Reproducibility and Versioning in ML Systems: Fundamentals of Repeatable and Traceable Setups
MLOps Part 3: A practical exploration of reproducibility and versioning, covering deterministic training, data and model versioning, and experiment tracking.
Recap
Before we dive into Part 3 of this MLOps and LLMOps crash course, let’s briefly recap what we covered in the previous part of this course.
In Part 2, we studied the ML system lifecycle in depth, breaking down the different stages into detailed explanations.
We started by understanding the first phase of the ML system lifecycle: data pipelines. It involved crucial concepts like ingestion, storage, ETL, labeling/annotation, and data versioning.
Next, we checked out the model training and experimentation phase, where we discussed crucial ideas related to experiment tracking, model selection, validation, training pipeline, resource management, and hyperparameter configuration.

Moving further, we explored the deployment and inference stage. We went deep by understanding things like model packaging, inference, and deployment methodologies, testing, model registry, and CI/CD.
After deployment and inference, we went ahead and understood monitoring and observability. There, we checked out operational monitoring, drift, and performance monitoring.
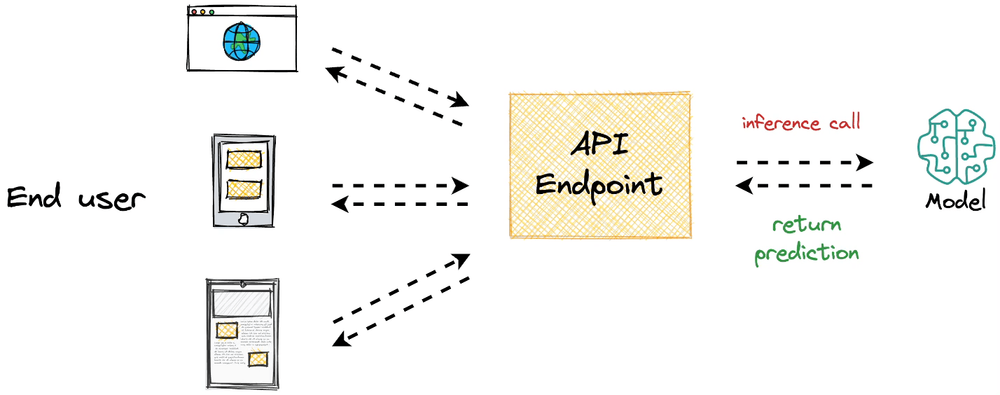
Finally, we walked through a quick hands-on simulation, where we studied how we serialize models, convert them into a FastAPI service, test them, and containerize for reproducibility and deployment considerations.
If you haven’t yet studied Part 2, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
You can find it below:

In this chapter, we'll explore reproducibility and versioning for ML systems, focusing on the key theoretical details and hands-on implementations, wherever needed.
As always, every notion will be explained through clear examples and walkthroughs to develop a clear understanding.
Let’s begin!
Introduction
One topic we’ve touched on throughout, but which deserves focused attention, is reproducibility.
As the name suggests, reproducibility means that you can repeat an experiment or process and get the same results. In ML, this is critical for trust and collaboration.
If someone else (or you in the future) cannot reproduce your model’s training, it’s hard to debug issues or improve upon it.
Reproducibility also ties closely with versioning, because to reproduce an experiment, you need to know exactly which code, data, and parameters were used.
Let’s break down why this matters and how to achieve it in production ML systems.
Why reproducibility matters
With whatever we have learnt so far, we well understand the fact that reproducibility is quite critical for production-grade systems.
So let's expand upon our understanding and see the key factors that make reproducibility and versioning so important.
Debugging and error tracking
If a model’s performance suddenly drops or if there is a discrepancy between offline and online behavior, being able to reproduce the training process exactly as it was can help pinpoint the cause.
For instance, was it a code change? A new version of a library? A different random seed? Without reproducibility, you’re effectively chasing a moving target.
Collaboration
In a team, one engineer might want to rerun another’s experiment to verify results or build on it. If it’s not reproducible, it slows down progress.
Reproducing someone’s work should be as easy as pulling their code and data and running a script, not a guessing game of “what environment did you use?”.
Regulations and compliance
In certain industries like healthcare, finance, or autonomous vehicles, you might need to prove how a model was built and that it behaves consistently.
For example, a bank might need to show regulators the exact training procedure that led to a credit risk model and that running it again on the same data yields the same outcome.
Continuity
Personnel changes happen, maybe the original author of a model leaves the company.
If the process is well-documented and reproducible, the next person can pick it up. If not, organizations risk losing the “knowledge” locked in that model.
Production issues
We often retrain models periodically. If a new model version performs worse than the last, reproducibility helps. You can compare the runs since you have all the ingredients versioned.
Also, if you ever need to roll back to a previous model, you should ideally retrain it (if data has changed) or at least have the exact artifact. Versioning allows you to do that.
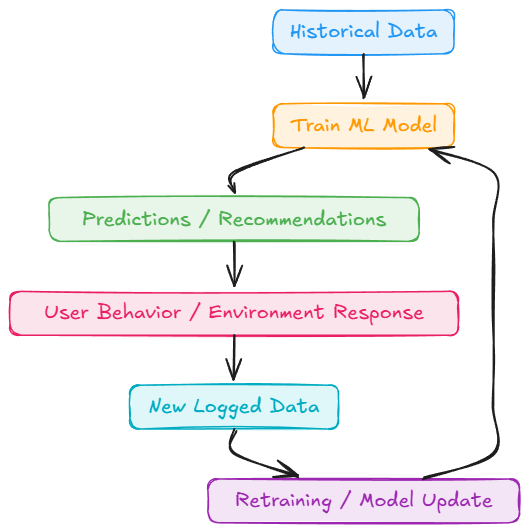
Now that we understand the significance of reproducibility, let’s first explore the challenges associated with it before diving into how we can incorporate it into our systems.
Challenges to reproducibility
Unlike pure software, ML’s outcome can depend on randomness (initial weights in neural nets, random train-test split, etc.). If not controlled, two runs with the same code/data could still yield slightly different models.
As we saw in Part 1, ML is “part code, part data”. You need to version both.
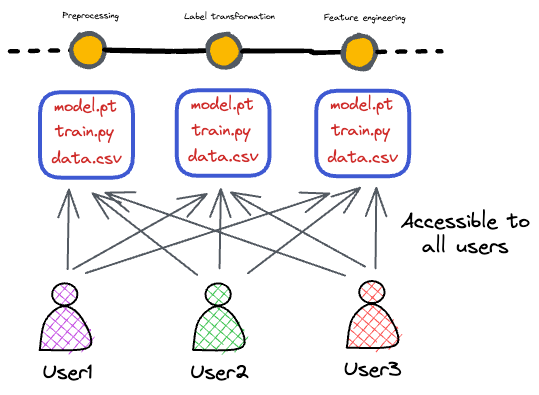
Data is large, so you can’t just throw your dataset into Git easily (plus, data may update over time).
Environment matters—the library versions, hardware (rarely, differences like floating-point precision on different GPUs can cause differences), OS, etc. If your training code relies on some system-specific behavior, that’s a reproducibility risk.
ML models and pipelines have a lot of moving pieces, like model hyperparameters, feature pipelines, pre-processing steps, etc.
It’s easy to have “experiments” that were not fully tracked. For example, you manually tweaked something in a notebook and forgot, leading to a one-off model that’s hard to replicate.
Next, let’s look at some best practices that can help us address these challenges and understand how to effectively incorporate reproducibility and versioning into ML systems.
Best practices for reproducibility and versioning
Now that we have a solid understanding of the importance of reproducibility and the challenges it presents, let’s explore the best practices that help us fully leverage the benefits of reproducibility and versioning.
Ensure deterministic processes
If exact reproducibility is needed, set random seeds in your training code. Most ML libraries allow this (e.g., np.random.seed(0), random.seed(0), and for frameworks like TensorFlow/PyTorch, there are ways to fix seeds for their random ops).
Note, however, that some parallel or GPU operations are inherently non-deterministic due to race conditions or reduced precision. If you need bit-for-bit identical results, you might have to sacrifice some performance (many frameworks have a “deterministic” mode that is a bit slower).
In practice, reproducibility within a tolerance is often enough, i.e., the model might not be bit-identical, but it should have a similar performance and similar outputs. Nevertheless, controlling sources of randomness (data shuffling order, weight initialization, etc.) is good practice.
Also, if using multiple threads, be aware that the order of execution could vary. Often, fixing seeds and using a single thread for critical parts can improve determinism.
The rule of thumb: if someone runs your training pipeline twice on the same machine, it should yield effectively the same model (or metrics). If it doesn’t, document that (maybe because of nondeterminism) and at least ensure the metrics are the same.
Version control for code
This is non-negotiable. All code, from data preparation scripts to model training code, should be in Git (or another version control system, abbreviated as VCS). Every experiment should ideally tie to a Git commit or tag.
That way, you know exactly which code produced which model. In practice, teams often include the Git commit hash in the model’s metadata. This allows tracing back from a model to the code.
Code versioning is well-understood in software engineering; ML just needs to extend that rigor to other artifacts.
Version data
This one is trickier but crucial. At minimum, if you’re retraining a model, save a snapshot or reference to the exact data used. If the training data lives in a database and is constantly changing, you might need to snapshot it.
If not managed, you might end up confused between different variants of the same data, not understanding which one was exactly used.
Ideally, we use tools like DVC (Data Version Control), which extends Git workflows to data and models. DVC doesn’t store the actual data in Git, but stores hashes/references so that data files can be versioned externally (e.g., on cloud storage) while still tying into Git commits.
For example, you could use DVC to track your train.csv, when you commit, DVC records a hash of that file (or a pointer to a cloud object). Later, you can reproduce that exact file even if it’s large.
DVC gives a “Git-like experience to organize your data, models, and experiments”.
Test for reproducibility
It might sound meta, but have a process to verify reproducibility. For instance, after training and saving a model, you could do a quick test: load the model and run it on a known test input to see if the results are as expected.
This ensures the model file isn’t corrupted and the environment can indeed produce the same outputs. Another idea is that if you retrain the model with the same data (perhaps with a different random seed or after some benign change), ensure metrics are in the same ballpark.
If they’re wildly different, something’s wrong. Either a bug or an unstable training process. For critical models, you might even have a “reproducibility test” where you attempt to re-run an old training job (on archive data) to see if you get the same result, as part of CI.
This is not common (because it can be expensive), but it’s conceptually similar to regression tests in software.
Track experiments and metadata
Use an experiment tracker (like MLflow) to log everything about an experiment and its runs.


This typically means that when you execute a training script, it logs:
- A unique run ID
- Parameters used (hyperparameters, training epochs, etc.)
- Metrics (accuracy, loss over epochs, etc.)
- The code version (via Git hash, as above)
- Data version (maybe a DVC data hash or dataset ID)
- The model artifact or a reference to it
- Possibly the environment info (library versions)
With this info, you have a record of each experiment. If run #42 was the best and became production, anyone can inspect run #42’s details and ideally reproduce it by checking out the same code and rerunning with the same data and parameters.
Note that an experiment in MLflow is a named collection of runs, where each run represents a specific execution of a machine learning workflow or training process.
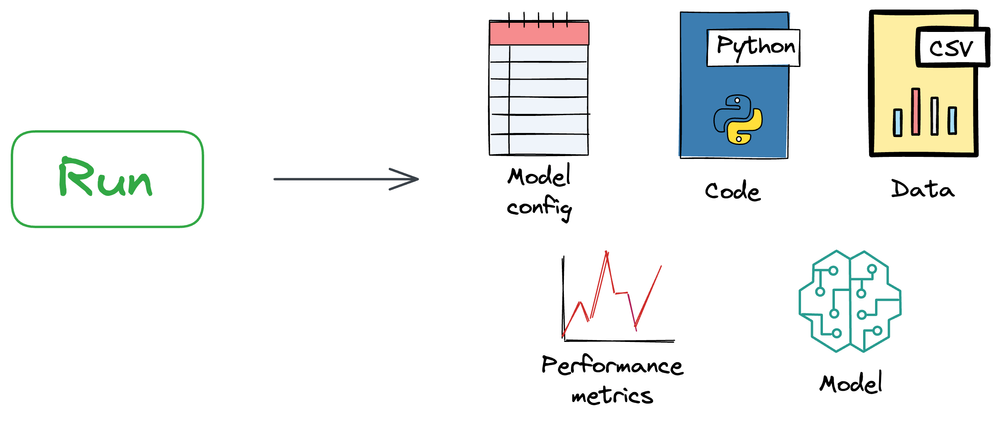
And to elaborate further, a run is a single execution of a machine learning workflow within a specific experiment.
It encapsulates all the details of that particular execution, including the code, parameters, metrics, and artifacts produced during the run.
Version model artifacts
Every time you train a model that could go to production, give it a version number or ID. Register it in a model registry.
Tools like MLflow provide a central place to manage models with versions and stages (e.g., “v1–staging”, “v1–production”).

A model registry entry contains the model artifact and metadata like who created it, when, and often references to the experiment or code. For instance, MLflow’s Model Registry provides a UI and API to transition models through stages and keep a history.
It also stores lineage, i.e., which run (with which parameters and data) produced that model. By using such a registry, you ensure that even if you deploy model v5 today, you can still fetch model v3 if needed, and you know exactly what each version is.
Data and model lineage logging
When a model is trained, log references to the exact data. For example, if you use a data lake with partitions, note which partition or timestamp. If you query a database, include the query or a data checksum in the log.
Some advanced setups use data lineage tools (like tracking data provenance through pipelines). For most, even just recording “used file X of size Y bytes, with checksum Z” is great. It allows you to verify that you have the same file later. If using DVC, the DVC commit ID acts as the link.
Environment management
Use tools to capture the software environment:
- Use a
requirements.txtorenvironment.yml(for Conda) to pin library versions needed for training and inference. - Avoid “floating” dependencies (like just saying
pandaswithout a version) because an update in a library could change behavior. - Containerize if possible: a Docker image can serve as an exact snapshot of the environment. You could even version your Docker images (like
my-train-env:v1). - If not containers, use virtual environments to isolate dependencies. That way, running the pipeline a year later with the same
requirements.txtcan (hopefully) recreate the needed environment. - Infrastructure as code: If your training involves spinning up certain cloud instances or using specific hardware, script that. This way, even infrastructure differences like accidentally using a GPU with different capabilities are less likely to creep in.
Trade-offs
It’s worth noting that absolute reproducibility (bit-for-bit) is sometimes unnecessarily strict. In many cases, we care that the performance or behavior is reproducible within a tolerance, not the exact weights.
For example, if training a deep net gives 0.859 accuracy one time and 0.851 the next time, that’s effectively the same in terms of usefulness. Trying to get identical weights might be overkill.
However, if you get 0.88 one time and 0.80 another time with supposedly the same setup, that indicates a problem (like maybe something changed that you didn’t control).
So aim for consistency, but don’t panic over a tiny difference caused by nondeterminism. From a business perspective, it’s the consistency of quality that matters. That said, if you can achieve bit-for-bit reproducibility easily, do it because it simplifies debugging, but be aware of the sources of nondeterminism as mentioned.
To summarize everything, in practice, achieving reproducibility requires discipline and culture as much as tools. You have to instill the habit of: “Did I commit that code? Did I tag the data version? Am I logging the runs?”
Sometimes, fast experimentation tempts people to do things quickly without tracking, but that can lead to wasting more time later untangling what was done. A common adage is: “If it’s not logged or versioned, it didn’t happen.”
So teams often adopt checklists or automation to enforce this (e.g., the training script automatically logs to MLflow so you can’t forget).
Overall, reproducibility and versioning are what make ML projects manageable and reliable in the long term. They turn ML from a one-off art into an engineering discipline.
By versioning everything (code, data, models, configs) and using tools to help track it, we create an audit trail for our models. This not only builds confidence (we can debug, we can improve, we can trust what’s running in production because we know where it came from) but also saves time.

As the saying goes, “If it isn’t reproducible, it’s not science.” In MLOps, if it isn’t reproducible, it won’t be robust in production.
Now that we’ve covered the key principles, let’s put some of these ideas into practice through some hands-on simulations.
PyTorch model training loop and model persistence
In this example, we illustrate a simple PyTorch training loop for a neural network, including how to handle reproducibility (with seeds) and how to save and load model weights.
We won’t use an experiment tracker here for brevity, but will show logging prints and saving. In practice, you’d integrate this with something like W&B or MLflow.
Project setup
This project's code is meant to be run using Google Colab. We recommend uploading the .ipynb notebook in Colab, and running it from there.
Download the notebook here: