Primitives, Communication and Practical Usage
MCP Part 2: An overview of key MCP primitives (capabilities), the MCP communication protocol and hands-on examples.
Recap from Part 1
Before we dive in, let’s briefly recap what we covered in Part 1 of this MCP crash course.
In Part 1, we laid the groundwork for understanding the Model Context Protocol (MCP). We began by exploring the evolution of context management in LLMs, from early techniques like static prompting and retrieval-augmented generation to more structured approaches like function calling and agent-based orchestration.
We then introduced the core motivation behind MCP: solving the M×N integration problem, where every new tool and model pairing previously required custom glue code.
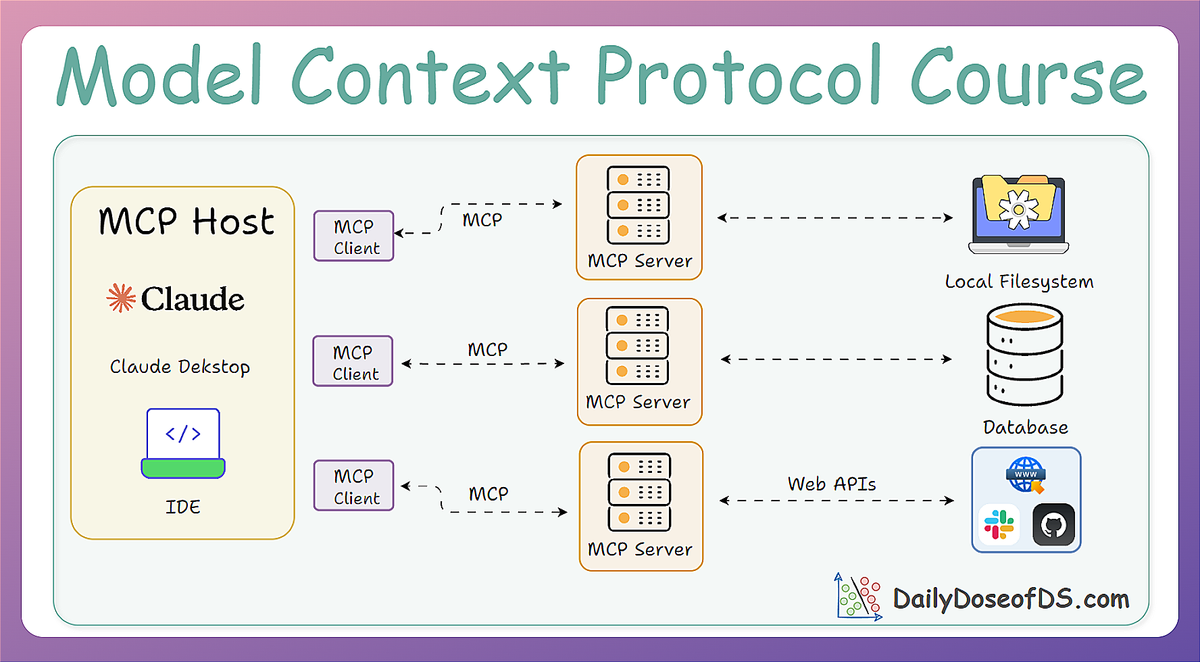
Finally, we unpacked the MCP architecture, clarifying the roles of the Host (AI app), Client (protocol handler), and Server (tool provider) and explained how they interact through a standardized, modular system.

Now, in Part 2, we’ll build upon that foundation and get hands-on with MCP capabilities, communication protocol, and real-world implementation.
If you haven't read the previous part yet, we highly recommend doing so before reading ahead:
Let's dive in!
Primitives in MCP
An MCP Server can expose one or more capabilities (primitives) to the client.
Capabilities are essentially the features or functions that the server makes available. The MCP standard currently defines four major categories of capabilities:
- Tools → Executable actions or functions that the AI (host/client) can invoke (often with side effects or external API calls).
- Resources → Read-only data sources that the AI (host/client) can query for information (no side effects, just retrieval).
- Prompts → Predefined prompt templates or workflows that the server can supply.
- Sampling → A mechanism through which the server can request the AI (client/host) to perform an LLM completion. Sampling will be explored in greater depth in later parts of this course.
Let’s break down each in detail:
Tools (actions)
Tools are what they sound like: functions that do something on behalf of the AI model. These are typically operations that can have effects or require computation beyond the AI’s own capabilities.
Importantly, Tools are usually triggered by the AI model’s choice, which means the LLM (via the host) decides to call a tool when it determines it needs that functionality.
Because tools can change things or call external services, they often are subject to safety checks (the system may require the user to approve a tool invocation, especially if it’s something sensitive like sending an email or executing code).
Suppose we have a simple tool for weather. In an MCP server’s code, it might look like:
This Python function, registered with @mcp.tool(), can be invoked by the AI via MCP.
When the AI calls tools/call with name "get_weather" and {"location": "San Francisco"} as arguments, the server will execute get_weather("San Francisco") and return the dictionary result.
The client will get that JSON result and make it available to the AI. Notice the tool returns structured data (temperature, conditions), and the AI can then use or verbalize (generate a response) that info.
Since tools can do things like file I/O or network calls, an MCP implementation often requires that the user permit a tool call.
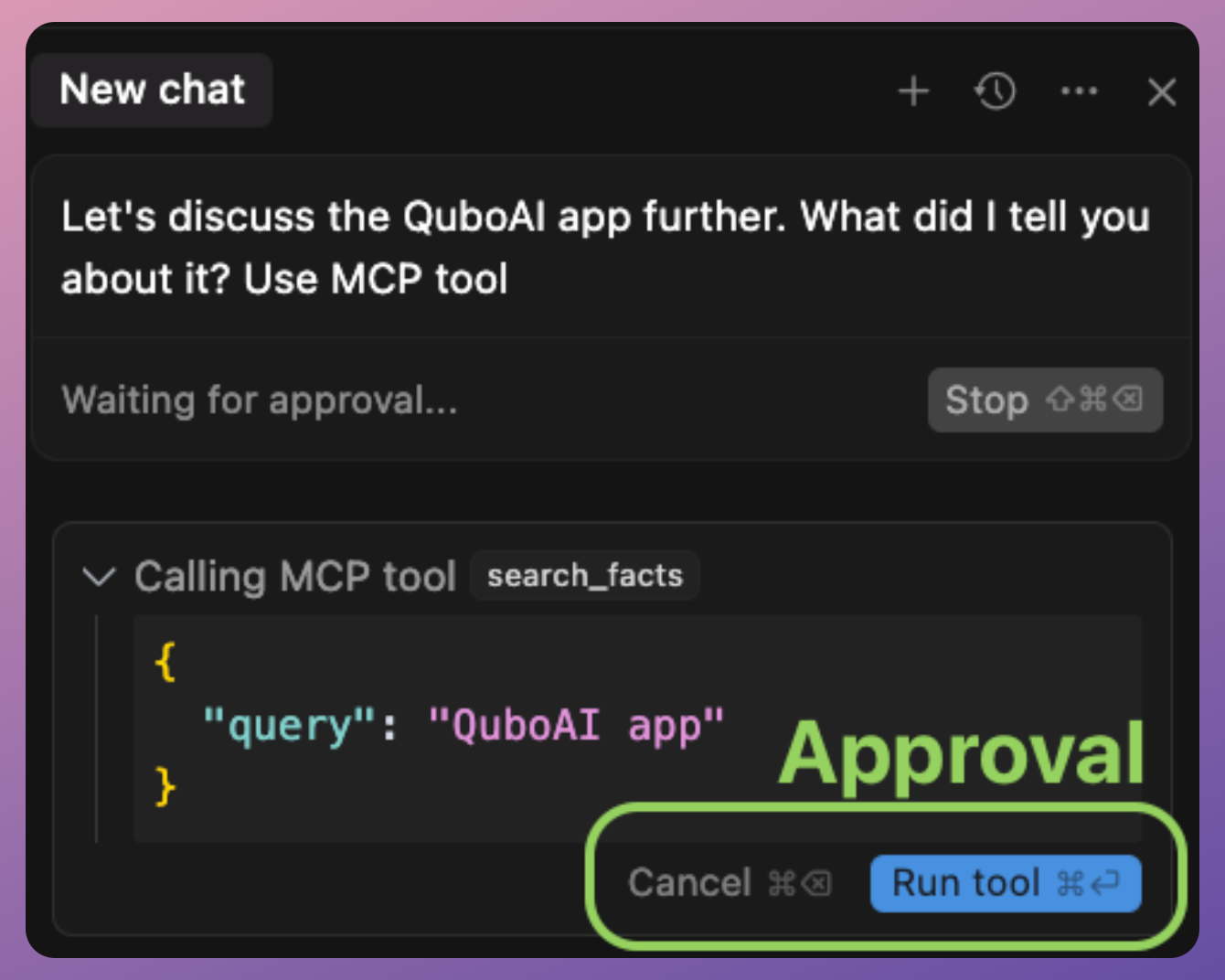
For example, Claude’s client might pop up “The AI wants to use the ‘get_weather’ tool, allow yes/no?” the first time, to avoid abuse. This ensures the human stays in control of powerful actions.
Tools are analogous to “functions” in classic function calling, but under MCP, they are used in a more flexible, dynamic context.
They are model-controlled (the model decides when to use them) but developer/governance-approved in execution.
Resources
Resources provide read-only data to the AI model.
These are like databases or knowledge bases that the AI can query to get information, but not modify.
Unlike tools, resources typically do not involve heavy computation or side effects, since they are often just information lookup.
Another key difference is that resources are usually accessed under the host application’s control (not spontaneously by the model). In practice, this might mean the Host knows when to fetch certain context for the model.
For instance, if a user says, “Use the company handbook to answer my question,” the Host might call a resource that retrieves relevant handbook sections and feeds them to the model.
Resources could include a local file’s contents, a snippet from a knowledge base or documentation, a database query result (read-only), or any static data like configuration info.
Essentially anything the AI might need to know as context. An AI research assistant could have resources like “ArXiv papers database,” where it can retrieve an abstract or reference when asked.
A simple resource could be a function to read a file: