AugSBERT: Bi-encoders + Cross-encoders for Sentence Pair Similarity Scoring – Part 2
A deep dive into extensions of cross-encoders and bi-encoders for sentence pair similarity.
Recap
In the latest deep dive, we went into a whole lot of detail around sentence pair similarity scoring in real-world NLP systems, why it matters, and the techniques to build such systems.
This is the second and final part of this series, where I intend to walk you through the background, the challenges with traditional approaches, optimal approaches, and implementations that help you build robust systems that rely on pairwise scoring.
To recap Part 1, we understood that so many real-world NLP systems, either implicitly or explicitly, rely on pairwise sentence scoring in one form or another.
- Retrieval-augment generation systems heavily use it.
- Question-answering systems implicitly use it.
- Several information retrieval (IR) systems depend on it
- Duplicate detection engines assess context similarities, which is often found in community-driven platforms.
To build such systems, we explored two popular approaches to sentence pair similarity tasks: Cross-encoders and Bi-encoders, each with its own strengths and limitations.
1) Cross-encoders
These models take a pair of sentences, concatenate them, and process them together through a pre-trained model like BERT.
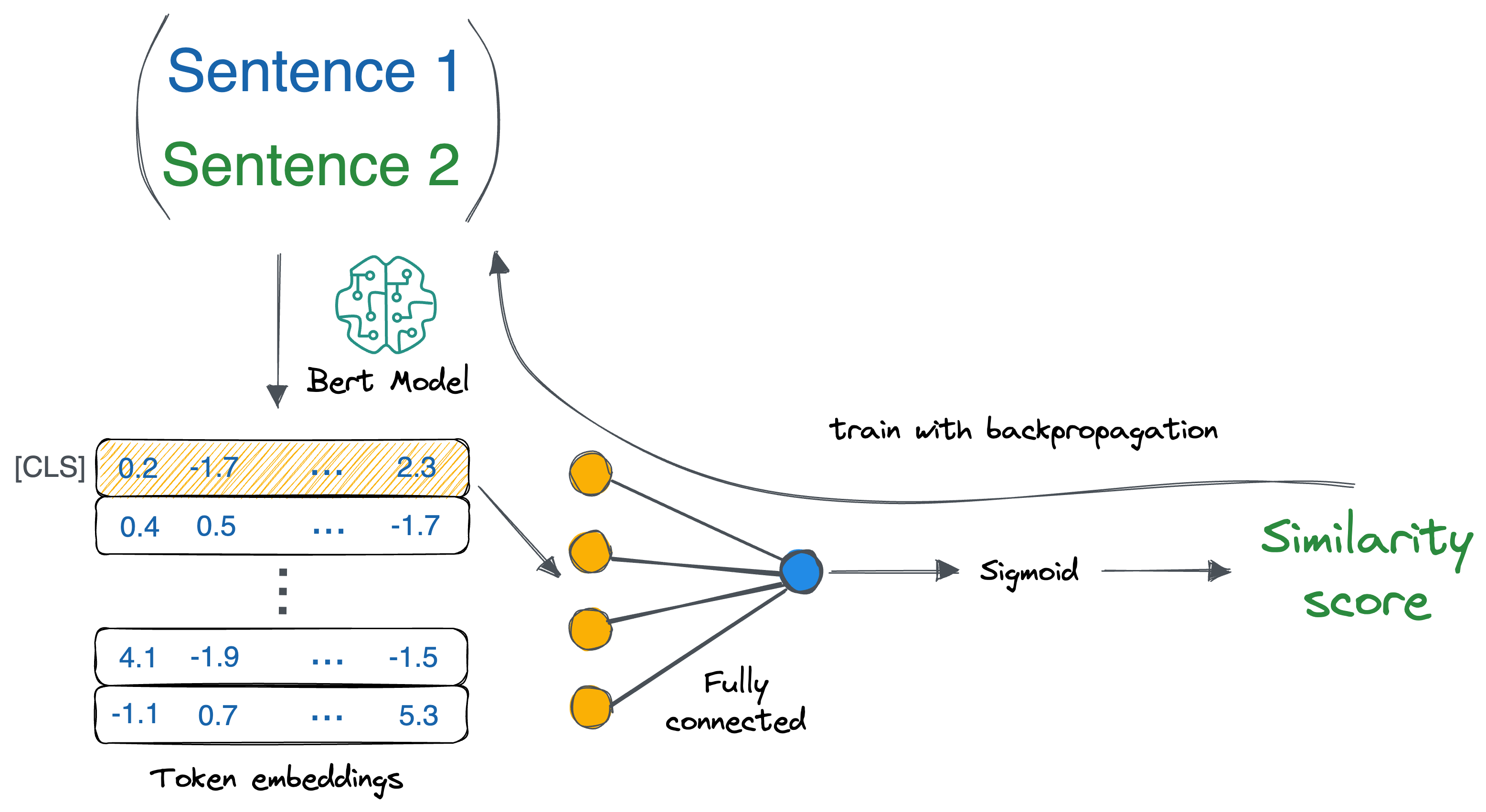
Since the model attends to both sentences simultaneously, it can capture intricate relationships and dependencies between the two, resulting in high-accuracy predictions for tasks like semantic similarity and question answering.
However, Cross-encoders are computationally expensive. Each sentence pair needs to be processed from scratch, and since independent sentence embeddings are not generated, this method doesn’t scale well to tasks like large-scale retrieval.
2) Bi-encoders
In contrast, Bi-encoders process each sentence independently. Each sentence is passed through the same model (e.g., BERT), generating reusable sentence embeddings that can be stored for later comparisons.
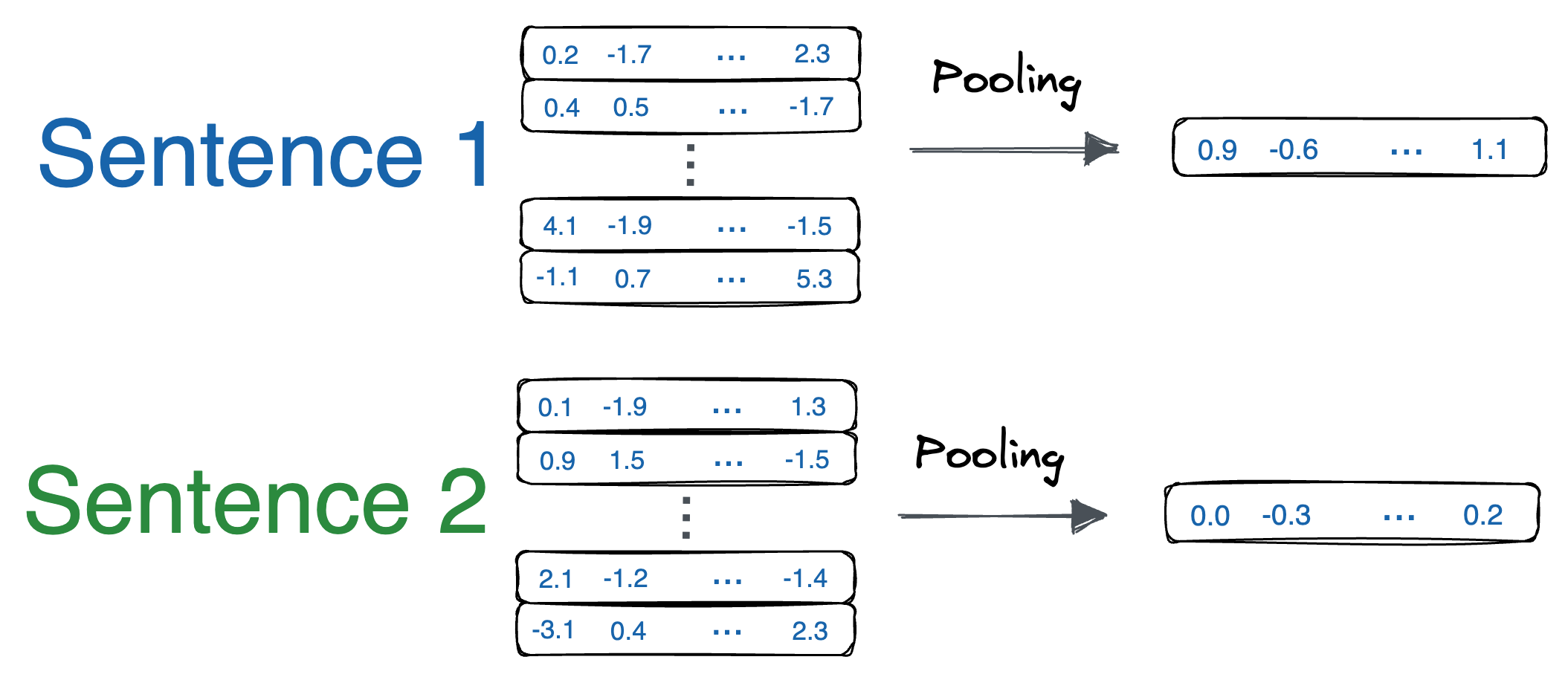
While Bi-encoders are much faster and more efficient, they tend to be less accurate because they don’t allow direct interaction between the two sentences during encoding.
This often requires Bi-encoders to be trained on much larger datasets to achieve competitive performance.
We covered this in much more detail in Part 1, so if you haven't read it yet, I would highly recommend doing so before reading this article.
That said, both methods have their place in NLP tasks, but the trade-off between efficiency and accuracy remains a challenge.
An ideal approach would be to combine the accuracy of Cross-encoders with the efficiency of Bi-encoders.

This is precisely what AugSBERT aims to achieve, which is the focus of this article.
In this article, we’ll introduce AugSBERT, a hybrid approach that uses Cross-encoders to label large datasets and Bi-encoders to quickly and effectively handle inference, leading to a solution that maximizes both performance and scalability.
First, we shall understand how it works, and then we will look at a practical implementation of this strategy, along with some nuances that you need to be careful about when building AugSBERT-like models.
Let's begin!
AugSBERT
Augmented SBERT (AugSBERT) is designed to improve Bi-encoders by leveraging Cross-encoders to label or augment training datasets.
Depending on the amount of labeled data you have, there are three key scenarios in which AugSBERT can be applied—fully labeled datasets, limited labeled datasets, and completely unlabeled datasets.
Let’s break down each scenario and the technique used to boost model performance.
1) Full labeled sentence pairs dataset
When we have a fully annotated dataset (all sentence pairs are labeled), a straightforward data augmentation strategy can be applied to extend the training data.
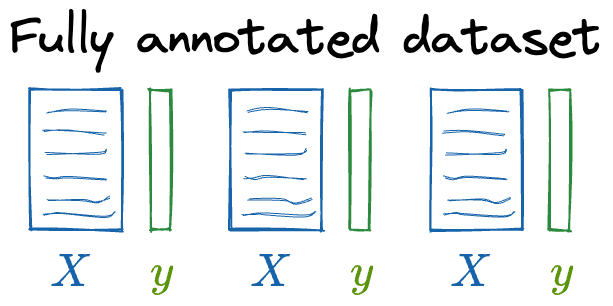
Augmenting the dataset ensures that the model is exposed to diverse variations of sentence pairs, helping the Bi-encoder generalize better.
While data augmentation in computer vision tasks is often straightforward, one thing I have observed in NLP, however, is that you have to be a bit tricky at times.
Here's a small de-tour on what I did once in one of my projects:
NER data augmentation
Data augmentation strategies are typically used during training time. The idea is to use some clever techniques to create more data from existing data, which is especially useful when you don’t have much data to begin with:
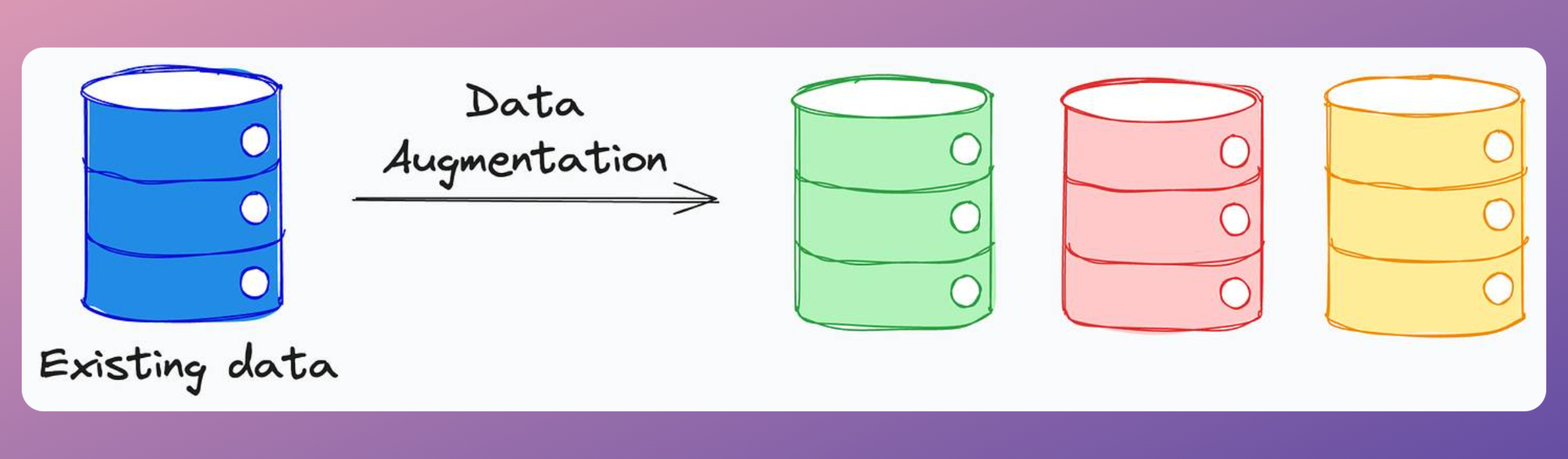
Let me give you an example.
These days, language-related ML models have become quite advanced and general-purpose. The same model can translate, summarize, identify speech tags (nouns, adjectives, etc.), and much more.
But earlier, models used to be task-specific (we have them now as well, but they are fewer than we used to have before).
- A dedicated model that would translate.
- A dedicated model that would summarize, etc.
In one particular use case, I was building a named entity recognition (NER) model, and the objective was to identify named entities.
An example is shown below:
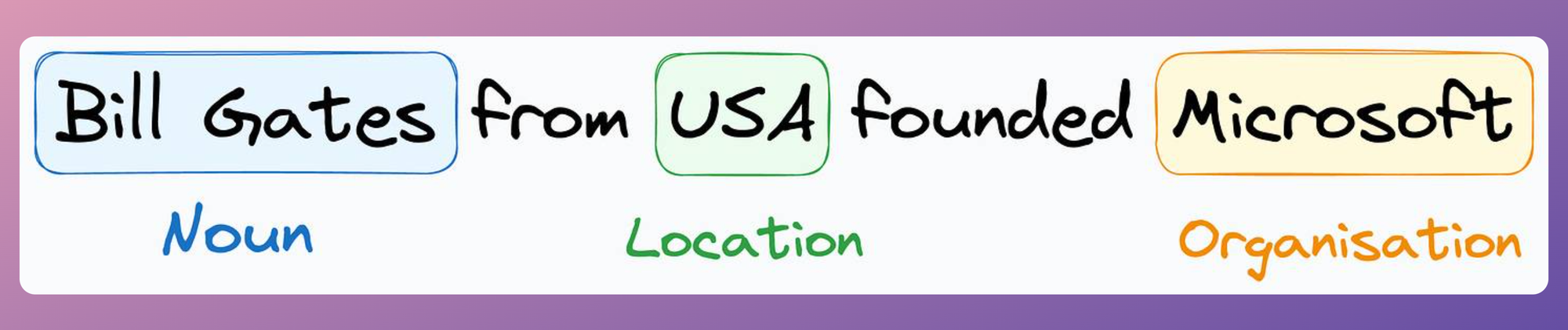
I had minimal data — around 8-10k labeled sentences. The dataset was the CoNLL 2003 NER dataset if you know it.
Here’s how I approached data augmentation in this case.
Observation: In NER, the factual correctness of the sentences does not matter.
Revisiting the above example, it would not have mattered if I had the following sentence in the training data:
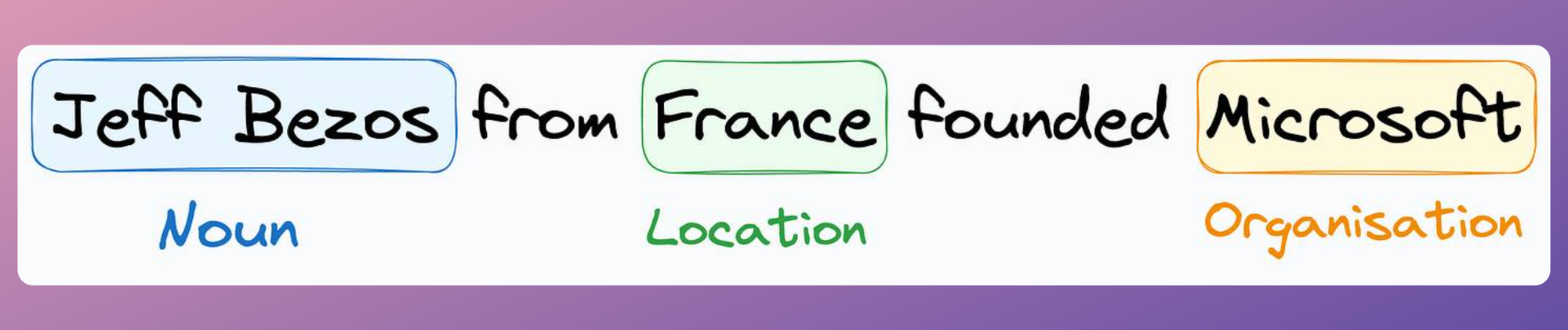
Of course, the sentence is factually incorrect, but that does not matter.
The only thing that matters to the model is that the output labels (named entity tags in this case) must be correct.
So using this observation, I created many more sentences by replacing the named entities in an existing sentence with other named entities in the whole dataset:
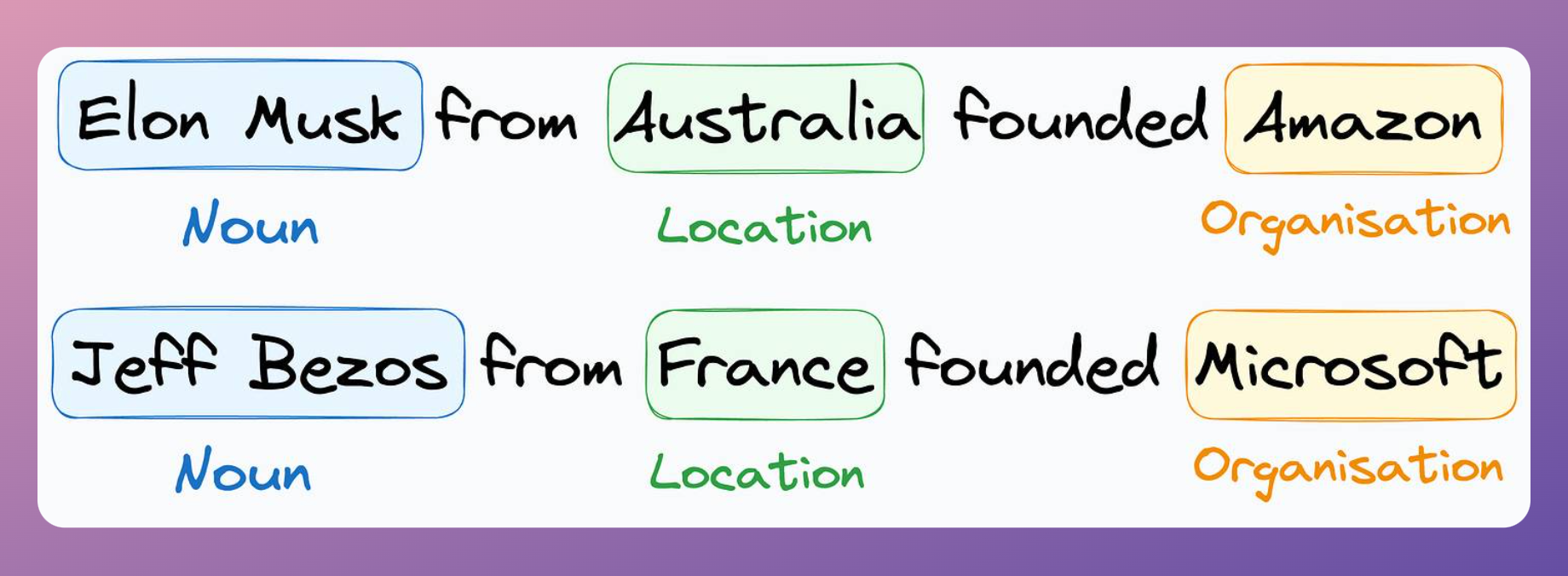
For such substitutions, I could have used named entities from outside. However, it was important to establish a fair comparison with other approaches that restricted their approach to the dataset provided for the task.
This technique (along with a couple more architectural tweaks) resulted in state-of-the-art performance. Here's the research paper I wrote:

Coming back...
Using similar augmentation strategies for sentence pair similarity scoring, we can ensure that the model is exposed to diverse variations of sentence pairs, helping the Bi-encoder generalize better.
Steps for data augmentation
Here is a detailed, step-by-step approach to applying data augmentation on fully labeled datasets:
1.1) Prepare the full labeled dataset (Gold Data)
Begin by compiling your original dataset, where each pair of sentences is annotated with a similarity label (1 for similar, 0 for dissimilar).
This dataset will serve as the "gold standard" that ensures your model learns from human-labeled, high-quality sentence pairs.
For instance:
Sentence 1: "What is artificial intelligence?"
Sentence 2: "Explain artificial intelligence."
Label: 1 (Similar)
1.2) Apply word-level augmentation
Word-Level Augmentation involves modifying words in sentence pairs while preserving the overall meaning.
This can be done by substituting words with their synonyms or using contextual word embeddings. Here are the key techniques used: