Integrating Sampling into MCP Workflows
MCP Part 5: A deep dive into sampling, its working, code, use cases and best practices.
Recap
In Part 4 of this MCP crash course, we expanded our focus beyond tools and took a deep dive into the other two foundational pillars of MCP: resources and prompts.
We learned how resources allow servers to expose data, anything from static documents to dynamic query-backed endpoints.
Prompts, on the other hand, enable natural language-based behaviors that can dynamically shape responses based on input, roles, and instructions.
Through theory and hands-on walkthroughs, we explored how each capability differs in execution flow, when to use tools vs. resources vs. prompts, and how they can be combined to design the server logic.
We also discussed how Claude Desktop can leverage these primitives to orchestrate rich user interactions powered by model-controlled, application-controlled, and user-initiated patterns.
Overall, in Part 4, we learned everything that it takes to build full-fledged MCP servers that don’t just execute code, but also expose data and template-based reasoning, allowing for cleaner separation of logic and language.
If you haven’t explored Part 4 yet, we strongly recommend going through it first since it lays the conceptual scaffolding that’ll help you better understand what we’re about to dive into here.
You can read it below:
In this part
In this chapter, we move a step ahead and introduce what we think is one of the most powerful features in the MCP protocol: sampling.
So far, we’ve seen how clients invoke server-side logic, but what if the server wants to delegate part of the work back to the client’s LLM?
That’s where sampling comes in.
We’ll explore how MCP enables server-initiated completions to request a response from the client’s LLM during execution.
We’ll explore:
- What is sampling and why is it useful?
- Sampling support in FastMCP
- How does it work on the server side?
- How to write a sampling handler on the client side?
- Model preferences
- Use cases for sampling
- Error handling and some best practices
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
Introduction
In a typical MCP setup, an MCP server exposes functions (tools), data (via resources), and prompts that an LLM client can use.
But what happens when the server itself needs to tap into the intelligence of an LLM? This is exactly what MCP Sampling is designed to solve.
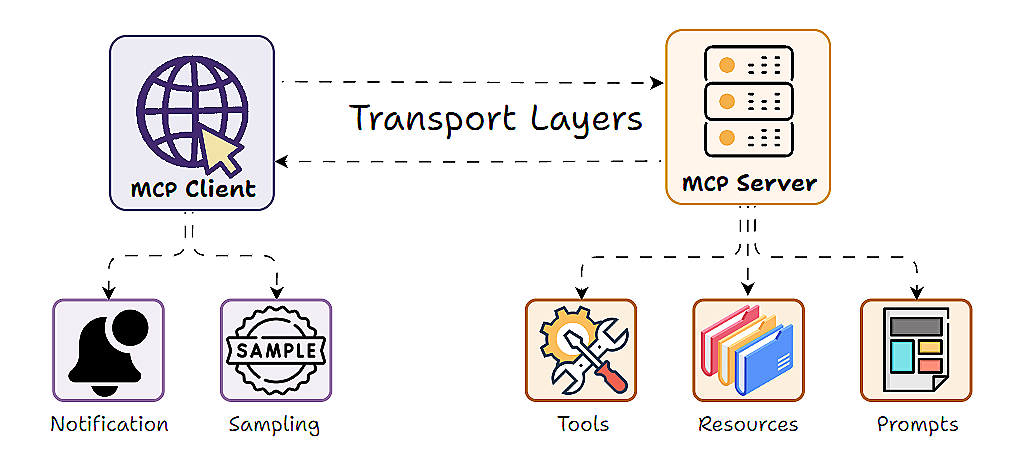
LLM sampling enables the server to delegate tasks to the language model available on the Client's side. In simpler terms, sampling in MCP allows a server to ask the client’s AI model to generate text (a completion) and return the result.
We will explore the concept, implementation, and applications of sampling with the FastMCP framework.
Concept and motivation
LLM sampling creates an inverted or bidirectional architecture.
Typically, an LLM client invokes the server’s tools, but with sampling, the server can also call back to the client’s model.
Why is this useful?
Consider the scenario of building an AI-driven server that needs to perform language understanding or generation as part of its functionality.
For example, summarizing a document or composing a message. Traditionally, the server would have to integrate an LLM API itself or run a model locally, which can be costly and hard to scale.
MCP sampling flips this around:
- Delegation of LLM work: The server offloads the language generation task to the client’s model. The server can ask, “Please summarize this text”, and the client’s LLM does the heavy lifting.
- Here's the step-by-step flow:
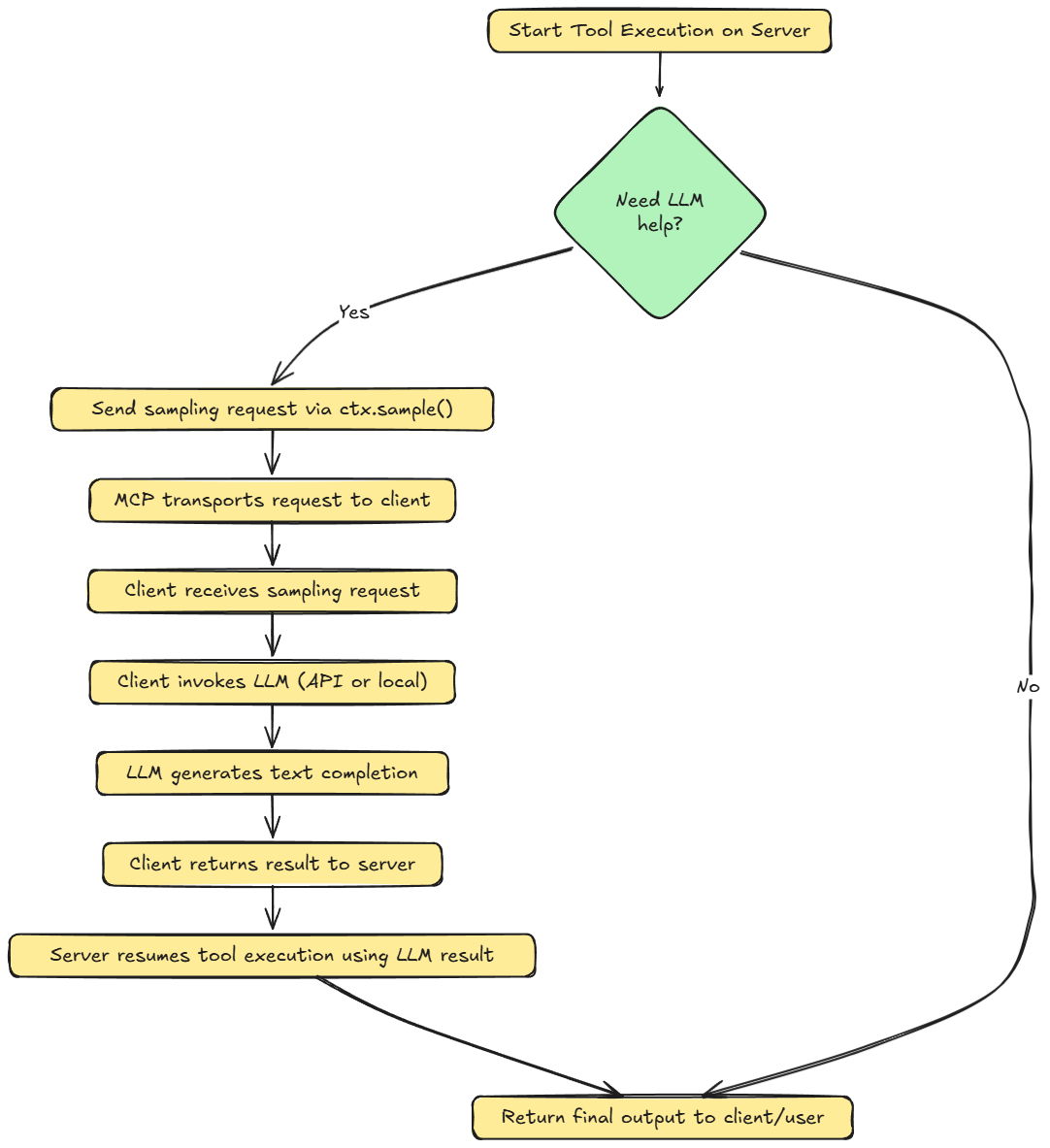
- The server’s tool function determines it needs an LLM’s help (e.g. to analyze or generate text).
- The server sends a prompt/request to the client via the sampling mechanism.
- The client receives this request and invokes its own LLM (local model or an API) to generate the completion.
- The client returns the generated result back to the server.
- The server’s tool function then resumes execution, using the LLM-generated result as needed, as if the server had produced it itself.
This provides several key advantages:
Scalability
The server avoids doing the computationally intensive inference.
This means the server can handle more concurrent requests since it’s not bogged down generating large chunks of text itself. Each client essentially handles its own LLM workload.
Cost efficiency
Any API costs or computational load associated with the LLM are borne by the client. If using a paid API, the client’s account is charged for the completion, not the server.
This distributes costs across users and frees the server owner from maintaining expensive infrastructure.
Flexibility in LLM choice
Clients can choose which model to use for a given request.
One client might use OpenAI’s GPT-4o, another might use an open-source model, and the server doesn’t need to change at all.
The server can even suggest a model preference (we’ll discuss model preferences later), but the client ultimately controls execution.
Avoiding bottlenecks
In a traditional setup, if the server had to handle all AI generation, it could become a bottleneck (imagine hundreds of users triggering text generation at once on one server).
With sampling, each user’s own environment handles their request, preventing server-side queue build-up.
In summary, sampling in MCP allows distributed AI computing.
The MCP server can incorporate powerful LLM capabilities without embedding a model or invoking external APIs itself.
It’s a bridge between the usually deterministic server logic and the dynamic text generation, achieved through a standardized protocol call.
Next, we’ll see how this fits into the MCP architecture.
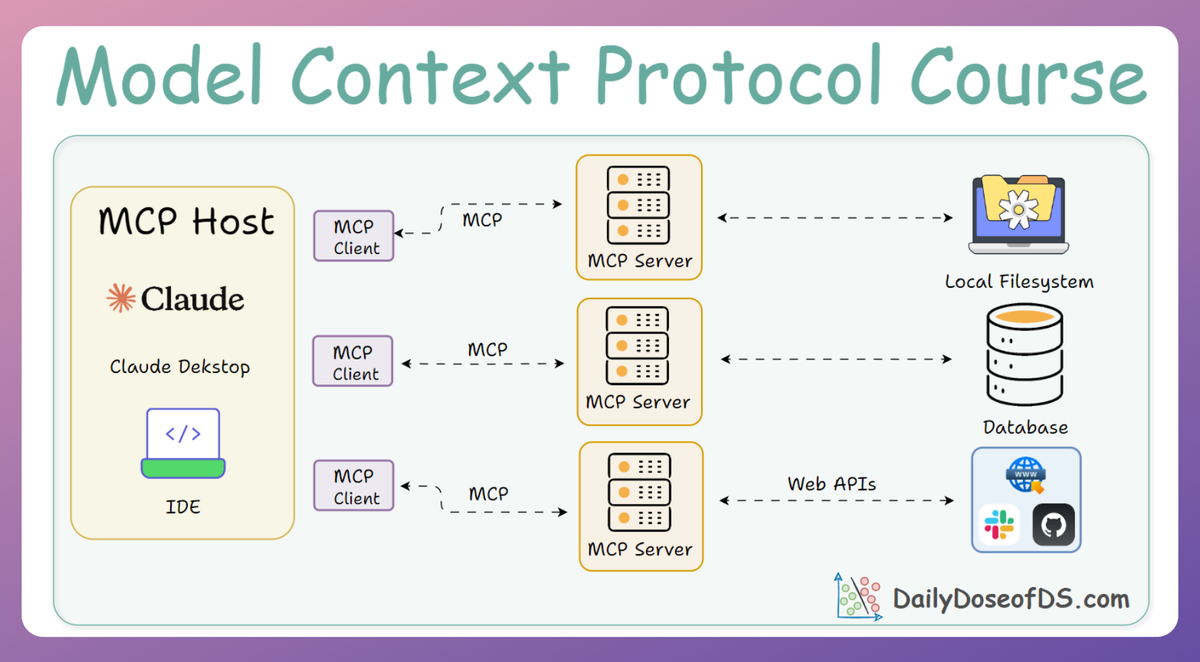
Architecture
From previous parts, we know that MCP uses a client-server architecture.
The server exposes an interface of tools, resources, and prompts, and the client connects to the server to use those capabilities.
Apart from the server providing tools, resources, and prompts, it can also request the client’s LLM to generate completions (i.e., sampling).
The LLM’s outputs are returned to the server, enabling AI-driven behaviors on the server side.
In a normal interaction, the client sends a request. The server does the necessary execution and returns the result to the client. Sampling introduces a reverse interaction: now the server, while handling a request, can ask the client to perform an AI task.
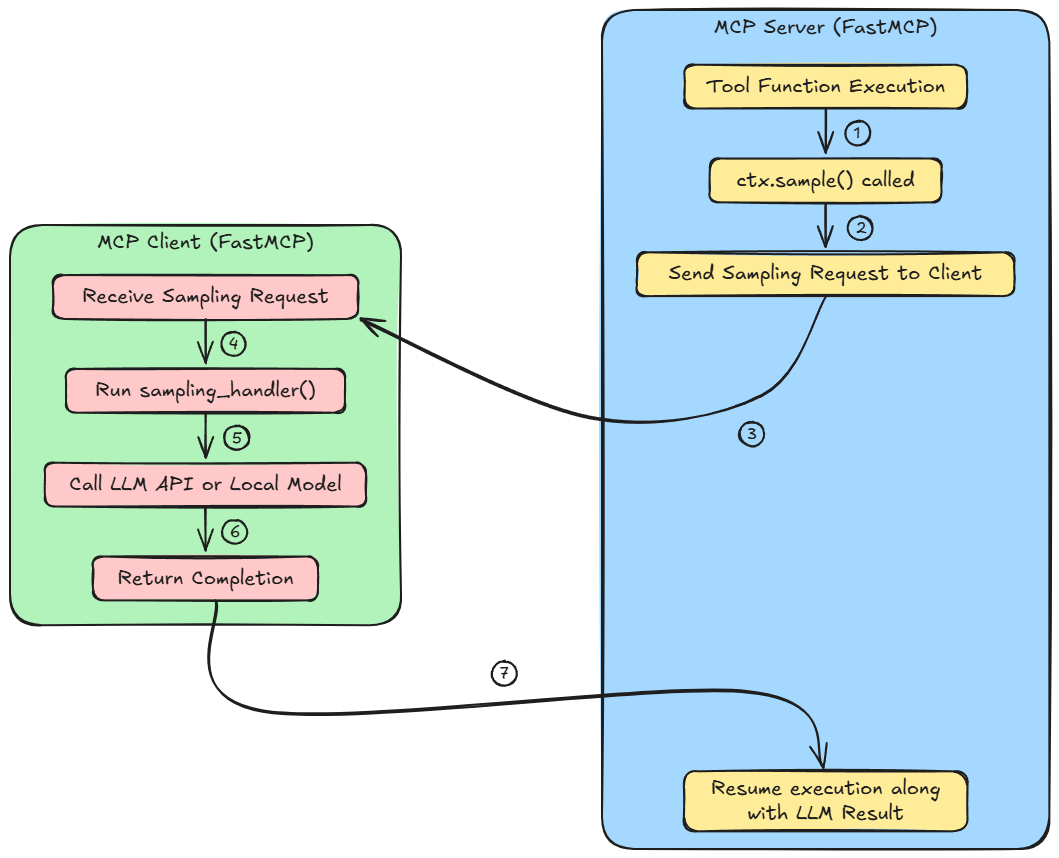
MCP Server (blue)
- A function/tool is running as part of an agent workflow on the server.
- Inside this function,
ctx.sample()is called to invoke an LLM for generating a response or make a decision. - This call does not execute the sampling locally. Instead, it packages the request and sends it to the MCP client.
MCP Client (green)
- The client listens for sampling requests from the server and receives this one.
- A user-defined
sampling_handler()is triggered. This function defines how to process the request. E.g., format the prompt, handle retries, etc. - The client uses either an external LLM API (like OpenAI) or a local model (like LLaMA or Mistral) to complete the request.
- The client sends back the generated text as a response to the server.
Once done, we get back on the MCP Server (blue) and resume execution along with LLM's result. The server receives the result from the client and resumes the tool function execution using the LLM-generated output.
In practical terms, FastMCP’s client library helps us explicitly provide a sampling handler (a callback function) to deal with these requests. We’ll cover how to implement this shortly in this article.
Transport and execution
The MCP protocol ensures that these requests are transported reliably. FastMCP supports multiple transports (like stdio and sse).
No matter the transport, the flow is the same. The server invokes the sampling method on an instance/object of the Context class (like ctx.sample(...)), packages it into an MCP message, sends it to the client, and waits for a response.
The client side invokes the sampling handler, which in turn invokes the actual LLM, and sends back the completion. All of this is asynchronous, that is, the server’s tool coroutine will suspend until the result comes back, avoiding blocking other tasks.
The entire flow is depicted in the diagram below:
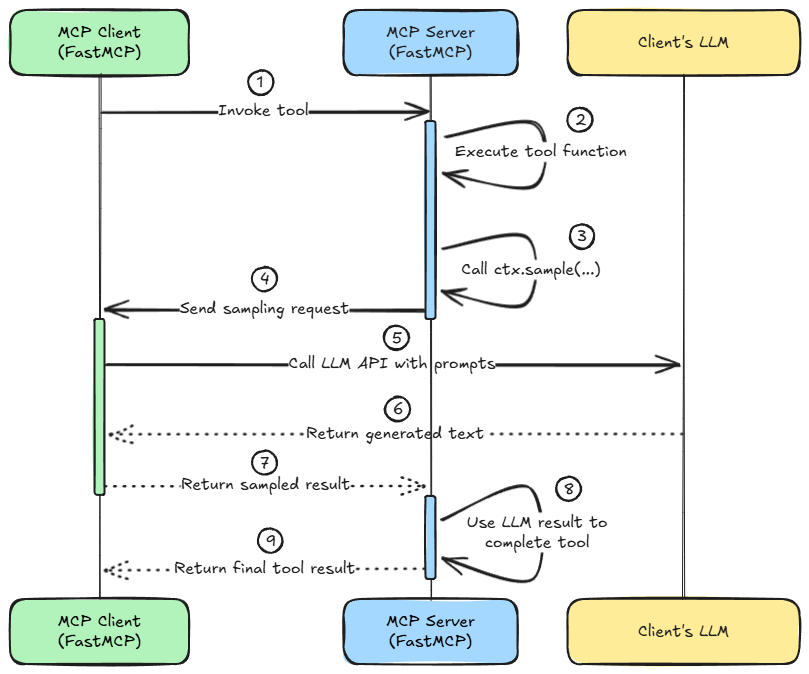
Sampling requests are just another type of structured request, so all the usual MCP validation applies.
For example, the server can’t force the client to run code; it can only request a text completion with certain parameters. And from the client’s perspective, it only ever runs its own LLM on prompts, and it doesn’t execute server code.
Context object and sampling mechanism
To use sampling in FastMCP, the server provides a Context object to its functions.
The Context is a powerful handle that, apart from requesting LLM sampling, can give server code access to logging, sending updates, etc.
FastMCP automatically injects this context into tool functions when we include it as a parameter. For example:
In the above snippet, because we annotated ctx with type Context, FastMCP will inject the context when analyze_data is invoked by an MCP client.
On a side note, you can download the code for this article below. Specifically open the open-me.ipynb notebook for instructions.
Download below: