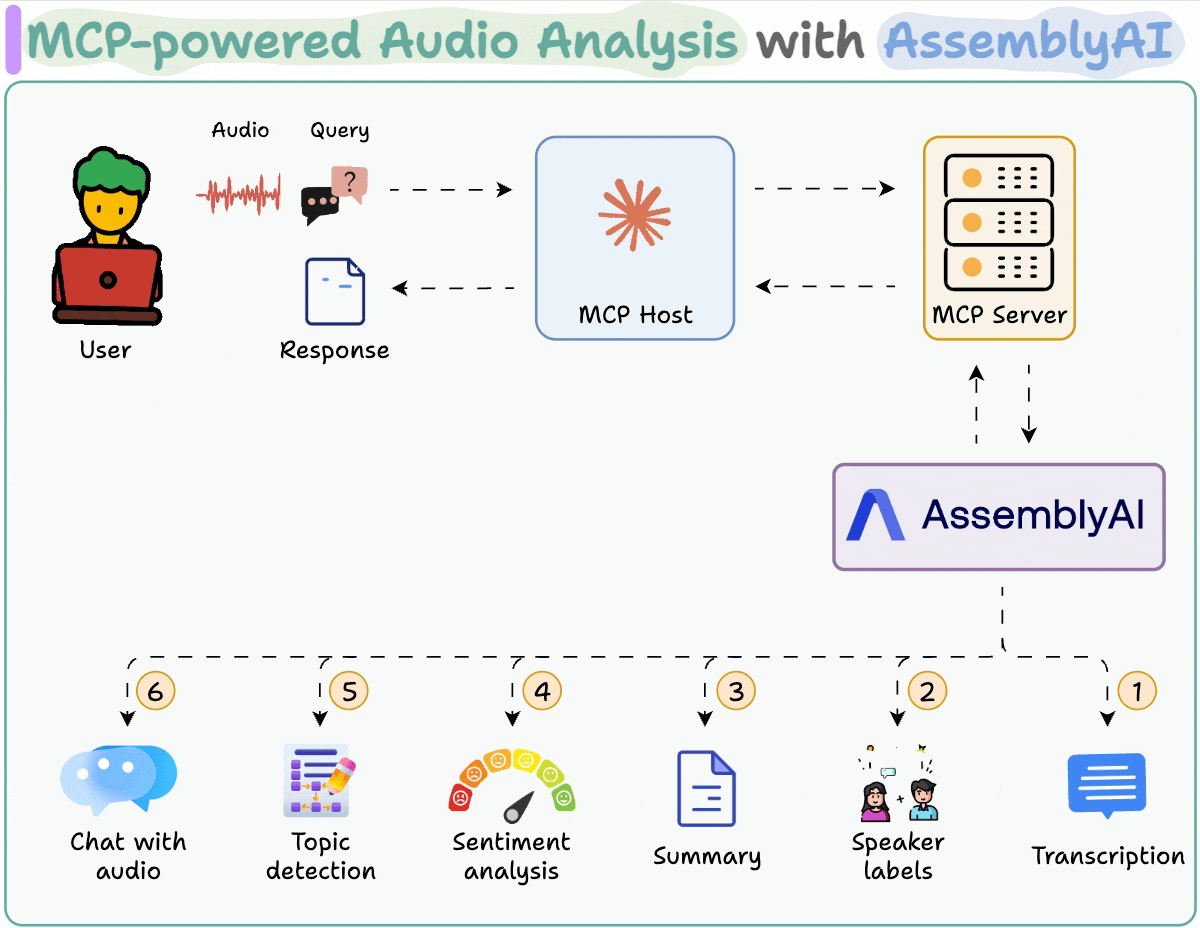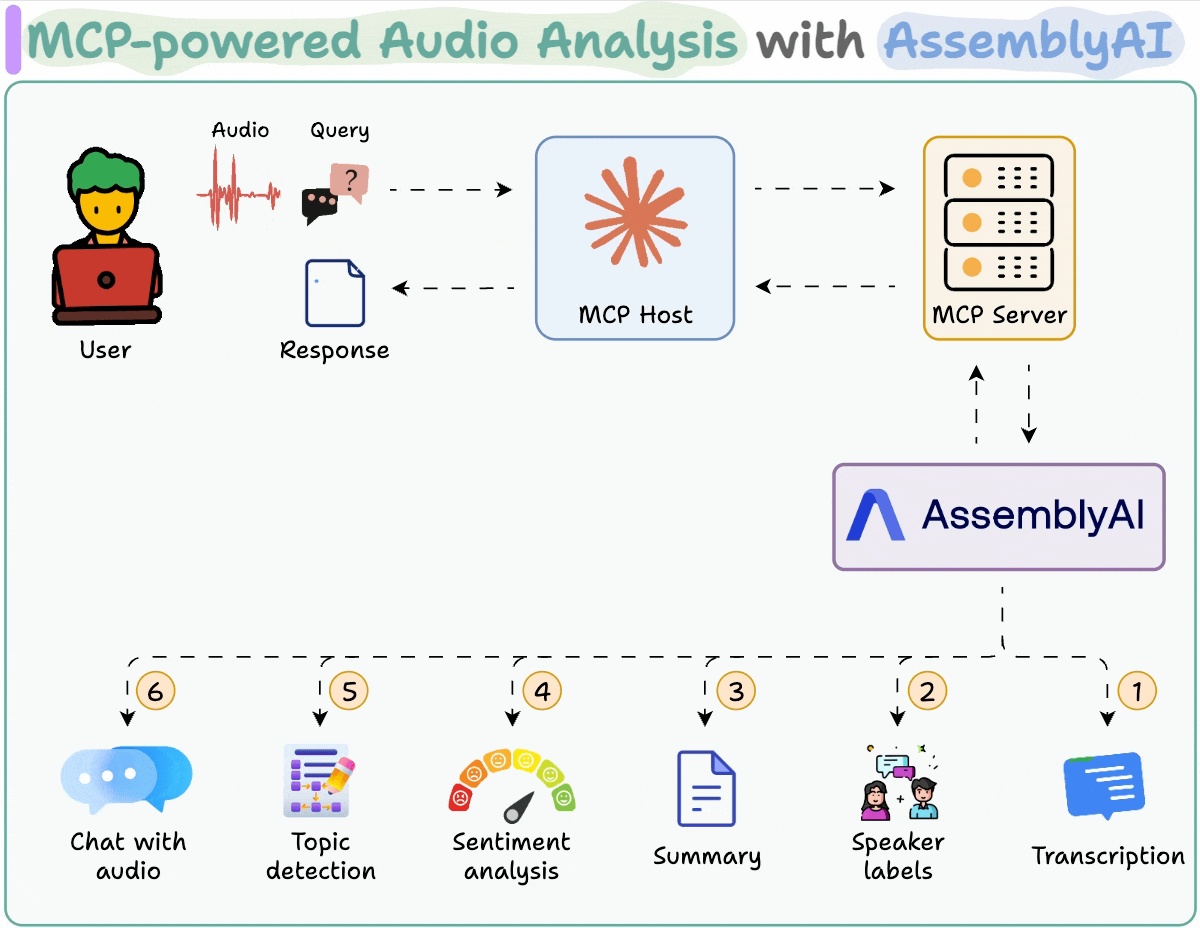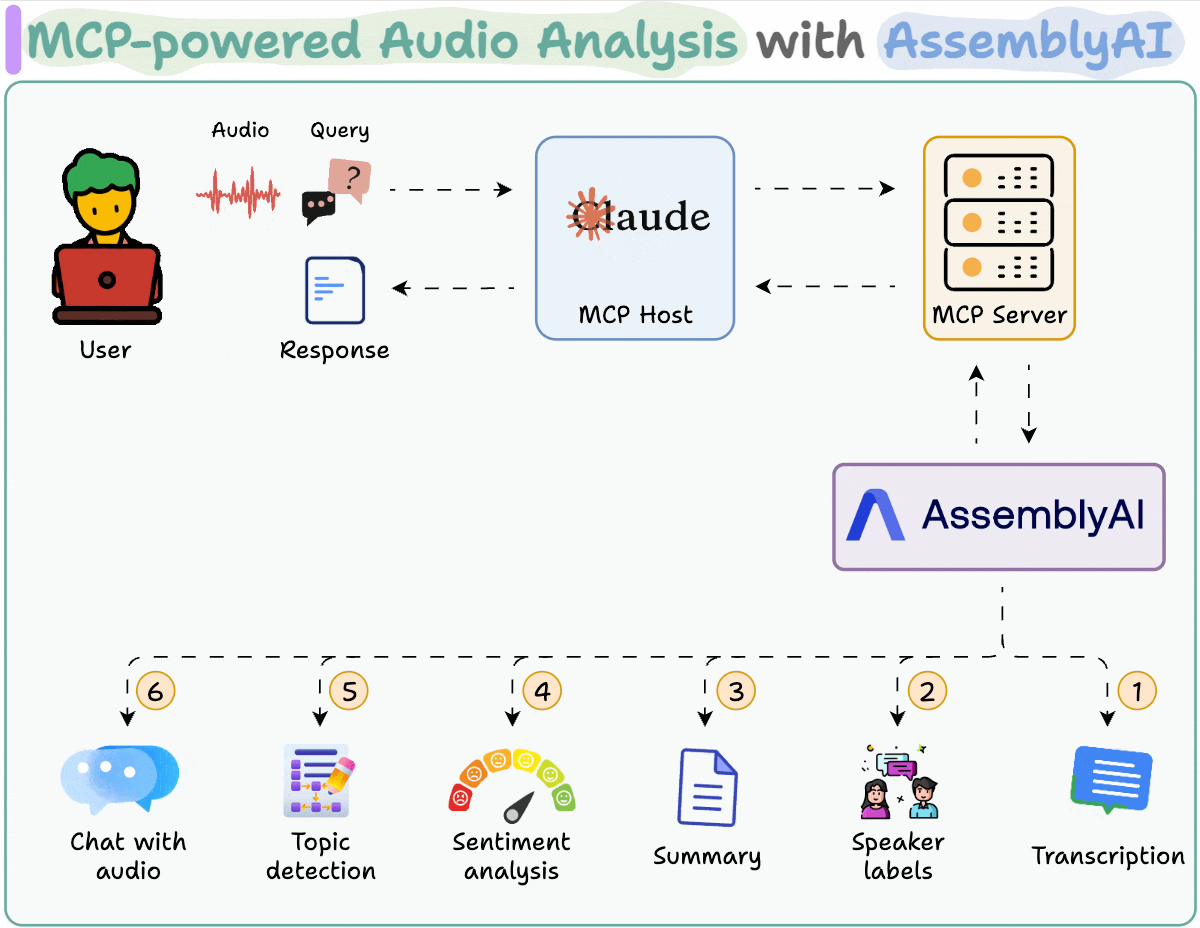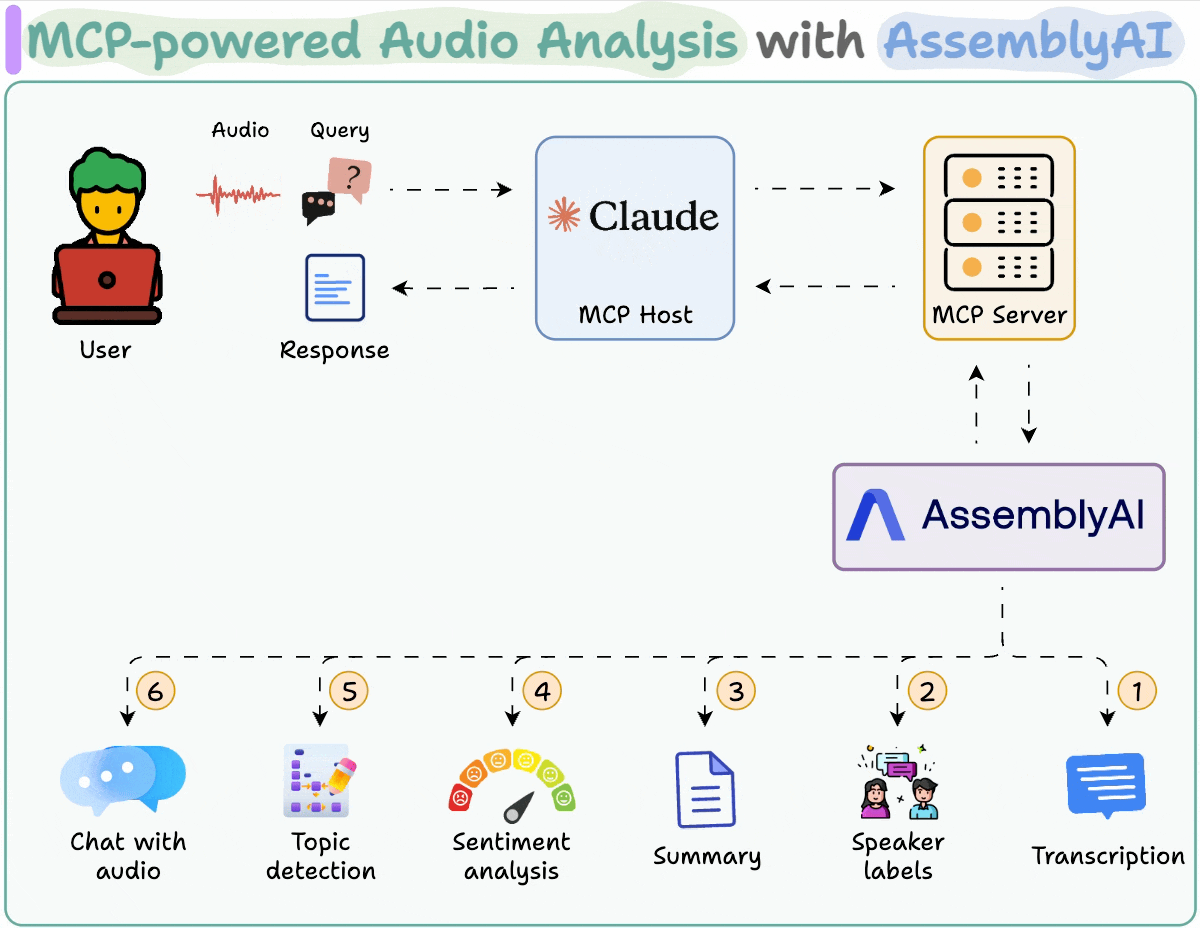
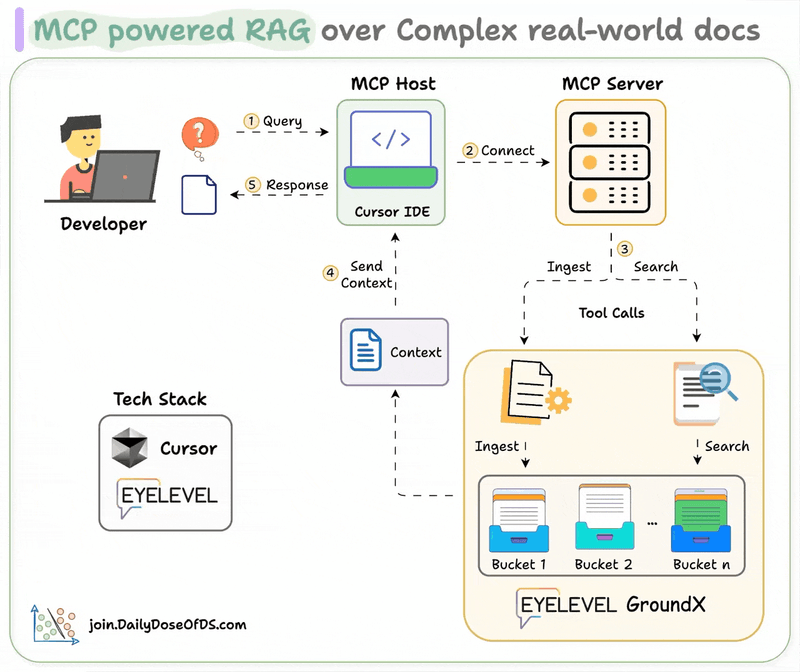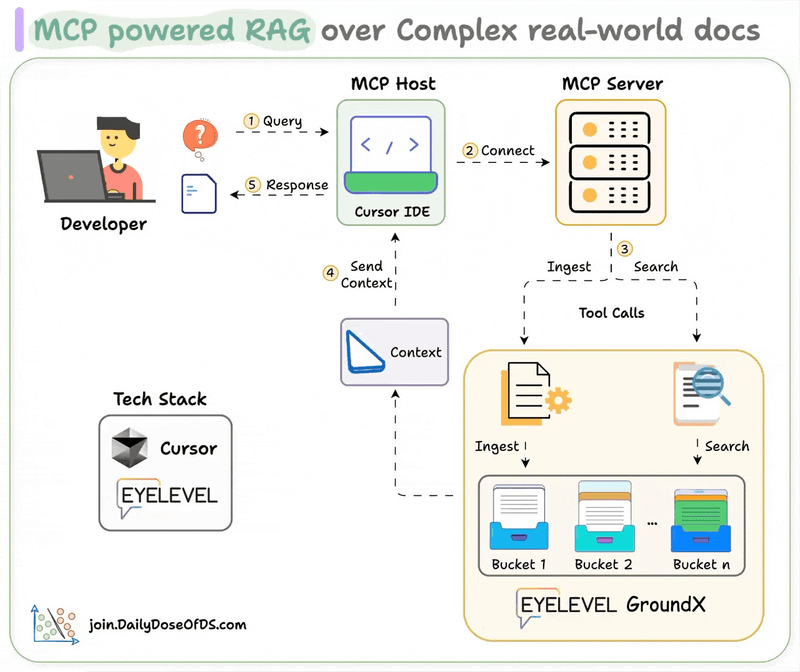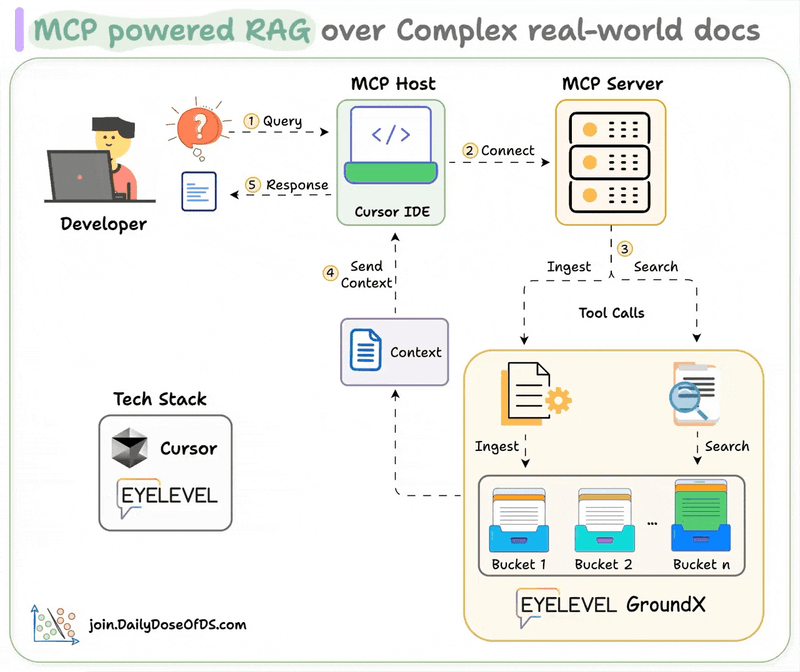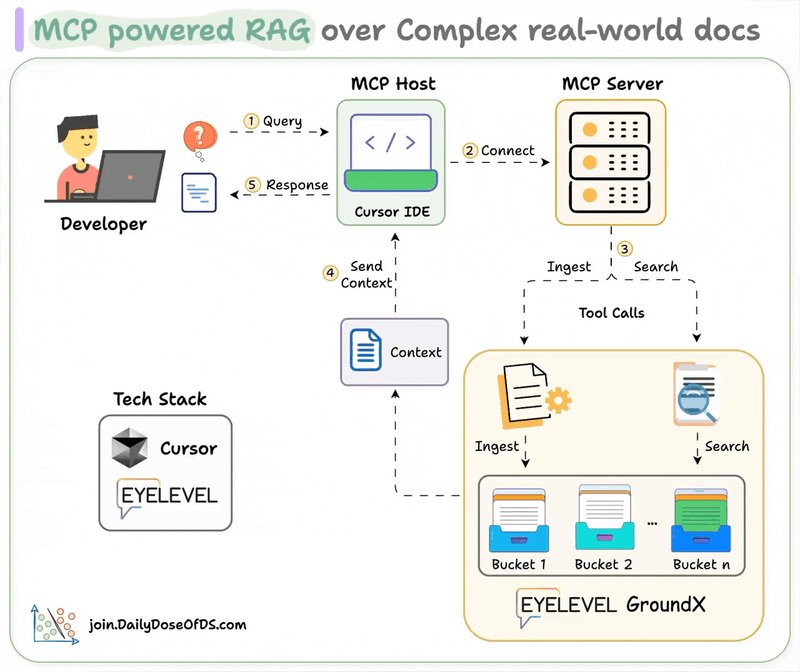
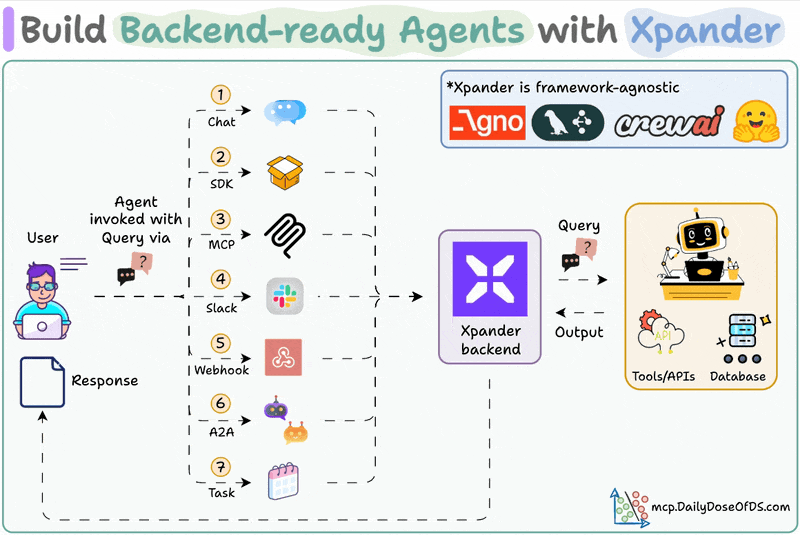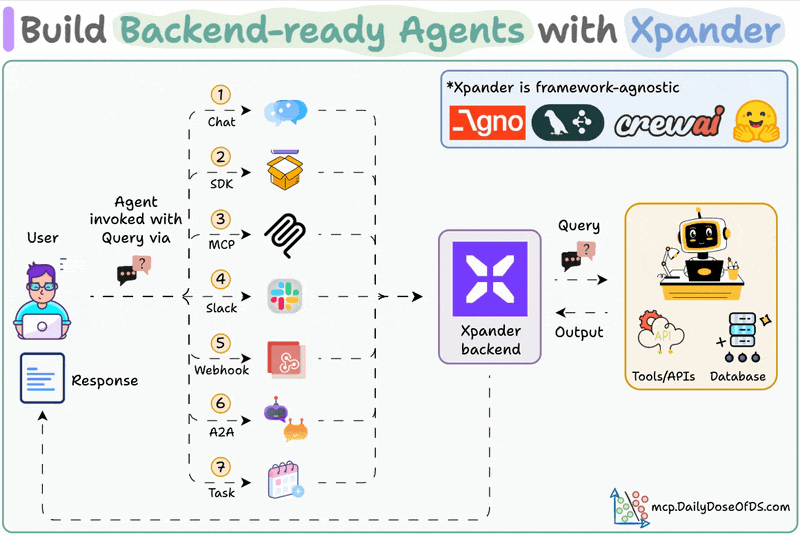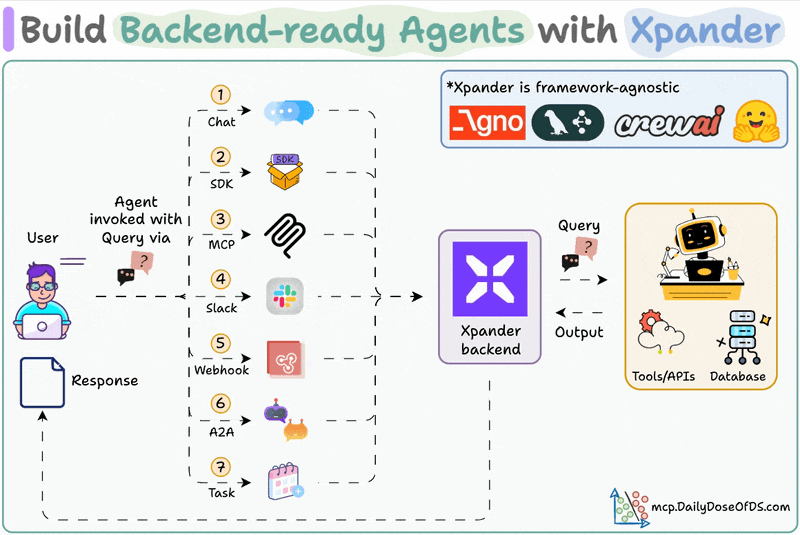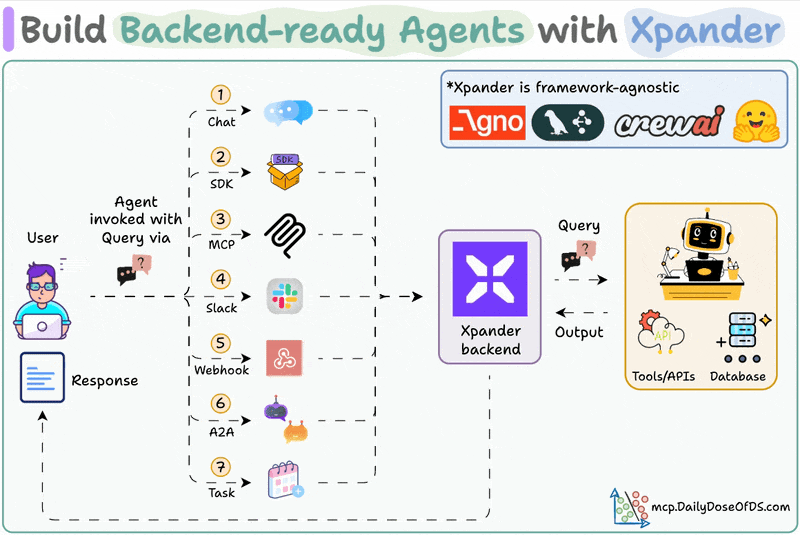
MLOps/LLMOps Course
Model Deployment: Introduction to AWS
MLOps Part 14: Understanding AWS cloud platform, and zooming into EKS.

372 posts published
MLOps Part 14: Understanding AWS cloud platform, and zooming into EKS.
...explained step-by-step with code.
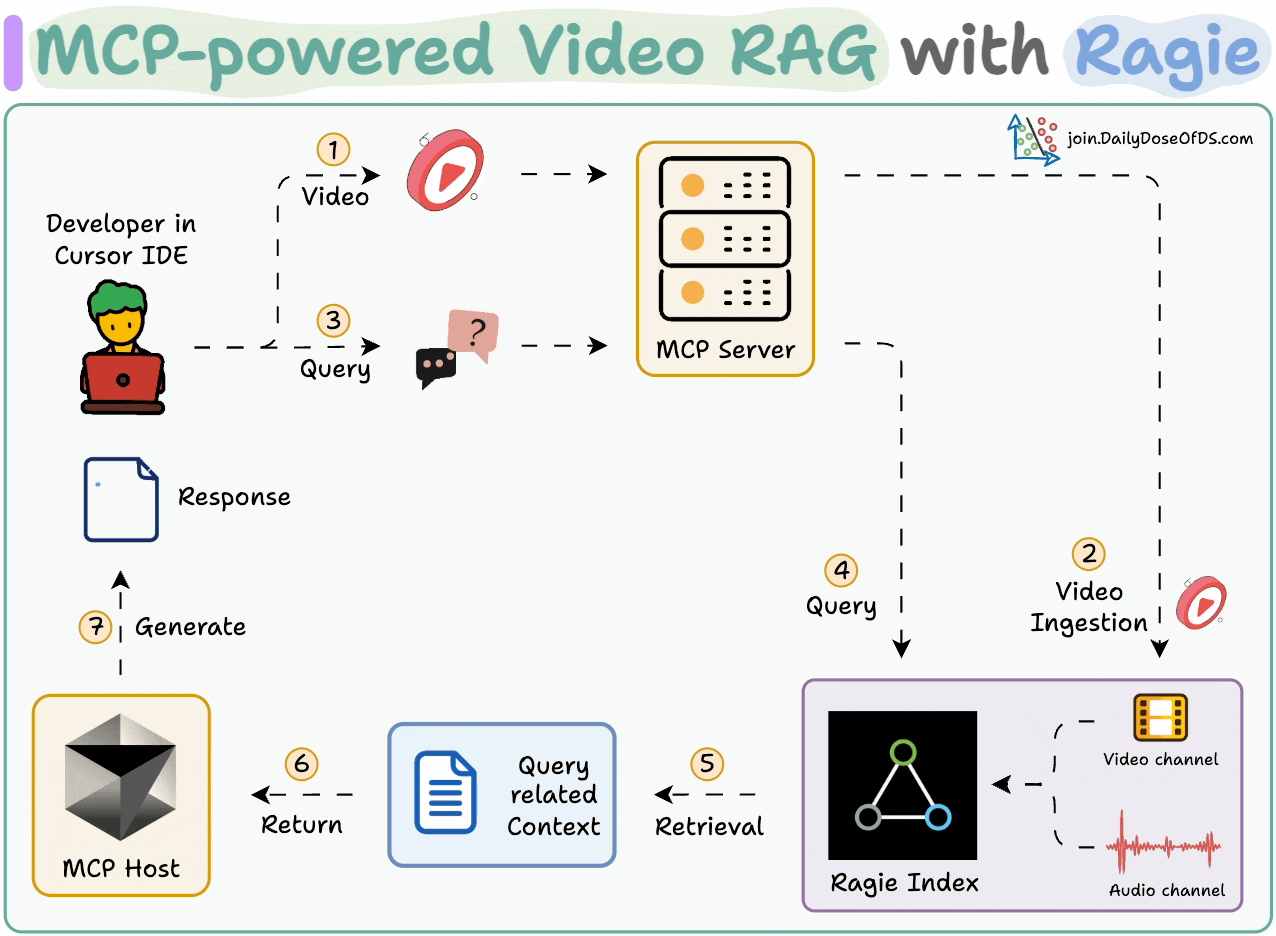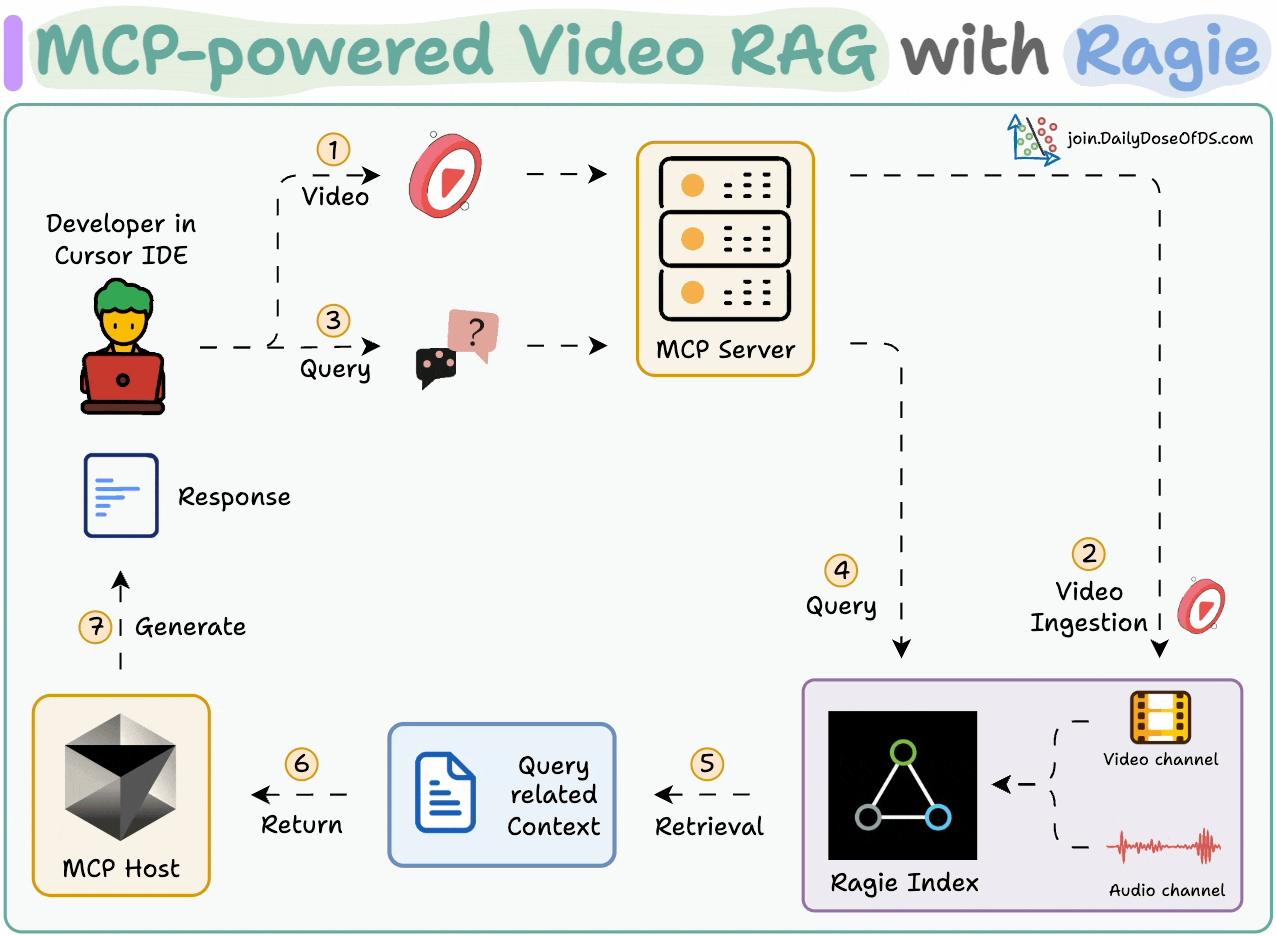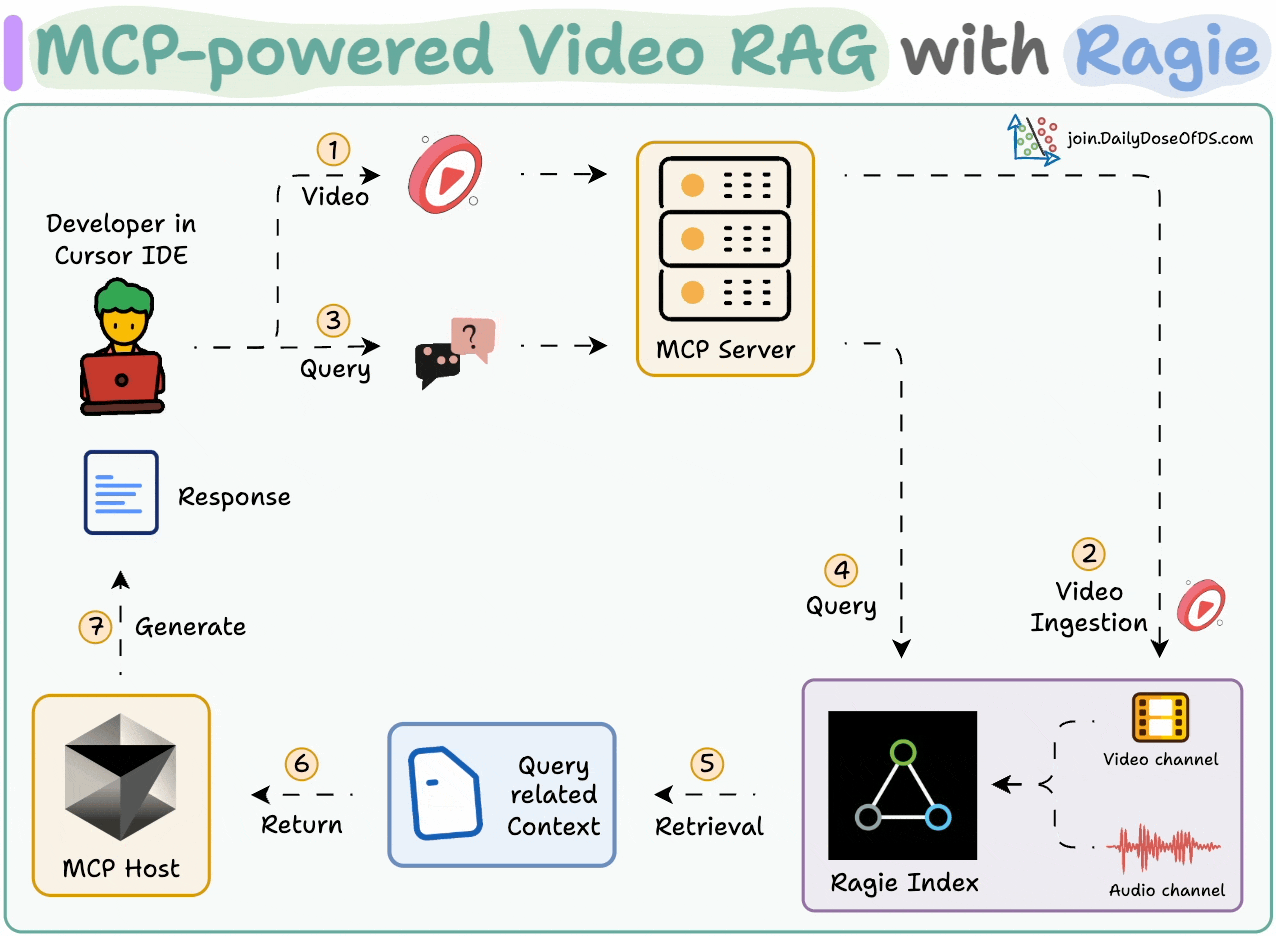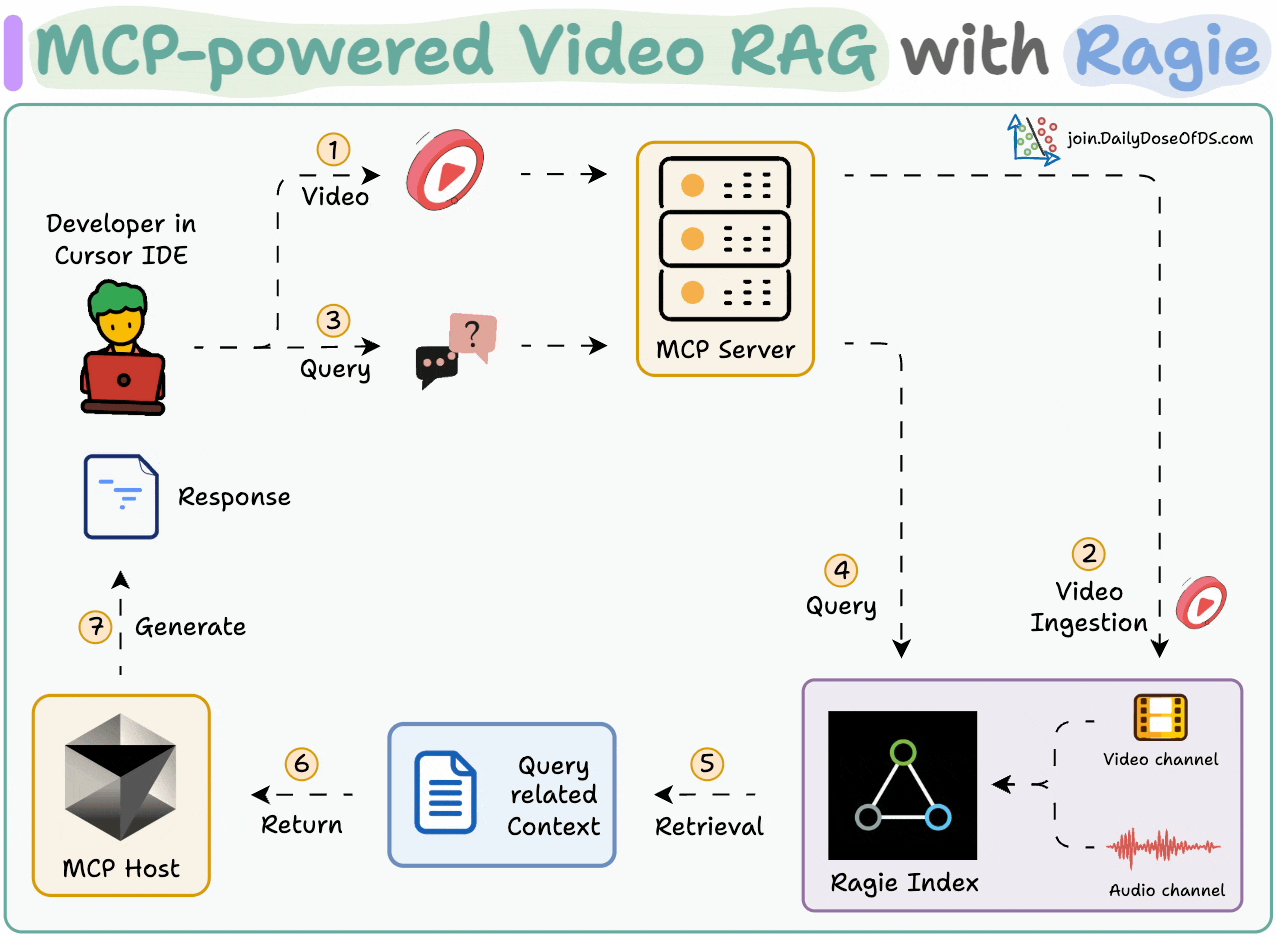
Chat with videos and get precise timestamps.
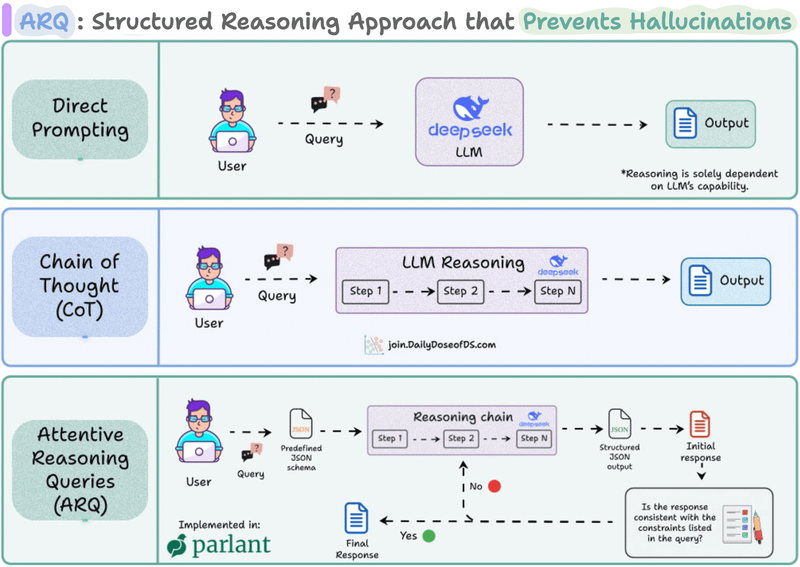
...that actually prevents hallucinations (explained visually).
MLOps Part 13: An overview of cloud concepts that matter, from virtualization and storage choices to VPC, load balancing, identity, and observability.
MLOps Part 12: An introduction to Kubernetes, plus a practical walkthrough of deploying a simple FastAPI inference service using Kubernetes.
Multi-agent (100% local).
Generate realistic data using existing data (100% local).
...with hands-on implementation.
MLOps Part 11: A practical guide to taking models beyond notebooks, exploring serialization formats, containerization, and serving predictions using REST and gRPC.
...explained step-by-step.
100% local.
A unified MCP server for all your data (100% local).
...powered by Qwen 3 LLM.
MLOps Part 10: A comprehensive guide to model compression covering knowledge distillation, low-rank factorization, and quantization, followed by ONNX and ONNX Runtime as the bridge from training frameworks to fast, portable production inference.
MLOps Part 9: A deep dive into model fine-tuning and compression, specifically pruning and related improvements.
MLOps Part 8: A systems-first guide to model development and optimizing performance with disciplined hyperparameter tuning.
..explained step-by-step with code.