LLMs
3 Prompting Techniques for Reasoning in LLMs
...explained with visuals.

Avi Chawla
...explained with visuals.
A large part of what makes LLM apps so powerful isn't just their ability to predict the next token accurately, but their ability to reason through it.
And that's not unique to code. It’s the same when we prompt LLMs to solve complex reasoning tasks like math, logic, or multi-step problems.
Today, let’s look at three popular prompting techniques that help LLMs think more clearly before they answer.
These are depicted below:
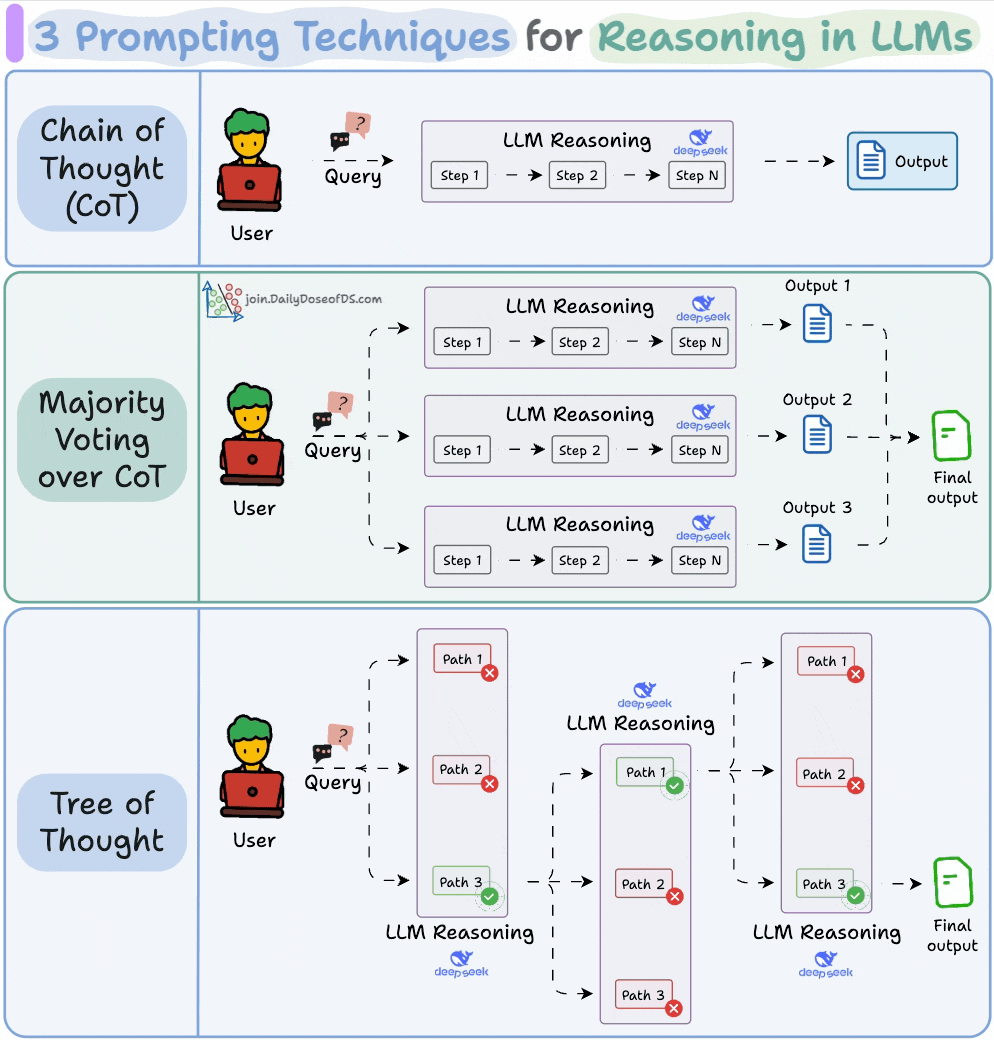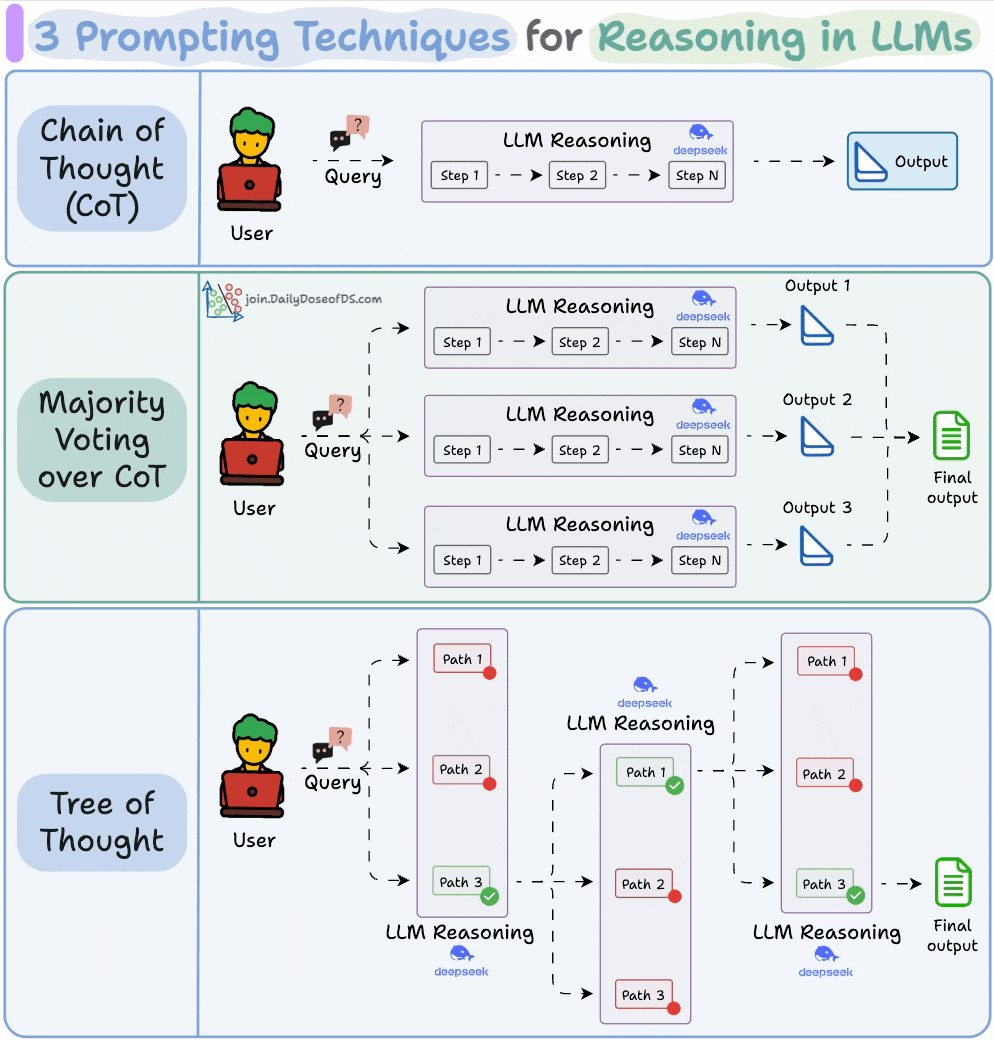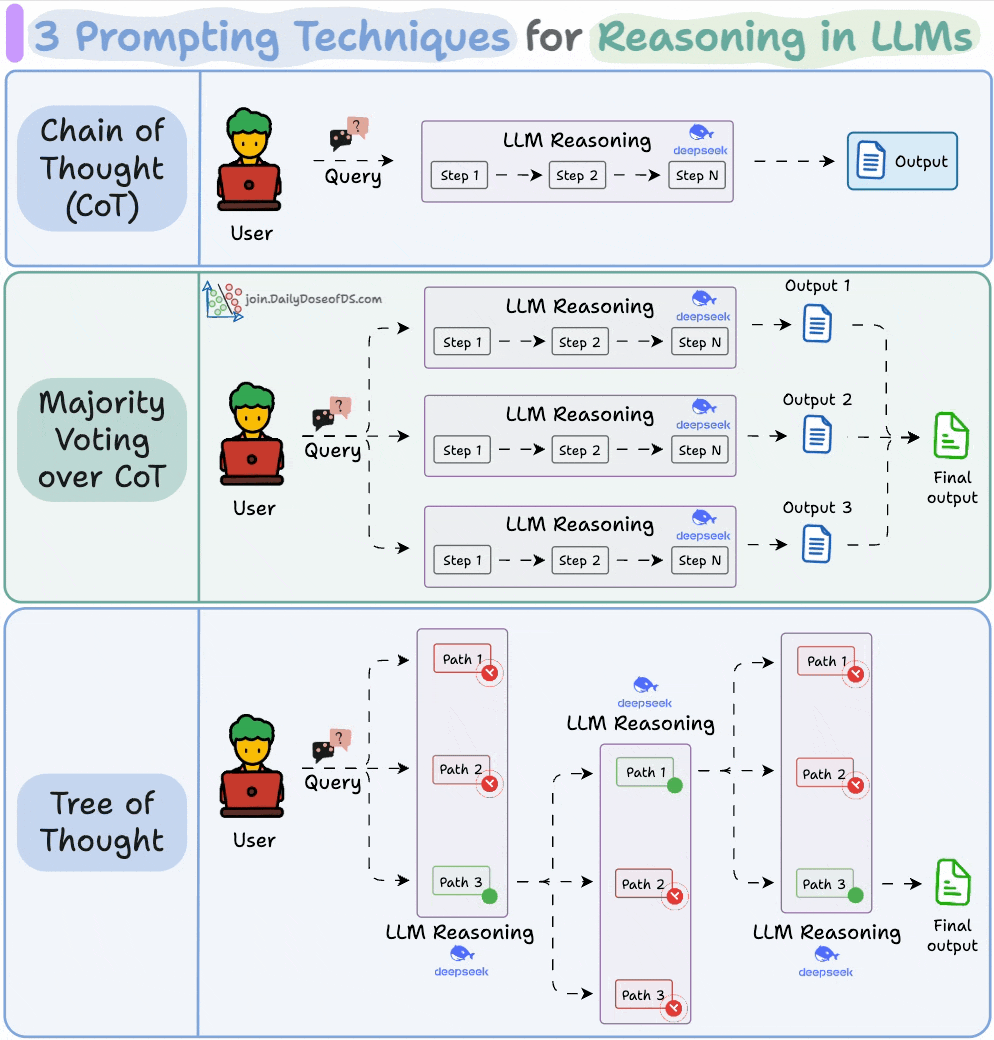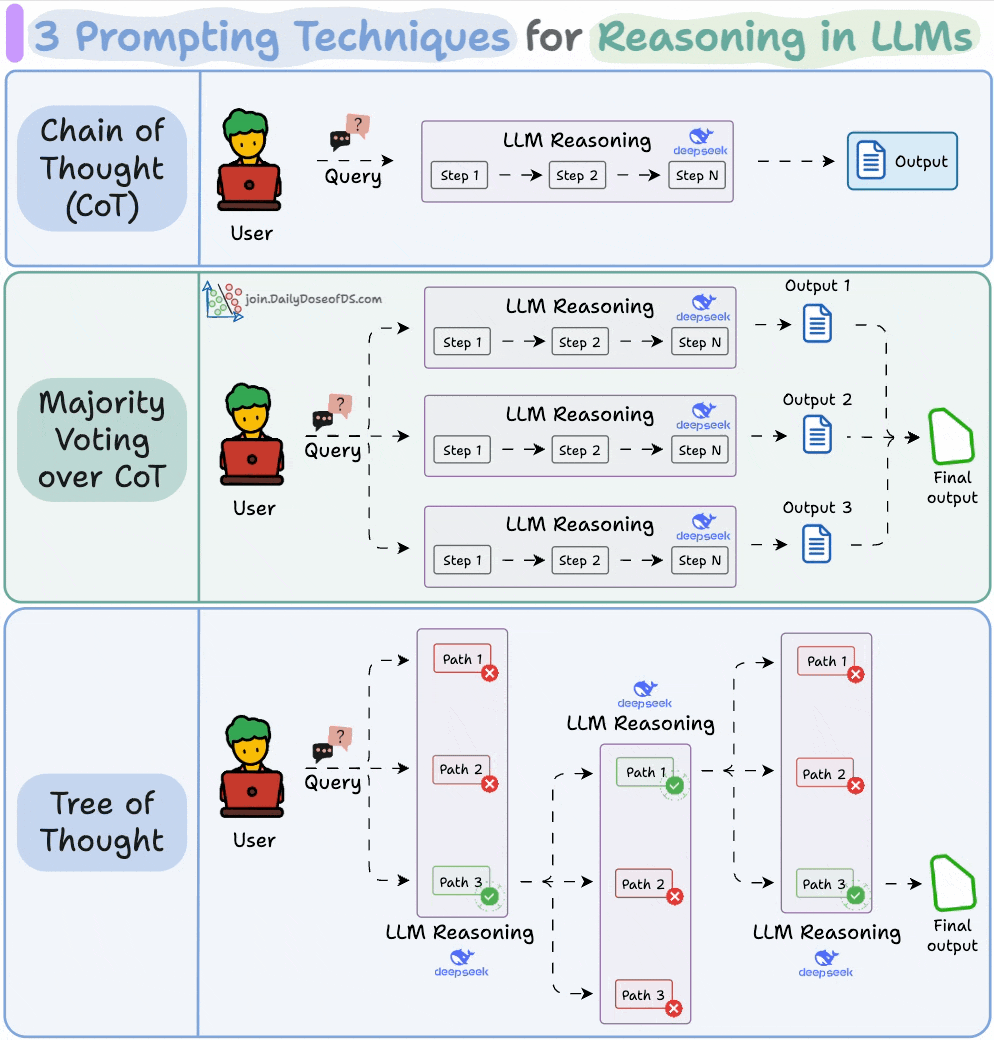
The simplest and most widely used technique.
Instead of asking the LLM to jump straight to the answer, we nudge it to reason step by step.

This often improves accuracy because the model can walk through its logic before committing to a final output.
For instance:
Q: If John has 3 apples and gives away 1, how many are left?Let's think step by step:
It’s a simple example, but this tiny nudge can unlock reasoning capabilities that standard zero-shot prompting could miss.
For starters, zero-shot prompting means giving the model a task without any intermediate steps or examples. Ask a question and expect an answer.
CoT is useful but not always consistent.
If you prompt the same question multiple times, you might get different answers depending on the temperature setting (we covered temperature in LLMs here).
Self-consistency embraces this variation.
You ask the LLM to generate multiple reasoning paths and then select the most common final answer.
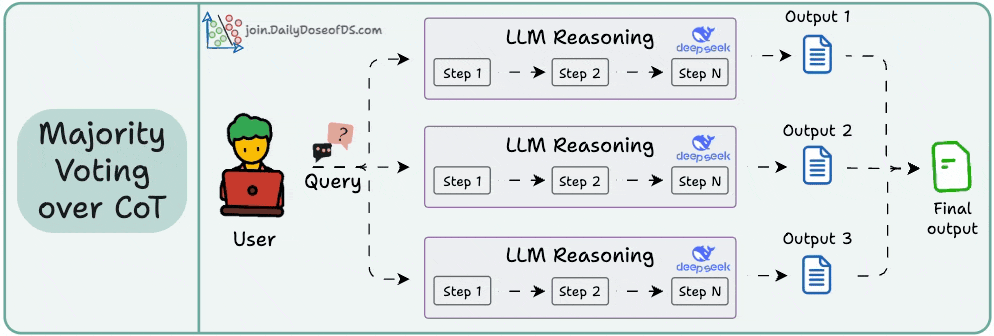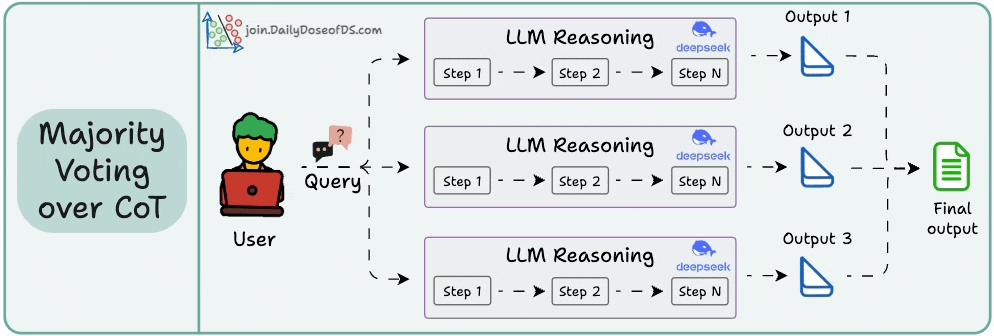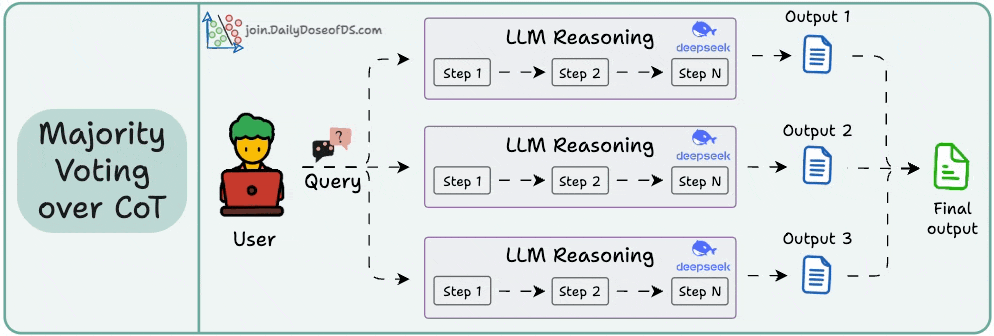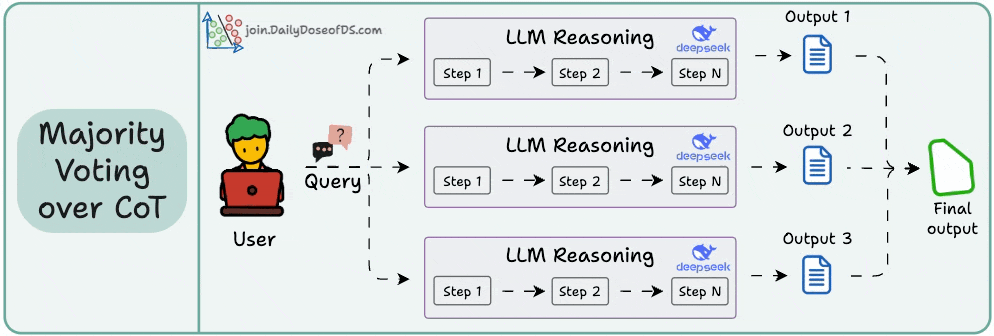
It’s a simple idea: when in doubt, ask the model several times and trust the majority.
This technique often leads to more robust results, especially on ambiguous or complex tasks.
However, it doesn’t evaluate how the reasoning was done—just whether the final answer is consistent across paths.
While Self-Consistency varies the final answer, Tree of Thoughts varies the steps of reasoning at each point and then picks the best path overall.
At every reasoning step, the model explores multiple possible directions. These branches form a tree, and a separate process evaluates which path seems the most promising at a particular timestamp.
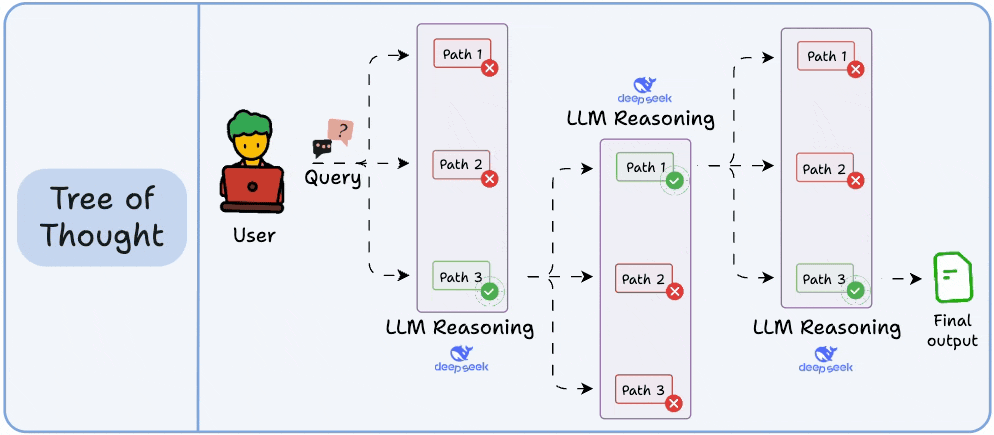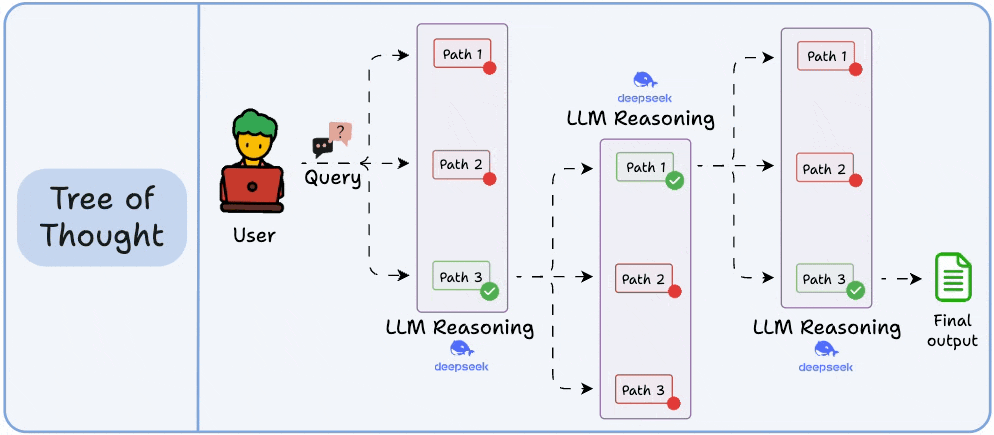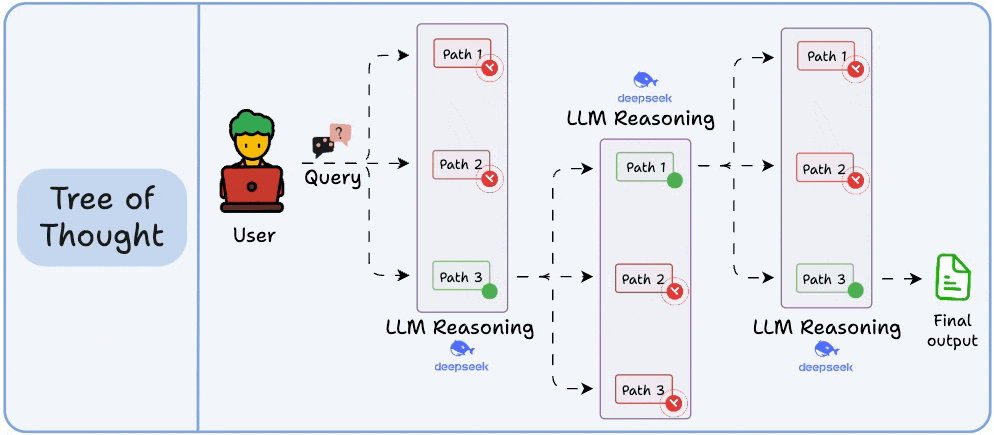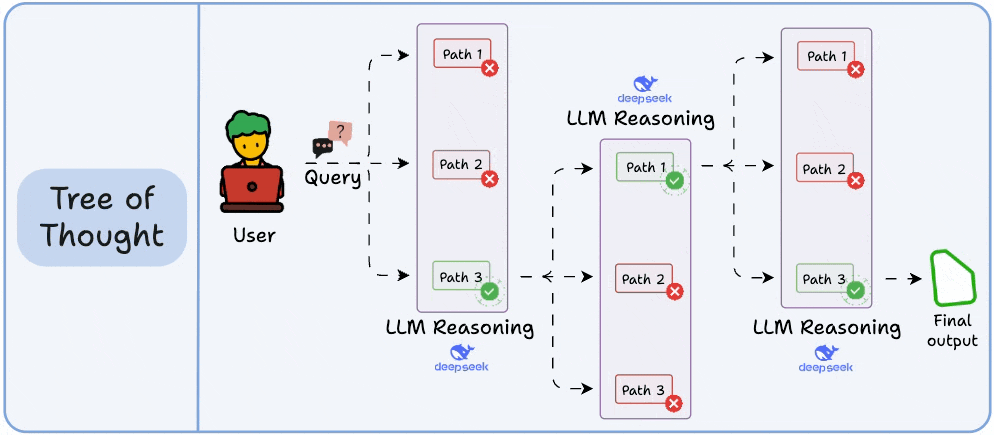
Think of it like a search algorithm over reasoning paths, where we try to find the most logical and coherent trail to the solution.
It’s more compute-intensive, but in most cases, it significantly outperforms basic CoT.
We’ll try to put together a demo on this soon, covering several use cases and best practices for inducing reasoning in LLMs through prompting.
Let us know what you would like to learn.
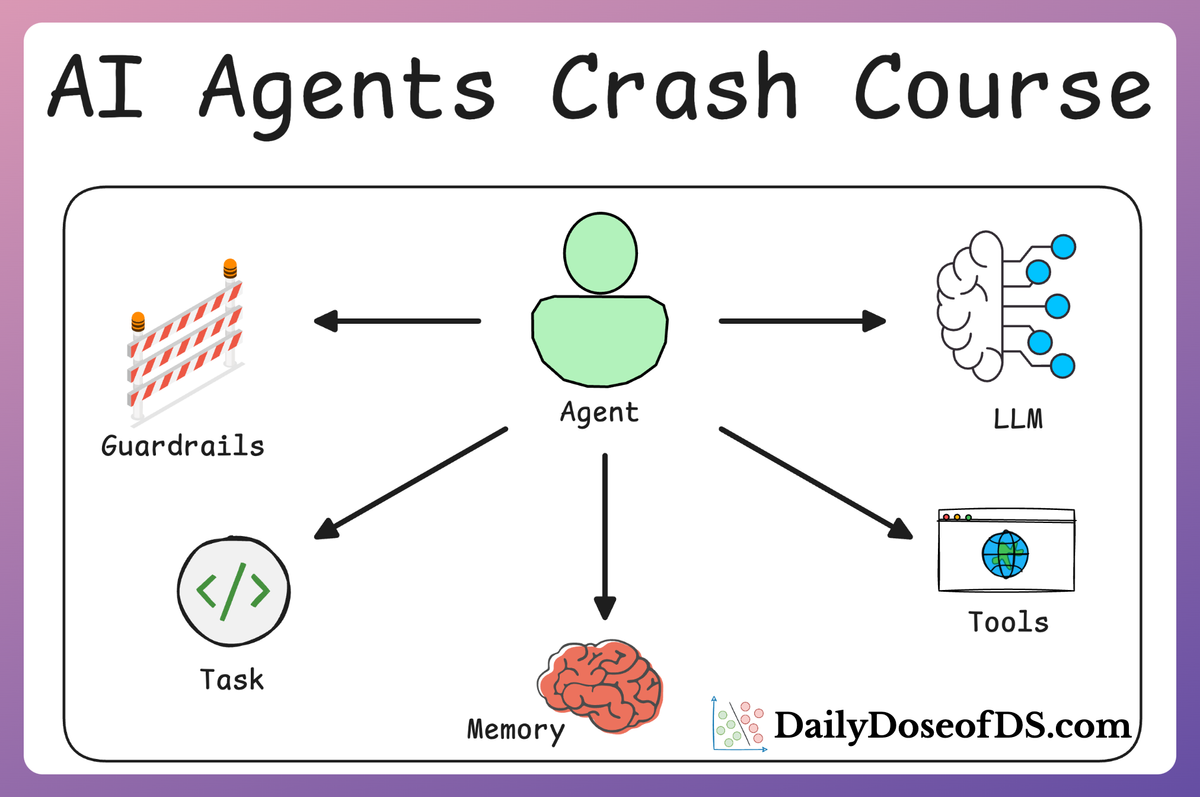
ReAct pattern for AI Agents also involves Reasoning.
Thanks for reading!