How to Structure Your Code for Machine Learning Development
A highly overlooked yet critical skill for data scientists.
Introduction
Do you know one of the biggest hurdles data science and machine learning teams face?
It is transitioning their data-driven pipeline from Jupyter Notebooks to an executable, reproducible, error-free, and organized pipeline.
And this is not something data scientists are particularly fond of doing.
Yet, this is an immensely critical skill that many overlook.
Machine learning deserves the rigor of any software engineering field. Training codes should always be reusable, modular, scalable, testable, maintainable, and well-documented.
To help you develop that critical skill, I'm excited to bring you a special guest post by Damien Benveniste. He is the author of The AiEdge newsletter and was a Machine Learning Tech Lead at Meta.

In today’s machine learning deep dive, he will provide a detailed guide on structuring code for machine learning development, one of the most critical yet overlooked skills by many data scientists.
I personally learned a lot from this one and I am sure you will learn a lot too.
Let’s begin!
I have always believed that machine learning deserves the rigor of any software engineering field. Training codes should be reusable, modular, scalable, testable, maintainable, and well-documented.
Today, I want to show you my template to develop quality code for machine learning development.
More specifically, we will look at:
- What does coding mean?
- Designing:
- System design
- Deployment process
- Class diagram
- The code structure:
- Directory structure
- Setting up the virtual environment
- The code skeleton
- The applications
- Implementing the training pipeline
- Saving the model binary
- Improving the code readability:
- Docstrings
- Type hinting
- Packaging the project
What does coding mean?
I often see many Data Scientists or Machine Learning Engineers developing in Jupyter notebooks, copy-pasting their codes from one place to another, which gives me nightmares!
When running ML experiments, Jupyter is prone to human errors as different cells can be run in different orders. Yet, ideally, you should be able to capture all the configurations of an experiment to ensure reproducibility.
No doubt, Jupyter can be used to call a training package or an API and manually orchestrate experiments, but fully developing in Jupyter is an extremely risky practice.
For instance, when training a model, you should ensure the data is passed through the exact feature processing pipelines at serving (inference) time. This means using the same classes, methods, and identical versions of packages and hardware (GPU vs. CPU).
Personally, I prefer prototyping in Jupyter but developing in Pycharm or VSCode.
When programming, focus on the following aspects:
- Reusability:
- It is the capacity to reuse code in another context or project without significant modifications.
- Code reusability can be achieved in several ways, such as through libraries, frameworks, modules, and object-oriented programming techniques.
- In addition, good documentation and clear code organization also facilitate code reuse by making it easier for other developers to understand and use the code.
- Modularity:
- It is the practice of breaking down a software system into smaller, independent modules or components that can be developed, tested, and maintained separately.
- Scalability:
- It refers to the ability of a software development codebase to accommodate the growth and evolution of a software system over time. In other words, it refers to the ability of the codebase to adapt to changing requirements, features, and functionalities while maintaining its overall structure, quality, and performance.
- To achieve codebase scalability, it is important to establish clear coding standards and practices from the outset, such as using version control, code review, and continuous integration and deployment.
- In addition, it is important to prioritize code maintainability and readability, as well as the use of well-documented code and clear naming conventions.
- Testability:
- It refers to the ease with which software code can be tested to ensure that it meets the requirements and specifications of the software system.
- It can be achieved by designing code with testing in mind rather than treating testing as an afterthought. This can involve writing code that is modular, well-organized, and easy to understand and maintain, as well as using tools and techniques that support automated testing and continuous integration.
- Maintainability:
- It refers to the ease with which software code can be modified, updated, and extended over time.
- Documentation:
- It provides a means for developers, users, and other stakeholders to understand how the software system works, its features, and how to interact with it.
Designing
System design
In Machine Learning, like any engineering domain, no line of code should be written until a proper design is established.
Having a design means that we can translate a business problem into a machine learning solution, provided ML is indeed the right solution to the problem!
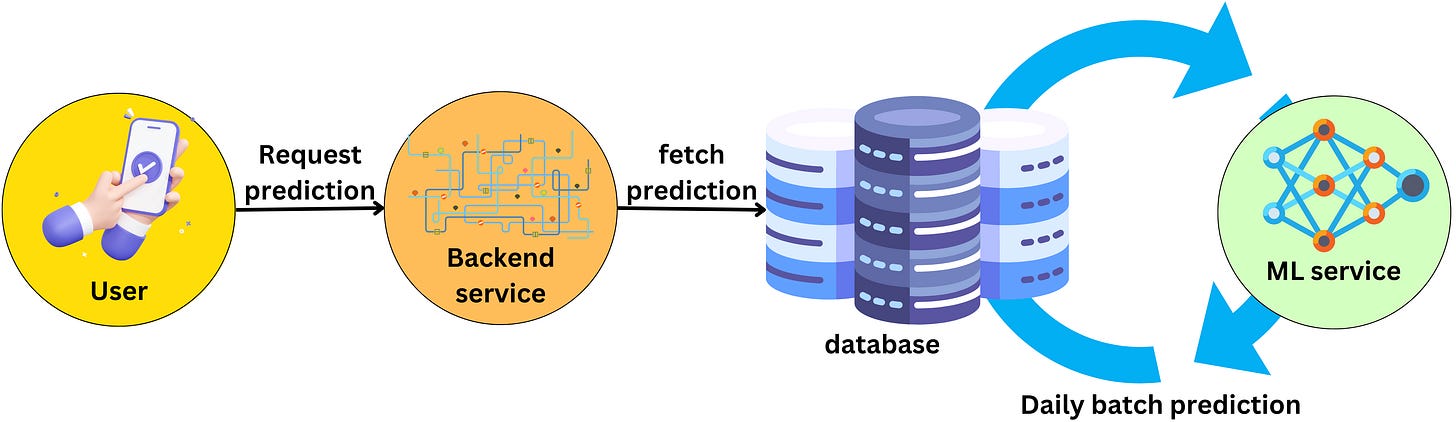
For simplicity, let’s assume we want to build a mobile application where a user needs machine learning predictions displayed on the screen — personalized product recommendations, for instance.
The process workflow may appear as follows:
- The mobile application requests personalized predictions from the backend server.
- The backend server fetches predictions from a database.
- We figured that daily batch predictions were the most appropriate setup for now, and the machine learning service updates the predictions daily.
This process is depicted in the image below:
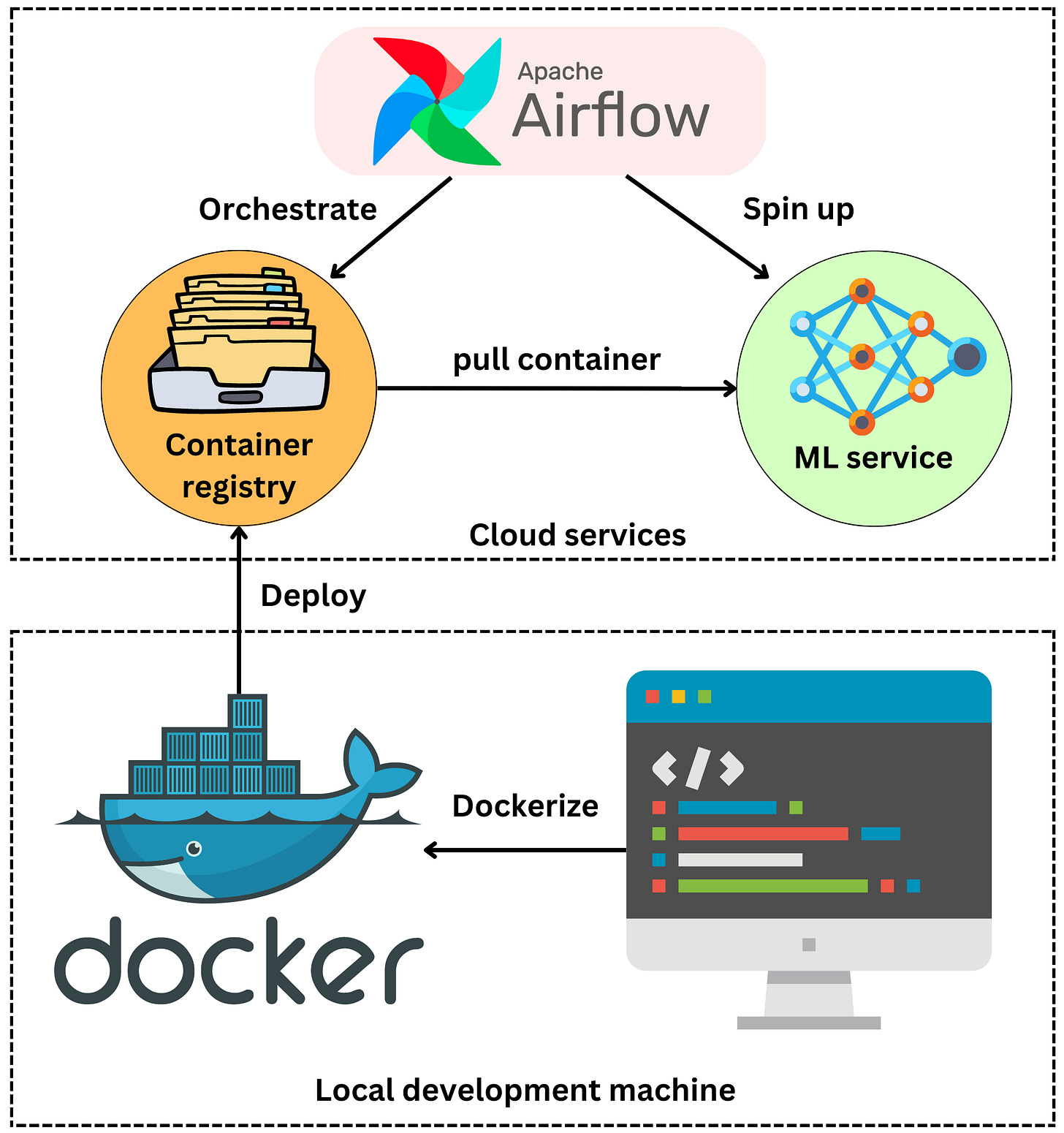
Deployment process
Before we can understand how to develop our model, we need to understand how we will deploy it. Let’s assume that, for our purposes, an inference application will be containerized in a Docker container.
The container can be deployed in a container registry such as AWS ECR (Amazon Elastic Container Registry) or Docker Hub. We can have an orchestration system such as Airflow that spins up the inference service, pulls the container from the registry, and runs the inference application.
Class diagram
Now that we know what we need to build and how it will be deployed, how we need to structure our codebase is becoming much clearer.
More specifically, we shall build two applications:
- An inference application.
- A training application.
To minimize potential human errors, it is imperative that the modules used at training time are the same as the ones used at inference time.
Let’s look at the following class diagram:
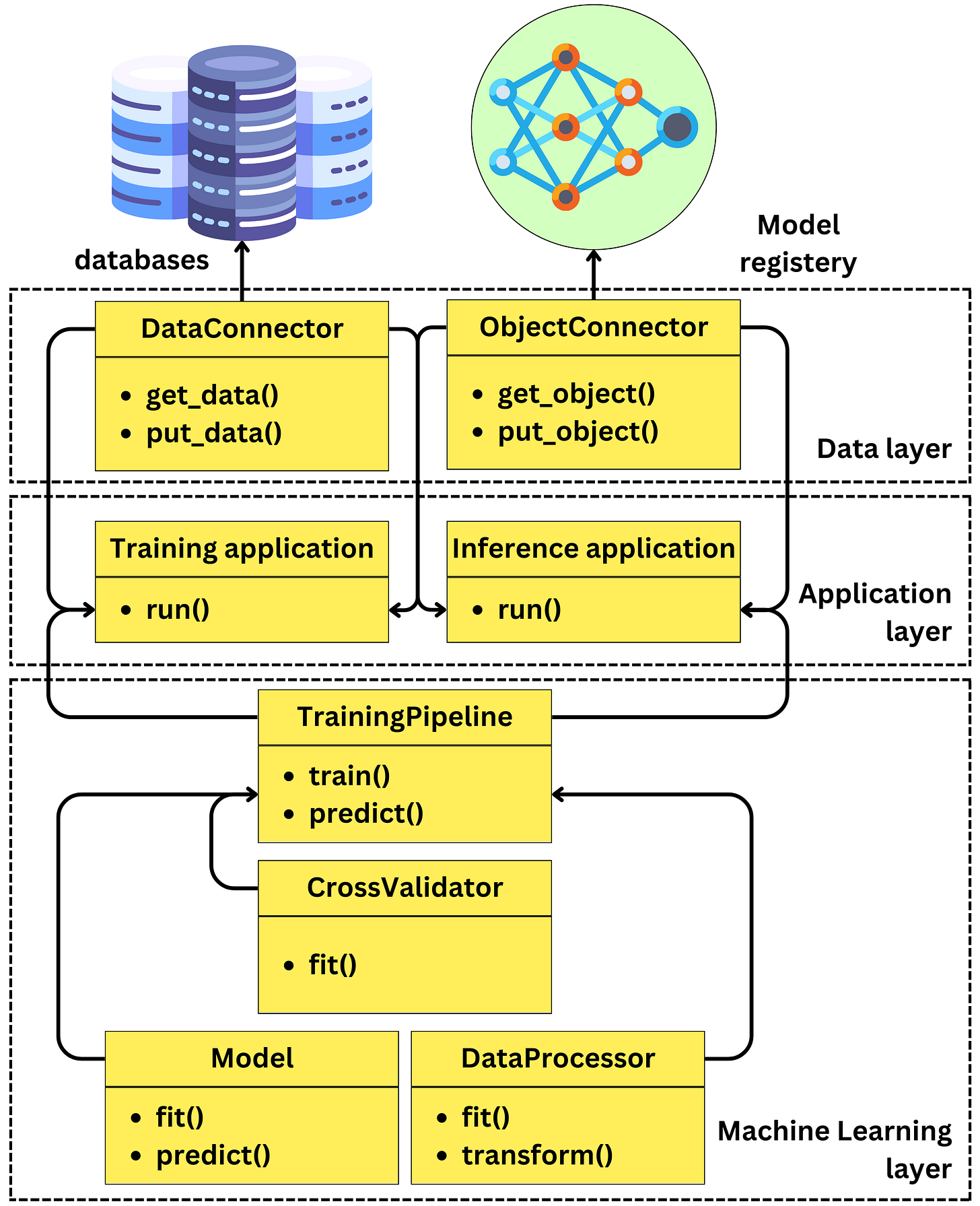
- The application layer:
- This part of the code captures the application’s logic. Think about these modules as “buttons” that start the inference or training processes.
- We will have a
run()function for each of those applications that will serve as handles for the Docker image to start those individual processes.
- The data layer:
- This is the abstraction layer that moves data in and out of the applications. I am calling it the “data” layer, but I am including anything that needs to go into the outside world, like the data, the model binaries, the data transformer, the training metadata, etc.
- In this batch use case, we are just going to need a function that brings the data into the applications
get_data()and another that puts predictions back into the databaseput_data().- The
DataConnectorclass moves data around. - The
ObjectConnectoris the actor responsible for transferring model binaries and data transformation pipelines usingget_object()andput_object().
- The
- The machine learning layer: This is the module where all the different machine learning components will live. The three components of model training are:
- Learning the parameters of the model: the
Modelwill take care of that with thefit()method. For inferring, we use thepredict()method. - Learning the features transformations: We may need to normalize features, perform Box-Cox transformations, one-hot encode, etc… The
DataProcessorwill take care of that with thefit()andtransform()methods. - Learning the hyperparameters of the model and data pipeline: the
CrossValidatorwill handle this task with itsfit()function.
The TrainingPipeline will handle the logic between the different components.
The code structure
Directory structure
Now that we have a class diagram, we must map it into actual code. Let’s call the project machine_learning_service.
Of course, there are many ways to do it, but we will organize the project as follows:
- The “docs” folder: for the documents.
- The “src” folder: for the source code (or the actual codebase).
- The “tests” folder: for the unit tests.
Setting the virtual environment
Going ahead, we assume we will Dockerize this project at some point. Thus, controlling the Python version and packages we use locally is crucial.
To do that, we will create a virtual environment called env using venv, an open-source package that allows us to create virtual environments effortlessly.
First, within the project folder, we run the following command to create a virtual environment:
Next, we activate it as follows:
Once done, we should see the following directory structure:
In the current directory, let’s check the Python version that is running so that we can use the Python binaries of the virtual environment. We do this using the which command, as demonstrated below:
Next, let’s make sure that the Python version is Python 3:
Okay, we are good to go!
The code skeleton
Within the source folder, let’s create the different modules we have in the class diagram:
For now, let’s have empty classes.
- The
Modelclass: This will be responsible for training the model on new data and predicting on unseen data:
- The
DataProcessorclass: This handles the processing needed before the data is fed to the ML model, such as normalization, transformation, etc.