Memory
[Hands-on] Agent memory is only as good as its schema
A deep dive on building production-grade memory for Agents.

Avi Chawla
A deep dive on building production-grade memory for Agents.
When you give an agent a knowledge graph for memory, the default behavior is that the LLM handling extraction decides the structure on its own.
It picks the entity types, the relationship labels, and the attributes.
The results are generic.
Everything becomes a Topic or Object and every connection is labeled RELATES_TO, resulting in a graph that can’t be queried meaningfully.
Zep’s Graphiti (open-source with 26k+ GitHub stars) fixes this with a prescribed ontology.

You can define entity types and edge types as Pydantic models, and the extraction model classifies against these definitions instead of guessing.
Let’s look at why this matters, how the extraction pipeline works, with code!
Vector-based memory stores facts as text chunks and retrieves them by semantic similarity. That works until a query requires connecting facts that don’t appear in the same chunk.
Consider three facts stored about a project.
A query like “was Alice’s project affected by Tuesday’s outage” needs all three.
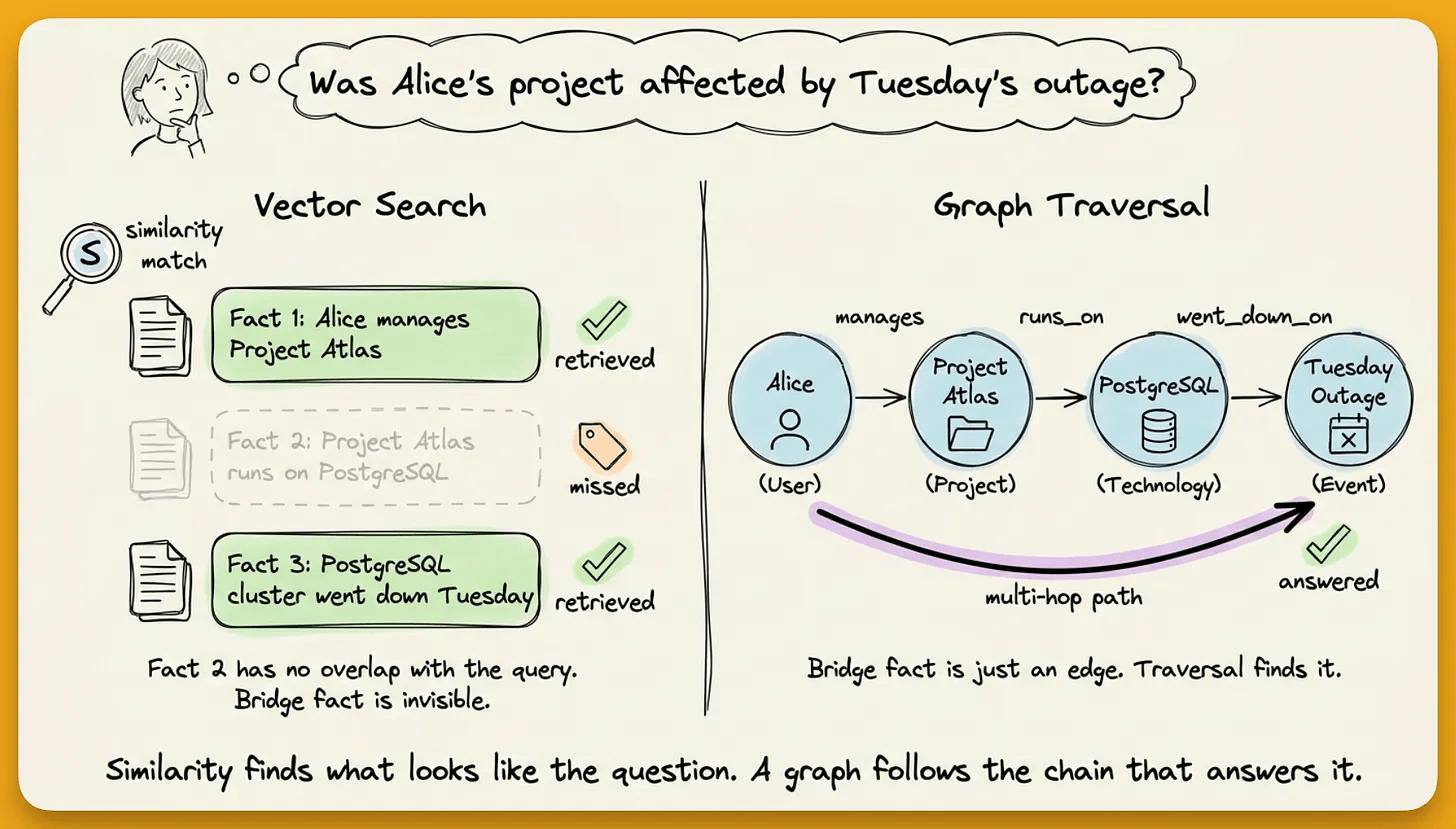
Vector search will retrieve just facts 1 and 3 because both mention relevant terms. Fact 2 is the bridge connecting Alice to PostgreSQL through Project Atlas, but it mentions neither Alice nor Tuesday. Similarity search misses it.
A knowledge graph stores entities as nodes and relationships as edges. Instead of matching text, it traverses connections.
That chain (Alice → manages → Project Atlas → runs on → PostgreSQL) is what makes multi-hop reasoning work, and it is invisible to flat vector retrieval.
Every graph-based memory system follows the same pipeline. LLM accepts the raw data and extracts entities and relationships.
These get stored as nodes and edges, and at query time, the system searches the graph and injects relevant facts into the agent’s prompt.
The extraction step determines everything downstream. It decides what the graph contains, how it’s structured, and what can be queried.
When extraction is unstructured, the LLM picks entity types and relationship labels on its own.
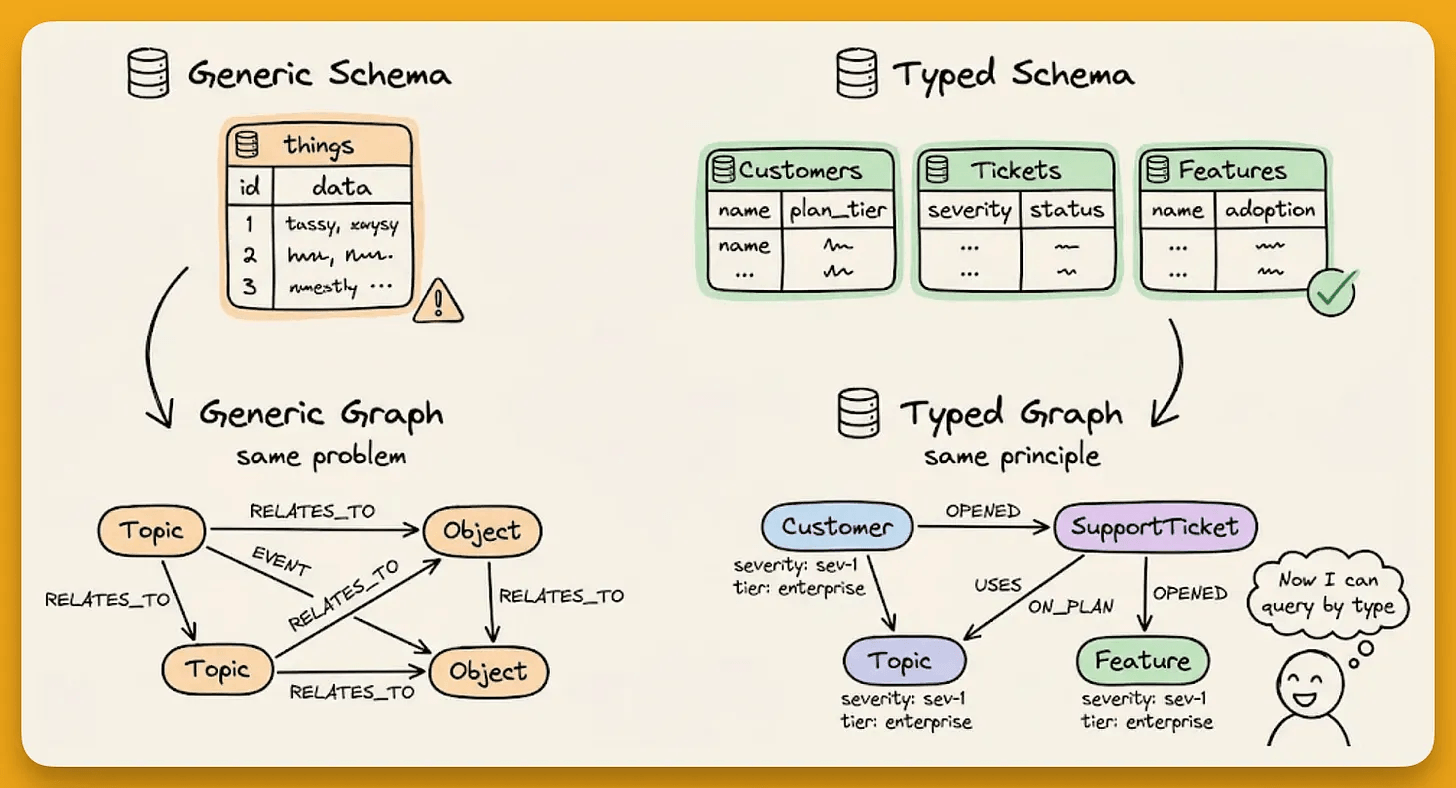
A developer conversation about building a web app called Nexus with Python, TypeScript, React, and Docker produces nodes labeled Topic and Object with RELATES_TO edges across the board.
Two things break without proper structure:
status or category to distinguish “active vs. completed” or “frontend framework vs. database.”The fix is the same pattern used everywhere in the AI stack.
Define custom entity types using EntityModel (a subclass of Pydantic’s BaseModel) with EntityText fields and descriptions that guide the extraction model.
The docstrings and field descriptions are important here because good descriptions with concrete examples give the extractor enough signal to classify accurately.
The Pydantic descriptions above aren’t just classification instructions. They teach the extractor vocabulary it doesn’t know.
A Technology entity follows the same pattern.
Edge types use EdgeModel and carry their own attributes.
Finally, wire these into the graph with source/target constraints using EntityEdgeSourceTarget, which defines which entity types can connect through which edge types:
The code enforces that:
WORKS_ON can only connect a User to a ProjectUSES_TECHNOLOGY can only connect a User to a Technology.When a conversation is ingested with a schema, Zep’s extraction pipeline runs through five steps:
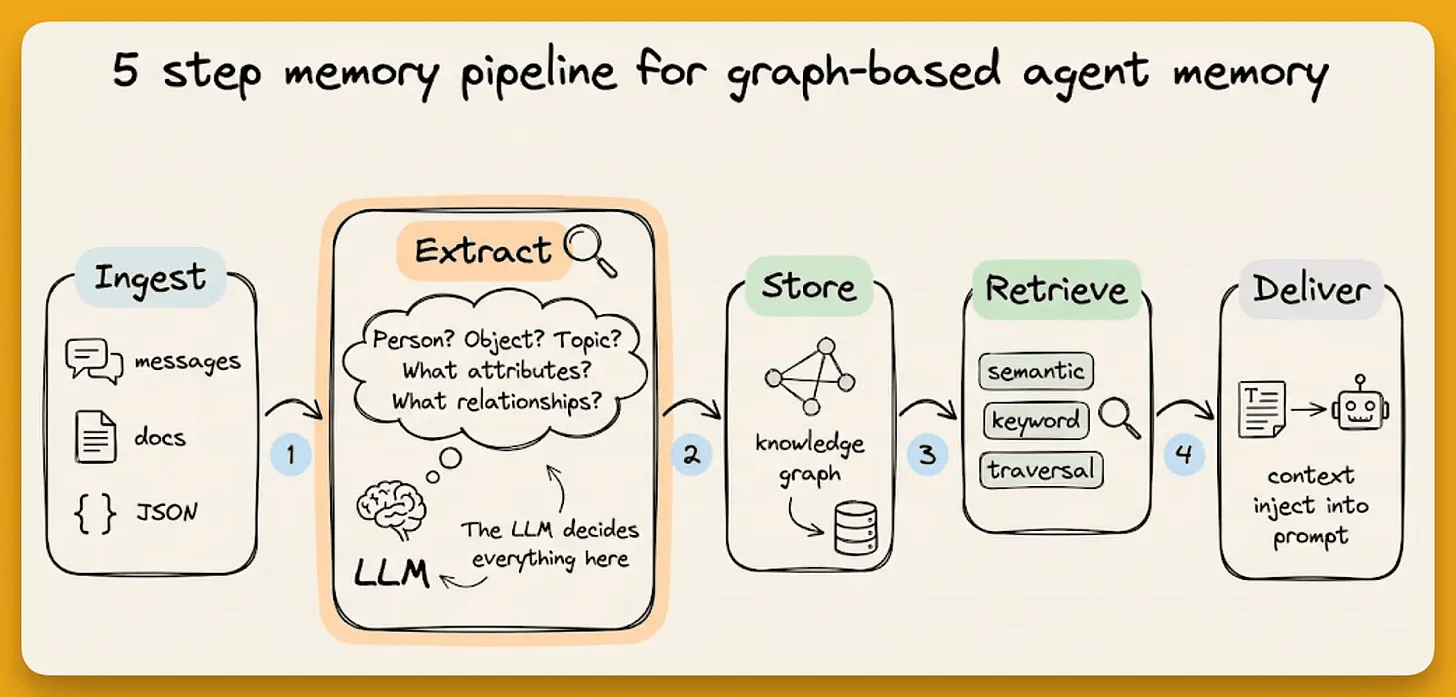
The Pydantic schema defined above guides steps 1 and 3.
Entity types tell the extractor what to look for. Edge types with their constraints tell it what relationships to classify. Resolution and temporal processing happen automatically.
Every edge also carries explicit validity intervals (t_valid, t_invalid). When information changes (”Alex moved from Project Atlas to Project Nexus”), the old fact is invalidated, not deleted.
This way, you can query what’s true now as well as reconstruct what the state would have been at any point in time.
We ingest a conversation where a developer named Alex discusses their work (an active web app called Nexus, their tech stack, proficiency levels):
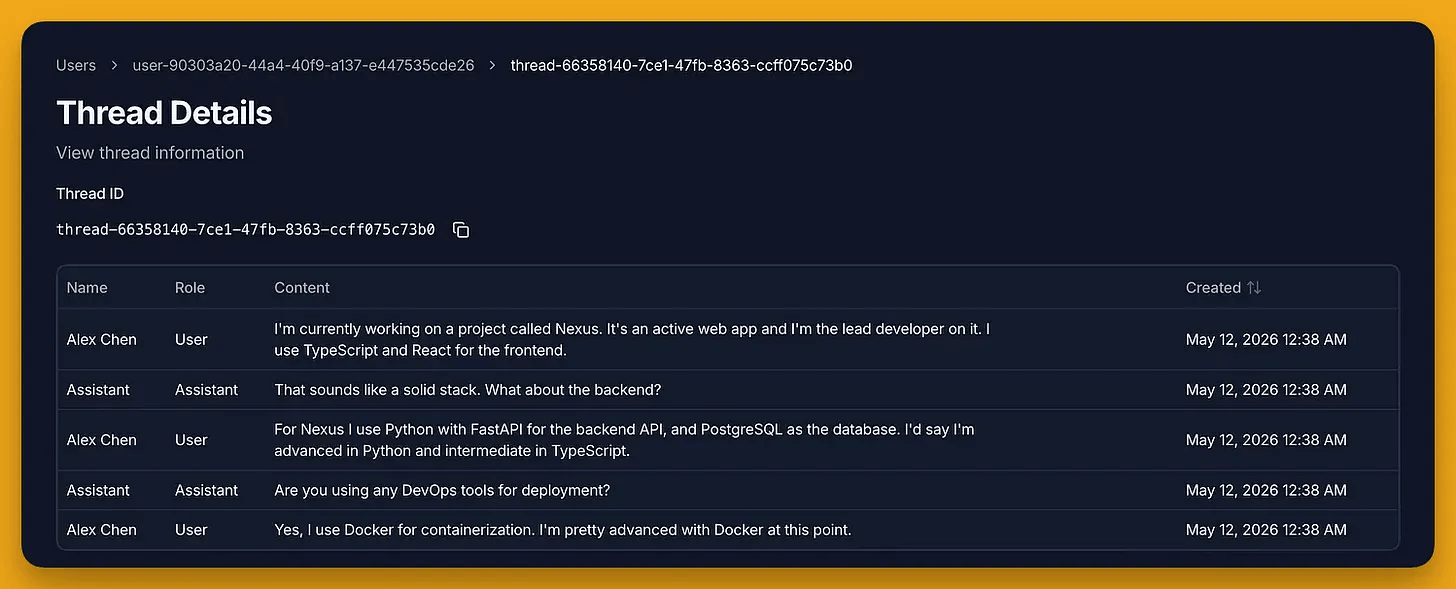
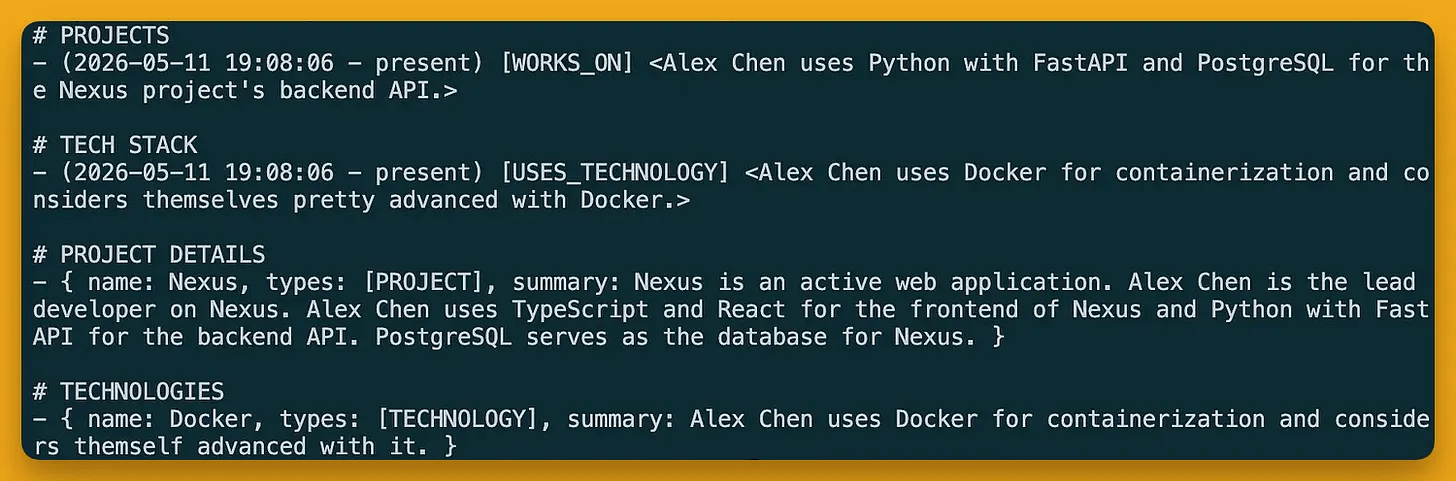
Querying for Project nodes returns Nexus with populated project_status and project_type attributes.

The node isn’t a generic “Topic” or “Object.” It’s a Project with structured fields as defined in the schema.
The edges are typed too.
WORKS_ON carries role: lead developer
USES_TECHNOLOGY carries proficiency: advanced for Python and Docker, proficiency: intermediate for TypeScript.
This can now filter projects by status, technologies by category, and query “which active projects use PostgreSQL” with a precise answer.
The final piece is context templates, which assemble typed facts into a prompt-ready block.
You can define which edge types and entity types to include, and Zep formats them with temporal annotations into a single string injected into the agent’s prompt.
It looks like this:
Every entry in the resulting context block is typed, temporally annotated, and carries the attributes defined. Save the template once, reference it by ID in agent calls.
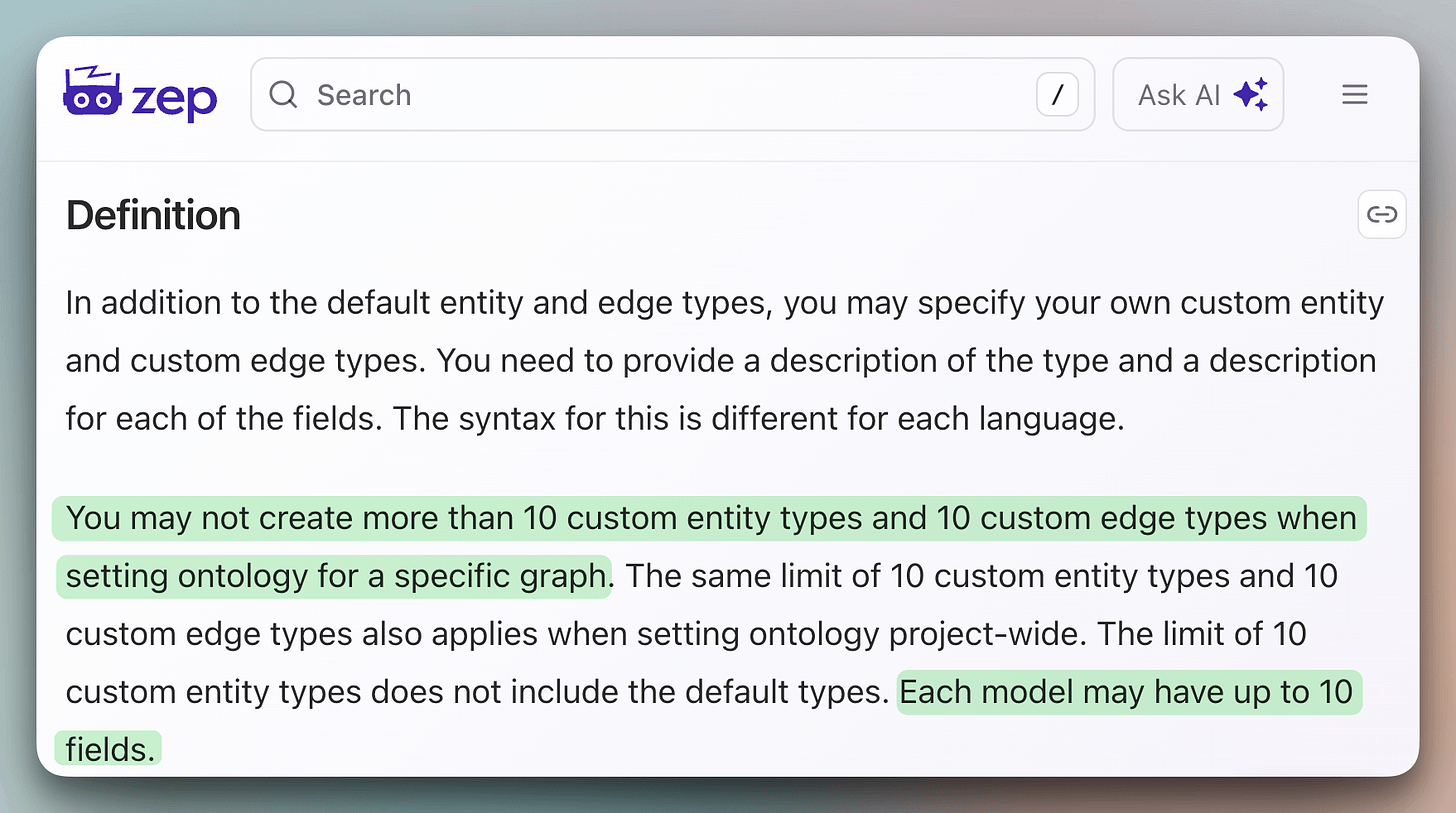
Zep enforces a hard limit of 10 custom entity types, 10 custom edge types, and 10 fields per type.
That’s intentional to force a dev to think about what matters in a domain rather than modeling everything.
The source/target constraints also act as guardrails on what an agent is allowed to remember. If a schema doesn’t include an edge type connecting Project to Competitor, the extraction model won’t create that relationship, even if a conversation mentions both.
The schema defines the space of valid memories.
This is the same principle behind typed function calling, where we constrain the LLM’s output space so that it can’t produce invalid arguments. Memory schemas apply that same constraint to what the agent stores.
Start with 3-4 entity types and 3-4 edge types that capture 80% of your domain logic, and add complexity incrementally.
Agent memory without schema discipline is a graph that behaves like a vector store.
In a way, you pay the cost of graph construction without getting the benefit of structured retrieval.
The schema is how you get that benefit back, and the fact that it’s Pydantic means there’s nothing new to learn.
You can find Zep’s GitHub repo here → (don’t forget to star 🌟)
Thanks for reading!