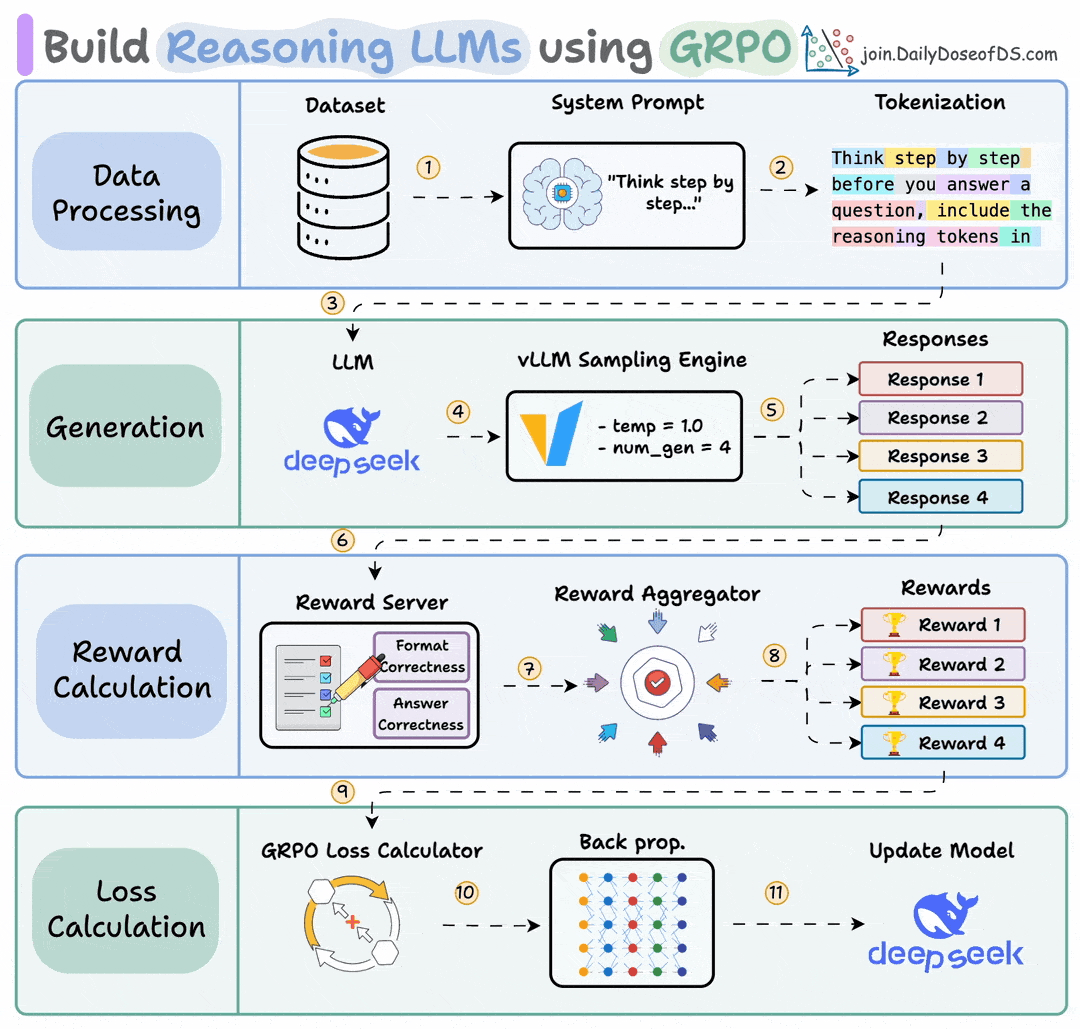
If 4 out of 16 responses got the math problem right, those 4 received a positive advantage, and the other 12 received a negative advantage.
This step cut an entire full-size model from memory.
GRPO also removed the need for the learned reward model, since RLVR’s verifier handled scoring directly.
So the four-model PPO setup (policy + reference + critic + reward model) collapsed to just two, i.e., the policy being trained and a reference copy for KL regularization.
In fact, in practice, some implementations fold the reference into the policy checkpoint, bringing it close to a single-model setup.
With this setup. DeepSeek R1-Zero, trained with just GRPO and verifiable rewards (no supervised fine-tuning at all), went from 15.6% to 77.9% on AIME 2024 math problems.
With majority voting, it hit 86.7%, matching OpenAI’s o1.
The model developed self-verification, reflection, and chain-of-thought reasoning on its own, purely from the binary correct/incorrect signal, and nobody taught it to reason step by step.
The RL training loop discovered that reasoning improved the reward, so the model learned to reason.
RLVR with GRPO became the dominant approach for training reasoning models through 2025.
Every major lab released a reasoning variant following this recipe.
GRPO itself is general-purpose.
It doesn’t care whether the reward comes from a math verifier, a code compiler, a human, or a Python script.
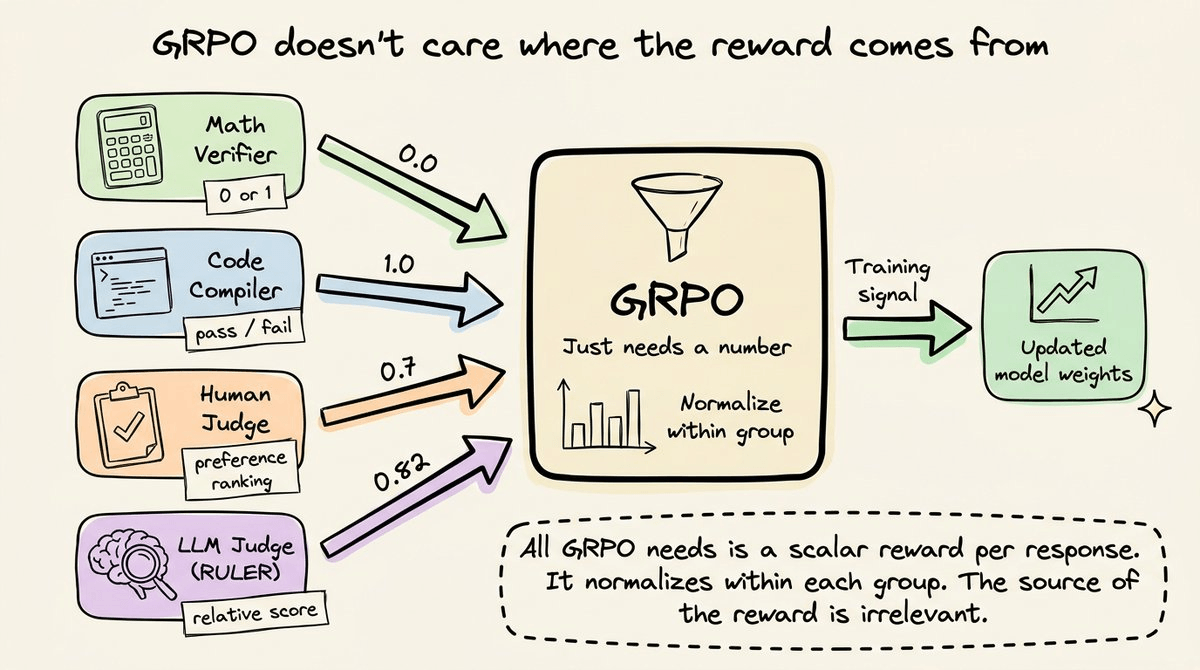
It just needs a number for each response, and it normalizes within each group to produce the training signal.
But a clear bottleneck here is where these reward comes from.
For math and code, this is fine since the environment provides a deterministic signal.
But agents that interact with real-world tools and data don’t produce outputs you can string-match against a gold answer.
A RAG agent retrieves context and generates a response. There’s no single correct answer to compare against. A customer support agent drafts a reply. There’s no compiler to run it through. A summarization agent condenses a 20-page document. There are many valid summaries, and no string-matching verifier can distinguish a good one from a mediocre one.
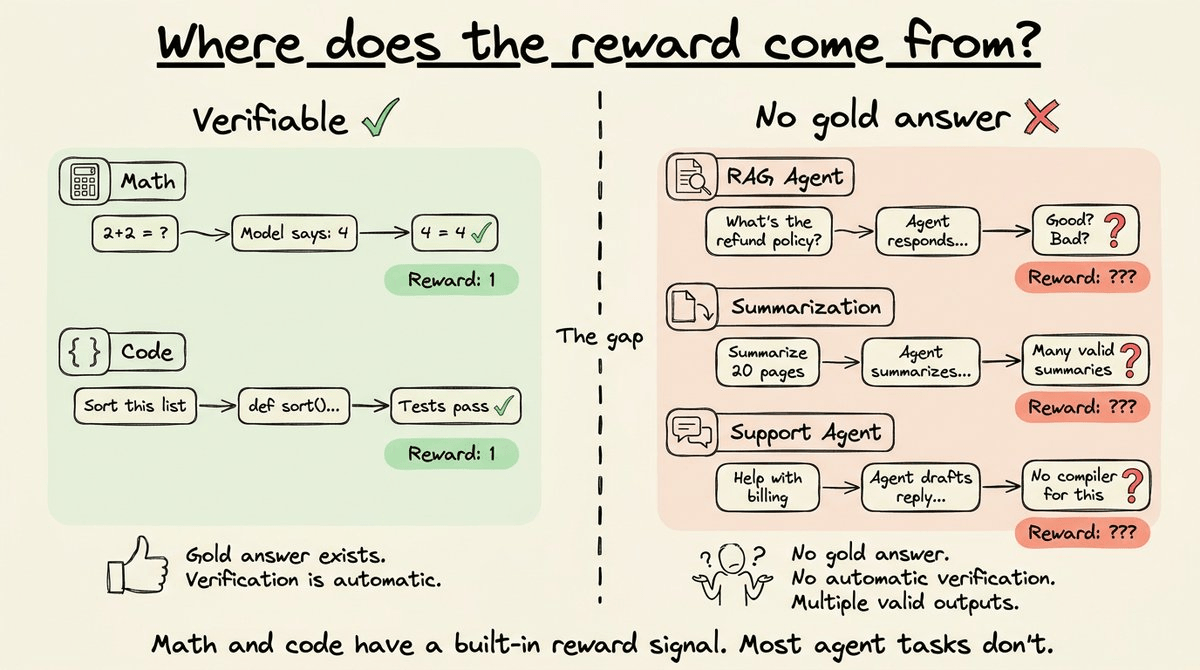
In these cases, the environment doesn’t hand you a reward signal the way a math problem does.
Of course, some agent tasks do have verifiable outcomes, and for these, RLVR works just fine, even with multi-step tool use. The verifiability depends on the task’s outcome, not on whether the model is acting as an agent.
But for the majority of agent workflows, the outcome is subjective or multi-dimensional.
Intuitively, GRPO is still the right fit here because Agents that take multiple steps, call tools, and compose responses would benefit from learning through exploration, trying different approaches, and getting reinforced for what works.
So, while the RL framework is the right fit, the missing piece is the scoring function.
One solution is to write custom reward functions where Python code scores each output based on hand-defined criteria.
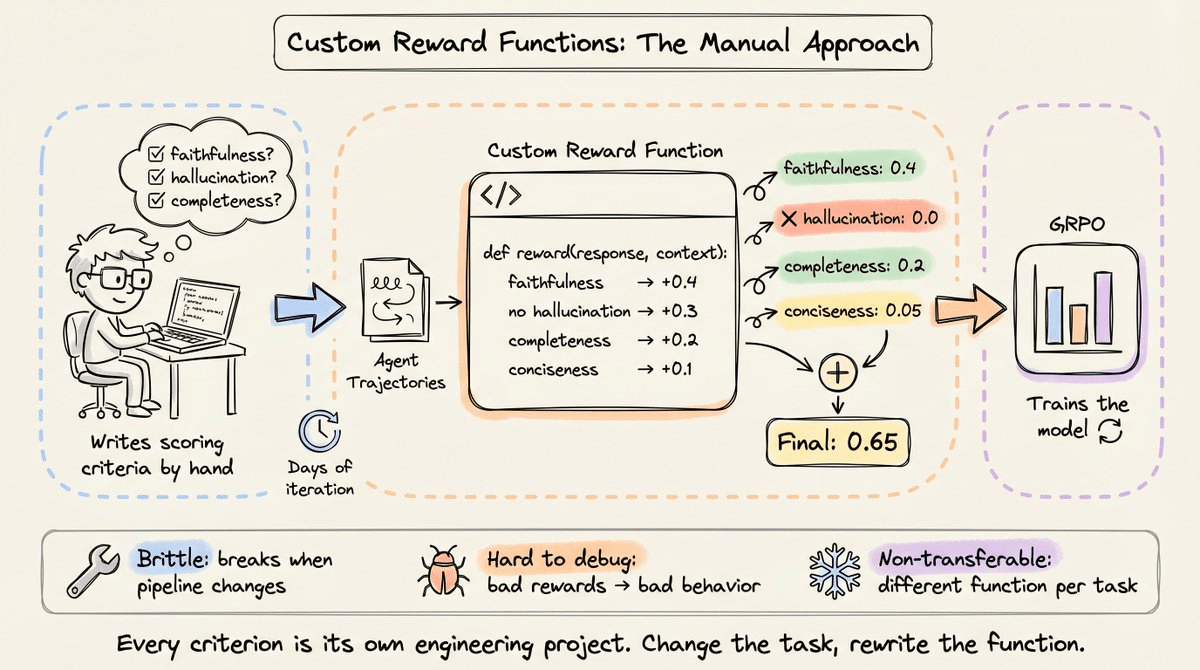
Each criterion returns a partial score, and these get summed or weighted into a final reward.
This works, but it introduces its own set of problems.
Writing a good reward function takes days of iteration. Researchers need to anticipate edge cases, calibrate the weights between different criteria, and test that the function actually rewards the behavior you want.
A reward function that over-weights format compliance and under-weights faithfulness will train an agent that produces beautifully formatted hallucinations.
Reward functions are also brittle. If you change the retrieval pipeline, add a new tool, or modify the system prompt, the reward function needs to be rewritten.
Debugging is problematic too.
When the agent learns bad behavior during training, the cause could be the reward function, the training hyperparameters, the data, or something else entirely.
But because the reward function is custom code, you often can’t tell whether the function is measuring what you think it’s measuring until you’ve already trained a model on it and evaluated the outputs.
This is the primary reason RL has been widely adopted for verifiable tasks (math, code, logic) but not for agent workflows (RAG, customer support, tool use, summarization).
RLVR gave reasoning models a general-purpose, automatic reward signal where they could check the answer and return 0 or 1. No such equivalent exists for most agentic workflows.
The distinction isn’t about the model. The same Qwen 2.5 14B can serve both roles.
The distinction is about the task. Can we verify if an Agent is producing an output that can be automatically checked?
This isn’t a gap that only open-source practitioners are noticing.
The major AI labs have been converging on the same problem from different directions.
Anthropic demonstrated that you don’t need humans in the RL loop at all.
Their Constitutional AI work showed that if you write down a set of principles (a “constitution”), an AI can evaluate outputs against those principles and generate preference data for RL training.
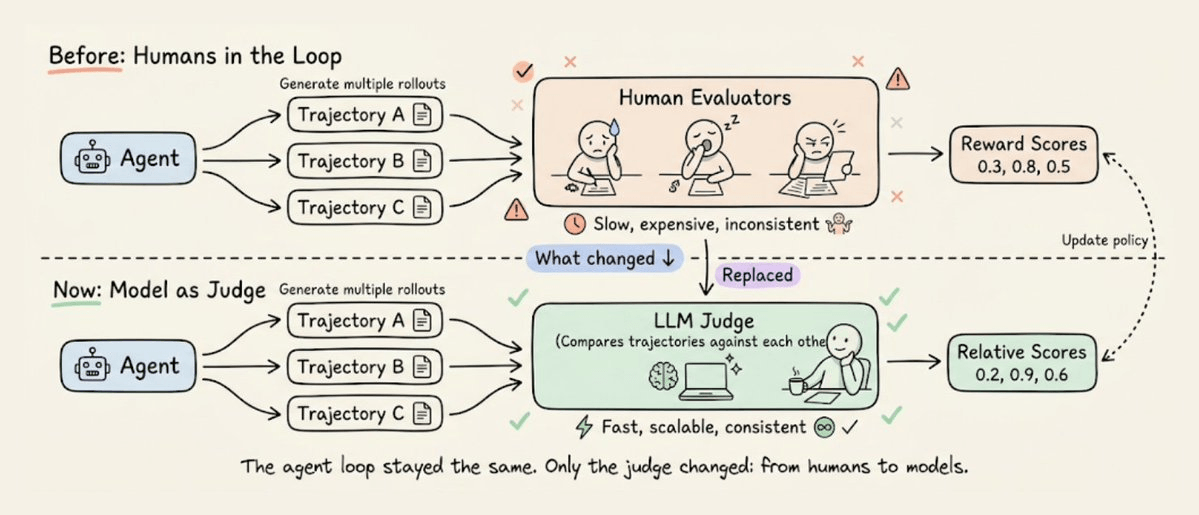
The AI judged its own outputs against the written principles and used those judgments as the RL signal. This was a significant conceptual shift that a document of rules replaced an army of human evaluators.
OpenAI has been working on something similar internally. They are developing “Universal Verifiers,” a technique to extend RL beyond math and code into domains like biology, medicine, and general knowledge, where answers can’t be checked with a simple string match.
The details aren’t public, but the direction is clear that we need general-purpose reward signals that work across any domain, not just the ones with deterministic verifiers.
If you want to see this in practice, RULER, built into OpenPipe’s ART framework (open-source with 9k+ stars) is a general-purpose reward function that replaces all of that custom scoring code with a single function call.
It uses an LLM-as-judge to rank multiple trajectories, and it works by exploiting the same property that makes GRPO powerful, i.e., only relative rankings matter.
Here’s how it works step-by-step:
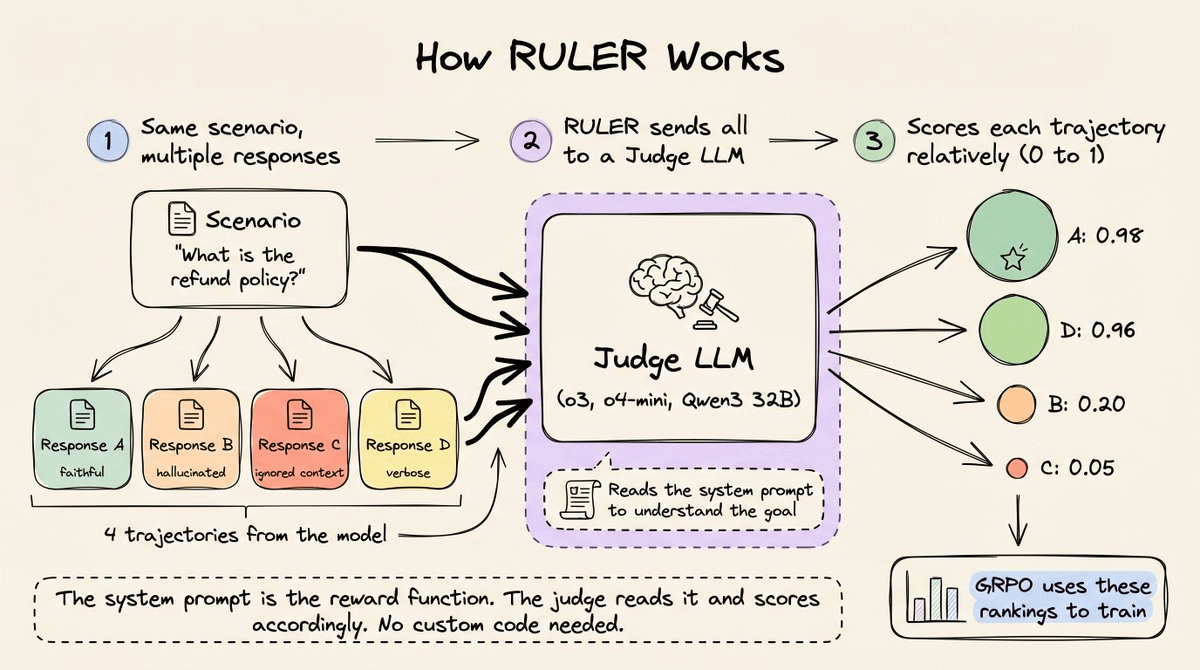
Two properties make this work:
1) Relative scoring is easier than absolute scoring.
LLMs struggle with absolute scoring because there’s no shared calibration.
But asking “which of these 4 responses best follows the system prompt’s instructions” is a comparison task, and LLMs do those consistently well.
RULER leans into this by presenting all trajectories together and asking the judge to rank them against each other.
2) GRPO normalizes within each group anyway.
Whether the best trajectory scored 0.9 or 0.3 in absolute terms doesn’t matter.
GRPO takes the scores within a group, computes the mean and standard deviation, and normalizes.
The training signal comes from the relative ordering by understanding which trajectories were above average and which were below. RULER’s relative rankings map directly onto what GRPO expects.
Before jumping into code, let’s trace what happens conceptually. Say you’re training a RAG agent. At each training step, GRPO generates multiple responses for the same query:
Scenario: "What is the refund policy?"
Retrieved context: "Refunds within 30 days. Digital products non-refundable..."
(Faithful)
Response A: "Refunds within 30 days. Email support@example.com."
(hallucinated)
Response B: "Refunds within 30 days. Also store credit for 90 days."
(ignored context)
Response C: "Not sure, check the website."
(verbose but accurate)
Response D: "The policy states that refunds are available within..."In a traditional setup, you’d write a reward function to score each of these:
def reward_function(response, context):
score = 0.0
if uses_context(response, context):
score += 0.4
if not has_hallucination(response, context):
score += 0.3
if is_complete(response, context):
score += 0.2
if is_concise(response):
score += 0.1
return scoreEach of those helper functions (uses_context, has_hallucination, is_complete, is_concise) is its own engineering project.
You need to define what “uses context” means precisely, decide thresholds, handle edge cases, and test everything.
With RULER, you replace all of that with:
scored_group = await ruler_score_group(group, "openai/o3")The judge LLM reads the system prompt (”Answer using ONLY the retrieved context. Do not add information not in the context.”), reads all four responses and scores them.
The system prompt already defines faithfulness, hallucination, and completeness implicitly. The judge applies those criteria without implementing them in Python.
ART represents each agent response as a Trajectory, and it is a sequence of messages (system, user, assistant) packaged with metadata that GRPO needs for training.
Multiple trajectories for the same scenario form a TrajectoryGroup. This is the unit RULER scores and GRPO trains on.
# A single trajectory: one complete agent interaction
traj = art.Trajectory(
messages_and_choices=[
{"role": "system", "content": "You are a RAG support agent..."},
{"role": "user", "content": "What is the refund policy?\n\n[Context]: ..."},
Choice(finish_reason="stop", index=0,
message=ChatCompletionMessage(role="assistant", content="...")),
],
reward=0.0, # RULER fills this in
)
# A group: multiple trajectories for the same scenario
group = art.TrajectoryGroup([traj_a, traj_b, traj_c, traj_d])
# Score the entire group relatively
judged_group = await ruler_score_group(group, "openai/o3")The reward=0.0 initialization is a placeholder.
ruler_score_group returns, each trajectory’s reward field is updated with the judge’s score.Choice and ChatCompletionMessage objects are OpenAI’s standard types, so if you’re already using the OpenAI SDK for inference, these are the same objects you’re already working with.RULER has two levels of API.
1) The lower-level ruler function works with plain message dictionaries, so no ART-specific objects are needed.
This is the fastest way to see what RULER actually does.
Let’s look at a minimal example with three trajectories for the same RAG query.
Below, we have defined three message lists: one is faithful, one hallucinates, and one ignores the context entirely.
message_lists = [
# Good: uses retrieved context accurately
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "You can get a refund within 30 days of purchase. However, digital products are non-refundable once downloaded. To start the process, email support@example.com."},
],
# Mediocre: partially uses context, adds hallucinated details
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "Our refund policy allows returns within 30 days. You can also get store credit for up to 90 days. Just call our hotline at 1-800-REFUND."},
],
# Bad: ignores context entirely
[
{"role": "system", "content": "You are a RAG-based support agent. Use the retrieved context to answer user queries accurately."},
{"role": "user", "content": "What is our refund policy?\n\n[Retrieved context]: Refunds are available within 30 days of purchase. Digital products are non-refundable after download. Contact support@example.com to initiate."},
{"role": "assistant", "content": "I'm not sure about the refund policy. You should check the website or contact someone from the billing team."},
],
]Next, we run the scoring:
from art.rewards import ruler
scores = await ruler(message_lists, "openai/o3")
for label, score in zip(["Faithful", "Hallucinated", "Ignored context"], scores):
print(label)
print("→", score.score)
print("→", score.explanation)This produces the following output:
Faithful:
→ 0.97
→ Accurately reflects the retrieved policy
details, complete and concise.
Hallucinated:
→ 0.45
→ Gives correct 30-day refund info but adds
unsupported details (90-day credit, hotline),
reducing accuracy.
Ignored context:
→ 0.05
→ Provides no useful information and ignores available context.Notice that we never wrote a faithfulness checker or coded a hallucination detector.
The system prompt mentioned “Use the retrieved context to answer user queries accurately,” and the judge applied that as the evaluation criteria.
The hallucinated response scored 0.45 (not zero) because it partially used the context. The 30-day refund part was correct.
The judge gave partial credit for what it got right and penalized what it invented.
That’s a nuanced distinction that would take significant engineering to encode in a rule-based reward function.
Moreover, the scores are spread across the 0-1 range: 0.97, 0.45, 0.05, unlike binary pass/fail.
RULER produces a gradient that reflects relative quality. GRPO can use this gradient to apply proportional updates to strongly reinforce the faithful behavior, mildly suppress the hallucination pattern (since it was partially correct), and strongly suppress the context-ignoring behavior.
2) The ruler function above works for understanding and experimentation, but ART’s training loop operates on Trajectory and TrajectoryGroup objects.
These carry the reward field that GRPO reads, debug logs for inspection, and the structure that model.train() expects.
After this, the higher-level ruler_score_group function handles the conversion.
Below, let’s look at the same RAG scenario structured the way you’d use it in a real training pipeline, now with 4 trajectories instead of 3.
# The system prompt defines the agent's goal
# RULER uses this as the implicit reward function
system_msg = {
"role": "system",
"content": (
"You are a RAG-based support agent. "
"Answer user queries using ONLY the retrieved context. "
"Do not add information that is not in the context."
),
}
user_msg = {
"role": "user",
"content": (
"What is the refund policy?\n\n"
"[Retrieved context]: Refunds are available within 30 days "
"of purchase. Digital products are non-refundable after "
"download. Contact support@example.com to initiate."
),
}
responses = [
"You can get a refund within 30 days of purchase. Digital products "
"are non-refundable once downloaded. Email support@example.com to start.",
"Refunds are available within 30 days. You can also get store credit "
"for up to 90 days, and our hotline is 1-800-REFUND.",
"I'm not sure about the refund policy. Please check the website or "
"contact the billing team for more details.",
"Based on the information I have, the refund policy states that "
"refunds are available within 30 days of purchase. It is important "
"to note that digital products cannot be refunded after they have "
"been downloaded. If you wish to initiate a refund, you should "
"reach out to support@example.com.",
]Now we have 4 trajectories instead of 3. The fourth is a verbose but accurate response that uses only the retrieved context but wraps it in unnecessary filler words/sentences.
Moving on, we define our Trajectories and Groups as we discussed earlier:
import art
from openai.types.chat.chat_completion import Choice
from openai.types.chat import ChatCompletionMessage
trajectories = []
for resp in responses:
traj = art.Trajectory(
messages_and_choices=[
system_msg, user_msg,
Choice(
finish_reason="stop", index=0,
message=ChatCompletionMessage(role="assistant", content=resp),
),
],
reward=0.0,
)
trajectories.append(traj)
group = art.TrajectoryGroup(trajectories)Finally, we run the scoring:
from art.rewards import ruler_score_group
judged_group = await ruler_score_group(group, "openai/o3", debug=True)With debug=True, RULER prints the judge’s raw reasoning with the actual scores.
This is the raw reasoning:
{
"scores": [
{
"trajectory_id": "1",
"explanation": "Accurately answers the question using only the retrieved context, concisely and completely.",
"score": 0.98
},
{
"trajectory_id": "2",
"explanation": "Includes unsupported details about store credit and a hotline that are not in the retrieved context, so it violates the instruction to use only the context.",
"score": 0.2
},
{
"trajectory_id": "3",
"explanation": "Does not answer the question despite the needed information being present in the retrieved context.",
"score": 0.05
},
{
"trajectory_id": "4",
"explanation": "Accurately and completely answers the question using only the retrieved context, though slightly more verbose than necessary.",
"score": 0.96
}
]
}And these are the scores (ranked):
Rank 1 | Score: 0.980 — Concise, faithful response
Rank 2 | Score: 0.960 — Verbose but accurate response
Rank 3 | Score: 0.200 — Hallucinated store credit and hotline
Rank 4 | Score: 0.050 — Ignored the retrieved context entirelyIf you notice closely...
These scored trajectories are exactly what model.train() expects, so let’s look at that ahead.
To actually train with these scores, you replace the hardcoded responses with real model inference.
ART’s gather_trajectory_groups handles the orchestration.
Essentially, for each scenario, it generates a group of trajectories using the model’s current weights, scores them with RULER, and collects the results for GRPO:
for step in range(num_steps):
groups = await art.gather_trajectory_groups(
(
art.TrajectoryGroup(
rollout(model, scenario) for _ in range(4)
)
for scenario in scenarios
),
after_each=lambda g: ruler_score_group(
g, "openai/o3"),
)
await model.train(groups) # GRPO updates LoRA weightsIn every step, the model generates 4 responses per scenario using its current weights, RULER ranks them relatively, and GRPO reinforces the high-scoring behavior while suppressing the low-scoring behavior.
The agent gets better at following the system prompt’s instructions with every iteration.
Over multiple steps, the model learns the patterns that score well (faithfulness, conciseness, grounding in context) and unlearns the patterns that score poorly (hallucination, ignoring context, verbosity).
And notice that no reward function was defined anywhere in this code.
For most tasks, the system prompt provides enough signal for RULER to score effectively. But when you need more specific evaluation criteria, RULER supports custom rubrics:
custom_rubric = """
- Prioritize responses that are concise and clear
- Penalize responses that include emojis or informal language
- Reward responses that cite sources
"""
await ruler_score_group(group, "openai/o3", rubric=custom_rubric)The rubric is natural language, not Python, so iterating on it is fast.
You just change a sentence, rerun, and check the scores.
Compare this to editing a reward function where a misplaced weight or a buggy condition can silently teach the agent bad behavior that you won’t notice until after training.
RULER is general-purpose. It works on any task, not just freeform ones where custom rewards are painful.
The practical question is when RULER adds value over simpler alternatives.
For purely deterministic tasks (did the SQL query return the right rows?), a binary verifier is cheaper and gives a cleaner signal.
For purely subjective tasks (was the summary good?), RULER is the only automatic option. For tasks that sit in between (did the agent find the right answer AND explain it well?), you can combine both:
judged_group = await ruler_score_group(group, "openai/o3")
for traj in judged_group.trajectories:
independent_reward = verify_correctness(traj) # binary 0/1
traj.reward += independent_rewardRULER preserves any rewards you assign during rollout under a separate metric, so you can layer LLM-judge scoring on top of deterministic verification without losing either signal.
Here are some practical insights we have gathered based on using RULER:
The bottleneck in applying RL to agents was never the optimization algorithm.
GRPO handles that well.
It was always the reward signal.
RLVR solved this for verifiable tasks by letting the environment score outputs directly.
RULER solves it for every task (verifiable or non-verifiable) by letting an LLM judge score outputs relatively.
The full implementation is in the ART repository, along with Colab notebooks that walk you through the training loop end-to-end.
Repo: https://github.com/OpenPipe/ART (don’t forget to star it ⭐️)
Thanks for reading!