The Machine Learning System Lifecycle
MLOps Part 2: A deeper look at the ML lifecycle, plus a minimal train-to-API and containerization demo using FastAPI and Docker.
Recap
Before we dive into Part 2 of this MLOps and LLMOps crash course, let’s briefly recap what we covered in the previous part of this course.
In Part 1, we explored the background and the basics of MLOps. We started off by seeing what exactly is meant by MLOps. Then we realized that model development is actually a very small part of a much larger journey.
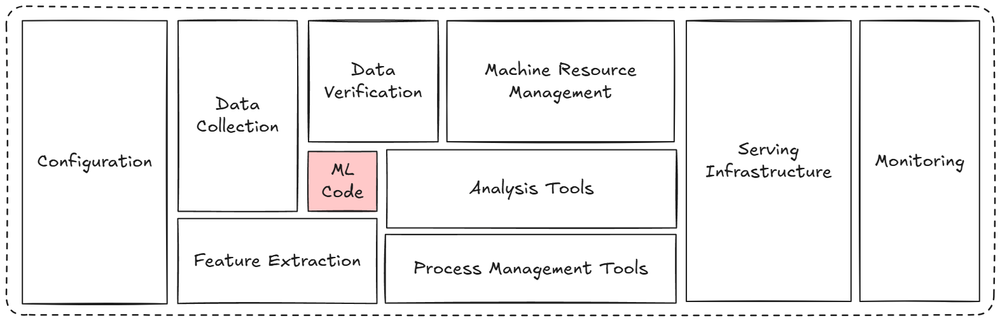
Next, we discussed why MLOps matters and how it helps in solving some of the long-standing issues of ML in the production world.
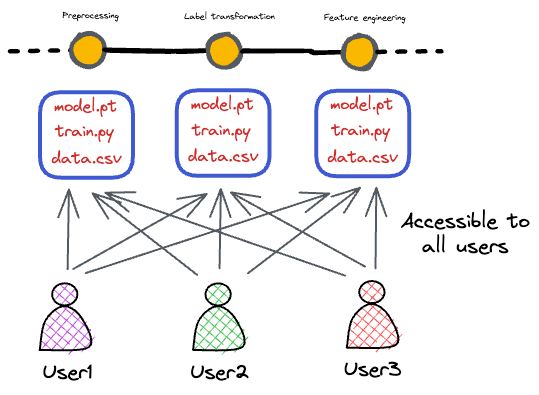
We also explored differences between ML systems/MLOps and traditional software systems.
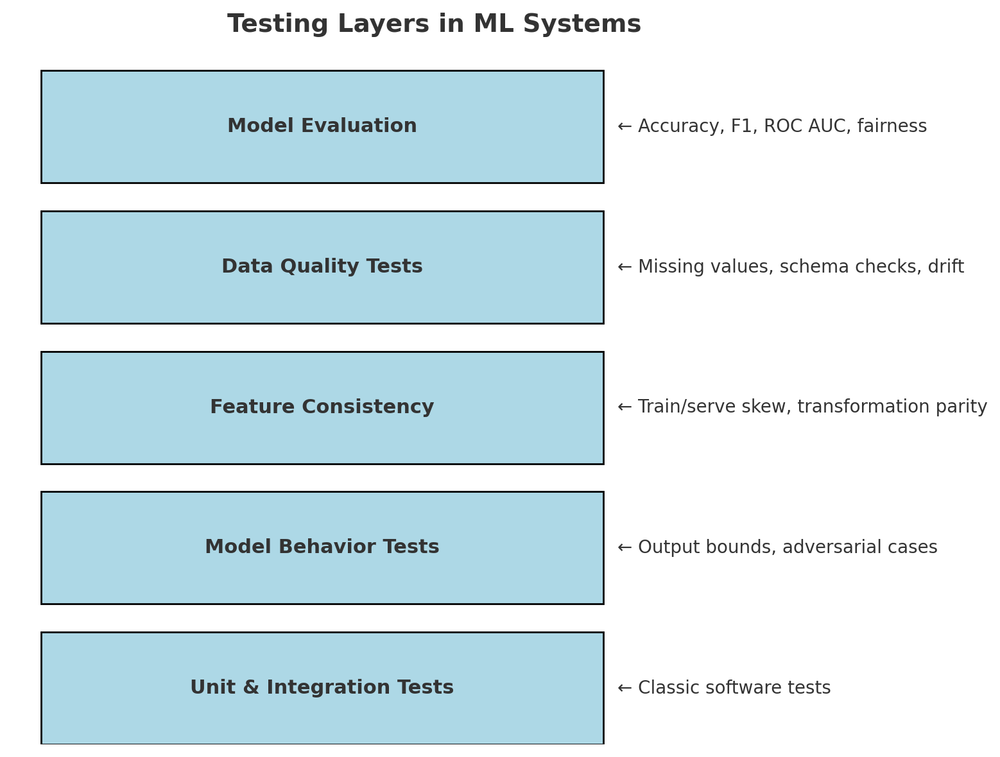
We then turned our focus to discussing some terminologies and system-level concerns in production ML. There, we checked out some common concerns related to latency and throughput, data and concept drift, feedback loops, etc.
Finally, we took a quick look at the machine learning system lifecycle and its various phases.
By the end of Part 1, we had a clear idea that ML is not just a model-centric exercise but rather a systems engineering discipline, where reproducibility, automation, and monitoring are first-class citizens.
If you haven’t yet studied Part 1, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
You can find it below:

In this chapter, we'll explore the ML system lifecycle in greater depth, focusing on the key details of each individual phase.
After that, we'll walk through a minimal demo that provides a quick simulation of an ML system, helping you practically connect to the basics of some of the theoretical concepts we've covered and those we'll explore further in this part.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
The machine learning system lifecycle (contd.)
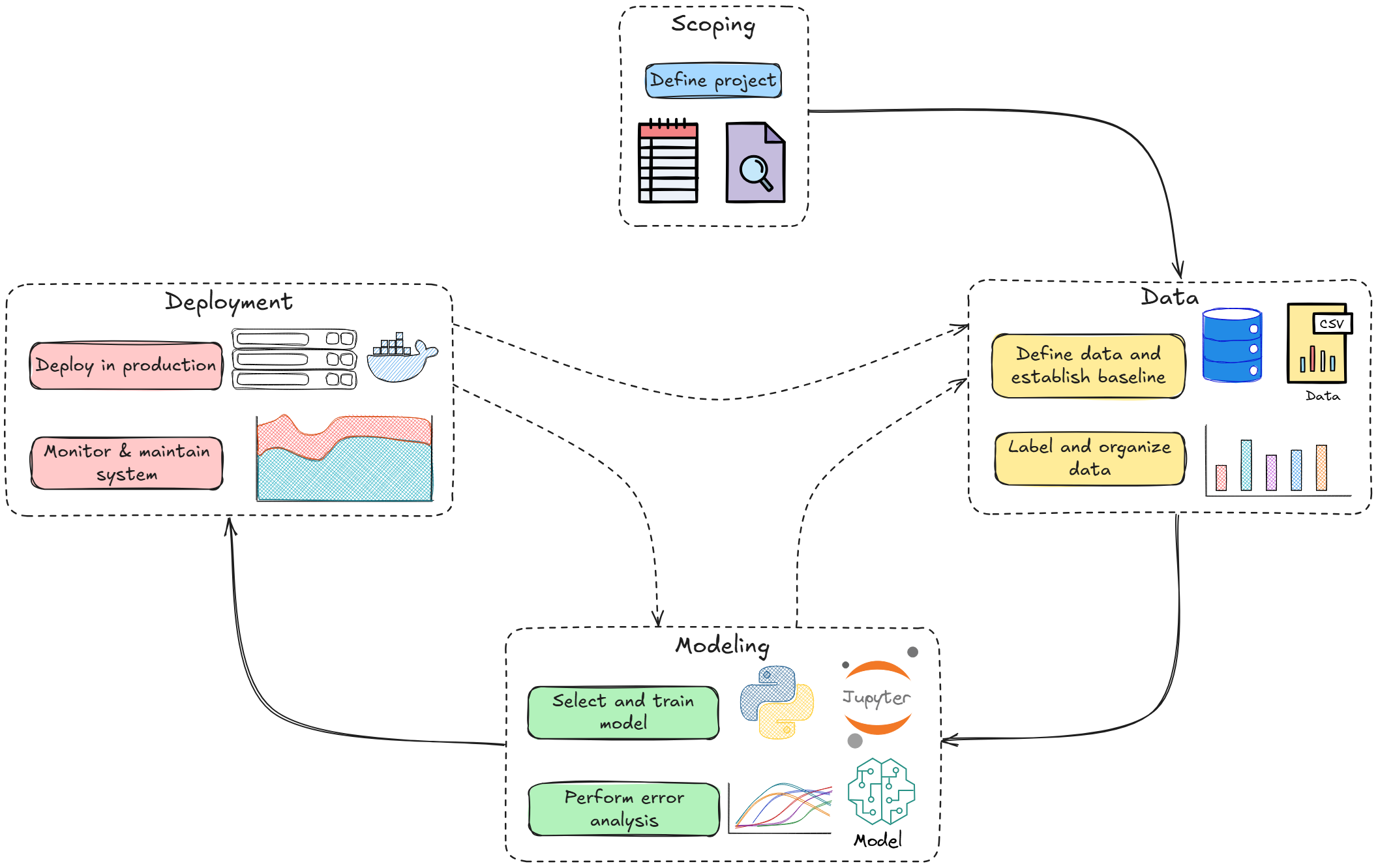
In our last part, we took an overview of the machine learning system lifecycle. We saw the different stages in the life of an ML system: Scoping → Data → Modeling → Deployment and Monitoring.
Let’s deepen our understanding by breaking down some of these components further, with a focus on the core technical elements of the ML pipeline:
Data pipelines
In ML, the quality and management of your data are often more important than the specific modeling algorithm.
In a production ML system, you need a robust data pipeline to reliably feed data into model training and eventually into model inference (serving).
Key aspects of data pipelines include:
Data ingestion
Getting raw data from various sources into your system/development environment.
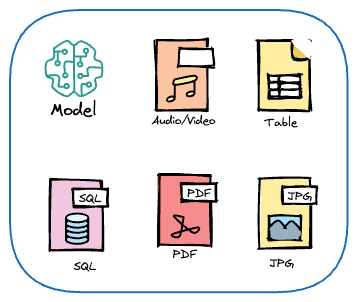
Ingestion can be done in batch (periodically importing a dump or running a daily job) or via streaming (real-time processing of incoming events).
Data storage
Once data is ingested, it needs to be stored (often in both raw form and processed form).
Common storage solutions include data lakes (e.g., cloud object storage like AWS S3, GCP Cloud Storage, or on-prem HDFS), relational databases, or specialized stores.
If you want to dive deeper into HDFS, we covered it in the PySpark deep dive:

Many production ML teams maintain a feature store, which acts as a centralized database of precomputed features that are used for model training and are also available for online inference.
The feature store ensures consistency between offline training data and online serving data.
Data processing (ETL)
Raw data often needs heavy processing to become useful for modeling. This includes joining multiple data sources, cleaning, normalizing features, encoding categorical variables, creating new features, etc.
This is typically done in an ETL (Extract-Transform-Load) pipeline. Tools like Apache Spark, or even plain Python scripts with Pandas, can be used, depending on scale.
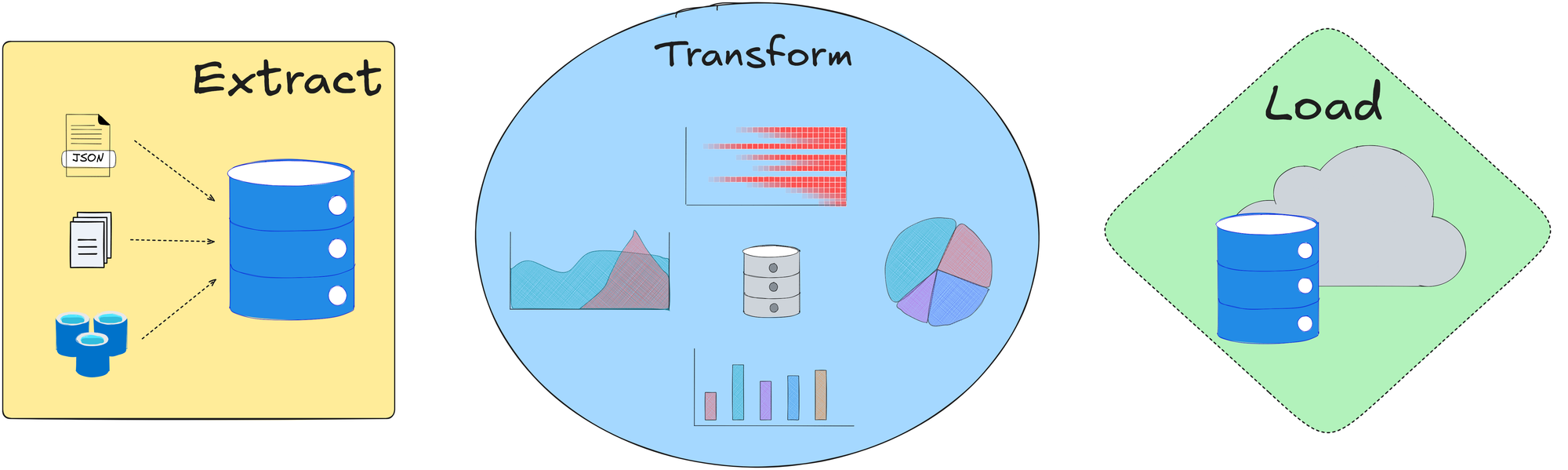
The output of this step is usually a curated dataset ready for model training.
Data labeling and annotation
If the ML problem is supervised and requires labels (ground truth), you need a process to obtain labels for your data. In some cases, labels are naturally collected, in other cases, you might need human annotation.
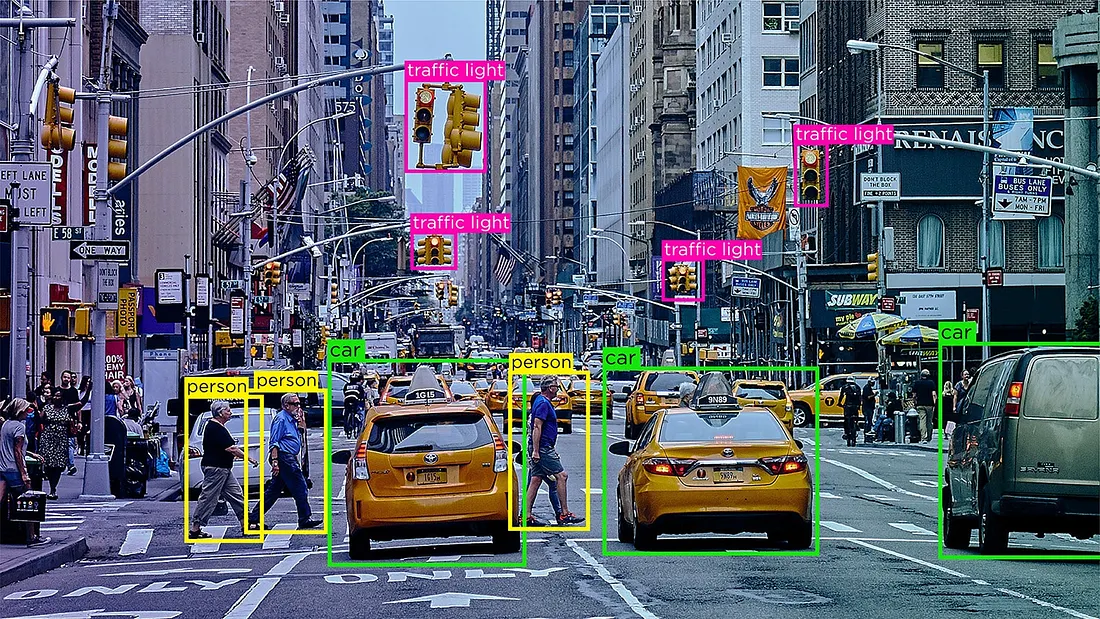
Production systems might include a labeling pipeline, using internal teams or crowd-sourcing to label new data on a continuous basis.
Data versioning and metadata
It’s critical to keep track of which data was used to train which model.
Data can change over time (new records appended, corrections applied, etc.), so simply saying “trained on dataset X” may not be enough; we need to know which version of dataset X was used to train a model for purposes like reproducibility, auditing, and model comparison.
Many teams log metadata about their pipelines: timestamps of data extraction, checksums of files, number of records, etc.
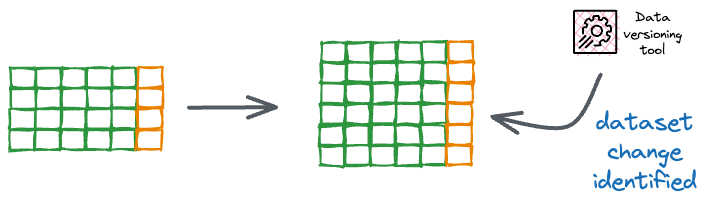
Tools can help manage dataset versions explicitly, for example, DVC allows you to version control data. We’ll talk more about data versioning later.
Before we move to the next stage of the ML system lifecycle, one important distinction to make is between offline data pipelines (for training) and online data pipelines (for serving features in real-time).