Develop an Elegant Testing Framework For Data Science Projects Using Pytest
A Comprehensive Guide to Pytest for data scientists.
Motivation
One of the biggest hurdles data science teams face is transitioning their data-driven pipeline from Jupyter notebooks to executable, reproducible, and organized files comprising functions and classes.
This involves building an error-free, well-tested pipeline that can be executed reliably.
For instance, imagine a situation where we wrote a function in our data pipeline that divides two numbers:
While working in a Jupyter Notebook, we, as the programmer, know what should go as an input and what to expect as an output.
But transitioning that directly to a data pipeline without testing and error handling can easily lead to pipeline failures.
Therefore, to alleviate errors in the data pipeline and ensure it works as expected, testing them against different example inputs (or data situations) becomes super important.
In other words, this boils down to creating a reliable automation framework for the pipeline.
For starters, an automation framework is an organized approach to writing test cases, executing them, and reporting the results of testing automation.
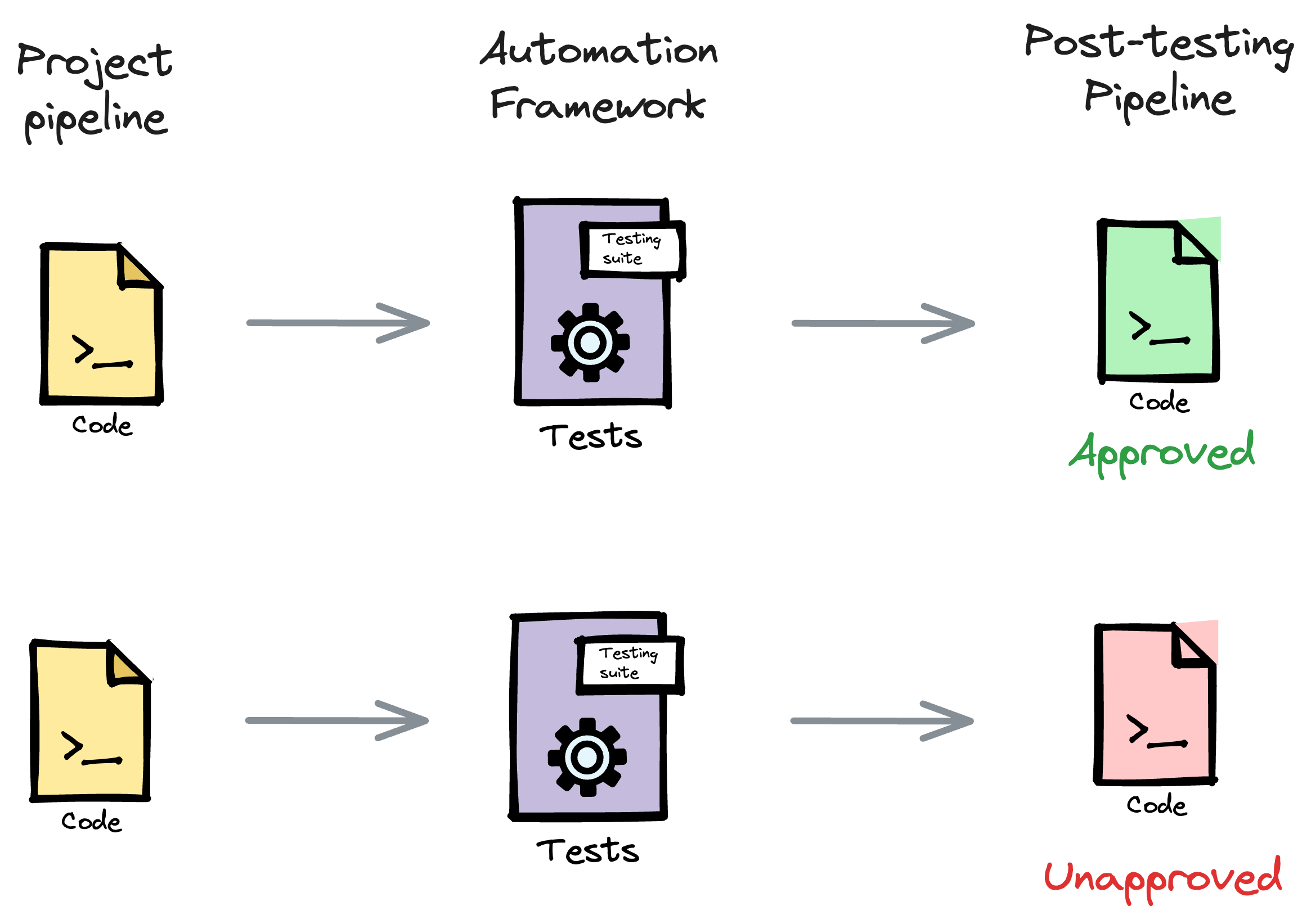
We should always test our data pipeline because it:
- Ensures that the code works as expected end-to-end — improving reliability.
- Helps us in detecting edge cases where different methods might fail.
- Allows other team members to understand our code with the help of our tests — reducing code complexity.
- Assists in swapping an existing code with an optimized/improved version without interfering with other functions.
- Supports in generating actionable insights about the code, such as run-time, expected input/output, etc.
Thankfully, Python provides a handful of open-source libraries such as unittest, nose, behave, etc.
But the one that stands out due to its ease of use and flexibility is Pytest.
Therefore, in this article, we’ll do a detailed walkthrough on leveraging Pytest to build a testing suite for our Python project.
Let’s begin 🚀!
Getting Started with Pytest
To begin, Pytest is a testing framework for writing test suites, executing them on a pipeline, and generating test reports.
The best thing about Pytest is its intuitive and uncomplicated process of integrating it with the data pipeline.
Testing is already a job that data scientists don’t look forward to with much interest.
Considering this, Pytest makes it easy to write test suites, which in turn, immensely helps in determining the reliability of a data science project.
To install Pytest, execute the following command:
Next, we import Pytest to leverage its core testing functionalities.
With this, we are ready to write test cases and execute them.
Putting Pytest at Work
Let’s define a divide_two_numbers() method in project.py.
Next, let’s create a separate file for tests (test_file.py).
For the method we defined above (divide_two_numbers()), let’s write a test function. This will check the output data type returned by the method against different inputs.
Here, the second test case is kept intentionally to raise an error.
To execute this test function, open the command line in the current working directory and run the command pytest:
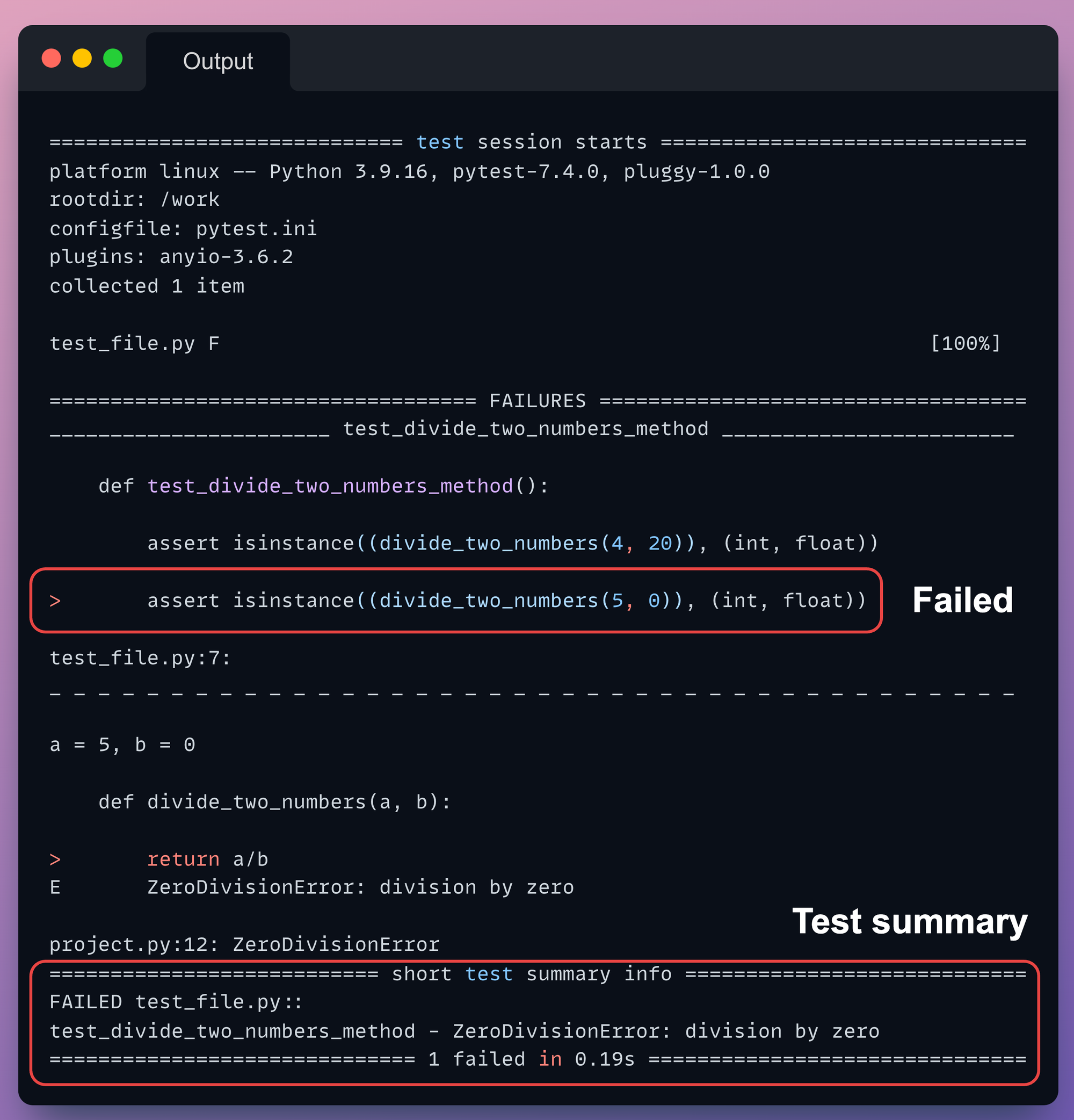
Pytest gives a comprehensive testing summary of our pipeline.
It shows the files it collected to run tests from, test_file.py in this case.
Next, all test failures are listed separately with their respective errors.
Lastly, we also get a test summary.
As expected, the method failed on the second assertion, in which the denominator was zero.
This allows us to update our function to handle such cases.
All this is fine, but now we should ask two questions:
- In the above
pytestcommand, we never specified the name of the test file. However, in the results, we see a mention oftest_file.pyonly. How did Pytest infer thattest_file.pyis the specific file we have listed all our test cases in? - Next, how did Pytest find the methods it needs to execute? In other words, how did Pytest differentiate the
divide_two_numbers()from thetest_divide_two_numbers_method()and figured out that test cases are listed in the latter method.
The answer lies in the technique of “Test Searching” (also called “Test Discovery”) in Pytest.
Let’s understand.
Test Searching in Pytest
Pytest implements the following test discovery method to find test functions, files, and Python classes: