LLMs
Verbalized Sampling in LLMs
...explained with usage.

Avi Chawla
...explained with usage.
Post-training alignment methods, such as RLHF, are designed to make LLMs helpful and safe.
However, these methods unintentionally cause a significant drop in output diversity (called mode collapse).
When an LLM collapses to a mode, it starts favoring a narrow set of predictable or stereotypical responses over other outputs.
According to a paper, mode collapse happens because the human preference data used to train the LLM has a hidden flaw called typicality bias.

Here’s how this happens:
That said, this is not an irreversible effect, and the LLM still has two personalities after alignment:
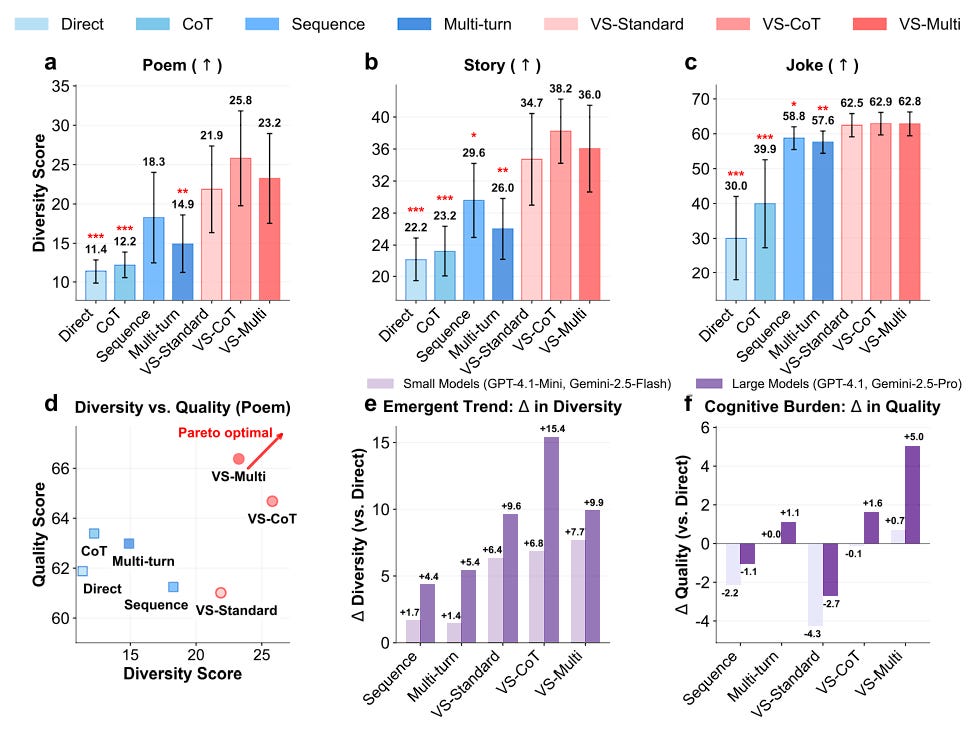
Verbalized sampling (VS) solves this.
It is a training-free prompting strategy introduced to circumvent mode collapse and recover the diverse distribution learned during pre-training.

The core idea of verbalized sampling is that the prompt itself acts like a mental switch.
When you directly prompt “Tell me a joke”, the aligned personality immediately takes over and outputs the most reinforced answer.
But in verbalized sampling, you prompt it with “Generate 5 responses with their corresponding probabilities. Tell me a joke.”
In this case, the prompt does not request an instance, but a distribution.
This causes the aligned model to talk about its full knowledge and is forced to utilize the diverse distribution it learned during pre-training.
So essentially, by asking the LLM to verbalize the probability distribution, the model is able to tap into the broader, diverse set of ideas, which comes from the rich distribution that still exists inside its core pre-trained weights.
Experiments across various tasks demonstrate significant benefits:
👉 Over to you: What other methods can be used to improve LLM diversity?
Thanks for reading!