Building with MCP and LangGraph
MCP Part 9: Building a full-fledged research assistant with MCP and LangGraph.
Recap
In Part 8, we broadened our scope beyond core MCP and explored its integration into agentic frameworks. Specifically, we examined how MCP can be embedded into Agentic workflows built using LangGraph, CrewAI, LlamaIndex, and PydanticAI.
We evaluated the feature support and limitations of each integration, diving into both the practical implementation details and the underlying concepts.
Through in-depth code walkthroughs and theoretical discussions, we built a comprehensive understanding of how each framework interacts with MCP.
If you haven’t explored Part 8 yet, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
You can read it below:
In this part
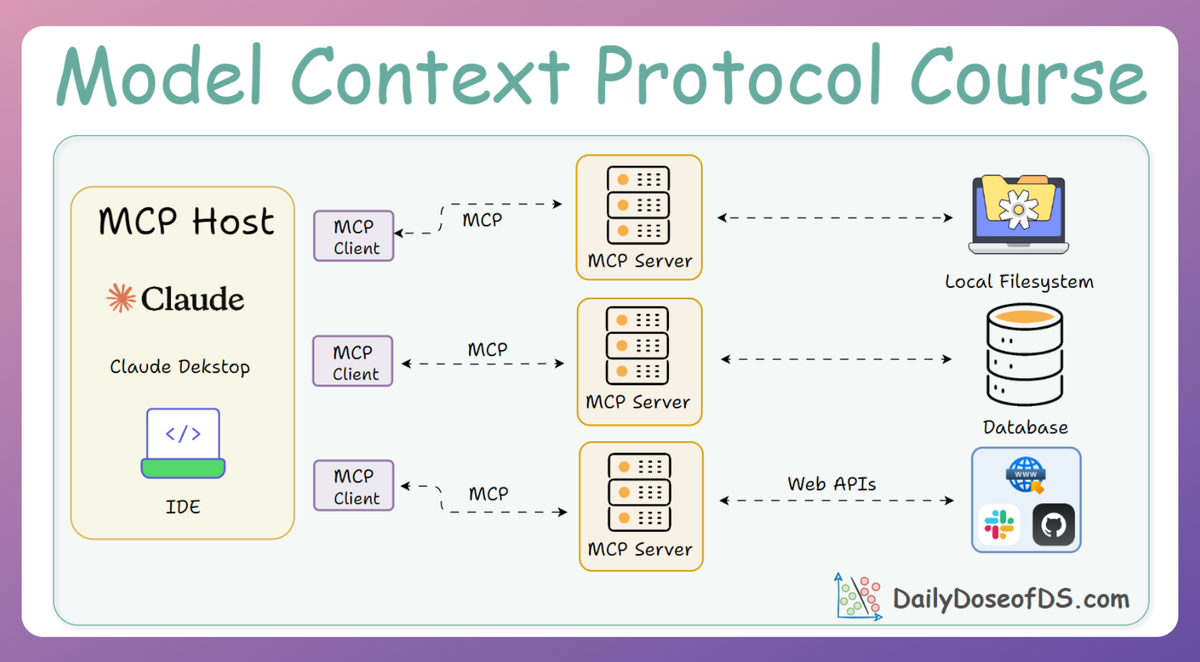
In this chapter, we’ll focus exclusively on the LangGraph framework and its integration with MCP.
LangGraph is widely regarded as the leading choice for building production-grade agentic systems. We’ll take a deeper dive into LangGraph workflows and integration patterns for MCP by working through a comprehensive real-world use case: a Deep Research Assistant.
Before diving in, it’s important to ensure you have a solid understanding of the fundamentals of AI agents and RAG (Retrieval-Augmented Generation) systems. If you’d like to brush up on these concepts, we recommend exploring the resources below:
Like always, this chapter is entirely practical and hands-on, so it’s crucial that you actively follow along.
Each and every idea will be accompanied by detailed implementations, ensuring that you not only grasp the idea behind it but can also adopt it into your own projects.
Let’s begin.
Ideation
Before diving into the code, let's first focus on system-level thinking of what we are building, the design goals, and the modularity.
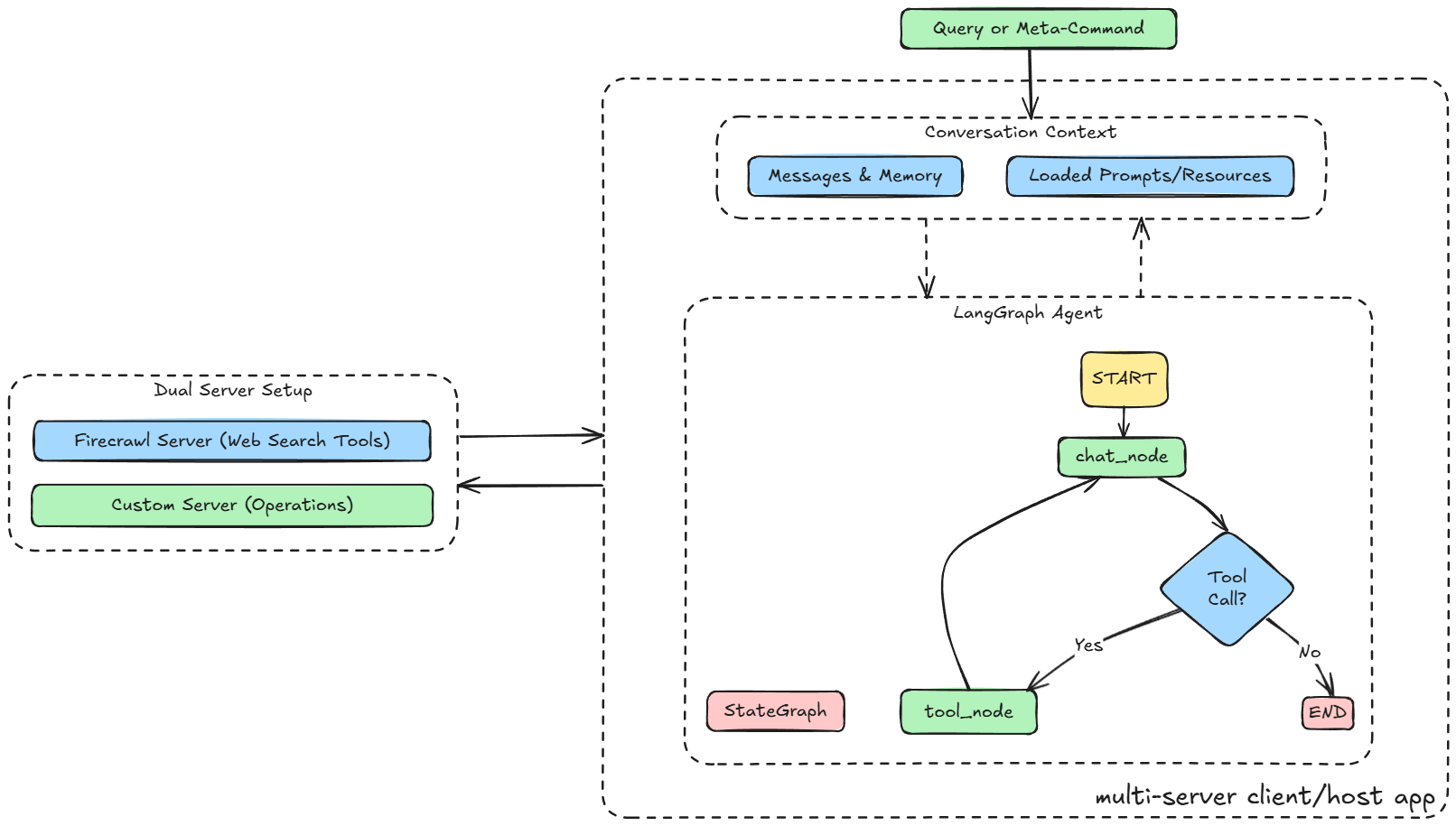
Our prime focus is to build a sophisticated yet modular architecture for a Deep Research Assistant, built using LangGraph and MCP.

The assistant must be designed such that it is an extensible, agentic system designed to reason, plan, and act across tools, resources, and prompts while maintaining stateful dialogues.
The system must combine LangGraph's agentic orchestration with MCP's structured tool, prompt, and resource management.
The assistant can leverage a graph-based reasoning, switch between multiple servers, and accept dynamic instructions from users who virtually retain control over the flow via queries and structured meta-commands.
Core capabilities and architecture
The Deep Research Assistant operates as a stateful LangGraph agent, powered by a dual-server MCP client. The system connects to:
- A custom research server, exposing vector storage tools, prompts, and FAISS-based semantic search.
- The Firecrawl MCP server, capable of live web searching/scraping and data extraction from the internet.

At the core lies a StateGraph, which defines how messages flow, how and when tools are used, and how the conversation state evolves over time.
Here's a flowchart of the same:
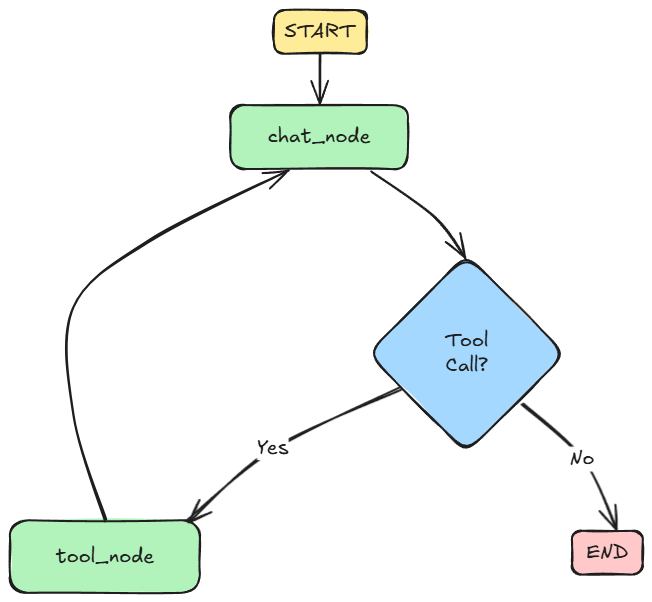
Instead of a traditional linear chat loop, the system follows a graph of conditional logic, enabling flexible transitions based on whether tools are needed, whether follow-ups are requested, or whether a user invokes a specific prompt or resource.
If this is getting too much to digest, don't worry. The implementation details will make everything clear pretty soon.
User-guided orchestration with meta-commands
One of the defining aspects of this system must be user control.
Instead of hiding context management behind the scenes, users should be able to explicitly guide the assistant using intuitive commands like:
@prompt:<name>to load MCP prompts.@resource:<uri>to load MCP resources.@use_resource:<uri> <query>to use MCP resources.

RAG as a tool
Instead of building a fixed, all-in-one RAG pipeline, we use a more flexible approach.
We treat RAG as a set of tools that can be used whenever needed, like saving data, retrieving context, or answering questions.
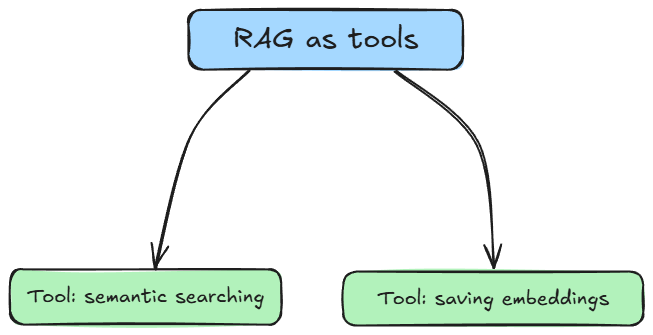
This makes the system more modular. RAG isn’t something that runs every time by default. It’s just one of the tools the agent can use when it makes sense.
Modular tooling and extensibility
Each MCP server would act as a capability provider, exposing tools, prompts, and resources independently. This makes the entire ecosystem swappable and extensible.
To add a new tool, just add it to the server, and it becomes readily available in the Agent’s toolset. The system supports scaling horizontally across domains.
LangGraph as the orchestrator
LangGraph would play a vital role in giving this system structured memory and decision-making control.
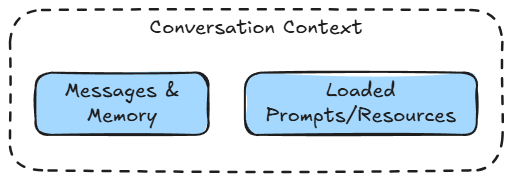
Unlike stateless LLM chains, LangGraph allows the assistant to maintain a chain-of-thought, conditionally branch based on whether a tool call is required, and reintegrate tool outputs into future decisions.
This is essential for such applications that require research and exploration, where context from earlier conversations, resources, or tool outputs must inform current decisions. It also opens up possibilities for multi-step research flows.
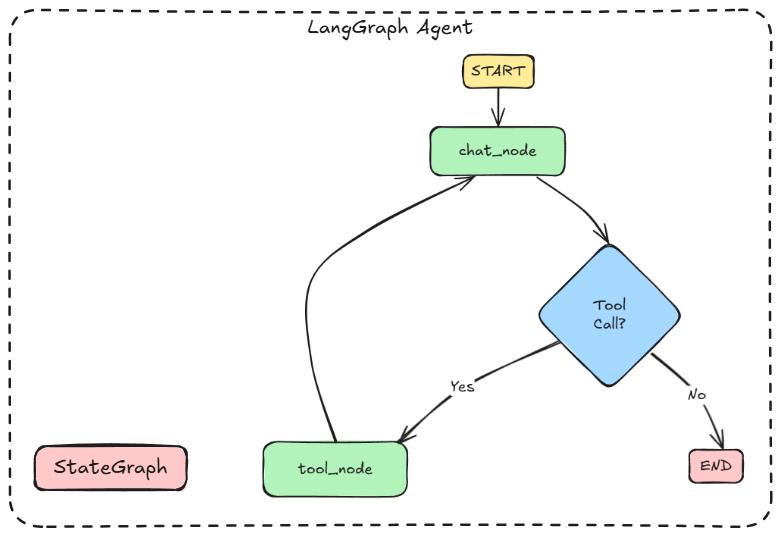
Here is the complete flow summarized as a diagram:
Now that we have a clear blueprint on how to proceed, let's get started with setting up the project.
Project setup
We'll be implementing one custom MCP server and also using the prebuilt Firecrawl MCP server.
We would be requiring npm for installing the Firecrawl MCP server. For that, we need to make sure we have Node.js (v22 or later) on our machine.
To download and set up Node.js on your system based on your operating system, check out the official installation guide linked below:

Or you can watch video tutorials as per your OS:
Once we have Node.js up and running, we'll set up our Firecrawl MCP server with:
Note: We'll be focusing our implementation on STDIO transport. Thus, we are installing the Firecrawl MCP server on our machine.
However, if you do not wish to set up the server on your machine, you may also use the remotely hosted URL of the Firecrawl MCP server:
After this, we'll set up a Python project. The codes and project setup we are using are attached below as a zip file. You can simply extract it and run uv sync command to get going. It is recommended to follow the instructions in the README file to get started.

Download the zip file below: