Model Deployment: EKS Lifecycle and Model Serving
MLOps Part 15: Understanding the EKS lifecycle, getting hands-on with AWS setup, and deploying a simple ML inference service on Amazon EKS.
Recap
In Part 14 of this MLOps and LLMOps crash course, we explored AWS and its services.

We began by exploring the fundamentals and gaining an overview of AWS. This included learning about what exactly AWS does, its market share, and how AWS (and other cloud platforms, in general) are layered platforms.
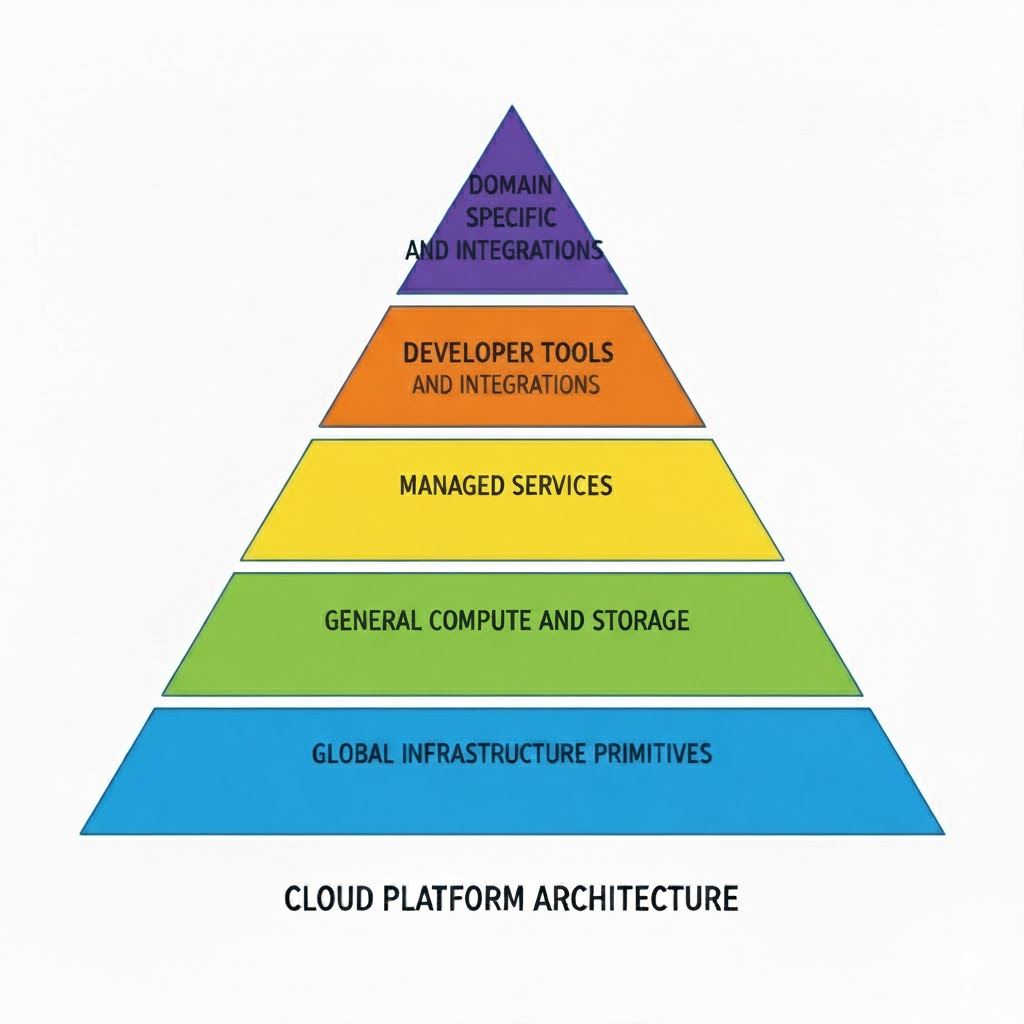
After that, we explored the key characteristics and design dimensions of AWS, understanding its service breadth, global infrastructure, managed operations, cost model and continuous evolution.
Next, we did a brief discussion on the strategic implications for organizations and how AWS simplifies operations for them via AWS Organizations.

Moving ahead, we explored the Elastic Kubernetes Service (EKS), its architecture and control plane and data plane specifics.

We also explored EC2, its architecture, its role in EKS node provisioning, node lifecycle and scaling and network and security aspects for EC2 nodes in EKS clusters.

Finally, we went ahead and learnt about the other EKS-related services and add-ons. This included AWS VPC CNI, CoreDNS, kube-proxy, Autoscaler, Load Balancer Controller, EBS CSI, ECR, AWS EBS and Fargate. With this, we concluded the previous chapter.

If you haven’t explored Part 14 yet, we strongly recommend going through it first since it stays directly connected to the content we’re about to dive into here.
Read it here:

In this chapter, we’ll continue our discussion on the deployment phase, diving deeper into a few more important areas, specifically getting hands-on with AWS.
We'll cover:
- Concepts on AWS EKS
- Setting up a free AWS account
- Hands-on demo: deploying a model on EKS
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let’s begin!
The EKS lifecycle
When it’s time to deploy a machine learning model, Amazon EKS offers a robust and repeatable framework for managing the model’s lifecycle.

Since we’re already familiar with AWS and its core services, we can focus on how EKS integrates these components, examining its operational mechanics, how it supports workloads such as model serving.
Cluster creation
The first step is provisioning the Kubernetes control plane and the associated compute and networking fabric.
We may use the AWS Management Console, the AWS CLI, or, most commonly, the command-line tool eksctl.
eksctl via the hands-on tutorial ahead.With eksctl we invoke a command such as:
This single invocation triggers a series of underlying orchestrations:
- A multi-AZ control plane (by default across three availability zones in the selected region) is created and managed by AWS.
- A managed node group of EC2 instances (here, t3.small type, two nodes) is provisioned, configured to register with the cluster.
- Networking is set up: VPC, subnets, security groups, route tables, the appropriate tagging, etc.
eksctlautomatically creates managed node groups by default when creating a cluster.- IAM roles are created for the node group and for the EKS control plane to manage Kubernetes operations securely.
- Default Kubernetes add-ons are installed: the CoreDNS service, kube-proxy for node networking, and Amazon’s VPC CNI plugin for Kubernetes pod networking.
Since we already understand the underlying AWS components, what to emphasize here is that EKS abstracts away the control plane lifecycle (patching, scaling, high availability).
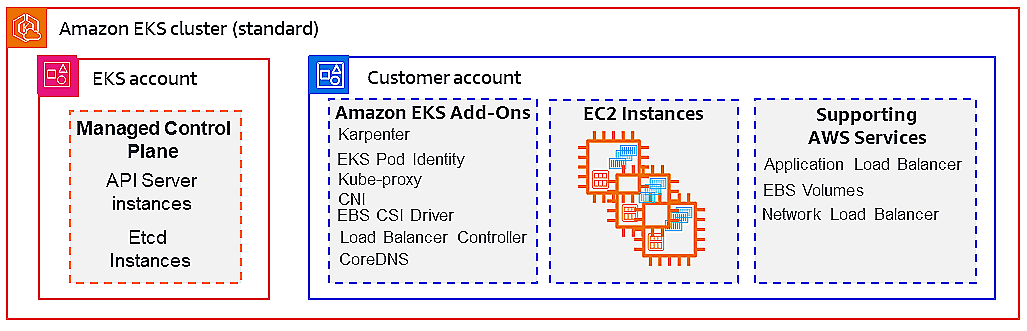
Hence, our primary scope becomes node management, workload deployment, monitoring and governance.
Node registration
Once the node group instances are running, the next step is registration with the Kubernetes scheduler.
Each EC2 instance boots from the EKS-provided AMI and runs a bootstrap script that uses authentication to register and join the cluster.
The mapping of IAM Role to Kubernetes node identity is handled via the aws-auth ConfigMap in the kube-system namespace. The IAM role attached to the node instances (via the instance profile) appears in that ConfigMap and is thereby granted the ability to work as Kubernetes nodes.
kube-system namespace in Kubernetes is a dedicated and crucial namespace reserved for objects and resources that are essential for the functioning of the Kubernetes cluster itself. It houses the core components (Kubernetes API server, Scheduler, kube-proxy, etc.) that make Kubernetes work.At this point the node becomes available in the scheduling pool: it appears in kubectl get nodes, and the VPC CNI plugin attaches the required secondary IP addresses permitting pod network communication.
The crucial takeaway is that nodes are standard EC2 instances under the hood, but once joined to EKS they behave as part of the Kubernetes cluster.

Any AWS-specific steps and processes are abstracted by EKS, allowing us to treat the cluster as a native Kubernetes environment.
Deploying workloads
With the cluster live and nodes registered, we move into deploying your workloads. Whether we are deploying a microservice, a stateful endpoint, or a full ML inference pipeline, we use standard Kubernetes manifests (Deployment, Service, etc.). The important point is that the integration with AWS services becomes seamless.
For example, as we'll cover ahead, to expose a model-serving endpoint publicly we would create a Service of type LoadBalancer:
- If the AWS Load Balancer Controller is installed, it will automatically provision an AWS Network Load Balancer (NLB) or Application Load Balancer (ALB), register the appropriate targets and manage the lifecycle of that load balancer.
- If the controller is not installed, the built-in provider will instead provision a Classic Load Balancer (CLB), register the Kubernetes nodes as targets, and route traffic through the service’s
NodePortsto the pods.
If your inference service needs durable storage (for caching model artifacts or logs), a PersistentVolumeClaim that binds to an EBS volume via the Kubernetes CSI driver can be created. If the pipeline needs to ingest large reference datasets, we can connect to S3. All of these storage modalities integrate easily with Kubernetes workloads running in EKS.
Scaling and updates
Once your model deployment is live, and need to scale (both up and down) and periodic updates (both in terms of Kubernetes version and node instance types), then EKS supports these via several mechanisms.
Autoscaling nodes:
When the inference load increases, the Kubernetes optional add-on component Cluster Autoscaler watches for unscheduled pods (typically due to lack of node capacity).
It then triggers AWS Auto Scaling Groups to add more EC2 instances to the node pool. When load decreases, the autoscaler triggers node termination (respecting pod eviction policies).
Scaling your workloads:
On the Kubernetes side, one can also configure Horizontal Pod Autoscalers (HPA). For example, you might scale up the number of replicas of your model-serving container when request latency exceeds a threshold. Beneath that, the autoscaler ensures sufficient nodes to host those pods. Monitoring and testing are crucial here to avoid cold-start issues with model loading.

Recommended reading:

Upgrading the control plane:
AWS manages the control plane, but you initiate version upgrades. You might upgrade from Kubernetes v1.XX to v1.XY; you do this via the AWS console, CLI or eksctl. After the control plane version is updated, you proceed with rolling updates of the node groups.
Managed node groups allow to update the AMI version, switch instance types, or increase node count with minimal downtime. Pods will be drained from old nodes and rescheduled on new ones.
Update of add-on components:
The Kubernetes add-ons (kube-proxy, CoreDNS, VPC CNI, etc.) also require updates. EKS provides version compatibility guarantees (the worker nodes and control plane must match within specified skew).
Now that we understand the flow and events in EKS-based workload management, let's go ahead and quickly review the integration of EKS into the broader AWS ecosystem.
Integration into the broader AWS ecosystem
While EKS delivers the Kubernetes control plane and orchestration layer, one of its greatest strengths is how deeply it integrates with other AWS services.
Identity and Access Management (IAM)
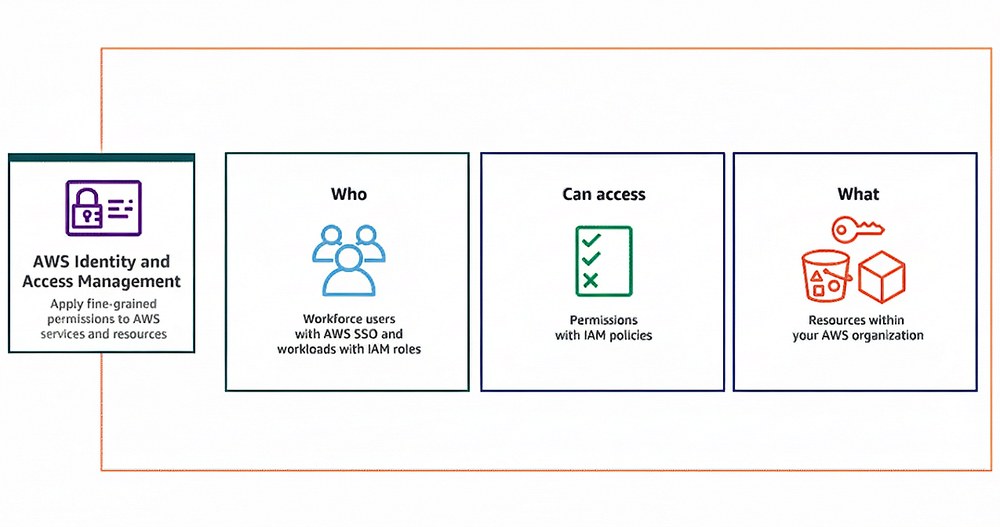
The integration between AWS IAM and Kubernetes is critical. The EKS control plane uses IAM to call AWS APIs, while worker nodes assume EC2 instance profiles with associated IAM roles.
These roles are mapped to Kubernetes users and groups via the aws-auth ConfigMap. More advanced deployments leverage IRSA (IAM Roles for Service Accounts) so that individual pods assume IAM roles.
This means that your model-serving pods can access exactly the S3 buckets or DynamoDB tables they need, no more, no less.
Networking: VPC, Route 53
EKS cluster lives inside a VPC, utilizing subnets. Pods receive IP addresses from the VPC via the VPC CNI secondary-IP model.
You can expose ingress via AWS Load Balancer Controller, integrate with Route 53 for DNS, and even connect your on-premises network via VPN, enabling a hybrid architecture where training data or model artifacts reside in a local data center, and inference runs in EKS. This means, the networking fabric continues to be under your control.

Storage
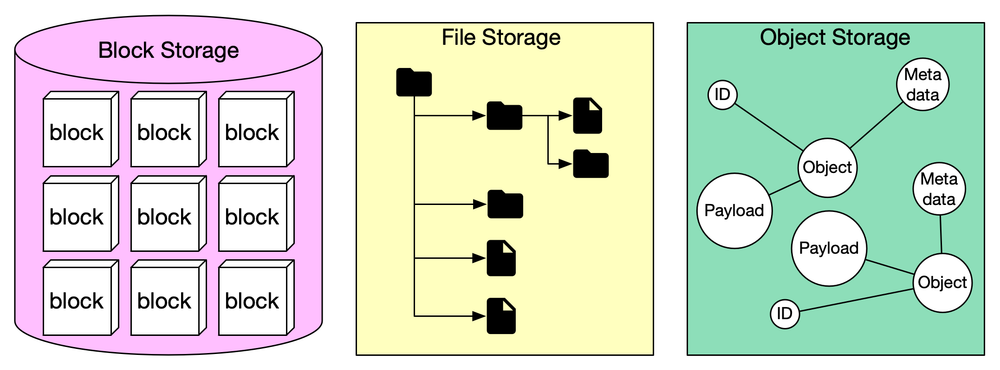
EKS supports EBS volumes for block storage, S3 for truly durable object storage, and others like EFS. Kubernetes uses CSI drivers (Container Storage Interface) for dynamic provisioning of volumes.
Also note that, beneath every EKS cluster, the underlying compute infrastructure typically runs on EC2 instances, each of which relies on Amazon Elastic Block Store (EBS) volumes as its root storage.
Every worker node, whether part of a managed or self-managed node group, launches with an attached EBS volume that contains the operating system, Kubernetes agent binaries, and container runtime storage.
These root volumes are automatically provisioned and deleted with the node lifecycle. This EBS integration exists by default, no additional driver is required for node operation.
Hence, CSI drivers are needed when workloads inside the cluster need persistent volumes of their own.
Security
Workloads on EKS benefit from AWS’s mature security ecosystem. Secrets can be encrypted via AWS Key Management Service (KMS) and injected into Kubernetes via Secrets Store CSI drivers.
The VPC-CNI plugin ensures your pods live inside your VPC and respect network security groups and flow logs.
If your model-serving API is exposed to the web, you can front it with a AWS Web Application Firewall (WAF) and ALB (Application Load Balancer) for DDoS protection, bot mitigation and request-inspection. This treats your Kubernetes workload as an AWS first-class citizen with respect to security.
Monitoring and observability
EKS does not reinvent observability. Metrics, logs and traces from your cluster and pods can flow into CloudWatch or other logging systems. You can instrument your model-serving containers to emit custom metrics and trace end-to-end requests through your API gateway, Kubernetes service, and database.
Now that we’ve walked through the lifecycle and integration, let’s see how architecture and operations choices influence cost, resilience, and other factors.
Design and operational considerations
Let’s review how key architecture and operations choices influence cost, resilience, performance and security, with particular focus to model deployment.
Cluster topology
When you create an EKS cluster, the control plane is automatically distributed across multiple Availability Zones to ensure high availability. To achieve fault tolerance for your workloads, you should also distribute your node groups across multiple AZs. This way, if one AZ experiences an outage, the control plane remains healthy and your nodes in other zones can continue serving traffic.
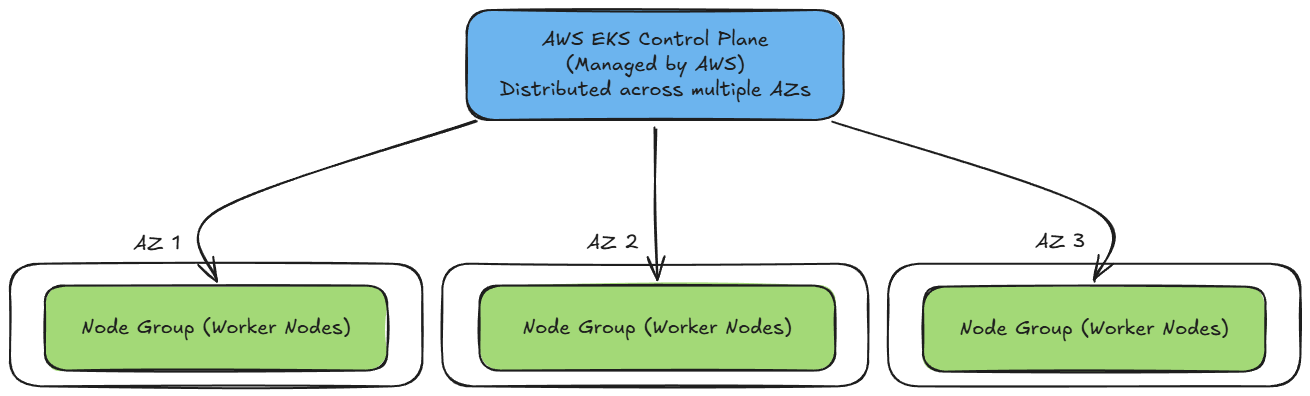
Using managed node groups further simplifies lifecycle management, as AWS handles provisioning, versioning, and patching of the underlying EC2 instances. You just need to trigger updates when you want to roll out new AMI or Kubernetes versions.
Networking strategy
When designing your model-inference API architecture, the first step is to determine whether your endpoints should be public or private.
Public endpoints allow access over the internet and are suitable for open APIs or publicly available models. In contrast, private endpoints restrict access within your secure network and typically require VPC Peering or AWS Direct Connect to establish connectivity from your on-premises environment or internal systems.

This ensures that sensitive inference traffic remains isolated from the public internet, maintaining higher confidentiality and control.
To mention another aspect from a security point-of-view: the control plane should ideally reside within private subnets, ensuring that all cluster management traffic stays internal and protected from external exposure.
However, using a public control-plane endpoint is not inherently insecure, it remains protected by IAM authentication, Kubernetes RBAC, and TLS encryption. When properly configured, it can offer both security and convenience, particularly for administrative access from trusted external networks.
Finally, since latency is critical for model inference, ensure that your inference paths are optimized for high bandwidth and low latency. Place your inference nodes in the same region or availability zone as your users.
Usage of appropriate instance types and networking configurations to guarantee consistent throughput.
Storage and data architecture
Choose the right storage medium for the job. For example, inference pods that maintain a local cache of model weights might use EBS for fast block access.
If you have deployed training pipelines, that ingest large datasets or write logs, S3 is the de-facto durable storage service.
Cost optimization
A model-serving cluster may idle during certain hours (e.g., off-peak). Hence, might use node group autoscaling to scale down to minimum nodes when load is low.
Right-size your node types: for example, if your inference container uses just 2 vCPU and 4 GB RAM, avoid launching larger nodes.
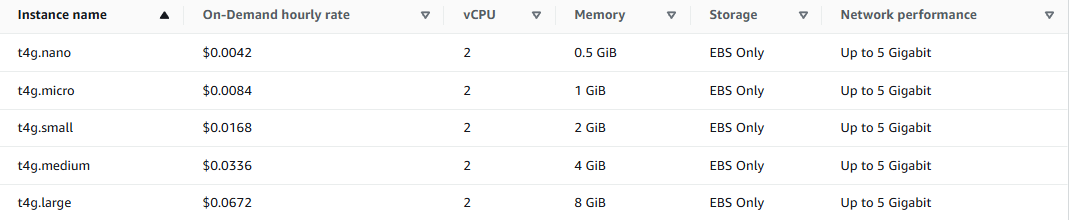
Leverage savings plans or reserved instances if you have steady usage patterns.
Observability

Collect logs, metrics, and traces. Create CloudWatch dashboards, implement alerts (e.g., for pod restarts, high inference latency). Ensure you have alerting for node group health, control-plane version compatibility warnings and any specific errors.
In a nutshell, EKS takes care of many of the heavy operational lifts, control-plane lifecycle, high-availability across zones, and integration with AWS services. So you can focus on what matters most: deployment.
By understanding how the control plane, EC2 nodes, and managed add-ons (networking, storage, monitoring) fit together, you are well primed to deploy containerized applications on the AWS cloud.
Now that the foundation is in place, let's move to the next section where we will first see how to set up a free-tier AWS account and apply this understanding to deploy a machine-learning model on our cluster, while respecting the boundaries of the free tier.