Data and Pipeline Engineering: Distributed Processing and Workflow Orchestration
MLOps Part 7: An applied look at distributed data processing with Spark and workflow orchestration and scheduling with Prefect.
Recap
In Part 6 of this MLOps and LLMOps crash course, we explored some of the crucial and advanced concepts related to the data phase of the ML system lifecycle.
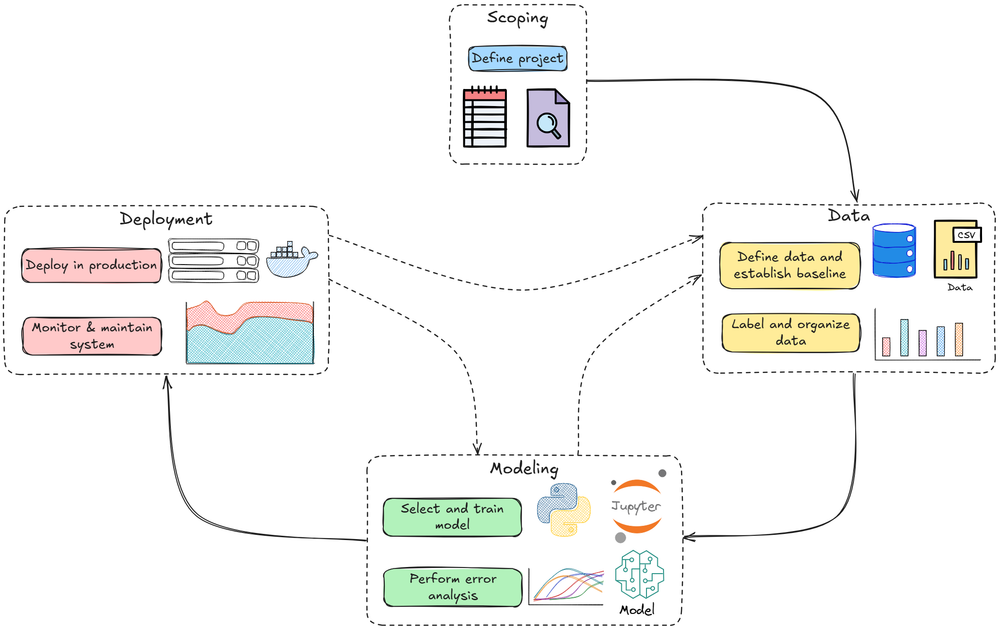
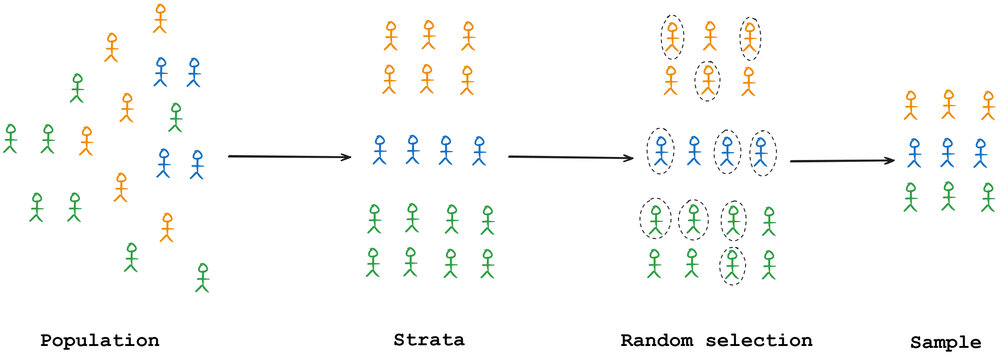
We began by exploring the concept of sampling, followed by an overview of various sampling strategies, categorized under probabilistic and non-probabilistic methods.
Next, we examined the concept of class imbalance and explored various techniques to address it, such as SMOTE, focal loss, and other resampling and algorithmic approaches.

We then explored the issue of data leakage, discussed its various types, and reviewed best practices to prevent it effectively.
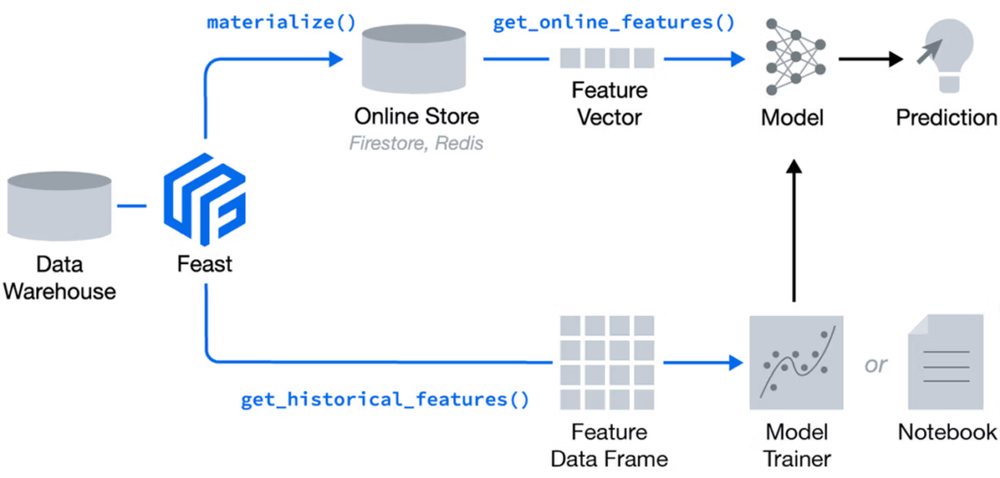
We also explored the concept and rationale behind feature stores, taking a deep dive into the Feast framework.
Finally, we completed an in-depth, hands-on tutorial on implementing a leakage-safe machine learning pipeline using the Feast feature store.
If you haven’t explored Part 6 yet, we strongly recommend going through it first since it lays the conceptual scaffolding that’ll help you better understand what we’re about to dive into here.
You can read it below:

In this chapter, we’ll continue with data processing and management in ML systems, diving deeper into practical implementations.
What we’ll cover:
- Introduction to Apache Spark
- Apache Spark vs. Pandas comparison
- Orchestration and workflow management: scheduling and automating pipelines with Prefect.
As always, every notion will be backed by concrete examples, walkthroughs, and practical tips to help you master both the idea and the implementation.
Let’s begin!
Distributed data processing with Apache Spark
As data volumes grow, single-machine tools (Pandas, NumPy) may start to falter. Enter Apache Spark, a distributed computing engine widely used for big data processing.
It plays a significant role in many MLOps pipelines where data is large or needs to be processed in parallel. Spark allows you to handle datasets that don't fit in memory by distributing them across multiple machines and performing computations in parallel.
What is Spark?
Spark is a cluster computing framework that provides an API for distributed data structures (like Resilient Distributed Datasets (RDDs), and higher-level DataFrames) and operations on them.

Spark is written in Scala but provides bindings for Python (PySpark), Java, R, etc. For ML pipelines, the two key aspects of Spark are:
- The DataFrame API (a similar concept to pandas DataFrame, but distributed).
- The Spark MLlib, which includes its own pipeline and machine learning algorithms that can run in a distributed manner.
Note: We’ve already explored Apache Spark in depth. In this chapter, our primary focus will be on understanding its role in MLOps and how it compares to Pandas in that context. If you're new to Spark, we recommend reviewing the article linked below before proceeding.

Spark DataFrame
Spark’s DataFrame is conceptually like a table distributed across a cluster. You can perform SQL-like operations, filter, join, group, etc., and Spark will automatically parallelize these operations.
Under the hood, Spark DataFrames are built on RDDs but provide optimizations through the Catalyst query optimizer.
The codes look similar to Pandas code, but Spark can run on a very large dataset spread across different machines. Spark will partition the data and run tasks on each partition in parallel. The data is not all loaded into one memory (each worker holds a chunk).
Spark for ETL in ML
A lot of data engineering pipelines use Spark to do heavy lifting:
- reading from data lakes
- joining large tables
- computing features like aggregations
Spark can then output the result to a storage (maybe writing a Parquet file), which is then used by model training. Or, one can use Spark to directly train models on large data via MLlib.
Spark MLlib and pipelines
Spark MLlib is the library of machine learning algorithms in Spark. It has its own Pipeline class analogous to scikit-learn’s.
For instance, Spark has Imputer, VectorAssembler (to combine features into a vector), and algorithms like LinearRegression in a distributed form.
An example Spark ML pipeline might look like the one in the attached notebook below: